


 下载:
下载:



-
随着云计算的发展,用于不同领域的多媒体数据库中产生了越来越大量的图像、视频和声音等数据[1-2],为了快速访问这些数据,必须对所有这些数据进行索引,索引图像[3-4]代表与计算机视觉有关的各种领域的必要工具,如视频监控和运动分析,索引过程成为与大数据领域相关的热点问题[5].对于大型数据库内图像,通常提取高维特征来精确描述图像内容,如果直接处理这些高维数据,可能会导致维度灾难问题,降低了索引算法的性能[6].
大规模图像检索是有效利用大数据的关键技术领域之一,基于内容的图像检索[7]已经成为流行的方法,该类方法通过图像处理和计算机视觉算法自动检测和提取图像的视觉特征(全局和局部特征),然后与存储在数据库中的一组图像特征进行比较.最后向用户显示和查询具有相似特征的图像列表.在我们的案例中,结果是与查询具有相似功能的视频列表,降维是用于克服这些问题的有效方法之一.文献[8]中提出一种基于矩阵指数嵌入来推断高维数据低维表示的降维框架,在该框架中矩阵指数可以通过特征相似度矩阵上的随机游走来粗略解释,并且因此更加鲁棒.文献[9]中提出两种k均值聚类的降维方法,一种是基于随机投影的k均值聚类降维方法,另外一种是基于奇异值的降维方法,两种方法都能够准确特征提取,并且降低了时间复杂度.另外还有其他方式用于降维,如线性判别分析(Linear Discriminant Analysis,LDA),支持向量机(Support Vector Machine,SVM)等方法.
目前对于图像检索的研究正在进行,文献[10]中提出了一种针对大数据设计的快速图像检索方法,该方法首先针对每个图像获得特征向量,之后编码图像特征向量并将它们放入数据库,这可以优化特征结构,最后,使用相应的相似性匹配来确定检索结果.文献[11]中提出了针对大规模图像数据库中基于尺度不变特征变换(Scale Invariant Feature Transform,SIFT)特征和基于内容的图像检索方法,该系统从每个原始图像中提取SIFT特征向量,根据视觉相似性计算结果将视觉相似的图像返回给用户,其创新之处在于引入SIFT描述符来表示图像的可视内容,然后利用距离比作为阈值来控制匹配特征点的个数.文献[12]提出了一种新的基于内容的图像检索方法,改进可扩展词汇树图像检索方法,解决了传统基于内容的图像检索技术通过特征向量来表达每幅图像在大规模图像检索中的精度和时间问题.
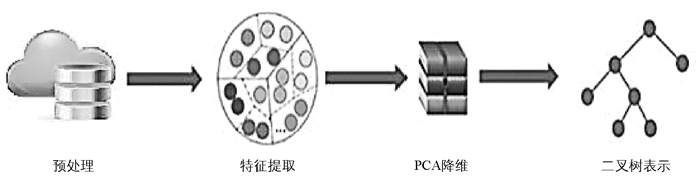
本文在研究了已有图像检索方法的基础上,针对大规模图像数据库检索中的特征维度灾难,以及搜索时间长的问题,提出了一种高效率的大数据数据库图像索引方法.该方法首先将SIFT和加速鲁棒特征(Speeded up Robust Features,SURF)提取为图像特征,然后采用PCA降维方法来减小这些特征的尺寸,最后,提出了一种基于二叉树的图像存储结构表示方法,以加快索引时间.
全文HTML
-
本文方法的主要目标是在系统中对图像进行索引,允许用户对一组图像进行研究.本文方法分为3个阶段,第1阶段是特征提取;第2阶段是应用PCA作为降维方法来减少特征维数;最后是二值树的生成,中值是SIFT和SURF特征的每个节点.本文方法总体结构如图 1所示.
-
首先,将高斯模糊应用于所有图像,以减少SIFT或SURF应用于这些图像时的关键点数量,在实验中应用了几个过滤器,实验表明SIFT和SURF的最佳滤镜是高斯模糊,高斯模糊是一种图像模糊过滤器,使用高斯函数来计算应用于图像中每个像素的变换,一维高斯函数的方程为
其中,x是在水平轴上与原点的距离,σ为高斯分布标准差,公式(1)用正态分布计算每个像素的变换.对于二维空间,每个维度都有一个
其中,x是在水平轴上与原点的距离,y是垂直轴上与原点的距离,σ为高斯分布标准差.算法1中显示了这个预处理过程.
