


 下载:
下载:

-
自然语言处理(Natural Language Processing,NLP)正在经历快速增长,因为其理论和方法越来越多地应用于不同领域,如医学、控制、机器人、人工智能等[1-3].在行业内,人们需要NLP进行市场分析,网络软件开发就是一种实例. NLP使得终端用户编程的语义分析应用于操作系统任务、智慧家庭的自动化和机器人运动控制等不同的话语领域[4-5].
目前,大多数终端用户编程语义解析方案已经转移到机器人技术的上下文中解析自然语言命令,文献[6]提出了机器人编程框架Node Primitives(NEP),旨在为机器人创建可用、灵活和跨平台的终端用户编程接口.文献[7]提出一种机器人编程平台,可动态地将自然语言用户表达式合成为应用程序接口(Application Programming Interface,API)调用.首先,构建一个API知识图来编码和发展API,然后应用NLP、机器学习和实体识别中的技术,通过编程为其结果调用API.文献[8]实现了分拣机器人自然语言解析技术的研究,文献[9]建立机器人自然语言导航的层叠式条件随机场模型,两个文献中的研究都能提高机器人对用户表达意思的理解.文献[10]将功能机器人的终端用户编程工具应用于计算机科学外展环境,能够使得机器人通过触摸屏与人交互,并实现自主导航.针对终端用户编程(End-User Programming,EUP)场景的开放域、大型语法异构测试集合已经出现,可以解决终端用户之间的语义差距,以及软件资源日益增长导致的测试集适用局限性.由于用户终端编程的大多数语义分析器一直在小词汇量和更连贯的话语条件下运行,因此不清楚这些方法如何在高异质性条件下进行推广[11].
大多数以解释自然语言命令为目标的语义分析器都针对特定的域,集中在小目标框架集的解释上[12],这反映在语义解析模型中,该模型在更受限的词汇和句法语义异构条件下进行评估[13].机器学习是当前语义分析方法的核心[14],应用机器学习方法,简单的任务可以用相对较小的数据集来解决,而更复杂的任务需要大规模的注释数据.由于注释数据的生成昂贵且耗时,因此在小注释数据集条件下有效地解决复杂问题的模型是目前关注的热点.
针对以上问题,本文提出了一种面向自然语言的语义解析方法,该方法由分布式语义解析方法和语义旋转启发式方法组成,针对大型异构框架集合,并在小注释数据集的限制下运行.所提方法利用不同分布语义空间上的几何特征,在无监督的情况下生成自然语言项与框架之间的对齐假设.该方法可以在开放/多域词汇表上操作,并且可以从较小的训练集中推广.
全文HTML
-
自然语言命令的语义解析包括将自然语言命令映射到来自知识库的正式函数表示,该函数表示在本文工作的上下文中被命名为动作框架,被定义为n元谓词-参数结构,描述了软件系统内的函数接口(或签名).除了命令所引用的动作框架标识之外,映射过程还标识其参数值.本文方法的目标是开发一个模型,将自然语言命令映射到行动框架.
以自然语言命令为例,用语言表达用户的意图:Write to Jack@163.com asking him to take a look at the newspaper today
在该示例中,自然语言命令针对名为发送知识库中存在的电子邮件的特定动作框架,除了识别预期的动作框架外,语义分析器还需要隔离Jack@163.com和take a look at the newspaper today作为参数值,并认识到应该分配哪些动作框架提供的参数(本实例中分别为地址和消息).将动作实例命名为动作调用的实例化,该动作调用描述了动作框架本身及其参数的值.
行动框架:发送电子邮件
提供商:网易邮箱
参数:消息和地址.消息:“take a look at the newspaper today”;地址:Jack@163.com.
映射自然语言到行动框架问题用数学化表示为:设A是由一组k个动作框架(a1,a2,…,ak)组成的知识库(knowledge base,KB),设ai=(ni,li,Pi)是A的元素,其中ni是动作的名称,li是动作的提供者(主要对象,与动作相关的服务或功能动作),Pi是动作参数的集合,a′i是ai的实例,保存其参数的值.设cj是一个自然语言命令,语义上表示目标动作实例a′j.目标是构建一个模型,给定一组动作框架A和自然语言命令c,返回有序动作实例的列表B.
