


 下载:
下载:
-
大数据是指利用习惯应用程序收集的大量复杂信息的信息集[1-2],由于大数据具有大量隐藏的潜在信息,创造商业价值显著,目前已成为学术和企业关注的热点[3].大数据一般分为数据采集、数据清洗、数据存储和数据分析应用4个环节,数据清洗是数据分析应用的一种重要预处理过程[4].数据清洗是一项代价高昂的任务,避免将不完整、无关和无效的数据输入系统,它包含数据库模式的逻辑重组和数据输入应用程序的完整性约束[5].
数据清洗一直是一个长期存在的问题,随着对大量信息和海量数据的不断关注,数据清洗已经变成一个重要的研究方向[6].数据清洗的传统方法包括异常值检测、噪声消除、实体解析和插补[7].这些方法都依赖于完美信息语料库或外部参考表的可访问性,以便在解决混乱信息中的错误之前学习信息质量标准或示例,但对于海量数据是不可行的[8].近年来,对于大数据清洗方法的研究也越来越多.文献[9]提出了针对健康大数据的数据清洗方法,所提方法能够提高后续数据处理的性能;文献[10]提出一种任务合并的并行大数据清洗优化方法,合并冗余计算和利用同一输入文件的简单计算,能减少MapReduce的轮数从而减少系统运行时间,最终达到系统优化的目标.文献[11]提出一种有效的并行混合随机确定性分解算法,在每次迭代时,通过最小化原始非凸函数的凸替代来同时更新变量的子集.文献[12]提出了一种基于Spark框架的能源大数据清洗模型,通过聚类算法得到正常簇及其边界样本,并设计了基于边界样本的异常识别算法,通过指数加权移动平均数实现了异常数据修正.文献[13]提出基于Spark的大数据清洗框架,通过分布式计算能力将弹性分布式数据集封装成大数据清洗的任务单元,通过组合、串联成完整的大数据清洗流程,并给出多叉树优化方法,实现大数据清洗的优化过程.
目前,大数据清洗方法的错误数据识别准确率有待提高,本文在现有研究基础上提出一种新的大数据清洗方法,即自适应布谷鸟搜索算法和引力搜索算法的混合SACS-GS方法.该方法对布谷鸟算法进行改进,提出了两种自适应突变策略和自适应发现概率,避免种群早熟和提高物种多样性,通过与GS方法混合,实现高精度大数据清洗.最后,通过Spark框架下实现SACS-GS方法,减少大数据清洗时间.实验结果表明,SACS-GS方法能够提高大数据清洗的数据准确性,同时减少数据清洗时间.
全文HTML
-
GS算法是根据质量相互作用和引力定律来定位的随机搜索算法,该算法通过重力和引力的作用在搜索对象中得到最优解决方案.首先统计系统的初始位置Pi=(Pi1…Pid…Pim),Pid表示第i个对象的d维度的位置,每一个位置都是潜在的解决方案,m表示搜索空间的维数,i=1,2,…,M,M表示空间维度.对象i和j的质量分别是Mi和Mj,则在时间间隔t内,两者的引力可表示为
其中,ξ表示一个小常数,Rij(t)表示对象i和j之间的海明距离,G(t)表示引力常数,
$ G\left( t \right)={{G}_{0}}\cdot {{e}^{-\alpha \frac{q}{{{q}_{\text{max}}}}}} $ ,G0为引力初始值,α为下降系数,q为循环迭代次数,qmax为最大迭代次数.$ F_{i}^{d}\left( t \right)=\sum\limits_{j\in {{k}_{\text{best}}}, j\ne i}^{M}{\text{ }rand\left( j \right)\cdot F_{ij}^{d}\left( t \right)} $ 表示对象i的引力.其中,rand(j)表示随机从[0, 1]中取值,kbest表示具有最佳适应值和最大质量的对象集合.由此可以计算在d维度中第i个对象的加速度aid(t),可表示为$ {{a}_{i}}^{d}(t)=\frac{{{F}_{i}}^{d}\left( t \right)}{{{M}_{i}}\left( t \right)}, {{M}_{i}}\left( t \right) $ 表示第i个对象的质量.因此,t+1时的速度和位置可表示为
vid(t)表示对象i的速度,Pid(t)表示对象i的位置.
