


 下载:
下载:

-
开放科学(资源服务)标识码(OSID):

-
烤烟等级识别在烤烟生产和贸易中具有重要意义。烤烟是用于制造烟草制品(如香烟、雪茄)的原材料,其质量和特性直接影响最终产品的口感、气味和吸引力。在现行的国家标准《烤烟》(GB 2635—1992)[1]中,根据部位、颜色和级别将烤烟分为3等42级。烤烟等级识别是对烤烟质量的评估,通常基于烤烟的外观、颜色、大小、形状、叶片均匀性以及烟叶中的糖分、尼古丁和其他化学成分等因素[2],而识别的准确性直接影响分拣与分类的精度和效率以及价格的确定。
烤烟等级识别作为烟草产业的关键环节,吸引了大量研究者的兴趣。在过去几十年里,研究者们通过3种不同的方法和技术[3],探索了烤烟等级识别精度的影响因素。①基于化学成分分析[4-5]。研究者们通过色谱分析、质谱技术等手段,研究烟叶中的糖分、尼古丁、挥发性化合物等成分的含量和变化规律。这些研究揭示了不同等级烤烟之间的化学成分差异,为合理分级提供了科学依据。②基于数据挖掘和模式识别[6]等现代信息技术。研究者们利用大数据分析、机器学习和人工智能技术[7],从大量的烤烟数据中挖掘出有关烤烟等级的隐藏规律。③基于外观特性分析[8-9]。研究者们利用计算机视觉技术、图像分析和机器学习算法,检测叶片颜色、纹理、大小和完整性等特征,从而快速、准确地判断烤烟的等级。总之,这些方法不仅提高了烤烟等级识别的准确性,还为决策制定和质量控制提供了科学支持[3, 10-11]。
在近10年的研究中,李海杰[12]构建了5层人工神经网络(ANN)对7种等级烤烟进行分类分级方法研究,验证准确率为80%;曾祥云[13]采用AlexNet卷积神经网络构建了烤烟质量分类模型,5种等级验证准确率为78%;随着可分离卷积理论的提出,王士鑫等[14]采用Inception V3卷积神经网络并运用迁移学习方法构建分类模型,12种等级下的验证准确率为95.23%;陈鹏羽等[15]使用特征融合方法改进WSDAN网络得到5种等级验证准确率为91.261%;Swasono等[16]将ResNet模型进行剪枝然后添加额外降维层构建模型,4类烟草病害的验证准确率为99.3%。虽然以上研究使该领域得到工业应用成为可能,但仍然存在2个主要局限。①识别分类的种类较少。烤烟总共有42个等级,而之前算法最高识别种类仅有12类。②算法冗余度较高。烤烟等级识别应用是流水线作业,需要算法识别快、准确率高,高冗余度的算法意味着高延迟,因此难以应用。据研究,之前算法局限的原因在于它们对烤烟图像的深层特征提取不足[17],因此为了实现烤烟自动分级的工业应用,增强算法深层特征提取能力是解决问题的关键。
近年来,ShuffleNet系列网络因其具有高轻量化特点和较强的深层特征提取能力,受到研究者们广泛关注[18],目前已在多项基于农产品分类的项目中得到应用[19-20]。而对于烤烟识别领域所面临的问题,运用ShuffleNet系列网络可以有效解决。本研究基于该领域所面临的问题,结合深度学习技术,采用分类算法中的ShuffleNetV2网络实现烤烟等级分类,并结合实际图像特征进一步改进算法,最终提升了该算法在该领域的检测性能,为实现烤烟自动分级从而提高烤烟收购效率和卷烟生产质量提供了一种新方法。
全文HTML
-
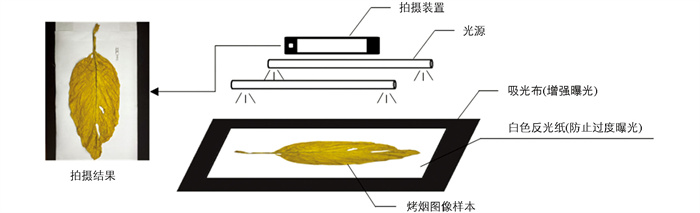
