



 下载:
下载:


-
当今数字化信息时代,随着互联网的迅猛发展,各种信息资源的安全性是很重要的问题,在很多场合都采取了访问控制的安全防护措施.其中,基于生理特征的身份鉴别,如人脸识别、指纹识别等就因其实时性、便捷性等特点而得到广泛应用[1-2].如何在复杂环境中对人脸检测和识别是目前人脸识别领域的研究内容,其中最佳鉴别特征的提取与分类器设计更是该领域的热点课题.随着压缩感知编码[3]理论的提出,一些研究人员发现特征[4-11]的选择并不很重要.假如能在高维空间对人脸图像有更准确的估计就可以获得更高的识别率.
于是,近年来基于稀疏编码模型的人脸识别技术引起广泛关注. WRIGHT[12]等最先提出基于稀疏表示分类(SRC)的人脸识别方法.该方法由于对图像本身存在的噪声影响不敏感,在识别方面有较强的鲁棒性.围绕此模型,很多学者作了大量深入的研究,比如针对更为复杂的光照、遮挡等实际环境,提出了在SRC中嵌入迭代加权系数的方法[13]以及基于Gabor变换提取图像局部方向性特征的SRC算法[14]等.以上方法虽然在应用中有着不错的效果,但SRC基于最大似然估计的l1-范数的系数求解,由于需要迭代,致使计算的复杂度较高.为此,ZHANG[15]等提出了用l2-范数代替稀疏求解的CRC.此方法在分类识别时,保证了测试样本与类内样本的误差足够小,同时与类间样本的误差足够大,使识别更加有效.此外,NASEEM[16]等将LRC引入,同样可较为准确地估计人脸图像在高维空间的分布.此算法简单、易实现,在人脸识别应用中无论计算效率还是识别率都很好,但对图像的要求较高,易受噪声的干扰.
为进一步改善人脸识别方法的性能,本文引入CRC[17-18],并根据各训练样本与测试样本的误差构建加权矩阵权衡它们之间的相似度,并将其嵌入到CRC中,称为加权CRC.另外,基于所有样本的协同表示在系数求解时需将二维图像转换为一维列向量,从训练集的规模考虑,一旦维数过大,势必会大幅增加计算的复杂度,从而降低运行效率.因此首先基于PCA对所有图像样本降维,然后利用CRC与LRC的特点,采取组合策略设计了两种二级分类方法以获得更好的识别效果,分别为:二级加权CRC、加权CRC与LRC相结合.它们在第一阶段都使用加权CRC,根据重构残差保留相关性较大的类用于下一阶段的分类识别;区别在于第二种方法在第二阶段基于LRC判别测试样本的归属.两种方法通过阶段性缩小分类目标的做法,可使分类更精确.在ORL,FERET及AR人脸库上的实验验证了本文方法的有效性.
全文HTML
-
基于压缩感知编码理论的SRC算法在人脸识别中因其鲁棒性较强而被广泛应用,但由于其基于l1-范数的系数求解[19],一味突出样本的稀疏性,致使计算中不断迭代,降低了算法的时效.于是ZHANG等提出CRC方法,此模型突出所有样本的协作性,为降低稀疏度,用l2-范数代替以简化计算.
设有C类目标样本,每类样本有ni幅图像,样本总数
$ N = \sum\limits_{i = 1}^C {{n_i}, \mathit{\boldsymbol{X}}} _j^i$ 是第i类第j幅样本,图像大小为m×n.将Xji矢量化为$x_j^i \in {\mathbb{R}^{m \times 1}} $ ,这样第i类训练样本组成的矩阵为${\mathit{\boldsymbol{X}}_i} = \left[{x_j^i, \cdots, x_{ni}^i} \right] \in {\mathbb{R}^{m \times ni}} $ ,从而构成完备的训练样本,表示为$\mathit{\boldsymbol{X = }}\left[{{\mathit{\boldsymbol{X}}_1}, \cdots, {\mathit{\boldsymbol{X}}_c}} \right] \in {R^{m \times N}} $ .设测试样本为$ \mathit{\boldsymbol{Y}} \in {\mathbb{R}^{m \times n}}$ ,将Y矢量化为$ y \in {\mathbb{R}^{m \times 1}}$ .CRC中样本系数α的求解由下式定义
其中λ∈(10-6,0.1) 是正则化参数,以稳定重构误差和稀疏性.