Pretreatment:jpeg file:Set of images;
Ø→jpeg_file;
ReadNb - images_i;
forj:1 to Nb -images do
Get Current Image(j) → image_j;
GaussianBlur (image_j) →image_GBj;
jpeg_file∪image_GBj→ jpeg_file;
end for
return jpeg_file;
算法1接受一组图像作为输入,计算每个图像的高斯模糊并存储这些图像,这个输出将被用作下一步的输入.
-
在特征提取阶段,本文使用SIFT和SURF描述符,描述符允许提取兴趣点图像.尽管SIFT和SURF描述符的工作方式不同,但这2种情况下的输出都提供了兴趣点周围的邻域表示作为描述符向量,描述符向量可以比较或匹配从其他图像提取的描述符.在本文中使用OpenCV作为库,并使用一些函数来计算SIFT描述符,本文采用的SIFT描述符是n×128矩阵. SURF描述符基于SIFT描述符,本文应用的SURF描述符是n×64矩阵.
为了在SIFT和SURF特征之间进行比较,需要在几个度量标准中定义一个相似度量度:FLANN匹配器和Brute-Force匹配器.
FLANN是快速最近邻搜索包(Fast_Library_for_Approximate_Nearest_Neighbors,FLANN)的简称,它是一个对大数据集和高维特征进行最近邻搜索算法的集合,而且这些算法都已经被优化过了.对于大型数据集,此度量比Brute-Force Matcher快,经验证FLANN比其他的最近邻搜索软件快10倍. FLANN度量使用分层k均值树进行通用特征匹配,这使得SURF具有固有的优势,因为二元特征不易扩展到分层K均值. 图 2显示了带有SURF描述符的基于FLANN的匹配器.
Brute-Force匹配器是使用SIFT特征描述符进行图像比较更简单的方法.它首先采用一个特征描述符,并通过使用一些距离计算将它与第2组中的所有其他特征进行匹配,并返回最接近的特征. 图 3显示了与SIFT描述符的强力匹配.
-
无监督和有监督方法都可以应用于减少图像特征尺寸,在本文中使用降维方法PCA. PCA是基于各种方程的数学程序.首先,按照等式计算协方差矩阵(3)和(4).
其中,x1,x2,…,xn是一组N维的特征值,u是所有图像特征的均值,然后可以按照式(5)计算WPCA.
本文已经提出应用PCA降维10%~90%的范围.使用Ncompression=128-(N×128/100)来计算SIFT的压缩维度,Ncompression=64-(N×64/100)来计算SURF的压缩维度,其中N在10~90之间.
-
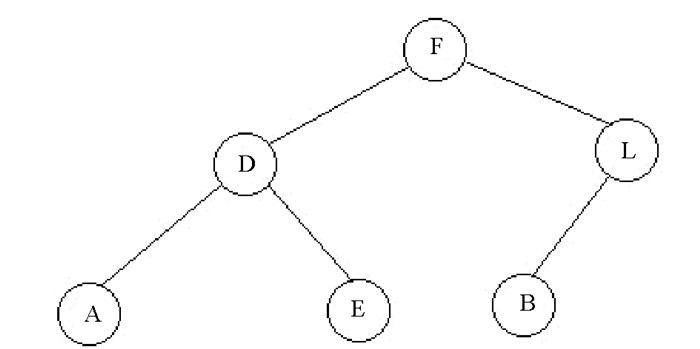
在这一阶段中,本文选择了二叉树作为上一步生成压缩图像的存储结构.这种结构能够加速更多的研究阶段,因为它与其他结构相比是最简单的结构,即使在实现层面,二叉树也可以用简单数组表示,并且数组的操作非常简单快捷. 图 4给出了二叉树的一个例子.
左侧的所有节点都小于根节点,右侧的所有节点都大于根节点.在二叉树中,通常节点具有无法在它们之间进行比较的值,但在本文方法中用矩阵表示SIFT或SURF特征,并且可以在2个矩阵之间进行比较,所以本文提出了一种算法,能够在2个矩阵之间进行比较.为了比较两个SIFT或SURF特征,本文使用相似性度量,结果是[0 1]之间的正常值,定义了两个度量区间[0 0.5]和[0.6 1],分别表示低于根节点的每个节点区间和高于根节点的每个节点区间.在算法2中给出详细步骤.
