


 下载:
下载:
-
随着我国经济的快速发展和各种科学技术的不断升级,农业生产和经营进入了一个前所未有的崭新时代[1].一方面,农业生产和经营中的科技含量不断提高,出现了大量的物联网农业基地[2];另一方面,农业生产和经营中的数据量不断增大,既包括了农作物的生长信息,也包括了各类仪器给出的监测信息[3].在这样的自动化、智能化背景下,如何从海量的数据中为农业生产和经营挖掘出有效的信息,是一个亟待解决的关键问题.借助互联网技术为农业生产和经营构建一个综合数据信息平台,实现对农业数据的多点实时采集、存储和处理,进而采用数据挖掘算法从海量数据中提取出对后续生产和经营的有效数据,是解决此问题的关键所在[4].从全球范围来看,基于数据挖掘技术的平台建设已经有了多年的历史.早在20世纪90年代,就先后出现了Salford系统、DB Miner系统[5-6],数据挖掘算法当时普遍采用了基于关联规则的算法,用于对数据的整理、过滤、提取和挖掘[7].进入21世纪以后,数据挖掘平台开始向第4代演进,出现了SPSS Clementine系统,挖掘算法也出现了决策树算法、预测算法等更为先进的算法[8-9].基于互联网+数据挖掘的数据平台,在农业领域中也有了一定程度的应用,如农业环境监测、土壤侵蚀监测、农业生产过程监测等等.在农业数据挖掘算法上,关联分析、聚类分析、决策树分析、粗糙集理论被广泛采用[10-12].在本文的研究工作中,将依托互联网进行农业数据平台的体系结构设计,进而设计更具针对性的数据挖掘算法,再通过实验加以验证平台的设计效果.
全文HTML
-
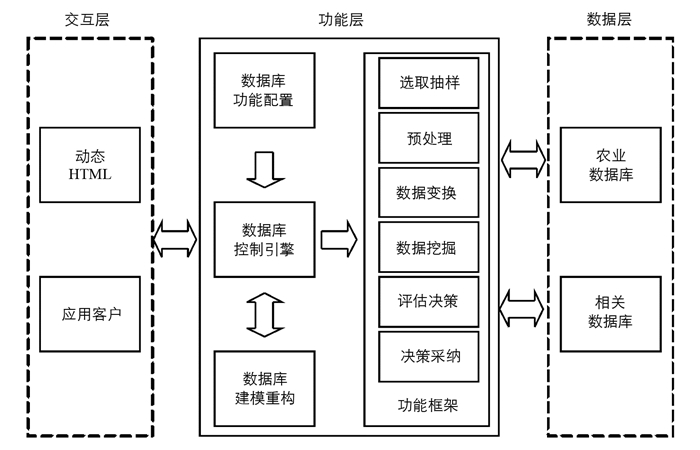
根据网络构成的体系结构,基于网络协议的平台设计大多是层次结构,包含了应用层、表示层、传输层、协议层、数据层等等.从网络构成的层次结构理论出发,为了实现农业数据平台设计,实现平台上的数据采集、数据存储、数据挖掘、各网点交互、用户使用等功能,本文给出了一种3层次的框架设计,如图 1所示.
第1个层次为交互层,主要包括了农业数据采集、处理、挖掘的可视化结果展示,对用户功能的响应,各节点之间网络信息传输功能的实现.这个层次的设计,主要依据HTML(Hyper Text Markup Language)动态网页技术和数据可视化技术.
第2个层次为功能层,是与农业数据处理相关的各种功能设计.结构功能包括数据库的功能配置、数据库的控制引擎、数据库的建模重构.具体功能包括农业数据选取抽样、农业数据预处理、农业数据变换、农业数据挖掘、挖掘结果评估决策及决策采纳.
第3个层次为数据层,主要负责对数据库的管理.这里涉及到的数据库包括农业数据库、相关数据库.其中,农业数据库负责存放农业生产和经营的相关数据,相关数据库则存放各种相关的仪器设备信息及其他有关材料的信息等.