将上述问题解释为将自然语言命令转换为动作实例,解决这一任务的典型方法是序列到序列(Seq2Seq)机器学习模型,Seq2Seq模型旨在同时提供目标操作框架及其参数值集.然而,该模型解决目标问题的效果并不好,因此本文提出一种语义解析方法,能够有效解决目标问题.
-
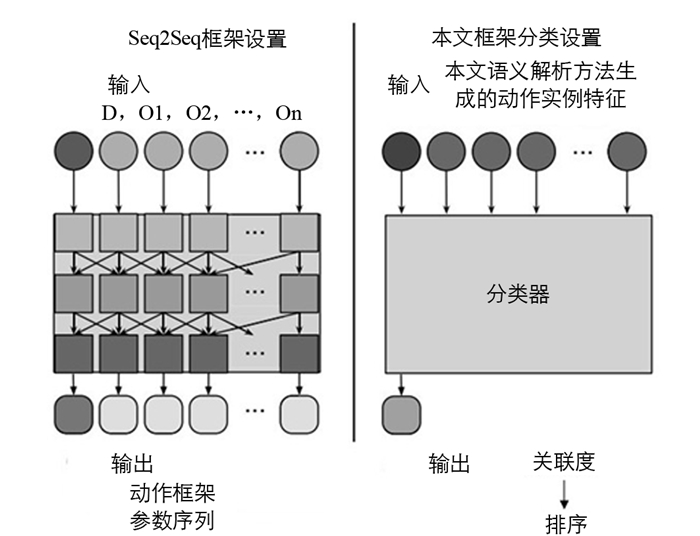
图 1给出了终端用户编程语义解析方法中对于语义特征的处理模型,在该模型中分类器与其他语义特征一起提供的关联度用作排名模型的输入,该排名模型根据相关动作实例表示用户意图的可能性来放置相关动作实例.所提方法中生成可能的动作实例,并让新模型负责将它们分类为代表或不代表用户意图.图 1中还给出了seq2seq方法,直接引导动作实例,同时预测动作框架及其参数值. Seq2Seq设置接收与动作描述和命令对象集相关的一组特征作为输入,输出为输入序列的映射.
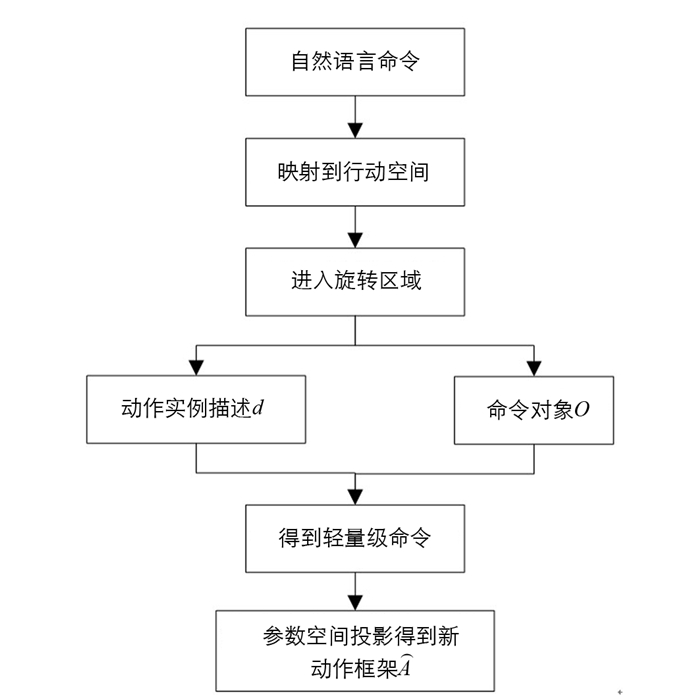
与seq2seq设置不同的是,所提终端用户编程语义解析方法通过分类设置定义了一个模型,该模型接收与动作实例相关的输入特征,并生成一个关联度的类.该类定义代表用户意图的级别,然后根据定义的级别进行相关动作实例的放置.本文语义解析方法分为语义角色标记、旋转、动作候选实例生成、分类与关联度排序4个部分.所提语义解析方法过程如图 2所示.
-
语义角色标记数学描述为σ(c)=(d,O),模型将自然语言命令(c)简化为由动作实例描述(d)和一组命令对象组成的轻量级表示(O).
