


 下载:
下载:
-
矩阵乘法是科学计算中最基本的操作之一[1-2].然而,由于矩阵乘法运算数据量大、计算密集度高,许多传统数据处理方法都难以满足实时性要求.如何进行大数据量的快速处理,降低运算时间,提高整体应用系统的时效性已显得尤为重要[3].
近年来,随着并行算法技术与并行处理构架的发展,多核CPU,FPGA,GPU等新型加速平台开始被研究和运用[4-7].开放式计算语言(open computing language,OpenCL)是一种通用的国际标准,可用来在不同架构CPU,GPU,FPGA等设备上使用统一的接口来设计,包括编程语言规则、程序设计语言、函数库、应用编程接口等[8].
目前,国内外研究学者在矩阵乘算法的加速和优化方面已有一些代表性工作[9-20],但是算法本身加速效果均不明显.本文将根据矩阵乘算法的运算特性和GPU架构特征,实现OpenCL加速的矩阵乘并行算法.同时,通过性能参数传递机制,实现了该算法在不同计算平台上的性能移植.
全文HTML
-
一个n×n的方阵A乘以n×n的方阵B可得一个n×n的方阵C:
其中C矩阵的元素
$ {c_{ij}} = \sum\limits_{k = 0}^{n - 1} {{a_{ik}}{b_{kj}}} $ ,0≤i,j≤n-1.在基于GPU实现的矩阵乘法中,将n阶矩阵分成Sx×Sy个大小为m×r的矩阵子块,其中:m=n/Sx,r=n/Sy,Sx与Sy分别为GPU在x,y方向设置的工作组大小.使用Sx×Sy个工作组执行分块乘时,每个工作组计算一个Ci,j块. -
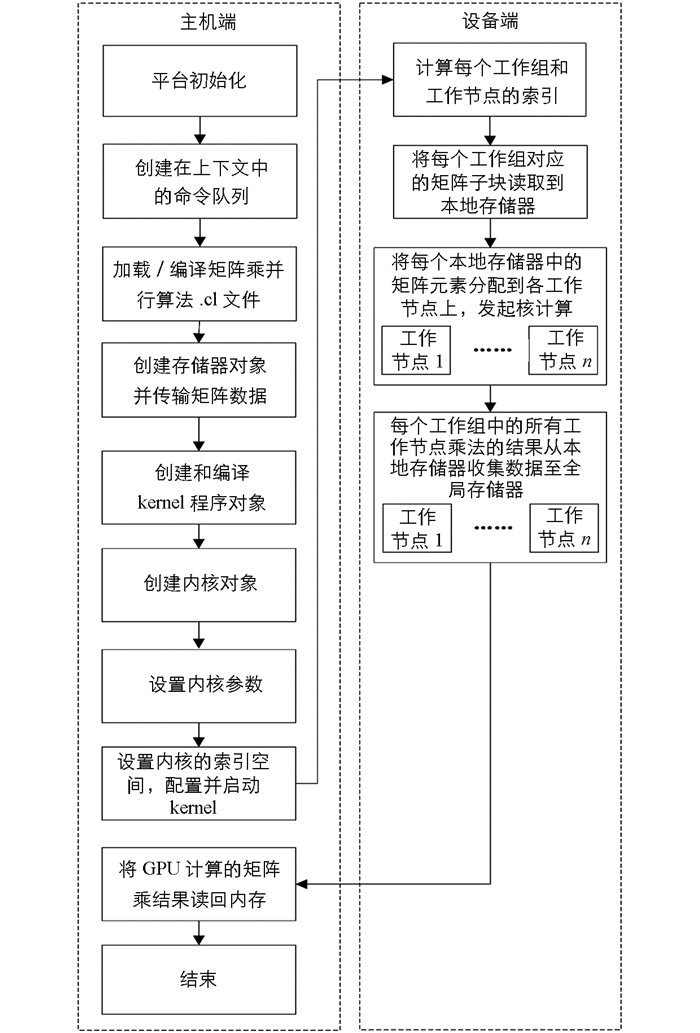
基于OpenCL的矩阵乘GPU并行化处理执行模式见图 1.
-
在GPU上创建矩阵乘并行计算工作项网格.计算网格的输入数据是方阵A和方阵B,包括Sx×Sy个工作组,每个工作组处理一个矩阵子块.每个工作组包括32*32个工作项,每个工作项处理矩阵子块中的一个矩阵元素.
