





-
开放科学(资源服务)标志码(OSID):

-
在信息时代,推荐系统作为缓解信息过载的重要手段,已经成为所有新闻、视频、音频、电商、互联网金融等相关平台的标配. 目前正处于一个被推荐系统影响的时代,推荐系统已经渗透到我们生活的方方面面. 个性化推荐从1992年诞生至今,经过30年的不断累积和沉淀,受到越来越广泛的关注和重视,已经发展成为了一门独立的学科.
传统的推荐算法,一般根据用户隐向量和物品隐向量的相似度进行物品推荐,虽然简单易懂且计算复杂度低,却十分依赖用户和物品的交互关系,一旦用户和物品的交互关系十分稀疏将会出现物品冷启动问题; 同时传统的推荐算法利用的信息一般是单维数据,无法做到多方面、多维度数据的融合. 深度学习具有更强的表达能力,无论是对数据的拟合能力或是对数据特征的挖掘能力都要强于传统模型,近10年已经成为最热门的研究方向,学者们将深度学习技术引入到推荐算法中,展开了相关研究. Karatzoglou等[1]对深度学习技术在推荐算法中的应用进行了详细介绍; Brandāo等[2]认为协同过滤算法与深度学习相结合,是推荐算法研究的热门方向; Makkar等[3]将用户在网页停留时间以及页面点击的次数作为衡量用户对该网页感兴趣的程度; Hao等[4]根据用户的滚条拉动次数和用户在网页逗留时间建立线性回归方程来预测用户偏好; 谢金峰[5]、刘丰[6]、程思等[7]、汪菁瑶等[8]研究用户的行为序列来提取用户兴趣,达到提高推荐准确率的目的; 段超等[9]、陶涛等[10]、任胜兰等[11]、张若琦等[12]、刘羽茜等[13]、于蒙等[14]尝试在推荐系统中引入注意力机制提升推荐效率. 在图书推荐领域,孙守川[15]将深度学习与协同过滤算法相结合,建立读者检索借阅模型; 尹婷婷等[16]针对读者兴趣,提出了一种基于深度学习的馆藏资源推荐模型; 丁永刚等[17]利用用户学术背景信息,通过SOM(Self-organizing feature Map)神经网络对读者进行聚类,并融入多种特征信息实现图书资源推荐; 沈凌云[18]利用Word2vec提取图书语义特征,采用长短时记忆网络(Long Short-Term Memory,LSTM)对读者借阅行为进行建模; 黄禹等[19]为了计算评分时能够融合更多层的特征,基于深度学习框架改进了矩阵分解算法. 然而,目前深度学习技术大多应用在商品、电影、音乐等领域,在图书领域的应用研究较少,且在已开展的图书推荐应用研究中,存在图书特征提取不够充分、忽视读者行为序列与候选图书的关系、未区分读者对不同图书的偏好等问题. 为此,本文提出了基于读者兴趣挖掘的深度学习推荐模型.
1) 在标准深度学习推荐模型的基础上,基于图书丰富的文本特征,利用谷歌提供的预训练BERT(Bidirectional Encoder Representations from Transformers)模型对图书书名、图书内容摘要等语义特征生成向量表示; 采用长短时记忆网络(LSTM)模型对读者历史借阅记录进行建模; 引入注意力Attention机制为不同图书分配不同权重,为读者“下一次借阅”实现更精准的推荐. 为了缓解新用户冷启动问题,将教材信息引入了读者借阅记录中,在新读者缺少历史借阅行为时,能根据其专业背景提供相关图书推荐.
2) 为了选择最优模型参数,进行了大量的模型训练实验. 通过对不同的负采样比例、隐藏层设置、迭代次数等模型参数进行实验,最终确定正负样本比例为1∶5,隐藏层设置为32 RuLU+16 ReLU+8 ReLU,模型迭代5次,推荐长度为10的参数设置为最优设置,并与不同算法进行对照实验.
HTML
-
BERT模型由谷歌团队[20]提出,是一种可适用于多种自然语言处理任务的预训练模型. BERT模型改进了传统预训练模型学习词向量的表示方法,基于transformer网络结构,创新性地提出了通过双向Multi-head Self-Attention模块来学习词汇的词向量表示,从多角度、多方位理解词义,较好地解决了词汇的一词多义问题,一经提出就刷新了11项自然语言处理任务的当前最优性能记录,被认为是开创了自然语言处理(NLP)领域的新时代.
BERT模型结构如图 1所示,模型的输出代表既有句向量代表,也有每个词汇的词向量代表. Multi-head Self-Attentio层由多个Self-Attention模块构成,多个Self-Attention模块组成的Multi-head Self-Attention层能够将单词在不同模块中获得的词向量进行线性组合,最终生成涵盖多方面语义信息的超强表达能力的词向量; 归一化层用来对神经网络的节点做均值为0,方差为1的标准化处理; 线性转化层起到增强模型表达能力的作用. 预训练阶段,BERT模型通过遮盖语言模型(MLM)和下一句预测(NSP)两个目标任务来完成训练.