动作实例描述是自然语言命令中当前标注的最小子集,其在识别目标动作框架中起关键作用,通常对应于主动词.命令对象集包括参数的潜在描述符或值,还包括间接语言.表 1为自然语言命令的示例及其作为动作实例特征和命令对象集的表示.
基于依赖树顶部的显式语法和自然语言命令的词性标记实现了一种简单但有效的浅层解析.浅层解析器假定第一个动词短语作为动作实例特征描述,并根据表 2中列出的规则识别命令对象.
用于识别命令对象(command objects,CO)的基于依赖性树的规则.一个依赖树表示为H=(V,E,φ),其中V是一组节点,每个节点代表一个标注;
$ E \subseteq V \times V$ 是有限边集,其中Eorigin表示原节点,Edest表示目的节点;φ:E→C表示从C到每个边分配一个标签.对于每个命令对象,关联一个语义类型,该语义类型由命名实体识别器分配,实现将标签规则与地名词典结合起来.其工作原理是搜索映射到地名词典元素的最长标记链,忽略间接引语部分的标记.
-
数学描述为
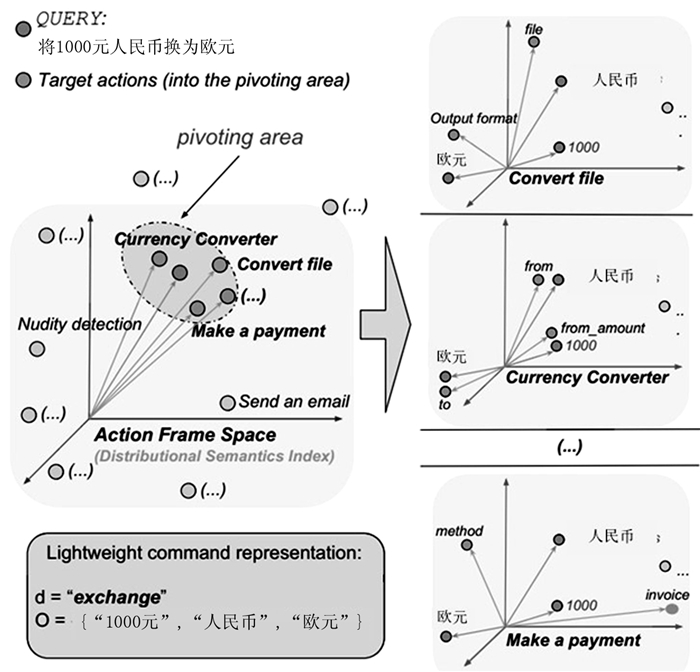
$ \rho (d, O, A) = \mathop A\limits^ \wedge $ ,旋转函数旨在选择一组动作$ \mathop A\limits^ \wedge $ ,其中$\mathop A\limits^ \wedge \subset A, |\mathop A\limits^ \wedge | \ll |A| $ ,所选子集基数明显小于原始子集基数,并且这些元素在语义上与自然语言命令相关.由于数据集很小,这一步骤减少了搜索空间,最大化了匹配参数的概率.该函数在由分布式语义模型定义的超空间中操作,其中轻量级命令和动作知识库都进行了投影,如图 3所示.由于分布式语义模型仅为单个单词提供向量表示,所以由轻量级命令和描述中存在的单词向量来生成动作.
从图 3中可以看出,自然语言命令将1000元人民币兑换成欧元被投射到行动空间中,在该空间中已经表示了全部动作.对于进入旋转区域的每个动作,模型投影到参数子空间(从金额到货币转换器的情况),并且还投影命令对象(1000元,人民币,欧元).空间中的几何特征决定了特征集,稍后将输入到分类器中.整个旋转过程的流程如图 4所示.