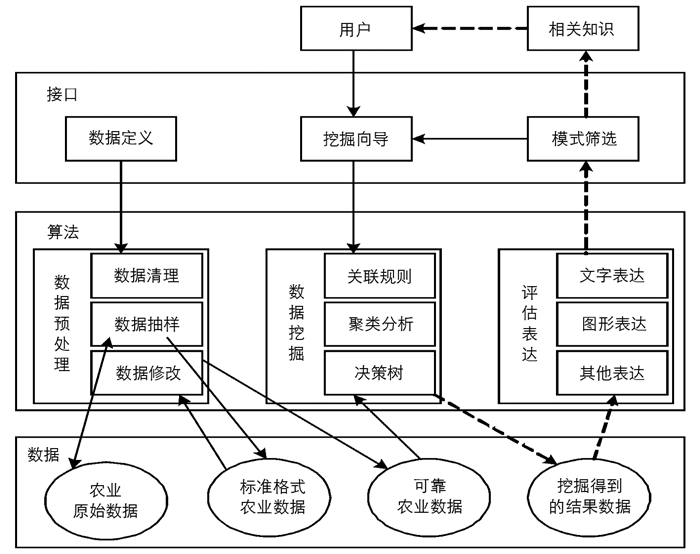
在这个平台下,整个数据挖掘工作的运行机理如图 2所示.
首先,做好数据准备工作,包括农业数据库构建、对数据库中数据进行抽样修改和定期清理更新.其次,用户向平台发起数据挖掘的具体需求,通过挖掘向导关联到具体的挖掘模块,平台开始执行相关的挖掘算法.再次,平台根据挖掘算法得到的结果向用户提供评估结果,同时根据不同的表达形式在平台上完成相应的列表展示或者图形展示.
-
数据挖掘是整个农业数据平台设计的核心功能,也是本文设计中的一个关键工作.从已经出现的数据挖掘方法来看,Apriori算法是一种非常常见的方法,不仅原理简单,而且易于编程实现,同时具有较高的挖掘效率.
但是,在实际应用中Apriori算法也表现出一些问题,主要有:①Apriori算法的挖掘过程中会形成一个较大规模的候选集合;②Apriori算法需要对被处理的数据执行多次扫描;③Apriori算法中的部分关联规则存在冗余.
为此,本文在Apriori算法的基础上改进以提升其性能,改进后的Apriori算法步骤如下:
第1步,对农业数据库中的数据进行全扫描处理,从而确定出不含重复数据的候选数据集合.为了达成比传统Apriori算法更好的效果,此处配置一个累加器,累加器的计数结果作为对候选数据集中候选元素的挖掘频度的支持,进而得到频度集合L1和对应支持度集合C1.
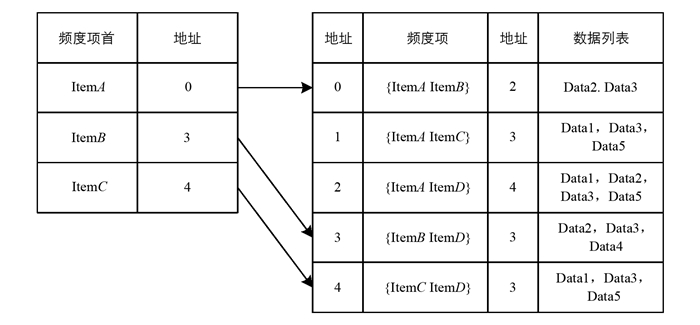
第2步,对频度集合执行自链接处理,从而形成二阶候选频度集合L2和对应支持度集合C2.在这个操作过程中,根据支持度最小剪枝处理原则,所有支持度小于2的数据都将被剔除出考虑范围.为了便于后续查找,为L2配置地址集合A2,如图 3所示.
第3步,不断拓展第2步的处理,进行到第k次时,已经得到频度集合L(k-1)、对应支持度集合C(k-1)、对应地址集合A(k-1).对于本次支持度集合C(k),如果某条数据不满足关联条件,将不再将其纳入L(k).
不断执行上述处理,当C(k)被清空时,挖掘分类执行完毕.
-
为了验证本文设计的农业数据平台和改进的Apriori算法的可用性和有效性,展开如下实验研究.