计算网格的输入矩阵数据一般都存储在慢速全局存储器中,在计算矩阵乘结果每个矩阵元素时,需要频繁地从全局存储器读取计算数据.设输入n维矩阵方阵,则生成n维结果矩阵方阵进行乘—加运算的时间复杂度为O(n3),所需要的全局存储器访问的次数为n3量级.也就是说,每计算一个结果矩阵元素就需要进行n次全局存储器的访问,这将严重影响算法的效率.本地存储器相对于全局存储器具有更高的访存速度,为了缓解显存带宽与运算性能之间的不平衡,可先将矩阵子块数据从全局存储器中取出,存储到高速本地存储器中,供一个工作组内所有的工作项使用,每次计算只需要从本地存储器中读取数据即可.但由于可供每个工作项使用的本地存储器仅为16 KB,当矩阵子块中数据量较多时,无法一次性放入本地存储器.这就需要适当控制矩阵子块的大小,保证每个矩阵子块的数据放入本地存储器.最后将结果矩阵数据转储在GPU的全局存储器中.
-
N维索引空间NDRange与工作组的大小会影响到加速的性能.矩阵乘并行算法的计算网格配置时二维工作空间NDRange的维度应取得较大.这样,就有更多的工作组可以被分配到GPU的CU中. CU以warp为单位执行工作组,在同一个CU上可以同时存在多个工作组的上下文和多个warp上下文,但一个时刻只有一个warp被执行.如果有多个warp能被调度,GPU的容许时延机制会按照优先级进行调度,这样利用零开销的工作项或warp调度选取其他工作项或warp执行,便能充分利用硬件资源来掩盖延迟时间.如果CU只分配了一个工作组,由于属于同一个工作组的若干个warp会有比较大的几率会同时进入长延时操作,就会使CU中的PE处于长时间等待.而属于不同工作组的warp在同一个CU上执行时,当一个工作组的所有warp都进入长延时操作,在其他工作组中的warp将有较大几率处于就绪态,系统就有可马上执行的warp,更好隐藏了延时.
并行算法中工作组尺寸要划分合理,不同的工作组布局对存储器访问的性能是不同的.每个工作组的工作项数量应为warp size(32)的整数倍.这样可以提高访问全局存储器和本地存储器的效率.尽可能同时执行更多的工作项,以便隐藏存储器延时.本文设计的每个工作组中有192个工作项,这样有助于提高系统的执行效率.矩阵乘内核函数的工作空间设置为globalWorkSize[0]×globalWorkSize[1],工作组内工作项值的大小为localWorkSize[0]×localWorkSize[1],核函数的网格配置如下:
-
在进行每个工作项的任务分配时,需要将矩阵子块中所有工作项在工作空间中的位置与一个矩阵元素对应处理.算法利用系统内建函数建立了工作项的ID索引workItemID如下.
-
在OpenCL计算模型中,系统定期从一个warp切换到另一个warp进行工作项调度,以最大限度利用计算单元的计算资源.如果32个工作项处于同一个warp中,则它们是被系统绑定在一起执行同一指令.所以,在每个工作组中包含的工作项总量应为32的整数倍,一般应保持在64至256之间,根据任务量的情况来确定工作组每个维度上的尺寸. 表 1中显示了矩阵大小为600×600,在工作组中设置不同数量工作项时的系统运行时间,从中可以看出当工作项为192时,系统性能最优.
1.1. 并行算法描述
1.2. 并行算法执行模式
1.3. 矩阵乘并行算法在OpenCL上的实现
1.3.1. 并行算法设计
1.3.2. 计算核心的启动配置
1.3.3. 数据坐标变换
1.4. 针对GPU架构特性的优化
-
硬件平台1:CPU为Intel Westmere E5690 2.4GHz(六核心),系统内存为2.67GHz,12.0GB. GPU为NVIDIA Tesla K40,其中SM数为15,工作组中最大工作项数为1024,每个SM中最大激活工作项数为2048,每个SM中最大激活工作组数为16,每个SM中最大寄存器数为64KB,每个SM中最大本地存储器为16KB.
硬件平台2:CPU为Intel Westmere E5690 2.4GHz(六核心),系统内存为2.67GHz,12.0GB. GPU为AMD Radeon HD5870,核心频率为850MHz,总共1280个流处理器;显存采用频率为4.8GHz的GDDR5,容量为1000MB,位宽为256位.
软件平台:Windows7 64位操作系统;Visual Studio 2015集成开发环境;并行开发环境为CUDA Toolkit 8.0,其内部支持OpenCL 1.2标准.