-
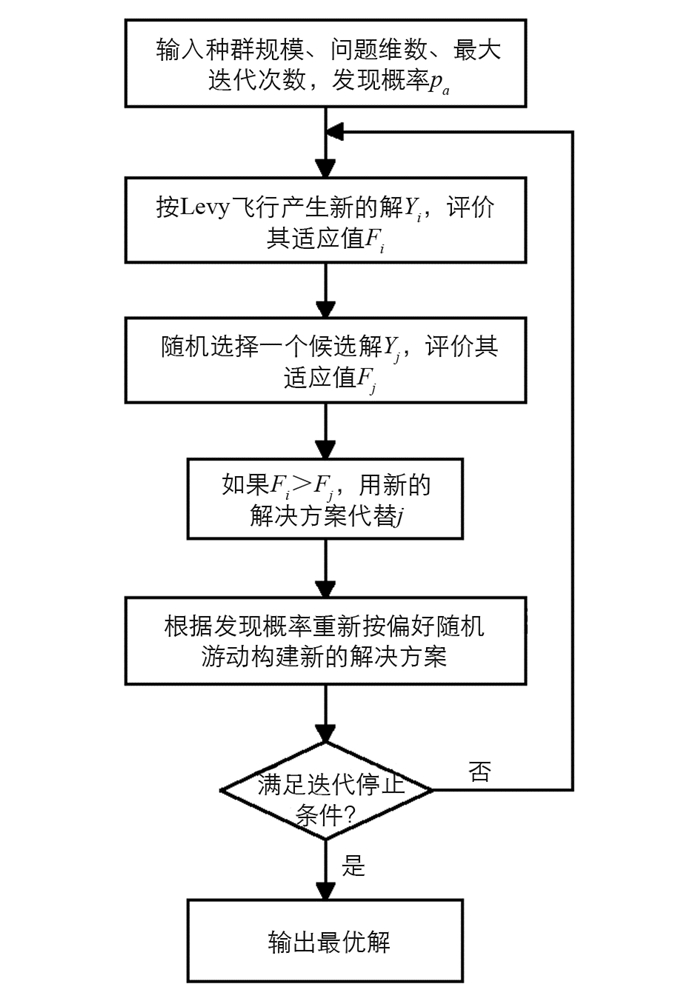
布谷鸟搜索(CS)优化算法,其基本策略是选择寄主鸟类的最佳鸟巢来放置布谷鸟的卵.以下规则解释了布谷鸟搜索算法:①布谷鸟随机选择一个鸟巢,每次放一个卵;②将优质的卵带到下一代的巢被选为最佳巢;③在整个搜索过程中,可用寄主鸟巢的数量是一个常数,寄主鸟在发现概率pa下可以找到布谷鸟放置的卵.基于以上规则,布谷鸟搜索算法步骤如图 1所示.
CS算法中,布谷鸟的卵代表一个新的解决方案.在初始过程中,每个解决方案都是随机生成的,图 1通过Levy飞行构建新的解决方案.
其中,α表示步长,且α>0,与问题的大小和产品有关,用于控制随机搜索的范围,⊕表示按项乘法. Levy飞行是随机游走的,服从的概率分布为Levy(λ)~u=t-λ,1 < λ≤3.
针对CS算法的不足,提出两种改进的搜索策略,通过线性递减概率规则将两种策略结合起来,形成自适应搜索策略.然后,引入一个自适应参数作为一个统一的随机数,根据前一阶段提出的发现概率pa来提高种群的多样性. SACS具有非常简单的结构,因此易于实现,而且不增加任何算法的复杂性.
差分进化(Differential evolution,DE)算法是最强大的随机搜索方法之一,由于DE算法结构简单,已成功地应用于各种问题. DE算法遵循进化算法的一般过程,算法中有3种操作:变异、交叉和选择.首先,以均匀分布随机生成一个种群,然后应用变异、交叉和选择算子生成一个新的种群,在公共域中对变异个体采用不同的策略,结合DE算法和CS算法提出两种搜索策略.