系数α可通过对(1) 式求导得出,即
下式计算各类训练样本线性重构与测试样本y的残差ei,即
本文实验中文献[20]方法亦使用公式(3) 计算残差.
最后依据ei的最小值判断y的类别
-
LRC模型的实现是基于最小二乘法的线性表示算法,该算法根据y与各类样本的重构误差决定其归属.实现步骤如下,对训练样本集的描述如前所述.
求解各类训练样本的重构系数
$\mathit{\boldsymbol{\alpha }} \in {\mathbb{R}^{{n_i} \times 1}} $ ,即用最小二乘法解出
$ \mathop {{\mathit{\boldsymbol{\alpha }}_i}}\limits^ \wedge$ ,即根据欧式距离计算y与每类训练样本的重构误差βi,
最后依据(8) 式决定y的归属,即
-
考虑到各训练样本xji与测试样本y有一定的局部相似性,那么它们对于分类识别的贡献取决于相似程度,而这种相似度可通过欧氏距离获得,定义wij为各训练样本xji的权重值,即
其中t为度量xji与y误差的固值参数.本文中t=min{‖y-xji‖2}.
以此构建对角加权矩阵,即
将M嵌入到公式(1) 中,得
通过解析(11) 式求得
$ \mathop {{\mathit{\boldsymbol{\alpha }}}}\limits^ \wedge$ 为本文中λ取值为0.01.
具体步骤如下:
Step 1:将各类训练样本
$ \mathit{\boldsymbol{X}}_{j}^{i}\in {{\mathbb{R}}^{m\times n}}$ 和测试样本$ \mathit{\boldsymbol{Y}}\in {{\mathbb{R}}^{m\times n}}$ 分别矢量化为$\mathit{\boldsymbol{x}}_{j}^{i}\in {{R}^{m\times 1}}, \mathit{\boldsymbol{y}}\in {{R}^{m\times 1}} $ .Step 2:利用PCA对xji和y降维,得
$ \overline{\boldsymbol{x}}_{j}^{i}$ 和$ \overline{\boldsymbol{y}}$ .Step 3:根据公式(9) 计算各训练样本
$ \overline{\boldsymbol{x}}_{j}^{i}$ 的权值,建立如公式(10) 所示的加权矩阵M嵌入CRC中,如公式(11).Step 4:基于加权CRC,由公式(12) 求解编码系数
$\mathop {\bf{\alpha }}\limits^ \wedge $ .Step 5:将
$\overset{\wedge }{\mathop{\boldsymbol{ }\!\!\alpha\!\!\text{ }}}\, $ 关联于各类训练样本的稀疏系数αi代入公式(3) 分别计算$ \overline{\boldsymbol{y}}$ 与每类训练样本$\overline{\boldsymbol{x}}_{j}^{i} $ 的重构残差ei.Step 6:按残差ei的升序排列,从中选取前S类样本
