


 下载:
下载:
-
云计算是一种计算模型,可以访问共享资源,包括计算机设备,应用程序或存储资源[1-2].云计算是一种分布式计算,能够提供安全快速、便捷的网络计算服务[3-4].在云计算中,执行并行应用程序的效率关键取决于用于调度并行应用程序任务的算法,此类应用程序始终由具有优先约束的大量任务组成,并由有向无环图(Directed Acyclic Graph,DAG)表示,其中节点表示应用程序任务,有向边表示依赖性. DAG调度问题已经表明是完全非确定性多项式(Nondeterministic Polynomially,NP)问题[5-7],因此研究重点是更好地调度求解.
DAG调度算法大多基于启发式算法,目前的研究提出了多种启发式算法,包括聚类算法、遗传算法、粒子群优化算法、随机调度算法和列表调度算法等.聚类算法[8]必须有从生成的簇到有界数处理器的映射过程,假设处理器的数目过大,则算法此时不适用.文献[9]提出了一种功能强大且改进的遗传算法.该算法利用进化遗传算法和启发式方法的优点采用基于模型检验技术的行为建模方法,该方法能够提供良好的时间表,但执行时间明显高于其他方法.粒子群优化算法也被用到云计算任务调度中[10-11],文献[12]提出一种基于多目标粒子群算法和遗传算法的超启发式资源调度算法作为混合算法,该混合调度算法与现有的基于启发式的调度算法进行比较,在降低成本和提高完工时间方面都有所提高,但该算法的缺点是执行时间仍然较高.
列表调度的基本思想是先计算任务优先级,然后按优先级递减顺序将任务放在列表中,然后根据资源的优先级映射任务.很明显,优先级越高的任务越早执行.常见的列表调度算法之一是异构最早完成时间(Heterogeneous Earliest Finish Time,HEFT)算法,具有复杂度低、性能良好的优点.文献[13]提出一种节能工作流任务调度算法,该方法通过回收松弛时间来合并相对低效的处理器,首先计算所有任务的初始调度顺序,并根据HEFT算法获得整个完工时间和期限.通过使处理器具有运行任务编号和能量利用率,可以关闭最后一个节点并在其上重新分配任务来合并未充分利用的处理器.该算法的任务调度性能还可以提高.
针对现有云计算调度算法存在的问题,提出了一种重复异构最早完成时间的云计算任务调度算法,该算法基于HEFT和任务复制算法,采用乐观成本表的算法来计算优先级,能够降低通信成本并获得最佳调度解决方案.
全文HTML
-
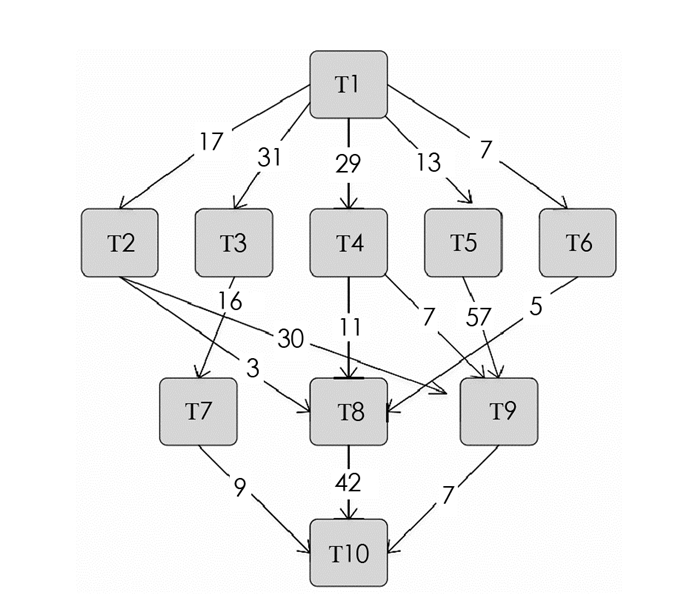
应用程序的相关任务调度问题可以由有向无环图表示(图 1),G=(V,E),其中V是节点集合,每个节点vi∈V表示任务,E是通信边缘集合,表示任务之间的依赖关系,每个边缘e(i,j)∈E表示任务依赖约束使得任务vi的执行应该在执行任务vj之前完成,任务vi是任务vj的前驱任务,任务vj是任务vi的后继任务.
