


 下载:
下载:
-
近20年间,互联网技术的飞速发展彻底颠覆了传统生活方式和经济模式,成为人们日常生活和工作中不可或缺的重要组成部分[1-2].通过网络入侵获取企业经营数据和商业机密成为一种重要的犯罪模式[3].如何有效应对网络入侵检测,保护网络安全,已经成为互联网技术领域亟待解决的重要课题[4].所谓入侵检测,就是对试图破坏网络访问规则、试图中断网络连接、试图盗取网络信息的相关攻击行为的检测[5].在抵御入侵检测的早期阶段,信息加密、防火墙、登录认证等方法比较常用[6-7].入侵检测就变成了对规则信息和攻击信息的区分检测,基于机器学习和智能识别的方法广泛应用于入侵检测[8].本文提出一种基于支持向量机的检测方法,以期更加准确地对入侵行为进行判断.
全文HTML
-
基于决策树的入侵检测方法,就是将规则信息和攻击信息分别形成信息库,并根据决策树的构建和识别方法形成对2种信息的判断,进而有效地检测出入侵信息[9].基于神经网络的入侵检测方法,是将先验数据代入网络中进行训练学习,网络稳定后确定网络参数指标,再对新的数据进行判断确定是否为入侵行为[10].基于遗传算法的入侵检测方法,是根据先验数据计算出父代和子代之间的遗传关系,进而判断新数据是否具有父代入侵行为的相关特征,从而得出是否为入侵行为的结论[11].基于聚类分析的入侵检测方法,是将规则信息和入侵信息分别聚类,根据新信息距离聚类中心的远近判断其是否为攻击行为[12].
支持向量机方法是一类典型的机器学习方法,在学习分类过程中又充分依赖统计学原理和风险最小化原理.支持向量机的方法,可以将要分析的问题按照向量机进行分类,形成明确的2个集合.这对于网络入侵检测而言是非常具有针对性的,可以把各种网络访问行为明确地区分为正常行为还是攻击行为.
假设存在一个高维度的特征空间,同时可以在这个空间中构造出一个完成学习过程的函数.借助这个函数,可以不断地进行偏差学习和优化,进而完成整个训练过程.支持向量机方法的突出优点在于:其检测效果直接对应于样本数据,无论是高维度的还是非线性的,检测效果都具有较好的一致性;泛化学习能力强,无论是维度上灾难问题还是过度学习问题,都能被支持向量机较好地解决.
从实现原理上看,支持向量机方法的实现过程就是一个分类过程.为了区分两类不同性质的样本,它需要构建一个最优超平面,这个平面如果能够保证两类样本之间的距离间隔最大,就达到了最佳分类效果.
在具体操作过程中,如果被分类的样本是线性的,就采用线性分类核函数.如果被分类的样本是非线性的,就采用非线性分类核函数.
如果在当前维度空间上,无法找到一个最优超平面,就延伸到更高维度的空间上去寻找.
对于入侵检测问题而言,其规则信息和攻击信息的区分是一个典型的二分类问题,与支持向量机的方法具有很好契合性.
从数学意义上讲,支持向量机方法在解决二分类问题时,对一个数据集进行处理,此数据集L={(x1,y1),(x2,y2),…,(xn,yn)},其中xi用于表示输入向量,yi用于表示输出向量,这时支持向量机的分类就演化为二次优化问题,为
其中,参数αi表示对输入向量xi进行训练时的拉格朗日因子,参数K()用于表示支持向量机中的核函数,参数C用于表示进行分类过程中的惩罚因子.
根据公式(1)的优化处理,可以进一步获得决策函数,为:
其中,参数D(x)表示的就是分类结果,如果它的值是1,就表示规则信息,如果它的值是-1,就表示攻击信息.
-
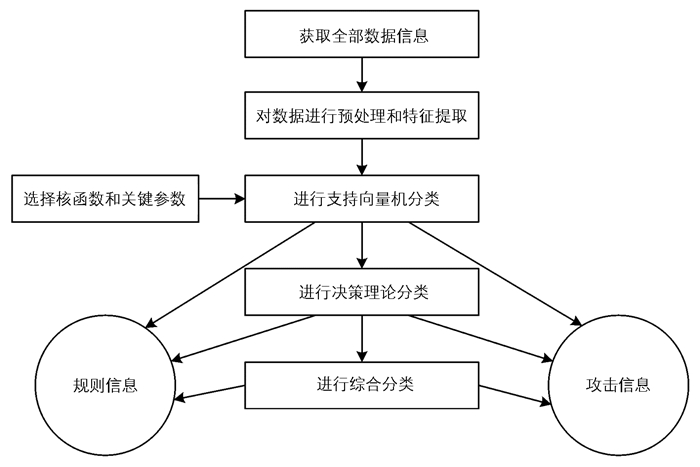
为了使支持向量机方法更加适合于入侵检测,本文进一步引入决策集合理论,构建了一种具体的入侵检测方法,处理过程如图 1所示.