试验使用iPhone 11手机相机(分辨率为3 024×4 032)采集山东、云南等烟草园区的烤烟图像样本。光源信息:电压AC 110~265 V,功率15 W,色温正白,长度0.9 m。图像样本采集方法和设备如图 1所示,共采集32个等级7 055张图片。
机器视觉识别系统主要由硬件和软件2部分组成[21],其中烤烟图像数据采集一般是由灯源、相机和桌面(模拟传送带)组成[2, 4, 9, 13, 22, 23]。苏明秋[22]改进为桌面铺上吸光布,目的是让烟叶叶身纹路充分展现;鲁梦瑶等[17]改进光源为面光源,目的是让烟叶叶身均匀受光。如图 2所示,本研究试验的烤烟图像采集方法在之前研究的基础上增加了吸光布和反光纸,使烤烟图像的色彩、纹理和轮廓更容易被捕捉;仅在传送带上时,烟叶叶身暗淡,纹路模糊;仅有吸光布时,曝光过度失去颜色信息,但纹理信息显示较好;仅有白色背景时,反光过度曝光不足,导致叶身暗淡,缺少光泽。
-
根据样本数量,试验图像从目前收集的32个等级中选用27种类别构建数据集,其他5种类别数据因数量太少故没有引入试验。为了数据的均衡性,将数据删减或增强后按约6∶2∶2的比例划分为训练集样本2 430张,验证集样本822张,测试集样本822张。具体分类情况如表 1所示。
-
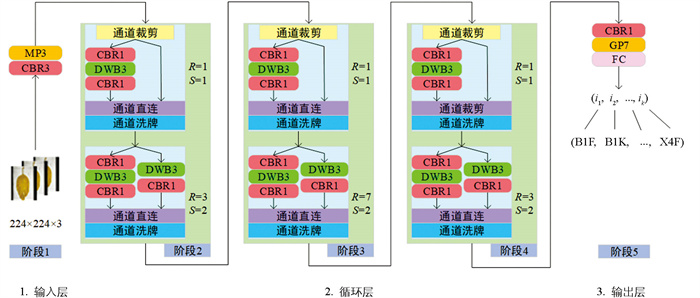
ShuffleNetV2整体的网络架构如图 3所示,主要由输入层、循环层和输出层组成[24]。输入层对图像进行预处理,得到224×224×3大小的RGB图像,然后经过1个CBR3模块(3×3 Conv+BN+ReLU)和1个MP3模块(3×3 MaxPool)后,得到56×56×24的特征矩阵,输入到循环层中。循环层由阶段2、阶段3和阶段4共3个循环结构组成,其中包含了通道裁剪(Channel Split)、若干CBR1模块(1×1 Conv+BN+ReLU)、DWB3模块(3×3 DWConv+BN)、通道直连(Concatenation)和通道洗牌(Channel Shuffle)等结构。“通道裁剪”和“通道直连”分别是将2个特征矩阵按通道维度直接剪切或连接起来;“通道洗牌”是将特征矩阵按通道维度进行打乱。输出层由1个CBR1模块、1个GP7模块(7×7 GlobalPool)和全连接层(FC)组成,最后输出为一个k×1大小的一维向量序列,其中k表示分类数。图 3中R表示循环次数,S表示卷积操作步距。
-
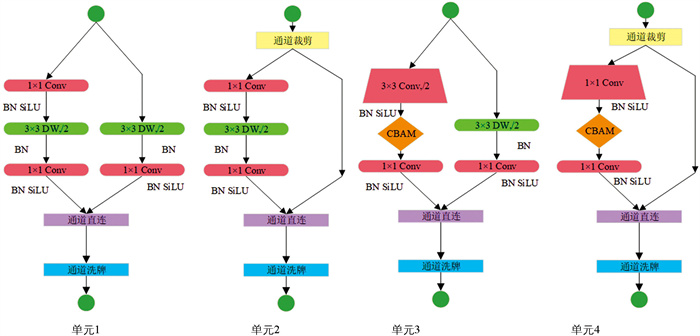
为了提高网络性能,本研究引入CBAM注意力机制[25]和SiLU激活函数[26],并基于ShuffleNetV2网络提出了ShuffleNetV2_FTC(Flue-cured Tobacco Classification,FTC)网络模型。主要改进工作为:①在循环层中,将卷积注意力机制(CBAM)嵌入阶段3和阶段4的循环结构中;②将网络所有激活函数由原来的ReLU改为SiLU[27];③在循环层中,将阶段3和阶段4循环结构中的前2个模块(CBS1:1×1 Conv+BN+SiLU和DWB3)合并为1个模块(CBS3:3×3 Conv+BN+SiLU)。改进后的网络主干单元层结构如图 4所示。
这种修改方式的灵感来自于Tan等[28]的工作,他们在EfficientNet系列网络中使用SE注意力机制,并在每层卷积输入前扩充了中间特征图通道数,而本研究使用的是CBAM注意力机制,没有扩充通道数。注意力机制嵌入位置的选择参考了Howard等[29]的工作,他们提出了MobileNet系列网络。研究表明,在浅层尽量不要使用注意力机制,并且不同深度层使用不同的激活函数。例如MobileNetV3_S中,浅层更多使用的是ReLU,深层更多使用的是H-Swish,但在本研究提出的网络中应用时会导致准确率降低,故没有采用。