旋转函数通过计算超空间中的几何度量来定义一组相关的动作框架(
$ \mathop A\limits^ \wedge $ ),如图 4所示.进入该区域的每个动作框架指向另一个空间,在该空间中命令对象和动作参数基于其名称、类型和密度的语义表示进行投影.考虑动作参数(i)(动作中存在的参数)和命令对象(j)(命令中的候选值)之间的多对多关系,每对[动作框架,命令]生成一组由排列iPj产生的动作实例. -
动作候选实例生成数学描述为features(d,O,
$ \mathop A\limits^ \wedge $ )=Z,生成动作实例候选并根据以下描述的特征集表示它们.分类模型将几何测量解释为语义相关性指标.因此,模型通过以下特征列表来表示每个动作实例:
1) cos(d,n):动作描述(d)和动作名称(n)之间的语义关联;
2)
$ \max _{0 \leqslant j \leqslant m} \cos \left(o_{j}^{{literal}}, l\right)$ :命令对象(o)和提供者(l)之间的最大语义关联性;3) cos(ojliteral,pi):由命令对象(o)和动作参数(p)组成的对之间的语义关联;
4) cos(ojtype,pi):由参数描述(o)的语义类型和动作参数(p)的语义类型组成的对之间的语义相关性集合.
5) den(pi):动作参数密度的集合.
这些语义相关性分数用作输入特征,以共同识别最相关的动作框架和参数值的最佳配置.
-
关联度排序的数学描述为y=classify(Z),对候选操作实例进行分类并将它们排序给最终用户.根据匹配模型将动作框架进行分值化处理.
匹配模型:匹配模型将动作框架实例分为
·错误的框架(得分0);
·具有错误参数的正确框架(得分1);
·具有部分权利参数的正确框架(得分2);
·具有正确参数的正确框架(得分3).
这个小的但有区别的类集作为数据扩充方法,即使考虑到任务提供的小训练数据集,也能够存在同一类的许多训练实例.
下式确定了生成排名的得分函数,其中分类函数接收作为唯一向量z设置的特征集作为输入.
得分函数的乘法保证来自较高类动作实例总是排在较低类动作实例之上.
2.1. 语义解析方法
2.2. 语义角色标记
2.3. 旋转
2.4. 动作候选实例生成
2.5. 分类及关联度排序
-
本文实验中用到的数据集采用文献[15]中处理自然语言程序设计的数据集,该数据集测试集合在词汇和语法结构方面呈现出高度的可变性,另外,测试集合由每个框架的小训练集组成,需要应用语义解析方法,这些方法可以在小注释数据集上运行.在本文中,使用此测试集来激励和评估语义解析方法.测试集合包含多组自然语言命令以及与Web API对应的关联操作框架和相应的映射.表 3给出了数据集动作存在的动作框架的一些示例.
为了评估所提出的模型,为旋转函数和分类器实例化了不同的实现.旋转函数假设有2种实现:
TF/IDF:旋转函数的一个自然候选者是TDF / IDF加权方案,它将目标操作调整为与查询重叠词汇表的操作,TDF/IDF旋转函数平均将目标操作框架的数量限制为10.
最近邻:将自然语言命令投影到分布式语义空间中时,使用最近邻方法来选择50个最接近的动作框架.这种类型的函数不仅限于词汇重叠,而是扩展它们与由分布矢量模型定义的语义潜在概念的关系.
关于分类,评估了3种学习方法:随机森林(RF)、支持向量机(SVM)和简单的多层感知神经网络(MLP).以不同的方式评估每种学习方法,通过网格搜索识别它们的超参数.本文实验使用通过Google新闻数据集生成的skip-gram模型作为分布空间模型.采用召回率和平均互惠等级(MRR)来对本文方法进行衡量标准,表 4是本文方法与Seq2Seq模型的结果比较.
从表 4中数据可以看出,本文语义解析方法的性能比Seq2Seq模型性能更优,这是因为Seq2Seq方法除了参数值的正确映射之外,还要求在一组数千框架上识别目标动作的学习模型,类数与训练例数之间的低关联度,使得Seq2Seq在处理自然语言语义解析时效果并不好.
本文方法在分类器为RF,旋转函数为最近邻居时性能达到最优.旋转函数为最近邻居时性能要优于TF/IDF,这是由于TF/IDF忽略最邻近的相关动作框架造成的.在所有评估情景中,随机森林在召回率和MRR具有最好的分类性能,而SVM和MLP分类器在召回方面表现接近.
-
本文提出一种面向终端用户编程的自然语言语义解析方法,用于在受限注释数据集合下,将自然语言命令映射到大型异构框架集合的动作框架.提出的分布式语义解析方法,使用最近邻旋转函数和随机森林组合可以得到0.855 1的召回率和0.432的MRR,效果优于现有的Seq2Seq模型,说明本文方法的有效性.未来工作将研究所提语义解析方法的实际应用.