


 下载:
下载:

-
近年来国内语音识别技术快速发展,并取得显著成效.国内语音识别领域处于领先地位的科大讯飞、百度语音实验室等对汉语语音识别率可以达到95%以上,但对濒危少数民族语言,如普米语、佤语等语言的语音识别技术研究仍处于空白状态.普米族主要居住于云南省和四川省,普米语为其民族语言,由于没有文字,语言和文化仅限于口口相传[1].随着年长的人相继离世,普米族的语言和文化正逐渐消亡.为了促进普米族语言和文化的传承和发展,语音识别技术介入迫在眉睫.
尽管目前语音识别的方法很多,但总的来说可以归结为基于语音信号和基于语谱图的2种语音识别方法.语音识别中,同一个词不同说话者的语速不同,同一个人发同一个音,在不同时刻,所用的时间也不相同[2-3].因此,通过语音信号来统计人类语音的发音特征非常困难.基于语音信号的语音识别中提取的特征参数主要有梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficient,MFCC)、线性预测倒谱系数(Linear Prediction Cepstrum Coefficient,LPCC)等,其中MFCC、LPCC是最有效的[4],但这2个特征参数的提取是比较困难的.而基于语谱图的方法能够包含发音特点,并将语音信号的所有特征以图像的形式显示出来.通过傅里叶变换将语音信号转换为语谱图,借助图像处理的方法提取语谱图特征,最后利用分类器,可以实现基于语谱图的语音识别,从而大大减小了语音识别的难度.近年来国内对基于语谱图的语音识别展开了研究.如:宋洋[5]提取语谱图的边界特征和二值特征作为语谱特征,通过构造BP神经网络实现维吾尔语音素分类.唐闺臣等[6]通过提取语谱图中的Hu不变矩特征、纹理特征和部分语谱特征,基于SVM实现了对语音情感的分类.梁士利等[7]将语谱图的频域图矩阵进行投影后的值作为特征值,并利用SVM实现二字汉语词汇语音识别.
基于语谱图的语音识别,其本质是实现语谱图的分类.普米语孤立词语谱图分类属于模式识别的范畴[8],模式识别算法的选择是普米语孤立词语谱图分类的难点也是核心问题.目前常用的模式识别算法有神经网络算法(Neural Network Algorithm,NNA)、K-近邻分类器(K-Nearest Neighbor Classifier,KNNC)[9]、支持向量机(Support Vector Machine,SVM)、卷积神经网络(Convolutional Neural Network,CNN)等.神经网络算法、K-近邻分类器进行模型训练时需要大量训练样本.此外,神经网络算法[10]基于经验风险最小化原则,面临“过学习的风险”的问题. SVM针对多分类和大样本数据时,单一核在学习过程中存在学习能力强泛化能力弱或泛化能力强学习能力弱等局限性,需要引入多核支持向量机[11].卷积神经网络[12-14]是深度学习的一个重要算法,其提供了一种端到端的学习模型,通过梯度下降算法可对模型的参数进行训练,并自动地学习图像的特征完成图像的分类.
全文HTML
-
基于Google公司开源的一个机器学习框架系统Tensorflow,本文搭建了一个卷积神经网络模型,在此基础上利用语谱图样本集对模型进行训练.模型训练的步骤为:①初始化普米语语谱图数据集;②训练模型的参数;③模型的测试.由此得到语谱图分类的卷积神经网络模型.
-
CNN模型由7个卷积层和2个全连接层组成.将彩色语谱图直接输入到卷积神经网络模型中,由于图像是彩色的,故模型通道数为3.对输入的图片进行卷积操作后,采用ReLU激活函数,对卷积核的输出值进行非线性变换,接着采用maxpoolig完成最大池化操作.全连接层采用的激活函数是ReLU函数,为了防止模型训练过拟合,在全连接层后都添加Dropout层,设置dropout_ratio参数值为0.5,即在模型训练过程中随机让网络中50%的节点不工作(输出置0),表 1列出了CNN网络结构的详细参数表.