$ \overset{\bigcap }{\mathop{{x}}}\, _{j}^{{{\eta }_{S}}}$ ,其中ηS∈[1,C].Step 7:根据公式(9) 计算S类训练样本
$ \overset{\bigcap }{\mathop{\boldsymbol{x}}}\, _{j}^{{{\eta }_{S}}}$ 的权值,建立如公式(10) 所示的加权矩阵$\mathit{\boldsymbol{\overline M}} $ 嵌入CRC中,如公式(11).Step 8:将选出的S类训练样本
$ \overset{\bigcap }{\mathop{{x}}}\, _{j}^{{{\eta }_{S}}}$ 重复步骤Step 4和Step 5.Step 9:最终根据公式(4),判断测试样本
$\overline{{y}} $ 的类别. -
此方法与二级加权CRC类似,只是在第二阶段用LRC分类识别,相比前种方法,识别性能更好,算法具体步骤如下:
Step 1:将各类训练样本
$\boldsymbol{X}_{j}^{i}\in {{\mathbb{R}}^{m\times n}} $ 和测试样本$\boldsymbol{Y}\in {{\mathbb{R}}^{m\times n}}$ 分别矢量化为$\boldsymbol{x}_{j}^{i}\in {{\mathbb{R}}^{m\times 1}} $ ,$ \boldsymbol{y}\in {{mathbb{R}}^{m\times 1}}$ .Step 2:利用PCA对xji和降维,得
$ \boldsymbol{x}_{j}^{i}$ 和$\overline{\boldsymbol{y}} $ .Step 3:根据公式(9) 计算各训练样本
$ \boldsymbol{x}_{j}^{i}$ 的权值,建立如公式(10) 所示的加权矩阵M.嵌入CRC中,如公式(11).Step 4:基于加权CRC,由公式(12) 求解编码系数
$\mathop {\bf{\alpha }}\limits^ \wedge $ .Step 5:将
$\overset{\wedge }{\mathop{\boldsymbol{ }\!\!\alpha\!\!\text{ }}}\, $ 关联于各类训练样本的稀疏系数αi代入公式(3) 分别计算$ \overline{\boldsymbol{y}}$ 与每类训练样本$\boldsymbol{\bar{x}}_{j}^{i} $ 的重构残差ei.Step 6:按残差ei的升序排列,从中选取前S类样本
$ \overset{\bigcap }{\mathop{\boldsymbol{x}}}\, _{j}^{{{\eta }_{S}}}$ ,其中ηS∈[1,C].Step 7:将选出的S类训练样本
$ \overset{\bigcap }{\mathop{\boldsymbol{x}}}\, _{j}^{{{\eta }_{S}}}$ 分别根据公式(6) 求解重构系数${{\overset{\wedge }{\mathop{\boldsymbol{ }\!\!\alpha\!\!\text{ }}}\, }_{{{\eta }_{S}}}} $ .Step 8:按公式(7) 分别计算测试样本