其中,i∈{1,2,…,NP},NP表示种群大小,r1,r2,r3,r4是从{1,2,…,NP}中选择的相互不同的随机整数索引,φ表示平均值为0.5,标准偏差为0.1的高斯分布.
突变策略CSrand1能够保持多样性和全局搜索能力,但它减慢了算法的收敛速度.突变策略CSbest2可以探索最佳向量周围的区域.此外,由于新个体在当前最佳向量附近被强烈吸引,同时提高了收敛速度,有利于开发能力.然而,CSbest2很容易陷入局部极小值.基于这两种新的搜索策略,将新的交叉策略嵌入布谷鸟搜索算法中,并通过线性递减概率规则将其与这两种新的搜索策略相结合.
If rand≥(1-G/Gmax) best2
Else
End if
其中,rand是一个介于0~1之间的实数,具有统一的随机概率分布,G是当前的代,Gmax是最大代数.
对于每个个体,如果随机实数大于(1-G/Gmax),则使用CSbest2,否则使用CSrand1.对于这些规则,选择这两种新搜索策略之一的概率是代数的函数. (1-G/Gmax)的值从1减少至0,用以平衡全局搜索能力和搜索速度.算法前期选择了两种不同的策略来生产后代,根据(1-G/Gmax)中选择CSrand1的概率大于CSbest2的概率,这个过程会引起探索.随着代数的增加,两种新的搜索方法可以以相同的概率使用.在算法后期,这两种搜索策略的使用方式正好相反.选择CSbest2的概率大于CSrand1的概率,这样可以提高开发利用率.因此,该算法基于线性递减概率规则和两种新的搜索方法,可以在搜索空间上平衡开发和探索.
发现概率pa用来控制种群的多样性,其值越大,下一代解的贡献越大,对提高收敛速度和搜索能力帮助越大;如果其值越小,则结果相反.针对以上问题,本文提出一种自适应发现概率,提高算法种群多样性,定义为
其中,t表示代数,i表示个体,fit表示t代种群中的适应度,fbestt表示i的最优适应度.可以动态控制发现概率,提高搜索的收敛速度和搜索能力.
-
大数据具有隐藏的知识和模式,数据提取可以帮助降低生产和维护成本,识别企业趋势,预测消费者的期望.大数据问题不仅与其大小有关,而且数据的变化趋势、生成频率、异构数据源、不同级别的错误以及其他因素决定了大数据问题的复杂性.如果源文件不清除数据而直接传送数据,则接收器将收到包括错误和异常的数据.
CS算法是一种优化算法,可以从全局大数据中选择数据.然而,由于大数据的复杂性以及CS算法对于大数据提取精确数据存在不足,需要一些混合优化算法,这些混合优化算法可以解决大数据中数百万个变量的问题.