-
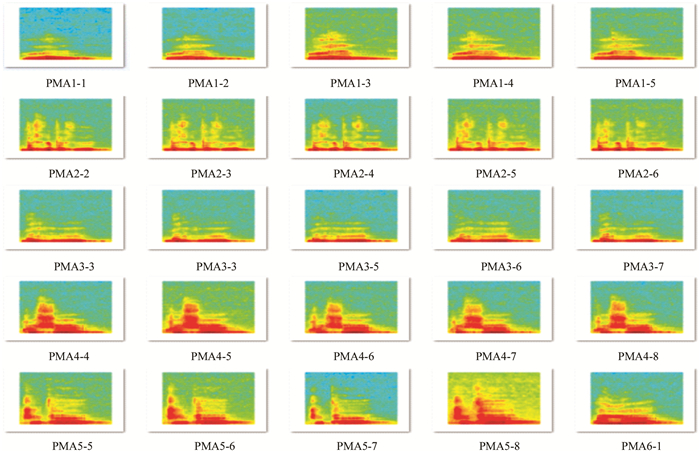
1) 在Tensorflow根目录下的子目录Spectrogram-Final文件夹中创建一个名为“tp-jpg”的文件夹,该文件夹用于存放语谱图样本集.部分训练样本如图 1所示.
2) 在Spectrogram-Final文件夹中有一个名为“bmp2jpg”的运行脚本,可将bmp格式的图片转换为jpg格式,并利用resize函数对图像进行缩放.
3) 通过执行Spectrogram-Final文件夹中的data-util.py代码,能将样本集严格地分为训练集和测试集,并且得到图名称与标签.
-
Spectrogram-Final文件夹中的cnn-model.py为设计好的卷积神经网络模型脚本,里面有卷积神经网络模型构造的详细内容,包括每一个卷积层、池化层的参数设计.设计好的卷积神经网络模型,执行cnn-model.py的代码,通过Tensorboard可以查看网络模型的示意图.
-
卷积神经网络的训练方式分为逐个样例训练方式、批量样例训练方式和随机批量样本训练3种方式.本文设计的模型采用的是批量样例训练,每个批次训练150个样本,迭代260次,在迭代过程中,利用梯度下降算法和反向传播算法对模型的参数权值和偏置值进行修改.
1) Spectrogram-Final文件夹中的train.py文件为卷积神经网络模型的训练代码.将data-util.py所生成的训练样本和测试样本输入到上述已经设计好的模型中,其中每批次训练的数量为150个样本,迭代260个周期,每迭代一次就测试一次数据.网络的基础学习率为0.0005,随着网络的训练,学习率将慢慢减小,从而使结果收敛.执行该程序,即可训练上述定义的卷积神经网络模型.
2) 通过Spectrogram-Final文件夹中的nohup.out GPU文件,可以查看模型训练过程中准确率的变化情况,如图 2所示,IFNO代表分类准确率的变化情况.此外,也可以通过Tensorboard-logdir train.log/命令启动train.log模型训练日志查看Accuracy和cross entropy的变化曲线,从曲线中能够清楚地看到Accuracy和cross entropy的变化情况.
3) Spectrogram-Final文件夹中的checkpoint文件夹,用于存放训练好的模型,可以自行查看训练后保存的模型、验证模型. checkpoint文件夹中包含checkpoint、model_260.ckpt.data-00000-of-00001、model_260.ckpt.index、model_260.ckpt.meta 4个文件. checkpoint是一个文本文件,记录了训练过程中所有中间节点上保存的模型的名称,图 3为checkpoint文件中间节点上保存的模型名称示意图. model_260.ckpt.meta文件是以“protocol buffer”的格式存储模型的结构图、定义的操作等信息. model_260.ckpt.data-00000-of-00001文件保存网络结构的变量值,而model_260.ckpt.index文件则保存model_260.ckpt.data-00000-of-00001中数据和model_260.ckpt.meta文件之间的对应关系.