没有前驱节点的节点称为入口节点,没有后继节点的节点称为退出节点,如果有多个入口节点或退出节点,则设置一对伪入口节点和退出节点.此外,伪入口节点和退出节点的计算成本和通信成本也将设置为0.当所有前驱任务完成并将前体任务的输出传递到任务执行处理器时,可以执行任务. DAG由一个矩阵W来补充,它是一个v×p的计算成本矩阵,其中v代表任务的数量,p是系统中处理器的数量. wi,j表示在处理器pj上执行任务vi的估计时间.表 1给出了图 1中每个处理器中任务的不同计算时间矩阵.
任务的平均执行时间为
每个边缘e(i,j)∈E与调度前的平均通信成本相关,平均通信成本通常为
其中,
$ \bar L$ 表示处理器的平均延迟时间,$ {\bar B}$ 表示连接p处理器集合的所有链路的平均带宽,datai,j表示任务vi应该传输到任务vj的通信量.如果任务vi和任务vj被安排在同一处理器上,那么通信成本将被设置为零,因为在本文中该通信成本与处理器间通信成本相比可以忽略不计.在本文中,假设处理器连接在完全的连接拓扑,且当处理器正在执行任务时不是抢占式的,处理器可以同时与其他人通信.在介绍目标函数之前,首先描述与以下定义相关联的pred(vi)和succ(vi),pred(vi)表示DAG中任务vi的直接前驱任务集,如果给定多个入口节点,则DAG设置具有零计算成本和零通信成本的伪入口节点.而succ(vi)表示一组任务vi的后继任务,如果DAG中存在多个出口节点,则将在DAG中建立具有零计算成本和零通信成本的伪出口节点,其前驱任务是当前多个出口节点.
EST和EFT两个重要的定义,EST(vi,pj)表示处理器pj上任务vi的最早开始时间,入口节点的EST表示为EST(ventry,pj)=0,EFT(vi,pj)表示处理器pj上任务vi的最早执行完成时间.节点的EST和EFT计算为
其中,r(vi,pj)是处理器pj最早的就绪时间,w(·)表示在处理器上执行任务的估计时间.式(3)中的内部最大块是任务vi所有前驱任务已经执行并且所需的所有数据已经被传送到处理器pj的时间,并且当任务vi和任务vj都安排在同一处理器pj上时,cj,i为零.调度长度定义为makespan=EFT(vexist),表示退出节点的EFT,如果有多个退出节点,调度长度是伪出口节点的EFT.
任务调度问题的目标函数是确定给定应用程序的任务分配给处理器,使得其调度长度最小化.
-
本文DHEFT算法在云计算中被称为完全连接的异构处理器算法,有3个主要阶段:①任务优先化阶段,用于计算任务优先级;②处理器选择阶段,用于选择最合适的处理器来执行当前任务;③复制阶段,用于更早地执行当前任务的执行起始时间.
-
给定DAG,可以根据任务优先级按降序构造任务列表.与HEFT算法相比,有更好的方法来计算任务优先级:Lookahead算法和有限数量异构处理器算法(PEFT算法),两个算法的主要特点是处理器选择策略. Lookahead算法和PEFT算法最强大的特点是,都有能力预测当前任务和所有子任务分配的影响.虽然Lookahead可以在选择处理器方面做出更好的决策,但是计算优先级的复杂性显著增加.因此,在本文中采用PEFT方法,引入一种新的基于列表的调度算法,即乐观成本表(optimistic cost table,OCT)方法. OCT是一个矩阵,其中行的数目是任务数目,列表示处理器数目. OCT(vi,pk)表示处理器pj上任务vi的OCT值,通过将DAG从出口节点向上遍历到入口节点,通过等式(6)递归地计算.
其中,cj,i表示通信成本,如果在处理器pk上安排任务vj,则cj,i为零. w(vj,pw)表示任务vj在处理器pw上的执行时间. OCT(vi,pk)表示最大乐观处理时间任务vi的后继节点,因为后继任务是在处理器中执行,与处理器可用性无关的最小化处理时间(执行和通信),在调度开始之前计算OCT.因为OCT是递归定义的,并且子节点已经具有退出节点的乐观成本,所以仅考虑第一级子节点.对于在任何处理器上调度的出口节点,OCT值为零.