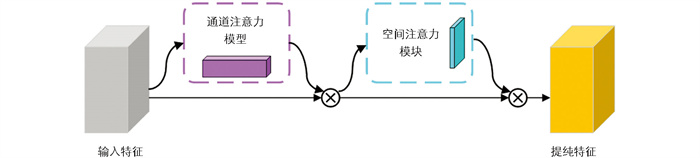
CBAM是一种用于前馈卷积神经网络的通用轻量级注意力模块,它会沿着通道和空间2个维度独立地依次推断注意力特征,然后将注意力特征相乘以进行自适应特征优化[25]。CBAM结构如图 5所示。
CBAM注意力机制由2段组成,前一段是根据3×3卷积层输出结果的一个中间特征矩阵F∈RC×H×W作为通道注意力模块的输入,对输入按通道分别进行全局最大池化(MaxPool)和均值池化(AvgPool),池化后的2个一维向量经过全连接层运算相加,生成一维通道注意力Mc∈RC×1×1,再将通道注意力与输入元素相乘,得到通道注意力调整后的特征图Mc(F),见式(1);后一段将特征图Mc(F)再按空间进行全局最大池化和均值池化,池化后的2个二维向量经过拼接后进行7×7卷积操作,得到二维空间注意力Ms∈R1×H×W,见式(2);最后再与特征图Mc(F)相乘得到结果Mc⊗s(F),继续输往下一层,见式(3)。注意力机制使用前后特征图大小和深度没有变。
通道注意力机制如下式所示:
空间注意力机制如下式所示:
CBAM如下式所示:
其中:σ为Sigmoid函数;MLP为全连接层运算。
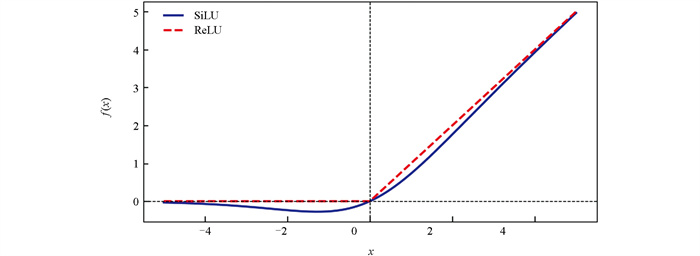
SiLU激活函数是Sigmoid函数的加权线性组合,相对于ReLU激活函数,其能够保留负样本输入信息,这对烤烟图像数据来说很重要。同时,它在接近0时具有更平滑的曲线,并且由于其使用了Sigmoid函数,可以使网络的输出范围在0和1之间,因此使得SiLU在一些应用中比ReLU表现更好(图 6)。
改进后的ShuffleNetV2_FTC网络具体配置如表 2所示,依然有0.5×、1×和1.5× 3种配置。0.5×的输出通道为[24,48,96,192,1 024,27],模型体量为参数量0.81 M,内存占用8.86 M,浮点运算量0.09 G。1×的输出通道为[24,116,232,464,1 024,27],模型体量为参数量3.90 M,内存占用15.05 M,浮点运算量0.44 G。1.5×的输出通道为[24,176,352,704,1 024,27],模型体量为参数量8.59 M,内存占用20.51 M,浮点运算量0.97 G。整体来讲,该模型提高了网络单层的非线性能力,但减少了卷积层层数(CBR1和DWB3合并为CBS3)。
-
在整个训练过程中,先用CIFAR-100数据集训练得到一个预训练权重,然后在训练烤烟等级图像时导入分类网络初始化权重矩阵。优化器统一选用自适应动量的Adam随机优化方法,训练60轮后学习率下降1%,并使用早停机制(Early Stopping)[30]防止过拟合训练。训练停止后,将得到的最优分类权重保存下来。
在测试过程中,首先将最优分类权重加载到分类网络中,然后导入烤烟测试集数据,最后输出烤烟等级识别分类准确率。基本试验参数如表 3所示。
试验环境:AMD锐龙5 4600H处理器搭配Radeon Graphics 3.00 GHz (16 G内存)+ NVIDIA 3060显卡(6 G显存);编程环境:Python 3.6+Pytorch 1.10。
