


 下载:
下载:

-
开放科学(资源服务)标识码(OSID):

-
在全球范围内,甲烷(CH4)是影响全球温室效应的一种重要温室气体,其排放带来的增温潜力是二氧化碳的28倍,而反刍动物是甲烷排放的重要贡献者[1]。在我国,牛养殖是畜牧业中甲烷的最大来源之一[2-3]。牛舍内空气质量较差会使动物的呼吸系统产生疾病[4]。饲料在牛消化道中被微生物发酵,会产生甲烷并排出体外。甲烷本身对牛没有任何毒害作用,但牛舍内甲烷量的增大会使氧气相对减少,造成慢性缺氧,同时也会存在引起火灾甚至爆炸的危险[5]。研究发现,通风率、舍内外温度、相对湿度对温室气体浓度均有显著影响[6-8]。因此,监测并控制牛舍甲烷浓度的变化非常重要。
目前,国内外针对畜舍内环境的预测模型主要集中在畜舍二氧化碳和氨气浓度的预测上,对牛舍甲烷浓度预测研究较少。这些模型主要可以分为两大类。一类是基于数理化学统计模型,这类模型通常通过生成原理或影响因素来构建,往往依赖于大量的试验数据支持,其预测性能存在一定的局限性,例如:文献[9]利用肉牛和奶牛的干物质摄入量和营养成分建立了线性和非线性模型来预测甲烷产量;文献[10]和文献[11]通过对不同结构的牛舍建筑进行研究,得到牛舍的温室气体和氨气排放量。这类模型往往比较复杂,而且受畜舍环境、建筑结构等因素的影响。另一类基于机器学习智能算法的预测模型可以解决机理复杂且未知的非线性建模问题[12],相对简单,而且对非线性函数具有良好的拟合能力,例如:文献[13]利用LightGBM-SSA-ELM组合模型结合新疆羊舍的环境数据,对羊舍的二氧化碳进行了准确预测;文献[14]和文献[15]分别构建了SSA-LSTM和LSTM-AT模型来预测温室环境。这类模型能够更好地提取气体浓度特征,同时预测模型精度也高。
通过采集系统采集的牛舍环境数据具有时序性、非线性等特点。门控循环单元(GRU)模型广泛应用于时间序列数据的预测[16-17],解决了传统RNN梯度消失和梯度爆炸的问题,能够提取牛舍采集数据中的非线性关系,关注数据长期依赖的问题,而且训练速度较快。传统的GRU模型在训练过程中往往需要依靠人工经验手动调节参数,其性能受到很大影响。如何选择最佳参数组合以获得更好的预测效果,是GRU预测模型必须解决的问题之一。麻雀搜索算法(SSA)是由文献[18]提出的群智能优化算法,模拟了麻雀群觅食并逃避捕食者的行为。加入混沌序列、混沌扰动和高斯变异的改进麻雀搜索算法(ISSA)解决了SSA算法容易陷入局部最优的问题[19]。BP模型是一种多层前馈神经网络,学习过程包括正向传播和反向传播两部分。网络的第一层为输入层,最后一层为输出层,中间为隐藏层,通过不断调整网络的权重和阈值,使误差达到最小,具有强大的非线性映射能力[20]。
本文使用牛舍环境监测数据作为输入量,通过ISSA算法对GRU模型的超参数进行优化调整,以提升GRU模型的非线性拟合能力,然后融合BP反向传播算法进一步提取ISSA-GRU模型预测残差序列的有用信息,构建ISSA-GRU-BP预测模型,提升模型预测精度,为牛舍甲烷控制提供可行参考。
全文HTML
-