通过平均每项任务的OCT,可以计算本文中的任务优先级.
设HEFT算法计算的优先级为rankh,表 2显示了通过OCT和HEFT两种方式计算的图 1中DAG样本的优先级.
与HEFT优先级相比,OCT优先级在任务的顺序中是不同的.例如,T5的优先级低于T4,因此首先选择T4进行调度.相反,基于rankh首先选择T5进行调度.本优先级排序算法的主要特征是OCT,反映每个任务和处理器执行后继任务直到退出节点的成本.
-
在按优先级构造任务序列后,将任务分配给处理器,并应用复制来减少完成时间.任务序列中的第一个未调度任务vi被选择并在处理器pj上调度. r(vi,pj)和EST(vi,pj)之间可能有空闲时间,其定义为
当选择任务序列中的任务vi在处理器pj上调度时,如果任务vj∈pred(vi)满足以下条件:任务vj在处理器pj上执行,slot(vj,pj)≥w(vj,pj),同时任务vj从未在处理器pj上被调度,则可以在处理器pj上复制任务vj,以使任务vi更早地执行,因此任务vi可以最早使用前驱任务复制完成其执行.本文算法只是在前两个或3个级别上进行复制,因为如果在所有节点上执行操作,复杂性将显着增加,并且前两个或3个级别起到决定性作用,以使总体完工时间减少.
2.1. 优先级定义
2.2. 处理器选择和复制阶段
-
为了验证本文DHEFT任务调度算法的可行性,进行了与其他算法相比较的仿真实验.为了测试调度算法的性能,在墨尔本大学开发的CloudSim-3.0.3平台上进行模拟实验.
本文使用任务完成时间和调度长度比(scheduling length ratio,SLR)来对本文算法进行验证,SLR是将DAG与不同的拓扑结构进行比较,表示标准化下限的完工时间,SLR定义为
SLR方程中的分母是关键路径CPMIN上任务计算成本的最小和.给定DAG的完工时间大于等式的分母,因此较低的SLR表示算法更好. CPMIN表示当任务节点权重被评估为所有有能力的处理器中最小计算成本时的DAG关键路径,分母代表调度长度的下限.
为了评估启发式的相对性能,使用随机生成的应用图,采用DAG Generation Program合成DAG生成程序,主要参数决定DAG形状,具体参数为
n:DAG中的计算节点数(即应用任务).
fat:确定DAG的宽度,DAG的宽度是可以同时执行的最大任务数.较小的值将导致具有低任务并行性的窄DAG,而较大的值导致具有高度并行性的宽DAG.
密度:该参数确定DAG两个级别任务之间的依赖性数量,低值表示少量边缘,大值表示许多边缘.
跳转:任务间通信跨越的最大级别数,允许生成具有不同长度执行路径的DAGs.
本文中,在合成DAG生成器中使用不同的参数值来创建DAG,其中包括特定数量的节点及其依赖性.有两个重要的定义是通信计算比(Communication-to-computation ratio,CCR)和处理器上计算成本的范围百分比β解释如下:
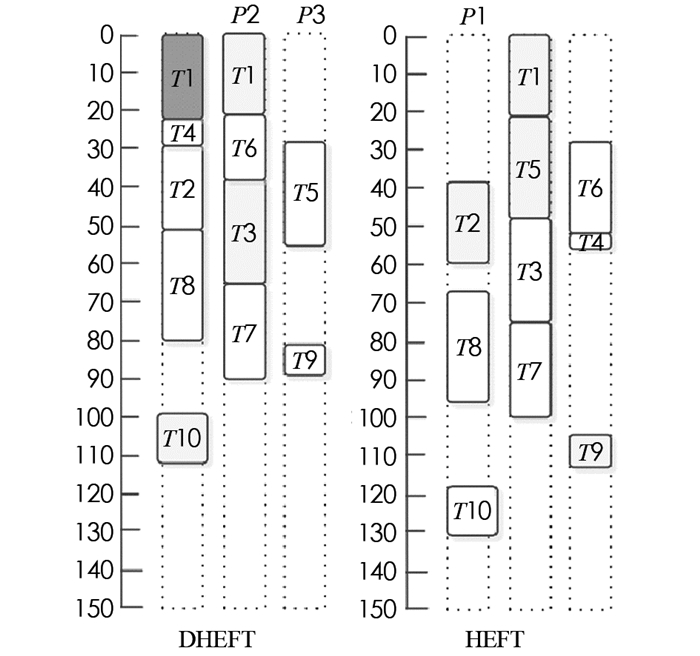
CCR表示边缘权重之和与DAG中节点权重之和的比率. β表示处理器上计算成本的范围百分比,处理器速度的异质性因素. β值高意味着更高的异质性和不同处理器之间的计算成本,低β值表示给定任务的计算成本在处理器之间几乎相等.图 2显示了本文算法DHEFT和HEFT样本DAG的调度结果.