为了克服大数据中的上述问题,提出一种混合SACS算法与GS算法的SACS-GS方法,其基本思想是通过GS算法的局部搜索能力来确定SACS的全局范围. SACS在全局范围内寻找产卵的区域,并找到使卵生长和成熟的最佳解决方案(最佳区域).在SACS-GS方法中,有许多数据可以完成用户请求,这些Dn最初存储为n目标函数与Dn对应,数据种群生成受Levy飞行影响,Levy飞行过程运行SACS算法,直到数据提取成为最大相关数据.在填充数据之后检查数据的质量和适用性.所选数据与预期数据密切相关,其余数据将被丢弃.由于混合上述两种算法,公式(4)可更新为
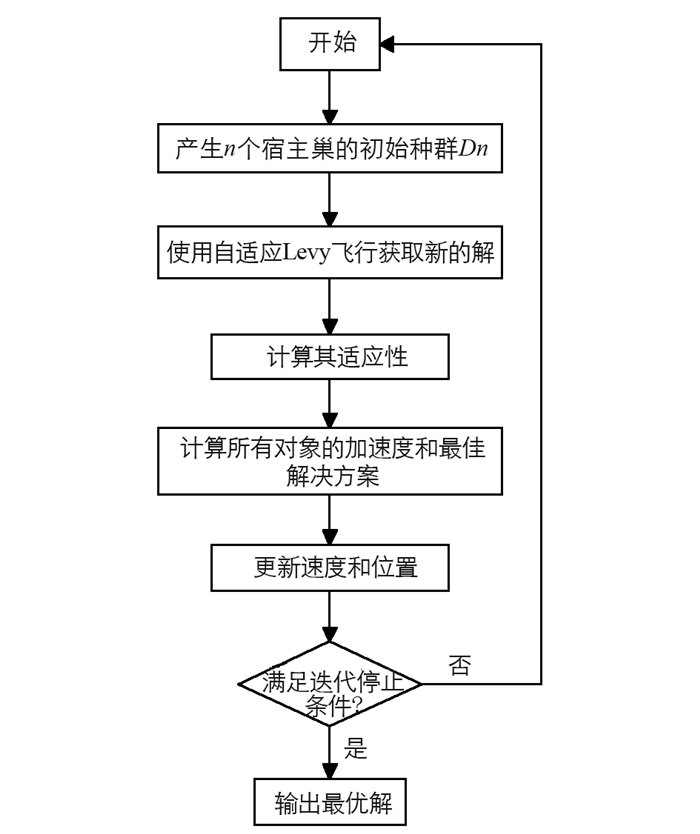
在SACS-GS方法中,最初所有对象都是随机假设的,每个对象代表一个解决方案,然后计算相互引力、引力常数、单个引力和对象的加速度,并在每次迭代后更新最佳解决方案值.更新最佳解决方案和加速度后,确定所有对象的速度和位置.重复此更新过程直到满足停止标准.本文SACS-GS流程如图 2所示.
SACS-GS方法能有效地检测源文件接收数据中的错误,并在交付数据之前修复数据,实现大数据的高质量清洗.当源文件接收到来自用户提取某些数据的请求时,将完成从原始数据集合中搜索确切数据,可以消除不需要的数据并修复数据,实现高质量的数据修复.
-
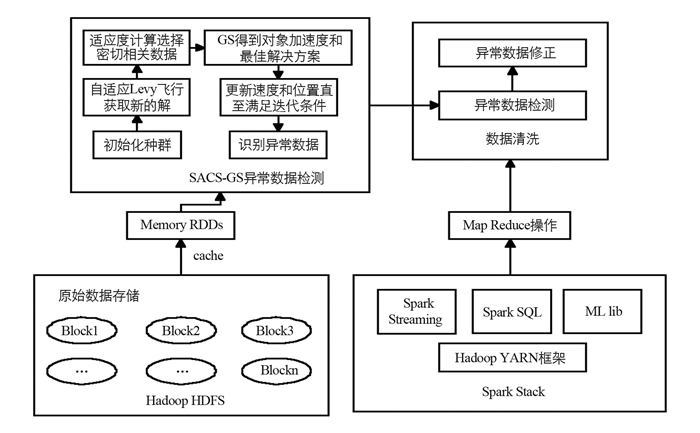
基于SACS-GS大数据清洗方法在框架Spark下的实现方案如图 3所示.
首先将待处理数据存入适合大数据的非关系型数据库中,通过弹性分布数据集(Resilient Distributed Dataset,RDD)将数据作为SACS-GS大数据清洗方法的输入. SACS-GS方法通过GS算法的局部搜索能力来确定SACS的全局范围,SACS在全局范围内寻找产卵的区域,并找到使卵生长和成熟的最佳解决方案,最终对异常数据进行识别,并对异常数据进行修正,实现数据的实时清洗.本文中采用的数据修正方法是指数加权移动平均数方法.
2.1. SACS算法
2.2. SACS-GS的大数据清洗方法
2.3. Spark框架下大数据清洗方案
-
为了验证本文方法的有效性,将本文方法与其他现有方法进行比较,实验硬件条件是Intel i7处理器,内存8 G,硬盘内存1 T,win 10操作系统的笔记本电脑.通过收集数据集网站Amazon得到实验数据,该数据大小为8 G,包括用户姓名、年龄、婚姻状态和国家,记录了2018年某一个月的用户信息.由于互联网数据种类繁杂,数据复杂度高,导致在采集数据的时候会出现错误.当数据量较小时,利用传统的数据清洗方法就能清洗错误数据,但是传统方法不再适合海量的互联网数据.本次实验使用准确率指标来评价SACS-GS大数据清洗方法错误检测的性能.