试验数据区域为甘肃省张掖市临泽县的一个试验牛舍(长约36 m,宽约13 m)。舍内饲养了50头6月龄的西门塔尔犊牛(199±1.07 kg,雄性),每天于06:30和14:30饲喂干草苜蓿和补充精料,全天自由饮水。牛舍东南西北四面墙正中各带有一扇3×4 m的大门,东西两面墙带有四扇1×2 m的窗户,对称屋顶有中央脊通风口,全天打开。由连接南北门的一条水泥过道将牛舍分为东西两侧,临近过道为饲喂区。
-
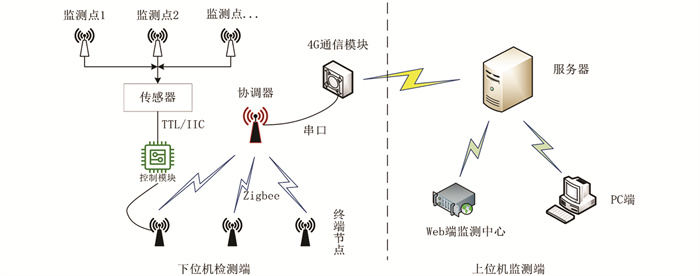
牛舍内安装了基于物联网的牛舍环境实时监测系统,实时获取牛舍主体区域的环境数据并传输至监测平台。系统拓扑架构如图 1所示,系统实物图如图 2所示。该系统以STM32F103控制芯片和Zigbee-CC2530通信芯片为核心,获取牛舍实时的甲烷浓度、舍内温湿度、舍外温湿度和流动风速等数据,数据以1 min为采样间隔进行记录,并通过Modbus协议传输,利用4G模块将采集的信息上传至物联网云平台。
-
将采集的2024年4月29日至2024年6月30日的牛舍环境数据作为试验数据。由于1 h内牛舍环境参数变化不大,将牛舍环境数据以1 min的时间间隔采集后,进行平均化处理,转化为60 min的时间间隔数据,总计生成了1 492组环境数据。
-
考虑到训练数据和测试数据中可能存在缺失部分,为了避免预处理中出现数据分布不一致的问题,本文使用了向前填充、向后填充与均值填充相结合的方式保证填充数据的覆盖率。同时采取拉伊达准则将试验数据中的异常值替换为其相邻数据的平均值。
-
由于牛舍环境中参数量纲和数值量级相差过大,为了消除差异,提高预测精度,按照(1)式对数据进行归一化处理,再对模型预测结果进行反归一化。
式中:Yi为真实值,Ymin为最小值,Ymax为最大值,Yi′为归一化值。
1.1. 试验区域
1.2. 试验数据采集
1.3. 试验数据预处理
1.3.1. 数据处理
1.3.2. 异常数据处理
1.3.3. 数据归一化处理
-
在本试验中,以GRU模型为核心,通过GRU模型的非线性拟合能力对牛舍环境数据中的非线性特征进行提取[21]。随后,采用ISSA算法得到最优的GRU模型超参数组合。最后构建BP模型进一步提取残差数据序列中的特征并进行拟合。最终建立的ISSA-GRU-BP模型充分结合了ISSA算法优化超参数的能力、GRU模型的非线性特征提取能力以及BP模型的拟合性能,显著提高了模型的预测精度。该模型输入为前3h的舍内温度、舍内相对湿度、甲烷浓度、流动风速、舍外温度和舍外相对湿度,输出为1h后的甲烷浓度值。预测模型的基本流程如下:
1) 预处理牛舍环境数据集,将处理后的数据集划分为训练集1、训练集2和测试集,划分比例为70%、20%和10%。
2) 训练集1用于构建GRU模型并进行训练,同时通过ISSA算法寻找GRU模型的最优超参数组合。
3) 在训练集2上使用ISSA-GRU模型进行预测,生成甲烷浓度的实际值与预测值之间的残差序列DCH4。
4) 以残差序列DCH4为基础构建数据集,通过BP模型提取其特征变化规律。
5) 在测试集上对ISSA-GRU-BP模型进行测试,以全面评估其性能表现。
-
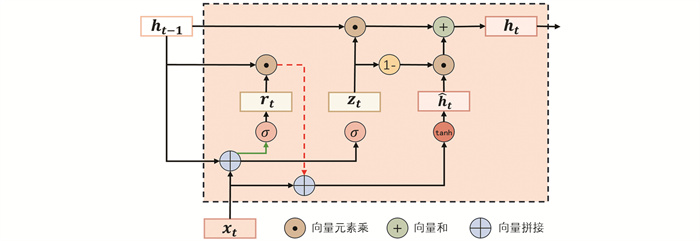