通过比较HEFTD和HEFT的时间表,可以看到T1被分配给P1,虽然不能保证T1的最早完成时间,但是P1最小化了预期的EFT,说明本文方法平均比现有HEFT算法产生更好的调度.
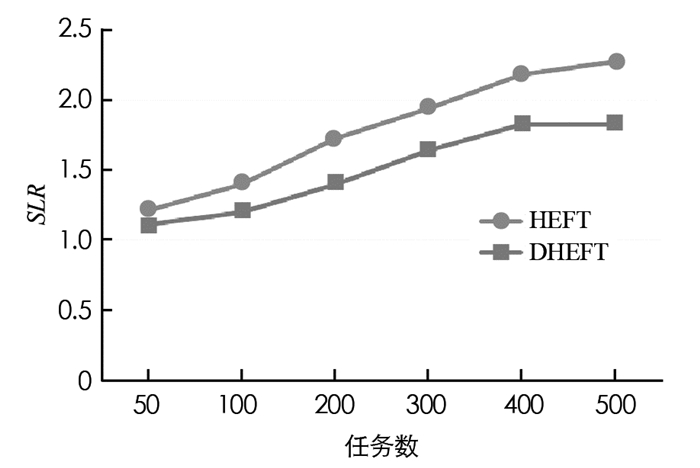
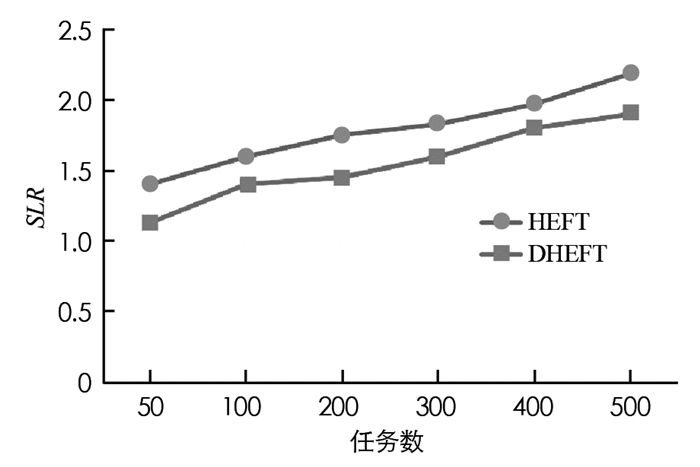
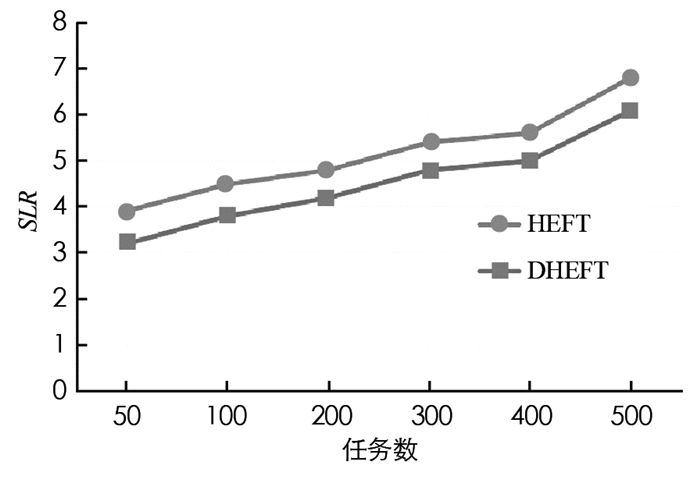
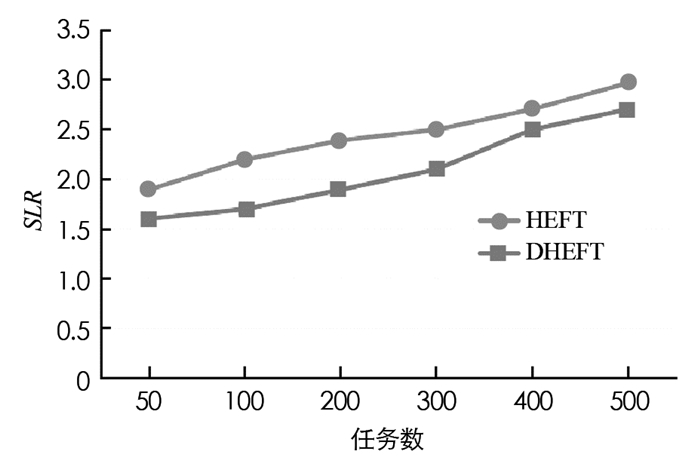
在本文中DHEFT与HEFT相比具有不同CCR值的性能,设置任务数量的范围为[50, 100, 200, 300, 400, 500],根据实验结果得到计算能力异质性因子值β取值为0.2时性能最佳,此时选择β为0.2.利用不同的CCR值,可以从这些数据中了解到DHEFT算法的平均SLR低于HEFT算法.图 3-图 6给出了不同CCR下的SLR性能.
从图 3-图 6中不同CCR下的SLR值可以观察到,当CCR=0.1时SLR最小,CCR=1时SLR最大,对于所有情况,平均SLR分别随着任务数量的增加而呈现增加趋势,这是因为除了关键路径上的任务节点之外,任务节点的比例随着任务图增大而增加,使得实现下限更加困难.在对时间的性能比较实验中,选择CCR等于0.1,β取值0.2进行实验.