-
对于烤烟等级识别模型使用准确率(Accuracy)、帧率(Frame Rate)、精确率(Precision)、召回率(Recall)、F1分数(F1 Score)等评判标准[17, 20, 31]。
假设:TP为正确标签识别为真的数量;TN为错误标签识别为假的数量;FN为正确标签识别为假的数量;FP为错误标签识别为真的数量[34]。
准确率为所有预测正确的样本占总样本的比例,即:
精确率为正确标签识别为真的样本占全部识别为真的比例,即:
召回率为正确标签识别为真的样本占全部实际为正确的比例,即:
F1分数是精确率和召回率的调和平均,兼顾了模型的精确率和召回率,可以用来衡量模型的准确度,其数值(范围为0~1)越接近1表示模型性能越好。
1.1. 材料与仪器
1.2. 数据划分及预处理
1.3. 烤烟识别模型构建
1.3.1. ShuffleNetV2网络
1.3.2. 改进ShuffleNetV2网络
1.3.3. 模型建立与训练
1.4. 模型评价指标
-
为了验证ShuffleNet系列网络在27类烤烟图像数据集上的效果,分别将ShuffleNetV1[32]、ShuffleNetV2(0.5×)、ShuffleNetV2(1×)和ShuffleNetV2(1.5×)网络导入进行训练,并在测试集上进行测试,试验结果如表 4所示。通过表 4的对比结果可以看出,V2系列在相同的浮点运算量下参数量要大于V1,但测试结果却得到提升,每秒12.3张的帧率完全满足烤烟等级识别工业应用的要求。
同时可以看出V2系列准确率有点偏低,如果能保证检测速度的情况下把准确率提高就更好了。因此本研究选用ShuffleNetV2网络,并在此基础上进行改进,以提升检测准确率。
-
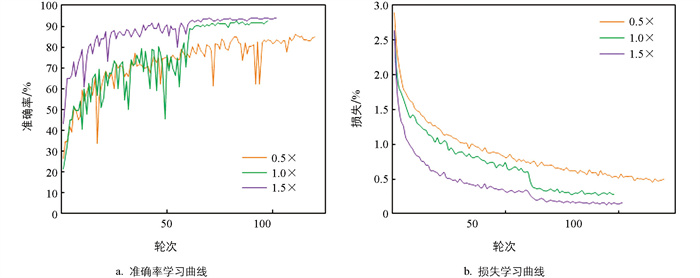
ShuffleNetV2_FTC网络训练过程如图 7所示,左边是验证准确率变化过程,右边是验证损失变化过程。0.5×模型在整个训练过程中耗时120个轮次,1×模型耗时98个轮次,1.5×模型耗时102个轮次。前60轮的训练曲线经历了明显的震荡,但在第60轮调整学习率后,准确率和损失曲线发生了明显变化,之后震荡趋于平稳,这表明学习率的调整对于稳定训练过程和提高性能是有效的。相比之下,在0.5×模型中,调整学习率后,准确率曲线和损失曲线却没有明显突变,这可能表明在初始学习率为0.001时,模型更早地接近拟合终点,不需要额外的轮次和学习率调整来稳定性能。最终,1.5×模型取得了更高的验证准确率(93.88%)和更低的验证损失值(0.131 8)。
将训练好的最优权重载入ShuffleNetV2_FTC网络,然后导入测试集图像(822张),得到如表 5所示的测试结果。表中的精确率、召回率和F1分数为27类烤烟图像检测的均值。对比可知,改进网络在参数量和计算量上有所牺牲,但降低了内存占用(这将有利于将算法移植到移动设备上),提升了准确率(提升了0.24%(0.5×)、6.06%(1×)和4.73%(1.5×))。帧率也得到了提高(减少模型层数是有必要的),由原来的每秒检测12.3张图片提升到了15.3张。
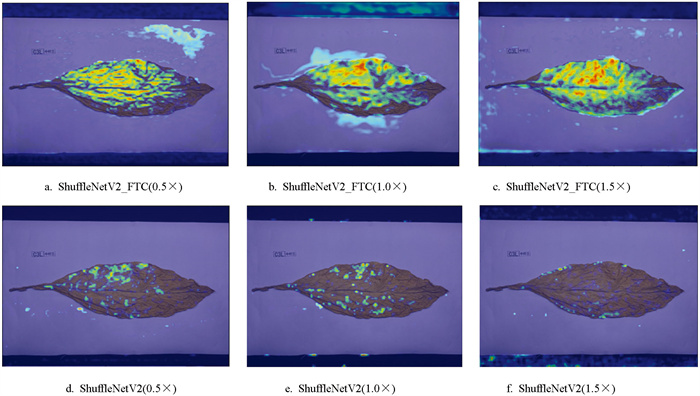
热力图能对模型的分类结果提供很好的可视化依据[33]。如图 8所示,试验展示了测试集中一张烤烟图像(C3L)在改进前后网络识别差异的对比,颜色越深、范围越广表示提取效果越好。在图 8中可以看出,改进网络对烤烟的颜色、形状和纹理信息特征提取能力更好,提取信息重心都在烟叶叶身。而ShuffleNetV2系列网络在烟叶本身提取到的特征无论从深度还是范围上都相对而言逊色于改进网络。