研究的主要对象为农业作物病虫害问题.对于水稻、棉花等农作物,二化螟是非常常见的虫害.如果能理清二化螟和温度、降水等气候条件的关系,就可以预判出二化螟的爆发节点和规模,从而进行有效的预防,提升水稻产量.
根据二化螟的爆发规律,2月份和5月份的温度和降水条件是非常重要的影响因素,也是本文要分析的主要数据.本文以2001-2018年18年间这2个月份的温度和降水相关数据为研究对象,通过改进Apriori算法挖掘出二化螟与气候条件之间的规律(表 1).上述数据来源于中国农业大数据平台和中国农业信息网,对于数据的统计采用Eviews软件完成.
将上述表格中的数据整理到本文的农业数据平台之下,进而登陆平台进行数据挖掘处理.因为本文的平台尚处于内网应用阶段,因此平台的访问网址为http://192.168.0.1/Agricluture Platform/Data Minning/.
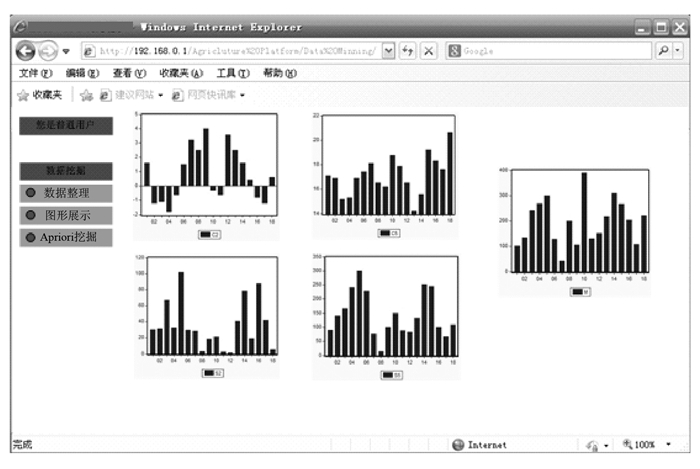
登陆平台后,进入数据挖掘功能,将相关数据进行图形展示的效果如图 4所示.
在图 4中,基于互联网+数据挖掘的农业数据平台可以通过任意浏览器操作,在浏览器上方输入网址即可进入.进入到这个Web界面以后,主视图左侧是一系列的功能菜单,本界面下就包含了用户信息和数据挖掘功能2个菜单.数据挖掘功能菜单下,又包含了数据整理、图形展示、Apriori挖掘3个功能按钮,点击后可以激活各自后台封装的功能函数.主视图的中间区域是数据整理的图形结果和数据挖掘的信息展示区域.
进一步点击Apriori挖掘功能,执行本文的改进Apriori算法,可以得到如下结论:
1) 二化螟爆发规模确实受到气候因素的影响,温度和降水都直接影响二化螟爆发.
2) 从表 1中的四个要素来看,它们对二化螟爆发影响的强弱顺序为5月份的降水最大,其次是5月份的温度,再次是2月份的温度,最后是2月份的降水.
3) 对于5月份降水量而言,当降水量介于75.4~100.6 mm3时,二化螟的爆发量小于151.2万例.这表明降水量越少,二化螟爆发的规模越小.相比之下,2月份的降水对于二化螟爆发的影响,要弱于5月份的降水.当然,这与综合情况有关,因为2月份的温度不适合二化螟爆发.
4) 对于5月份的温度而言,相对温度低时二化螟爆发规模较大,相对温度高时二化螟爆发规模较小.虽然2月份的温度不适合二化螟爆发,但也并非温度越高就越好.
在本文设计的农业数据平台下,借助改进Apriori算法,挖掘出了二化螟爆发于气候条件的关系.
-
针对农业数据便捷的智能化处理问题,本文研究了基于互联网+数据挖掘的农业数据平台.设计了3层次的平台框架,供用户进行最后的决策.针对数据挖掘这一核心工作,对Apriori算法进行了改进,进一步提升了挖掘算法的效率.针对水稻生长中的二化螟虫害问题,对平台的可视化效果和数据挖掘性能进行了展示.改进Apriori算法清晰地找出了二化螟爆发规模和气候条件之间的关系,为用户的防虫害工作提供了判断依据.