根据图 1框架,该方法的具体实现步骤如下:
1) 根据支持向量机方法,计算样本数据对(xi,yi)到超平面(w*,b*)之间的距离大小,这个距离函数表达为ri=yi(w*xi+b*).如果这个距离大小满足ri≥
$\frac{2}{{\left\| w \right\|}}$ ,表明待检测信息是规则信息;如果这个距离大小满足ri <$\frac{2}{{\left\| w \right\|}}$ ,将待检测信息纳入不确定集合.2) 对于不确定集合Q中的数据,按照决策集合的理论进一步分类.这个过程首先需要将集合Q中数据所对应的各种属性特征和决策值都看作决策信息表,之后根据属性特征对数据进行等价类确定[x],再在这个等价类中确定其归属概率P(X[x]).根据预先设定好的损失函数λ以及两个域值α和β,如果P(X[x])≥α,那么x就是规则信息;如果β < P(X[x]) < α,那么x就是规则信息和攻击信息的边界信息;如果P(X[x])≤β,那么x就是攻击信息.
3) 此时仅剩下边界信息集合N的数据尚未确定其分类,进一步采用归一化处理,进而计算m=
$\frac{{w{r_i} + \left( {1-w} \right)P\left( {X\left[ x \right]} \right)}}{2}$ ,然后将m和实现设置的域值n进行对比.如果m≥n,那么x就是规则信息;反之,x就是攻击信息.
-
为了验证本文提出的入侵检测方法的效果,在接下来的工作中将展开验证性实验.实验中,计算机的配置:CPU为英特尔i5-6500,其主频大小3.20 GHz,内存大小32 GB,操作系统为windows 8.0,硬盘大小500 GB,编译平台选择Matlab.
入侵检测的数据样本,选择网络安全领域比较常用的K-Cup测试数据集.在这个数据集中,每个信息都带有标记,以表明其是攻击信息还是规则信息.同时,这个数据集中的攻击信息还分为4个类型,分别是DOS型攻击信息,其意义为拒绝服务攻击信息;R2L型攻击信息,其意义为未对远程主机进行访问授权的攻击信息;U2R型攻击信息,其意义为未对本地主机进行访问授权的攻击信息;PROBING型攻击信息,其意义为不断对主机端口进行监听和扫描处理的攻击信息.
-
为了便于对入侵检测结果的量化分析,首先来设置4个参数,分别是参数TP、参数TN、参数FP、参数FN.这里,参数TP代表的是实际结果和检测结果都是攻击信息,参数TN代表的是实际结果和检测结果都是规则信息,参数FP代表的是实际结果是规则信息、检测结果是攻击信息,参数FN代表的是实际结果是攻击信息、检测结果是规则信息.
根据上述4个参数,可以进一步得到4个具体的入侵检测性能指标:指标DR,用于表示召回率;指标FAR,用于表示误检率;指标ACC,用于表示检测精确率;指标PR,用于表示查准率.
4个指标和4个参数之间的对应关系分别如下:
召回率指标的计算:DR=TP/(TP+FN)
误检率指标的计算:FAR=FP/(FP+TN)
检测精确率指标的计算:ACC=(TP+TN)/(TP+TN+FP+FN)
查准率指标的计算:PR=TP/(TP+FP)
选择基于神经网络的入侵检测方法、基于遗传算法的入侵检测方法、基于传统支持向量机的入侵检测方法作为本文方法的对比方法,对4.1节中的样本数据进行入侵检测实验,实验中得到4个参数和4个指标的结果表 1、表 2所示.
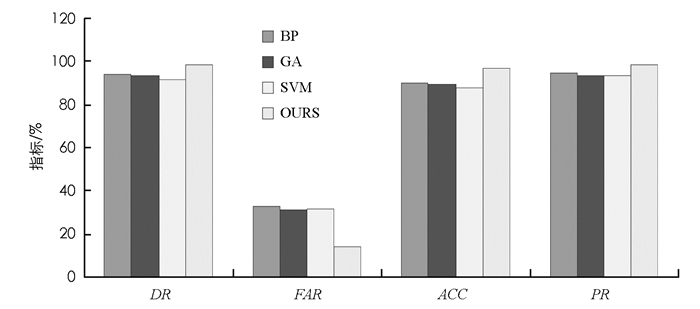
从表 2中的数据结果可以看出:
1) 对于召回率指标DR,本文提出的入侵检测方法达到了98.31%,高出排名第2的基于神经网络入侵检测方法(BP)近5个百分点.
2) 对于误检率指标FAR,本文提出的入侵检测方法最低,仅为13.99%,而其余3种方法的误检率都超过了30%.
3) 对于检测精确率指标ACC,本文提出的入侵检测方法达到了96.98%,高出排名第2的基于神经网络的入侵检测方法(BP)近7个百分点.
4) 对于查准率指标PR,本文提出的入侵检测方法达到98.31%,而其余3种方法的查准率指标都不超过95%.
上述4组指标可以明显看出,本文提出的入侵检测方法明显优于其它3种方法,从而证实了其有效性. 表 2中数据的可视化结果如图 2所示.
3.1. 实验条件设置
3.2. 实验结果分析
-
支持向量机方法是一种典型的二分类方法,这对于入侵检测中规则信息和攻击信息的明确划分具有良好的对应性.基于这种考虑,本文将支持向量机和决策集合理论结合起来,构建了一种新的网络入侵检测方法,并给出了详细的算法流程和实验验证过程.在实验过程中,选择了网络安全领域常见的K-Cup测试数据集,并以基于神经网络的入侵检测方法、基于遗传算法的入侵检测方法、基于传统支持向量机的入侵检测方法作为对比算法.实验结果表明,本文提出的方法在召回率、误检率、精确率、查准率等方面均优于其它3种方法,适合应用于网络安全领域的入侵检测.