1.1. CNN模型的构造
1.2. CNN模型的训练过程
1.2.1. 数据的初始化
1.2.2. 构造CNN模型
1.2.3. 训练CNN模型
-
针对已训练好的卷积神经网络模型,通过实验检验各项因素对语谱图分类准确率的影响,从而得到卷积神经网络模型适当的参数.在参数确定后,将卷积神经网络与支持向量机(SVM)、BP神经网络做了对比实验,以验证算法的可行性和有效性,并对CNN优于SVM、BP神经网络的原因进行分析.
-
实验室研究团队在云南省兰坪白族普米族自治县河西乡箐花村和录音棚中共采集了1 650个普米语孤立词语音语料,发音人为2男2女,每个词8遍,总计得到52 800条普米语孤立词语音.通过傅里叶变换可将这52 800条语音转换为语谱图,形成本文使用的样本集.
-
在测试实验中,当输入的一张语谱图经过卷积神经网络后,输出的类别与其对应的标签相符,则表明该语谱图的分类正确.反之,则网络对该语谱图的分类错误.将测试集输入至卷积神经网络中,最终的准确率作为该网络的评价指标,也作为普米语孤立词语谱图分类的最终准确率.准确率的高低作为卷积神经网络性能的评价指标.而且通过卷积神经网络与传统分类器进行分类效果的比较,可以判断卷积神经网络性能的优劣.实验的分类准确率定义为
-
实验包括彩色语谱图测试实验,以及在不同学习率、不同样本比例、不同激活函数下的对比实验,由此,可以得到卷积神经网络模型的适当参数.基于已设计好的CNN模型,利用普米语孤立词语谱图进行训练,并与传统分类器进行对比,从而可以对CNN的性能进行判断.
普米语孤立词语音信号的采样频率为44 100 Hz,单通道,语音信号为.wav格式.傅里叶变换设置的点数为1 024,重叠的长度512,窗长为1 024.下述实验中从语料库中选取了1 650条普米语孤立词语音信号,生成13 200张语谱图,其中11 550张为训练集,1 000张为测试集,650张为验证集.
-
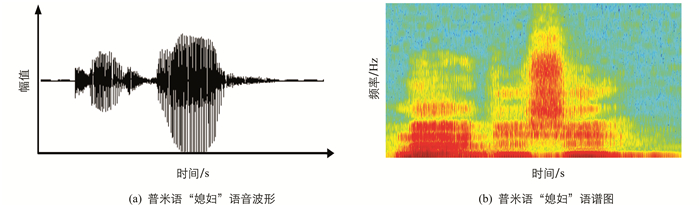
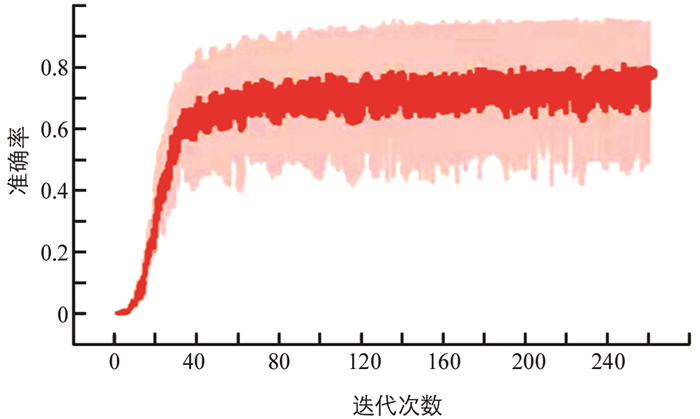
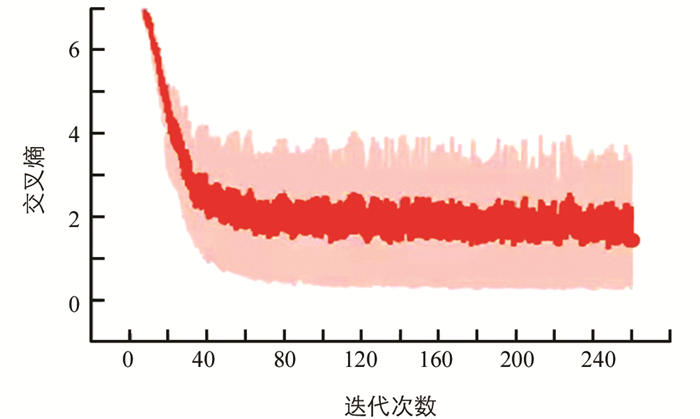
在Python程序中,调用已经编写好的Specgram程序将语音信号转换为彩色语谱图,生成的语谱图为200×900 px.利用resize函数可将语谱图大小修改为200×150 px,其修改后的语谱图直接作卷积神经网络的输入,进行网络模型训练并测试性能. 图 4为调用Specgram函数后,语音信号转换为语谱图的示例,图 5为彩色语谱图Accuracy曲线图,图 6则为彩色语谱图cross-entropy曲线图.