实验采用矩阵规模大小分别为100×100,200×200,400×400,600×600,800×800,1 000×1 000,1 400×1 400共7组测试数据,矩阵乘法算法分别运行于基于单线程CPU串行系统、基于多线程CPU的OpenMP系统、基于NVIDIA GPU的CUDA系统、基于AMD GPU的OpenCL系统和基于NVIDIA GPU的OpenCL系统,并记录系统处理时间(表 2).
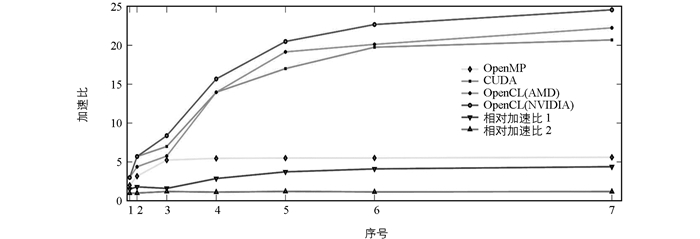
为了对各种架构下的并行算法效率进行验证,将CPU串行算法执行时间与并行算法执行时间的比值(加速比)作为衡量加速效果的依据:基于多核CPU的OpenMP并行算法运算时间与基于NVIDIA GPU的OpenCL并行算法运算时间的比值是相对加速比1;基于NVIDIA GPU的CUDA并行算法运算时间与基于NVIDIA GPU的OpenCL并行算法运算时间的比值是相对加速比2.
加速比反映了相应架构下并行算法相比CPU串行算法整体效率提升情况,可以用于对实际系统速度方面的客观评价(表 3).而相对加速比1可用于反映基于OpenCL的NVIDIA GPU并行算法相比基于多核CPU的OpenMP并行算法的效率提升效果,相对加速比2则可用于反映基于NVIDIA GPU的OpenCL并行算法相比基于GPU的CUDA并行算法的效率提升效果.
-
通过实验对基于NVIDIA GPU的OpenCL矩阵乘并行算法、基于AMD GPU的OpenCL矩阵乘并行算法、基于单核CPU的矩阵乘单线程算法、基于OpenMP的矩阵乘多线程算法和基于CUDA的矩阵乘并行算法进行对比. 表 2统计了各种算法在不同矩阵大小中进行矩阵乘法的运行时间.从表 2可知,单线程和多线程的CPU版本的运算时间最长,并且运算时间随矩阵规模的增加而明显增加.但是相比串行算法,OpenMP并行算法的执行时间增长更慢,获得了5.6倍的加速比.在CPU+GPU异构计算平台上运行的算法都有着较好的性能,实验中运算在各种矩阵规模下的矩阵乘算法均可在3s内完成.同时,随着矩阵规模的增加,CUDA加速的矩阵乘并行算法和OpenCL加速的矩阵乘并行算法的运行时间增加都较为平缓.
由表 3数据可得图 2所示3种并行算法的加速比对比图.随着运算数据量的增大,基于GPU加速的矩阵乘并行算法相比OpenMP并行算法获得了更大的加速比,这是由于相比具有六核心的CPU,GPU可为大量数据的并行处理提供更充裕的计算资源和创建更多的工作项,从而获得的加速比较大.相对加速比2的曲线反映出基于OpenCL架构的并行算法相比基于CUDA的并行算法具有1.21倍的加速效果.这主要是因为系统通过预编译来加载算法内核时,采用了离线生成二进制文件的方法显著减少了应用初始化时间.
当矩阵大小比较小时,系统启动的参与并行运算处理的工作项不多,并没有充分利用GPU中大量的CU.随着矩阵大小的扩大,系统启动的工作项数目在不断增多,算法获得的加速比也随着系统负荷的不断增加而扩大.当GPU的运算负荷接近饱和状态时,获得的加速比相应地也逐渐减缓.同时,CUDA加速的矩阵乘并行算法受制于硬件平台,OpenCL加速的矩阵乘并行算法分别在AMD GPU和NVIDIA GPU平台上取得了22.24倍和24.56倍加速比,说明在多种硬件平台上基于OpenCL的矩阵乘并行算法能够在最大程度上实现性能的可移植性和兼容性.
2.1. 测试环境和数据记录
2.2. 并行算法性能分析
-
为使矩阵乘并行算法在异构处理平台下充分利用GPU的处理能力,本文针对OpenCL模型采用基于工作组和工作项两级并行计算方式,通过分析GPU构架特性,合理安排工作项组织结构,并对GPU的本地存储器的分配进行了优化.实验数据显示,与基于CPU的单线程算法、基于OpenMP多线程多核CPU并行算法和基于CUDA架构的并行算法相比,利用OpenCL加速的矩阵乘并行算法效率更高,实现了对大数据集的跨GPU计算平台实时处理.