$\overline{\boldsymbol{y}} $ 与S类训练样本$ \overset{\bigcap }{\mathop{\boldsymbol{x}}}\, _{j}^{{{\eta }_{S}}}$ 的重构误差βηS.Step 9:根据公式(8),判断测试样本
$\overline{\boldsymbol{y}} $ 的归属.
3.1. 二级加权CRC方法
3.2. 加权CRC与LRC相结合方法
-
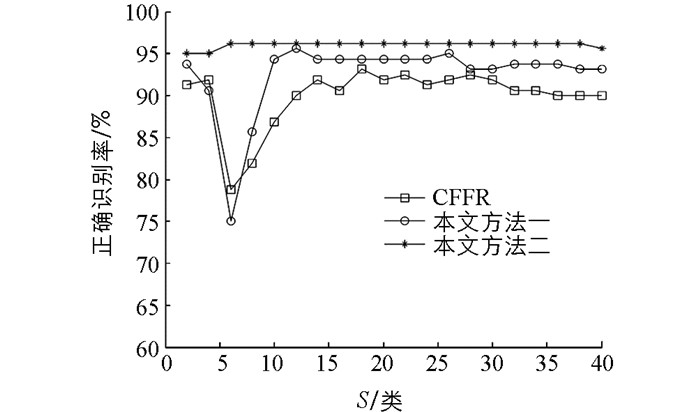
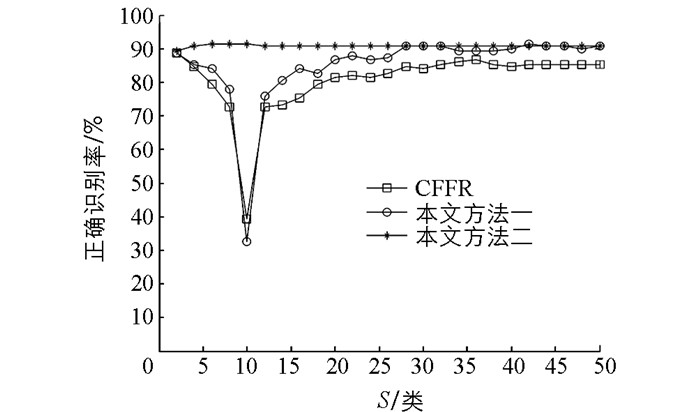
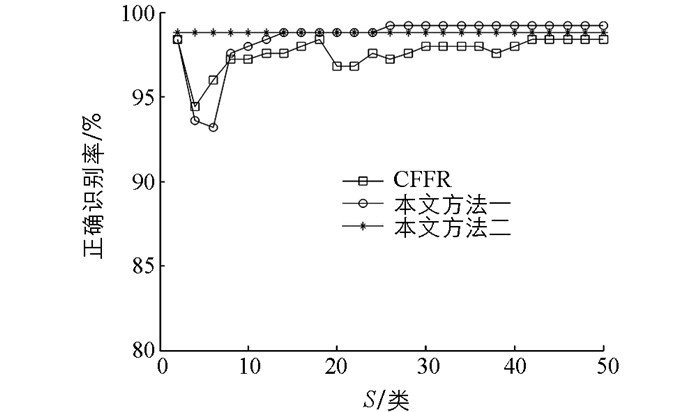
实验选用MATLAB 7作为仿真平台,分别在ORL,FERET及AR人脸库上对本文提出的两种方法和CFFR[20]进行了性能比较. ORL库有40人,每人包含10幅不同表情、姿态、角度的人脸图片,大小均为112×92,如图 1所示.实验取每人的前6幅,共240幅作为训练样本,余下的160幅作为测试样本. FERET库比较庞大,这里选择前50类,每人仅取7幅不同的人脸图像,这7幅图像的名称带有“ba”,“bd”,“be”,“bf”,“bg”,“bj”,“bk”标记.该数据库人脸差异主要表现在光照、表情、角度等方面,图片大小均为80×80,如图 2所示.其中每人的前4幅,共200幅图片用作训练样本,余下的150幅则为测试样本. AR库共120人,实验选其中50人,每人除包含有不同表情、光照等差异的图像外,还有不同程度的遮挡,如图 3所示.图片大小均为40×50.取每人前13幅图像中非遮挡图像任意4幅,遮挡图像随机4幅,共400幅图像用作训练样本,余下的250幅则为测试样本.首先在3种数据库上分别将原始图像降维到40,对比了当选择不同的二级类别数S时,3种方法的识别效果(图 4-6).
从图 4、图 5、图 6中看出本文提出的两种方法均比原算法[20]在识别率上有不同程度地提升.这是由于在协同表示时,考虑了训练样本与测试样本的相似信息对识别的不同贡献,通过构建加权矩阵权重不同样本,嵌入在CRC中,使分类更有效.比如在ORL库上,当S=C时,原算法和方法一即等同于一级分类,识别率分别为0.9和0.931 3,方法一相比原算法提高了近4个百分点;同样在FERET库上,当S=C时,原算法识别率为0.853 3,方法一识别率为0.906 7,相比原算法提高了近6个百分点.更重要的是在二级分类阶段,当选取的
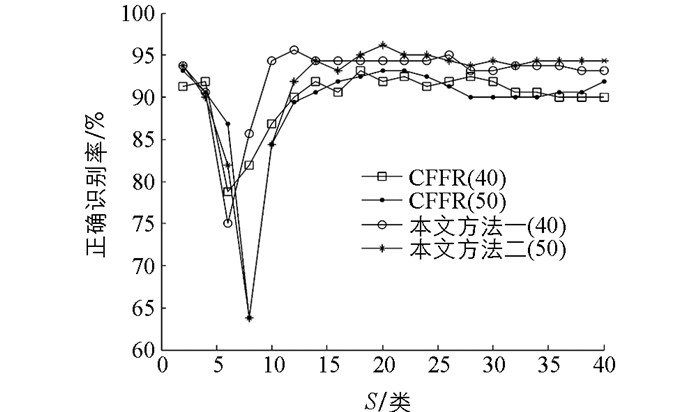