GRU是传统循环神经网络(RNN)的变体,由文献[22]提出。GRU通过使用门控机制有效解决了传统RNN存在的梯度消失和梯度爆炸的问题,相比LSTM,GRU只有两个门单元,即更新门和重置门,提高了训练速度且更能够捕捉长期依赖关系[23]。牛舍甲烷浓度受多种环境因素影响,而采集到的数据具有时序性和非线性的特征,需要通过GRU神经网络模型的非线性拟合能力,提取数据中的非线性特征来预测甲烷浓度变化。GRU神经单元基本结构如图 3所示。
本文构建的GRU神经网络模型由1个输入层、3个隐藏层和1个输出层组成。3个隐藏层子层的神经元数量分别为138、284和565。GRU的每个神经元只包括更新门和重置门两个门,通过更新门和重置门来控制信息的保留和遗忘。
1) 更新门zt
更新门zt决定了当前的隐藏状态应该由上一时刻的隐藏状态保留多少信息,以及由当前输入生成多少新信息,从而捕捉序列数据的短期依赖关系,公式如下:
2) 重置门rt
重置门rt决定了前一时间步的隐藏状态在多大程度上被抛弃,以便更好提取序列数据的长期依赖关系,公式如下:
3) 候选隐藏状态
$ \hat{\boldsymbol{h}}_t$ 候选隐藏状态
$ \hat{\boldsymbol{h}}_t$ 是通过将当前输入和前一隐藏状态结合,经过激活函数得到的潜在隐藏状态,公式如下:4) 最终隐藏状态ht
最终隐藏状态ht是通过更新门对上一时刻的隐藏状态和候选隐藏状态进行加权得到的,公式如下:
式(2)-(5)中,σ是sigmoid激活函数;xt是当前神经元的输入;ht-1是上一个神经元的隐藏状态;Wz、Wr和Wh分别是更新门、重置门和候选隐藏状态的权重矩阵;bz、br和bh分别是更新门、重置门和候选隐藏状态的偏置值。
本文选择均方误差(MSE)作为GRU模型的损失函数,并利用Adam优化器优化权重,以逐步减小误差,获得高精度的预测模型。
-
由于GRU预测模型所需超参数众多,靠人工经验进行调参难度大且费时。通过优化算法对GRU预测模型超参数进行寻优,计算出最优超参数组合,以获得最优的GRU模型。SSA麻雀搜索算法是一种智能群体优化算法,能够快速进行全局搜索并及时收敛[24],但容易陷入局部最优解。而Tent混沌序列具有随机性、遍历性等特点[19],能够显著提升优化算法的寻优性能,同时增加SSA算法种群的多样性,使种群分布更加均匀从而加快收敛速度[25],还可以对局部极值通过混沌扰动扩大搜索空间,并引入高斯变异对原始解周围进行重点搜索,从而使搜索算法跳出局部最优[16]。因此,通过引入Tent混沌序列、混沌扰动和高斯变异得到改进后的麻雀搜索算法。在ISSA算法中,每只麻雀对应一个解,麻雀的数量则表示解的总数。一只麻雀包含所需要优化的超参数,分别为时间窗口、学习率、批量大小、GRU子层每层神经元数量。ISSA算法步骤如下:
1) 使用公式(6)生成Tent混沌序列S并初始化种群,然后将其映射到搜索空间产生解,以增强种群的多样性和分布均匀性
式中:Si,u为种群中第i个个体Si的第u维变量;rand(0,1)为区间[0, 1]内的随机数。
2) 本试验中通过均方误差来计算种群中所有个体的适应度fi,根据适应度来评价个体的优劣,并找到种群当前的全局最优位置Xbest和最差位置Xworst。改进麻雀搜索算法会根据适应度调整种群个体的位置,以逐步逼近全局最优解。