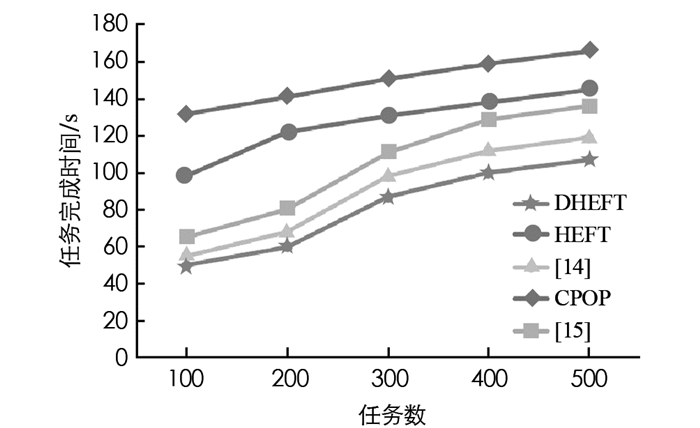
图 7给出本文算法与其他不同算法任务完成时间的比较.其他算法有处理器关键路径算法(Critical Path ON a Processor,CPOP),异构最早完成时间(Heterogeneous Earliest Finish Time,HEFT)算法,文献[14]中任务分层和时间约束的关联任务调度算法(related Task Scheduling Algorithm Based On Task Hierarchy And Time Constraint,RTS-THTC),文献[15]中任务复制的QoS调度算法(task replication of QoS,TR-QoS).图 7中曲线自上而下分别为CPOP,HEFT,[15],[14],DHEFT,从图 7中可以看出,本文算法在任务完成时间方面的性能要优于其他几种任务调度方法,说明本文方法的可行性与有效性.
-
本文提出了一种新的任务调度算法,称为基于复制的异构最早完成时间DHEFT任务调度方法.该算法结合异构最早完成时间算法和任务复制算法,可以减少任务的最早开始时间和最早完成时间,从而缩短任务完成时间.采用乐观成本表方法来计算任务优先级,该表考虑了后继任务的总体成本以获得更好的任务序列.实验结果表明,本文DHEFT调度算法比HEFT算法具有更低的SLR,且在任务完成时间性能方面,本文算法优于其他算法.