图 4中能够看出,语音信号转换为语谱图,语音特征更加直观. 图 5可观察到在卷积神经网络的训练过程中,彩色语谱图的Accuracy值逐渐向0.95靠近,并趋于平缓. 图 6中cross-entropy的值逐渐向0.01靠近,由此可以对网络模型参数进行调整.
-
卷积神经网络学习率的大小影响普米语孤立词语谱图的分类效果.学习率过大,卷积神经网络学习的速度会加快,造成Accuracy曲线震荡或者发散;而学习率过小,会造成训练过程算法过早收敛.因此,本次实验采用0.000 5、0.001、0.005、0.05、0.01、0.1这6种不同的学习率进行对比实验,找出最佳学习率的值. 表 2为6种不同学习率下的对比实验结果.
从表 2的对比实验中可以看出,学习率不同,语谱图分类准确率也不同.从表中还可以看出,虽然迭代次数在增加,但卷积神经网络学习率的值变化趋势越来越平缓,说明模型的学习能力趋于稳定.当学习率为0.000 5时,分类准确率最高,故本文所采用的卷积神经网络学习率为0.000 5.
-
表 3为4种不同样本比例的对照表,表 4则为每一类语谱图的4种样本比例对照表,表 5和表 6为不同规模样本集下的对比实验.从表 5中可以得出少量的样本无法训练模型,对语谱图的最终分类准确率产生的影响较大.当样本比例为7:1时,分类准确率最高,达到95.31%.
在实验中,语谱图共有1 650类,每一类有8张.每一类的训练样本集与测试样本集比例的不同,都会影响每一类的分类准确率.由此每一类训练样本集与测试样本集比例分别为3:5、4:4、6:2、7:1,表 6则为每一类不同样本比例的对比实验结果. 表 6可以得出结论,当每类样本的训练集与测试集之间的比率为7:1时,语谱图的分类准确率最高,约为95%.样本比例为6:2时,准确率达到78.98%,而样本比例分别为3:5、4:4时,分类准确率分别为37%、44.49%.相比之下,当比例为7:1时,可在一定程度上提高最终的分类准确率.
-
在卷积神经网络模型中,需要考虑不同的输出节点数是否会对模型的性能产生影响.由此,设置全连接层输出节点数分别为1 024、2 048、4 096进行对比实验.实验结果如表 7所示.
-
卷积操作实际上是一种线性操作,然而许多机器学习的问题是非线性的,需要将一个特征空间的向量通过非线性变换映射到另一个空间中,才能实现线性可分.激活函数是非线性变换的一种手段.常用的4种激活函数特点不一样,有的激活函数可能会在模型训练过程中出现“梯度消失”的问题,而有的则不会出现此问题.由此,需要通过实验找出分类效果好、收敛速度快的激活函数,实验结果如表 8所示.
从表 8中可以看出,在卷积神经网络模型中,以ReLU函数作为激活函数,模型训练时间最短,并且语谱图的分类效果是最好的.故本文模型选用ReLU函数作为激活函数.
-
上述实验分别从输入的样本比例、学习率等方面进行对比实验,由此得到CNN模型的最佳设置参数,表 9为卷积神经网络模型的最终参数设置.