3) 随机选取种群中一定比例的个体作为发现者、捕食者和警戒者。根据适应度值和算法规则分别使用公式(7)、(8)对发现者位置和捕食者位置进行更新,并使用公式(9)对警戒者位置进行更新。
式中:Xi,jt+1表示第i个个体在第t次迭代中的第j维的当前位置;imax为设定的最大迭代次数;α∈(0,1]为一个随机数;R2∈[0, 1]为安全值;ST∈[0.5,1]为警戒值,当R2<ST时,代表当前位置是安全的,发现者可以继续搜索,当R2≥ST时,当前位置被认为存在风险,警戒者发出警报,所有麻雀需要立即更换位置;Q表示服从正态分布的随机数;L用于计算种群的分布情况(一个所有元素均为1的1×u的矩阵)。
式中:XP为当前发现者的最优位置,Xworstt表示第t次迭代时的全局最差位置,C为一个所有元素均为1或-1的1×u矩阵,
$ \boldsymbol{C}^{+}=\boldsymbol{C}^{\mathrm{T}}\left(\boldsymbol{C} \boldsymbol{C}^{\mathrm{T}}\right)^{-1}$ 。式中:Xbestt表示第t次迭代时的全局最优位置;fbest为全局最佳适应度,fi>fbest表明麻雀处于危险位置,fi=fbest表示警戒者发现天敌,所有麻雀需要转移到安全区域;β为步长控制参数(服从均值为0、方差为1的正态分布的随机数);K为(-1,1)上的随机数,用来确定麻雀移动的方向;fworst表示全局最差适应度;ε表示一个无限接近0的常数,用于避免分母为0,并在每次迭代中更新。
4) 每完成一轮迭代后,需要计算当前迭代的最小适应度,以及GRU模型超参数寻优后的结果,更新全局最优位置Xbest和最差位置Xworst,并重新计算调整后种群适应度值。
5) 当个体的适应度值fi小于种群的平均适应度favg时,使用公式(10)通过高斯扰动对较优的解进行局部优化,探索其周围的解空间并进一步寻找当前最优解,然后将变异后的解和原始解进行比较,保留适应度最优的解。
式中:Xit为当前个体位置;Xbestt为当前全局最优位置;α为学习因子,控制个体向最优解靠近的程度;β为随机因子,控制高斯扰动的幅度;N(0,σ2)表示均值为0、方差为σ2的高斯分布随机数。
6) 在种群更新后,可以确定当前的全局最优适应度及其对应的最优位置。一旦达到预设的最大迭代次数则停止运行;否则继续重复执行步骤3)。
-
尽管ISSA-GRU模型显著提高了fi≥favg甲烷浓度预测的精度,但在对训练集2进行预测时生成的残差序列DCH4仍然具有一定的特征,可以进一步提取。而BP神经网络具有较强的拟合能力,通过残差序列构建的数据集建立BP模型并进行迭代,从而进一步提高预测模型的精度。
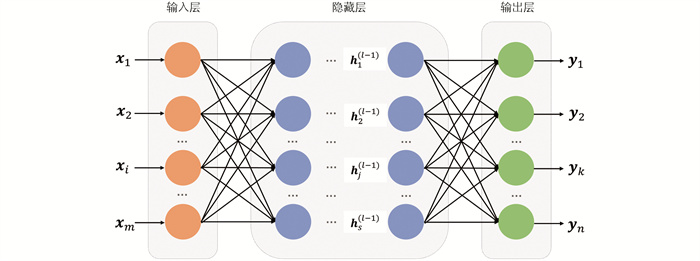
BP神经网络(Back Propagation Neural Network)是一种多层前馈神经网络,由输入层、隐含层和输出层3部分构成[26](图 3)。BP的核心机制包含两个步骤:输入信号的正向传递与误差的反向传递,用于持续优化网络中的权重和偏置。在正向传递过程中,输入的样本数据依次通过隐含层并传递至输出层,生成对应的输出结果。当预测结果与真实结果存在偏差时,模型进入误差的反向传递阶段[27]。反向传递将输出误差逐层反传至输入层,并依据每一层接收到的误差调整网络的权重和阈值,直至误差最终收敛[28-29]。计算过程如下[30]:
1) 前向传播
加权求和与激活函数的计算公式如下所示:
式中:zi(l)表示第l层中第i个神经元的加权输入;wij(l)为连接第(l-1)层第j个神经元到第l层第i个神经元的权重;aj(l-1)表示第(l-1)层第j个神经元的输出值(即激活值);bi(l)为第l层第i个神经元的偏置;ai(l)为第l层第i个神经元的输出值;f代表激活函数。
2) 反向传播
输出层误差计算公式如下所示:
式中:δk(L)为输出层第k个神经元的误差;ak(L)为输出层第k个神经元的预测输出值;yk为目标值;L表示输出层。
隐藏层的误差计算公式如下所示:
式中:δi(l)表示第l层第i个神经元的误差;δk(l+1)为第(l+1)层第k个神经元的误差;wki(l+1)为连接第l层第i个神经元到第(l+1)层第k个神经元的权重;f′(zi(l))为激活函数f对zi(l)的导数;zi(l)为第l层第i个神经元的加权输入。
权重更新和偏置更新计算公式如下所示:
式中:wij(l)表示连接第(l-1)层第j个神经元到第l层第i个神经元的权重;η代表学习率,用于控制梯度下降的步长;δi(l)为第l层第i个神经元的误差;aj(l-1)为第(l-1)层第j个神经元的激活值;bi(l)为第l层第i个神经元的偏置。
-
为对本文建立的ISSA-GRU-BP牛舍甲烷浓度预测模型及对比模型进行评价,本文使用均方根误差(RMSE)、平均绝对百分比误差(MAPE)和决定系数(R2)作为评价指标。
-
本文模型开发环境为AMD EPYC 9754处理器,Nvidia RTX4090D显卡,Windows 11操作系统,python 3.7编程语言,Anaconda 3集成开发环境,Keras框架和SKlearn框架组合。
2.1. GRU门控循环神经网络
2.2. ISSA改进麻雀搜索算法
2.3. BP反向传播算法
2.4. 模型评价指标
2.5. 试验环境
-
选取2024年4月29日至2024年6月30日的牛舍环境数据作为试验数据,统计结果如表 1所示。牛舍内甲烷浓度受到多种环境因素的影响,将这些环境因素作为外部因素融入甲烷浓度预测模型,有助于模型更全面地学习预测目标与环境变量之间的关系,提升模型预测精度。对环境因素做Pearson's系数相关性分析,结果如表 2所示。
牛舍内甲烷浓度与舍内外湿度具有正相关性,舍内湿度相关系数为0.53,舍外湿度相关系数为0.36;甲烷浓度与舍内温度、舍外温度、流动风速呈负相关,相关系数分别为-0.78、-0.62和-0.47。相关性结果表明牛舍甲烷浓度与牛舍环境因素具有相关性,构建模型时加入这些因素可以使模型更好地学习预测目标与环境因素的关系,提升模型预测精度。因此,本文选取舍外温度、舍外相对湿度、舍内温度、舍内相对湿度和流动风速作为牛舍甲烷浓度的外部影响因素。
-
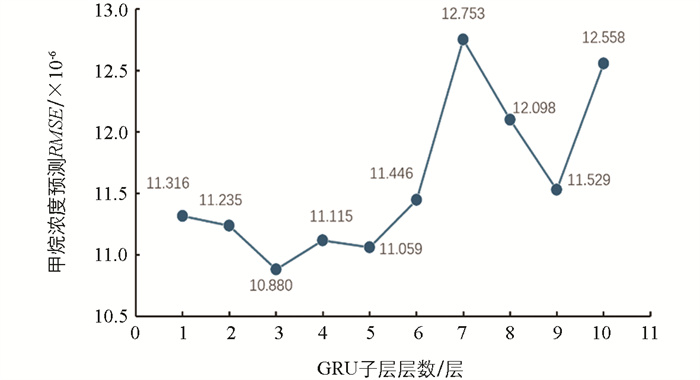
为了提高甲烷浓度预测模型的精度,将ISSA、GRU和BP模型有机结合,构建基于ISSA-GRU-BP的牛舍甲烷浓度预测模型,首先应通过预试验确定GRU子层的层数,以便于使用ISSA算法对建立的GRU模型超参数进行寻优。从1层到10层依次测试,当GRU子层层数为3时,甲烷浓度预测的RMSE最小,为10.880×10-6,所以在本试验中将GRU子层数目设置为3。试验结果如图 5所示。