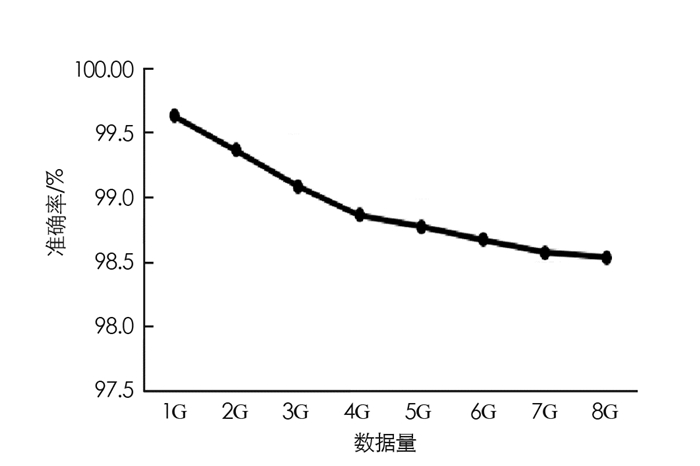
从图 4可以看出,SACS-GS大数据清洗方法能够以较高的准确率实现大数据错误检测,使采集的异常数据可以进行修复或删除.随着数据量增加,准确度降低,但是降低幅度较缓慢,在较大数据量的情况下,98%以上的准确率实现数据异常检测,说明本文方法的有效性.为了验证所提Spark框架下ASCS-GS大数据清洗算法对异常数据的检测性能,选择2 G容量大小的数据作为实验对象,该数据中实际有151个错误数据,表 1给出了本文方法与其他方法进行比较的结果.其他方法包括文献[10]中任务合并的大数据清洗技术,文献[14]中基于时间序列分析的双循环迭代方法,文献[15]中基于相关矩阵的数据清洗方法.
从表 1可以看出,本文所提SACS-GS大数据清洗方法能够以较高的准确率实现大数据错误检测,查找出最多错误数,更接近实际错误数,表明了本文方法的有效性.另外,SACS-GS方法比其他现有方法的检测准确率高,说明本文方法的优越性.
为了验证所提Spark框架下ASCS-GS大数据清洗算法的高效性,对不同容量的数据进行数据清洗运行时间测试,测试结果如表 2所示.
从表 2可以看出,不使用Spark框架的传统数据清洗方法所用时间最长,而所提SACS-GS大数据清洗方法对大数据清洗的时间最少.文献[10]中任务合并方法所用时间仅次于本文方法,说明Spark框架下SACS-GS大数据清洗方案的有效性.这是因为传统清洗方法未使用并行框架,所以用时最长.任务合并方法采用了MapReduce并行处理框架,缩短了清洗数据时长,与本文Spark框架下数据清洗方法时间相近,但根据上面实验数据,其准确率没有所提SACS-GS方法高,文献[14]中时间序列方法采用基于时间序列的双循环迭代检测方法,提高了数据清洗效率,但是效果没有使用并行系统好,文献[15]中相关矩阵方法使用大数据相关矩阵的特征向量统计,通过“旋转不变”估计量减少数据清洗时间,但是运行时间高于并行大数据框架方法.
-
为了提高采集大数据的准确性,本文提出了一种高精度清洗大数据分析的SACS-GS方法,并给出Spark框架下数据清洗方案.所提SACS-GS方法通过GS算法的局部搜索能力来确定SACS的全局范围,使用自适应突变策略和自适应发现概率实现全局范围内寻找产卵的区域,并找到使卵生长和成熟的最佳解决方案,高精度实现大数据的异常检测.实验结果表明,SACS-GS方法在检测误差方面比现有方法更有效和准确.另外,SACS-GS方法清洗数据用时最少,说明所提方法的有效性.