-
为了说明该CNN模型对普米语孤立词语谱图分类具有可行性和有效性,在相同实验条件下,本文进行基于SVM、BP神经网络和CNN的对比实验.从普米语孤立词语谱图样本集中选择400张进行基于SVM、BP神经网络的分类实验,其中320张作为训练集,80张作为测试集,提取每张语谱图的二值特征,得到16×16的特征矩阵.
1) 基于SVM的语谱图分类实验中,核函数与参数的确定将直接影响分类精度和泛化性能.针对这些问题,首先进行了线性核、多项式核、高斯径向基核、多层感知器核函数的对比实验,由实验结果得出:采用径向基函数作为SVM的核函数,预测分类准确率最高.其次,为了确定各个独立核的惩罚参数c和核函数参数g的值,先利用网格法来找最优参数.然而,该方法只能找到局部最优参数.免疫遗传算法将免疫算子添加到遗传算法中,避免了传统遗传算法不成熟收敛的问题,具有随机并行搜索的优点.因此,利用它进行SVM参数的全局优化.结果表明,当c=5.278,g=0.062 5时,分类准确率最高,其结果如表 10所示.
2) 基于BP神经网络的语谱图分类实验中,本文构建由输入层、隐含层、输出层组成的三层的BP神经网络模型进行语谱图的分类实验,模型的结构为256-28-80,即输入层有256个节点,隐含层有28个节点,输出层为80个节点,其模型的基本参数学习率、期望精度、迭代次数分别为0.000 5、10-5、60次.
3) 在上述的对比实验中,得到卷积神经网络模型适当的参数,并利用调整参数之后的模型进行普米语孤立词语谱图的分类实验. 3种方法的分类准确率如表 10所示.
在上述SVM、BP神经网络和CNN的对比实验中,基于SVM的语谱图分类准确率为63%,而BP神经网络的分类准确率为58%,基于CNN的语谱图分类准确率最高,达到91%.因此,可以得出CNN与传统分类器SVM和BP神经网络相比,语谱图分类准确率最高,性能最好.
BP神经网络在训练过程中容易出现过拟合的问题,影响分类准确率. SVM针对小样本,虽然有很强的学习能力和泛化能力,可得到现有信息下的最优分类模式,但对多分类和大样本数据,需要引入多核支持向量机,核函数的组合以及参数寻优十分困难.而卷积神经网络采用ReLU激活函数,避免了过拟合的问题,大样本数据则有利于模型参数的调整,此外,CNN能从图像中自动提取复杂的特征.因此,分类效果最好.
2.1. 数据集
2.2. 实验的评价标准
2.3. CNN的测试实验
2.3.1. 彩色语谱图实验
2.3.2. 学习率对比实验
2.3.3. 样本对比实验
2.3.4. 全连接层输出节点对比实验
2.3.5. 激活函数对比实验
2.3.6. CNN模型参数设置
2.4. 基于SVM、BP神经网络和CNN的语谱图分类实验
-
本文在机器学习框架系统Tensorflow上搭建了一个包含7个卷积层和2个全连接层的卷积神经网络模型,并完成了普米语孤立词语谱图的分类实验.通过不同样本比例、不同学习率、不同激活函数、不同输出节点数等的对比实验,分析各项因素对分类准确率的影响,得到模型适当的参数.在此基础上,分别对卷积神经网络、SVM和BP神经网络的实验结果进行比较,判断卷积神经网络模型的性能.
实验表明,在基于卷积神经网络的普米语语谱图分类实验中,分类准确率受学习率、激活函数、同一类训练样本与测试样本比例等因素的影响,但通过模型的训练,可找到适当的参数,对模型参数进行调整.相比于SVM和BP神经网络,卷积神经网络的性能较好,对普米语孤立词语谱图的分类是有效的.通过实验分析各项因素对分类准确率的影响,从而得到了适当的参数并在训练好的模型上进行普米语孤立词语谱图的分类实验.