在确定GRU子层层数后,通过ISSA算法对GRU神经网络的6个超参数进行寻优,得到最优的GRU模型超参数组合,寻优范围为:时间窗口1~10、学习率0.0001~0.001、批数目32~300、GRU每层神经元个数1~600。在GRU神经网络模型优化过程中,要对ISSA算法的参数进行设置,以达到算法的理想状态[16, 19, 25],参数设置为:种群数15,最大迭代次数50,发现者比例80%,警戒者比例20%,预警值0.8。GRU模型的超参数优化范围和优化结果如表 3所示。
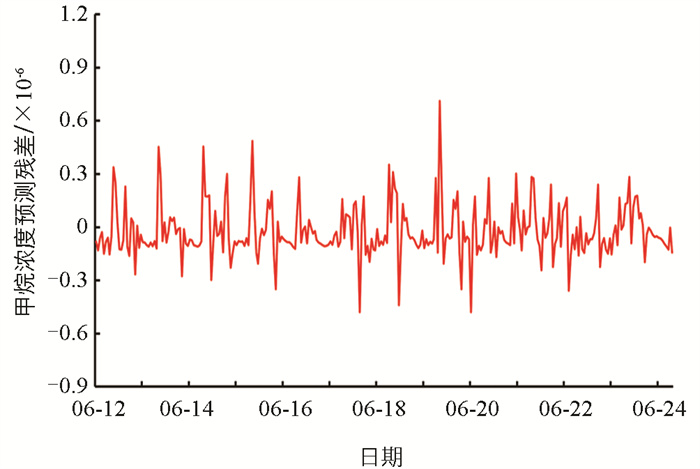
通过ISSA算法对GRU模型的超参数进行寻优后,用ISSA-GRU预测模型对训练集2进行预测,得到甲烷浓度的实际值与预测值之间的残差序列DCH4,残差序列如图 6所示。
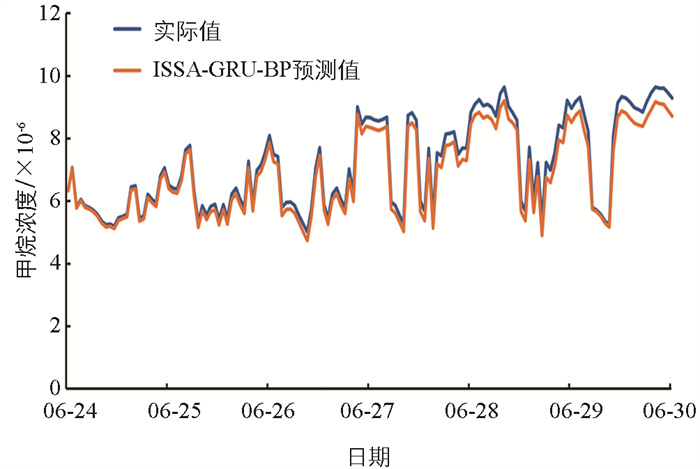
将残差序列DCH4作为数据集,用于构建BP模型,以进一步提取ISSA-GRU模型生成的残差序列特征。随后,在测试集上对构建的ISSA-GRU-BP模型进行精度评估。通过图 7可以看出,ISSA-GRU-BP模型预测的牛舍甲烷浓度值变化趋势与实际值的变化趋势非常接近,预测值与实际值的波动范围和变化模式基本一致,误差较小,表明模型能够很好地捕捉甲烷浓度的变化特征。在少数时间点(例如峰值或快速下降的区域),预测值与实际值之间存在轻微的偏差,但总体来看误差较小,对模型的整体预测精度影响不大。甲烷浓度随着时间变化呈现一定的波动性。ISSA-GRU-BP模型能够较好地跟随这种动态变化,适合处理非线性且时序性明显的数据。这也表明,模型能优化GRU非线性拟合能力,且在利用BP提取残差特征方面也有较好效果。
-
为验证本文模型的预测效果,将BP、GRU、GRU-BP、SSA-GRU、ISSA-GRU、ISSA-GRU-ARIMA与本文提出的ISSA-GRU-BP预测模型进行对比试验。不同模型相同模块参数设置相同。试验结果如表 4所示。
由表 4可见,本文所构建的ISSA-GRU-BP预测模型精度最优,甲烷浓度预测的R2、RMSE和MAPE分别为0.934、0.899×10-6和9.638%,说明通过改进麻雀搜索算法ISSA优化GRU模型来提取牛舍环境因子的非线性特征并通过BP神经网络模型进行拟合可以提高模型的预测精度。
3.1. 牛舍环境数据及相关性分析
3.2. 试验过程
3.3. 不同模型预测结果对比分析
-
采用ISSA算法对GRU模型的超参数进行优化,增强了GRU模型的非线性拟合能力,从而有效提升了甲烷浓度预测模型的精度。试验证明,本文提出的ISSA-GRU-BP模型能够有效拟合牛舍多环境参数,提高甲烷浓度预测,预测精度高于GRU、BP等模型,为牛群生长环境改善提供了新的思路和方法。
未来可以增加数据样本量和时间跨度,涵盖更多的季节变化和极端气候条件,以提高模型的泛化能力,并可以进一步加入其他影响因素,例如饲料成分、牛舍通风方式、气压等,以提升模型对复杂关系的捕捉能力。