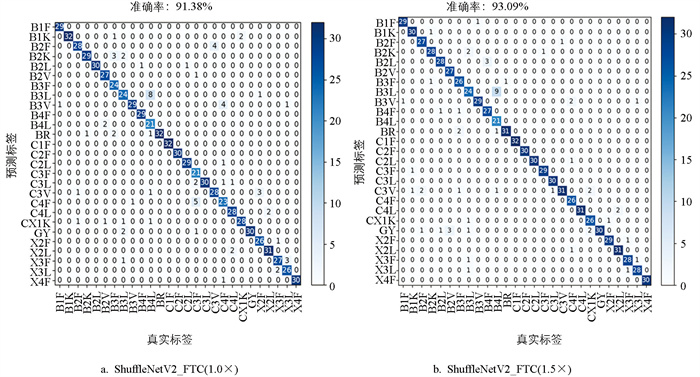
图 9展示了ShuffleNetV2_FTC(1×和1.5×)网络在烤烟测试集上的混淆矩阵图。横坐标表示真实标签,纵坐标表示预测标签,对角线数据占比越大表明分类的效果越好[34]。
从2个矩阵整体来看,各部位叶外(上部叶B、腰叶C、下部叶X)识别少有混淆,各部位叶内(CL系列、CF系列)识别多有混淆,表明相近等级间的识别效果较差,较远等级间的识别较好,和韩东伟等[23]的研究一致。从2个矩阵细节上看,对上杂二(B2K)、中柠二(C2L)、中柠三(C3L)、中柠四(C4L)和下秸二(X2F)类别的识别效果较差,其辨别难度较大,与童德文等[35]的研究一致;对上秸一(B1F)、上杂三(B3K)、中下杂一(CX1K)、中下杂二(CX2K)、下柠二(X2L)、下柠三(X3L)类别的识别效果略好,辨别难度较小,和庄珍珍等[2]的研究一致。
-
表 6展示了不同模型在测试集上的对比。首先从模型评估测试结果来看,ShuffleNetV2_FTC(1.5×)网络有着较好的应用性能。相对其他网络有最好的精确率、召回率、F1分数和准确率,EfficientNetV2_S次之,ResNeXt50[33]和MobileNetV3_S在本测试中表现不理想。
其次从模型体量来看,ShuffleNetV2_FTC(1.5×)网络有着较好的移动端部署性能。MobileNetV3_S有着最低的参数量和最低的浮点运算量;ShuffleNetV2_FTC(1×)有着最低的内存占用量,MobileNetV3_S次之;ShuffleNetV2_FTC整体有着最高的帧率,MobileNetV3_S次之。具体如表 7所示。
最后综合评估ShuffleNetV2_FTC网络具有更好的性能。EfficientNetV2_S虽然有较好的检测结果,但是模型体量太大,且帧率仅有12张图片,相对不适合部署在移动端;MobileNetV3_S虽然有最好的移动设备部署性能,但模型检测结果准确率仅有84.71%;ShuffleNetV2_FTC(1.5×)因较低的内存占用(20.51<50.39)和较高的检测帧率(15.3>14.4)使其综合性能优于MobileNetV3_L。
2.1. ShuffleNet系列网络试验结果
2.2. 改进的ShuffleNetV2网络试验结果
2.3. 多方法评估对比
-
本研究针对烤烟等级识别技术目前所面临的识别种类少和算法冗余度高2大问题,借助深度学习理论和计算机视觉技术,改进ShuffleNetV2网络,构建了ShuffleNetV2_FTC网络。提出的ShuffleNetV2_FTC网络相对于原模型获得了准确率和检测帧率的提升,相对于其他网络有更好的效率。最终改进模型在27类样本下测试准确率为93.09%,检测帧率为每秒15.3张,达到了理想检测效率。同时本研究还引入吸光布和反光纸结合的方式改进数据采集方法,一定程度上避免了图像失真的情况发生。本研究解决烤烟等级识别技术迟迟无法工业应用问题的方法具有普适性,可应用于其他分类识别任务,为后续实现精度和帧率更高更快的农产品分类识别方法提供了参考。在下一步研究计划中,将继续完善类别数据集,建立完整42个等级的烤烟等级识别数据库。