$ S\ll C$ ,方法一相比原算法可以达到最高识别率.比如ORL库,当S=12,方法一识别率达到最高,为0.956 3,而原算法在S=18时为最高,即0.931 3.另外在FERET库和AR库上,虽然原算法在S=2时,识别率最高,分别为0.886 7和0.984 0,但本文方法一依然可在此二级类别数下达到同等的识别率,并都在S=28时,识别率最高,分别为0.906 7和0.992 0.因此足可证明在选取较少的S类目标样本的前提下,方法一的识别效果明显优于原算法.另外,结合图 4、图 5和图 6,不难发现当S变化时,识别效果还是有较大差别.在ORL库上取S=6,FERET库上取S=10,AR库上取S=4时,无论是原算法还是方法一的识别率都存在剧烈抖动,即有一个极低值.起初以为只是个例,通过在试验中将所取原始图像的特征维数增多,发现抖动现象依然存在,且这个极低值会后移.比如ORL库,将图像降维到50,在S=8时,出现极低值,如图 7所示,FERET库、AR库亦同样如此.然后随着S数增多,识别率逐渐提高,趋于稳定.通过分析得出,算法抖动缘于通过PCA降维在一定程度上破环了图像的结构性信息.所以在某一低维特征,以上两种方法在图像有效信息缺失的情况下,应尽可能有完备的样本为前提,因为较少的S类样本协同表示在一定程度上会减弱l2-范数的稀疏性约束.相反,一旦维数增多,图像中用于判别的有效特征变多,较少S类样本稀疏表示的效果反而更好,这时方法一有较大优势.倒是S数增多,识别率下降明显.这也是图 7中维数增多,极低值后移直至消失的原因.因此,二级分类时,在某一特征维数下,只要选取适当数量的S类目标样本,还是能呈现出较高的识别率.
为解决上述算法在图像降维时出现的识别抖动问题,提出在第二阶段使用LRC,通过各类训练样本分别表示及重构测试样本来分类.从图 4、图 5及图 6可见方法二识别率较原算法及方法一都有一定提升,且识别效果更为平滑.在ORL库和FERET库上的实验都在S=6时取得最高识别率,分别为0.962 5和0.913 3.对于AR库,在S=2时,识别率即可达到最高,为0.988 0.因此可以得出方法二在二级分类时,选取的目标样本类别数S满足
$ S\ll C$ ,则很有可能获得更高的识别率.接下来在3种数据库上分别比较本文方法二和其他方法在不同特征维数下的识别性能,如表 1-表 3所示.对于方法二,二级分类数取S=6.
从表 1-3看出,在ORL和FERET库上,方法二在不同特征维数下的平均识别率均高出WSRC1~3个百分点,识别时间相差不多,均在0.01 s左右.而VSCRC方法在低维特征下识别率较低,随着维数增多,识别率明显提高,但相比方法二,均低了5~9个百分点,识别时间更是接近其6倍. AR库上,方法二和WSRC的平均识别率及识别时间几乎相同,VSCRC方法在较高特征维数下同样保持高识别率,但识别时间比方法二和WSRC高出很多.原因在于VSCRC通过不同场景扩张每类样本数的做法,虽然能有效利用样本中的光照、表情等信息,从而获得较好的识别效果,但样本数增多无疑消耗系数求解的时间,使识别时间增加,导致效率下降.综合来看,3种数据库上的实验表明方法二的识别性能更佳.
但是,有一点需要说明,基于本文方法的仿真实验是以选取的训练样本数多于测试样本为前提.一旦训练样本数少于测试样本,加权CRC与LRC的二级方法在识别率上相比其他两种方法就降低了很多,甚至无效了.分析得出是LRC算法的局限性,由于LRC是分别对每一类样本表示重构,如果训练样本少,那么在重构时误差就比较大,识别率自然降低,但是具体问题还有待进一步探究.