Algorithm 2 Binary_Tree_Generation(S_Features)
Require:S_Features:Set of features;
Ensure:Table_Root:Table contains the position of the nodes.
root ←random(features);
root →Table_Root;
Ø→Features_Left;
Ø→Features_Right;
length(S_Features)→Nb -features;
if Nb - features = 1 then
for i:1 to Nb - features do
if (feature_i≠root) then
Distance (feature_i,root)→Dist;
if (Dist≤0.5) then
Features_Left ∪ feature_i →
Features_Left;
else
Features_ Right ∪ feature_i →
Features_ Right;
end if
end if
end for
Binary_Tree_Generation(Features_Left);
Binary_Tree_Generation(Features_Right);
else
Break;
end if
return Table_Root;
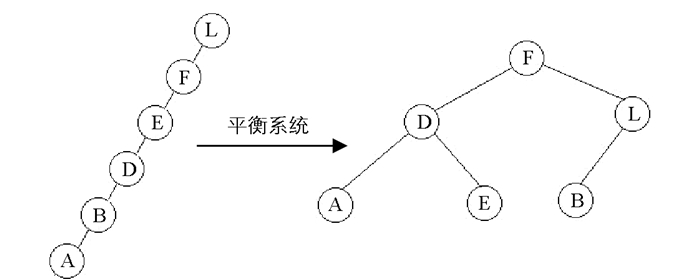
在算法2中,选择一个具有随机函数的根,通过使用相似性度量之一来计算根和特征i之间的距离,然后决定是否将该功能置于左侧或右侧.应用算法2直到获得完整的二叉树,二叉树的一个限制是所有节点都在左侧或右侧,在这种情况下,有必要平衡如图 5所示的二叉树.
已经通过实验方法应用了平衡系统,并获得最佳结果.
1.1. 预处理阶段
1.2. 特征提取阶段
1.3. 降维阶段
1.4. 图像存储结构阶段
-
在机器学习中,ROC(Receiver Operator Characteristic)曲线被广泛应用于二分类问题中来评估分类器的可信度,但是当处理一些高度不均衡的数据集时,PR(Precision-Recall)曲线能表现出更多的信息.为了评估本文方法,本次实验使用精确率/召回率作为评价指标,精确率/召回率公式见式(6)和式(7).
其中,TP表示把正类预测为正类,FN表示把正类预测为负类,FP表示把负类预测为正类.
为了对比各种降维方法对大数据数据库图像检索性能的影响,本文使用名为MIR Flickr图像数据集进行实验,该数据集包含100万张图像,运行环境为云(Ubuntu)和UMONS集群上的操作系统.
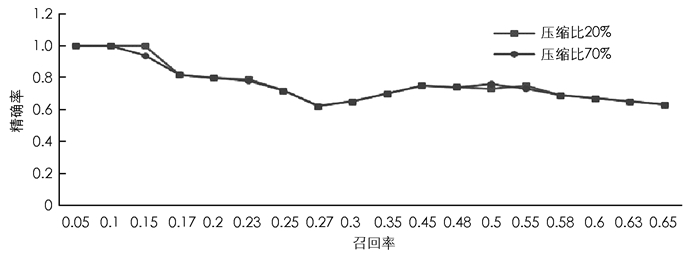
图 6显示了使用不同压缩比(20%和70%)时精确率/召回率度量的演变.
从图 6中可以得到,使用70%的压缩比可以与使用20%的压缩比获得几乎相同的PR曲线.因此,本文方法的压缩不会对精度产生负面影响,这种压缩对于减少计算时间非常有效.
图 7比较了本文方法与不使用二叉树搜索方法的搜索时间,基于二叉树的方法获得索引时间更少,时间减少30%~50%. PCA+SURF特征存储需要较低的空间,且搜索用时最少,仅为69 s,因为SURF索引的比例在70%以内,这个比例(70%)所需的存储空间是使用20%压缩时所需空间的一半.
-
针对大数据数据库图像索引维度和时间问题,本文提出了基于PCA-二叉树的大规模图像索引方法,通过应用PCA和二叉树表示数据来显示和评估通过不同策略在大规模图像中降维获得的实验结果.实验结果表明,与20%的压缩比相比,70%的压缩比得到的PR曲线几乎相同,因为本文方法在索引时间和存储空间2个方面都有所提升.此外,与传统图像索引方法比较,本文方法能够减少索引时间,最高减少50%.在接下来的工作中,计划通过使用Hadoop和HDFS作为分布式文件系统和MapReduce作为编程模型来改进本文方法,以便在数据增加时应用并行化处理.