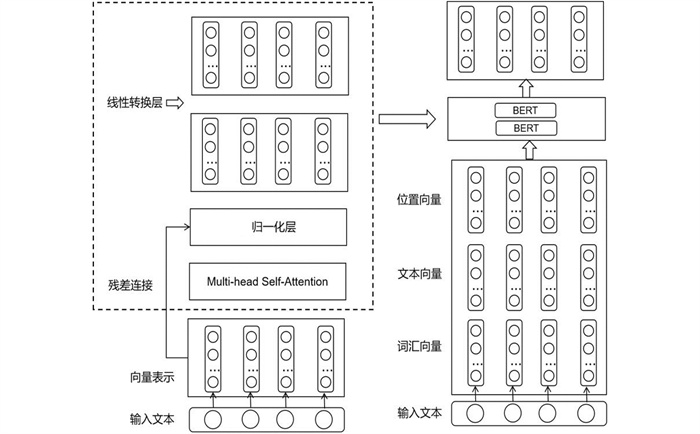
-
LSTM又称长短时记忆网络,是Hochreiter等[21]提出的基础循环神经网络RNN(Recurrent Neural Network)的改进模型,它引入了输入门(input gate)、遗忘门(forget gate)和输出门(output gate)3个“门”单元来决定丢弃或者增加信息. “门”(Gate)由一个Sigmoid神经网络层和一个点乘法运算组成,Sigmoid神经网络层输出0和1之间的数字,0表示不通过任何信息,1表示全部通过,由此来控制信息的通过.
LSTM网络结构如图 2所示,信息从输入门it贯穿到输出门ot,就像传送带一样把信息从前一单元传递到下一个单元,从而实现遗忘或记忆的功能,因此较好地缓解了RNN的梯度消失问题. 计算过程如式(1)-式(6).
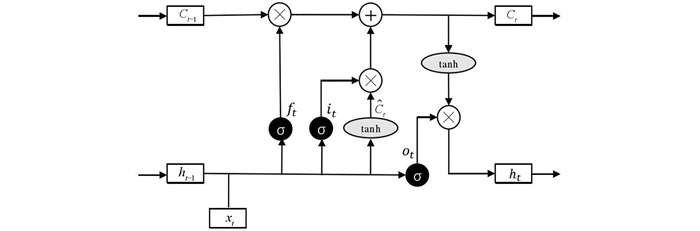
式(1)-式(6)中,ft,it,ot分别代表遗忘门、输入门,输出门,sigmoid和tanh代表激活函数,°代表按元素相乘.xt是当前时刻的输入,ht-1是上一时刻的隐藏状态,
$\widetilde{C}_t$ 是经过tanh后获得的新状态,Ct-1是上一次的单元状态,Ct是更新后的状态,ht是最终的输出. Wxf,Whf和bf分别代表遗忘门中xt,ht-1的权重矩阵和偏置项; Wxi,Whi和bi分别代表输入门中xt,ht-1的权重矩阵和偏置项; Wc和bc代表$\widetilde{C}_t$ 中的权重矩阵和偏置项; Wxo,Who与bo分别代表输出门中xt,ht-1的权重矩阵和偏置项. -
Attention机制,即注意力机制,灵感来源于对人类视觉注意力的模仿. 由于人类眼球的特殊构造,使我们面对庞大的输入信息时,视觉关注的重点是我们偏好的信息,而忽略那些我们不感兴趣的信息. 深度学习中的注意力机制正是利用了人类视觉注意力的原理,为不同对象赋予注意力权重. Bahdanau等[22]最先引入注意力机制应用于NLP领域的机器翻译任务,从2017年开始研究者们尝试在推荐模型中引入Attention机制[23-24],目前注意力机制已成为深度学习推荐技术中的重要技术和研究热点[25-26]. 注意力机制的计算实际上就是一个检索输入(查询Query)到目标任务(键-值对Key-Value)的映射过程. 如图 3所示,Source为数据源,由Key-Value键值对组成. 首先通过相关函数计算出输入序列Key(键)与目标任务Query(查询)的相关性,经过归一化处理后得到每个序列的注意力权重系数,将计算出的权重系数与Key相对应的Value值加权求和,得到最终的注意力权重. 值得注意的是,在某些场景下Key与Value是同一个值.
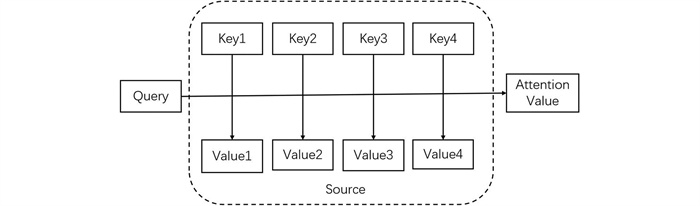
1.1. BERT预训练模型
1.2. LSTM网络
1.3. Attention机制
-
本研究提出的基于读者兴趣挖掘的DRPM模型结构如图 4所示,主要由输入层、特征提取层、偏好提取层、MLP(Multi-Layer Perception)层构建而成. 首先,将读者借阅历史、候选图书及读者人口统计学特征输入模型; 其次,通过特征提取层提取图书文本特征及读者特征; 然后,将已提取的读者借阅图书向量输入偏好提取层挖掘读者阅读兴趣; 最后,将加权后的历史图书特征、候选图书特征及读者特征拼接后输入多层感知机中得到推荐结果.
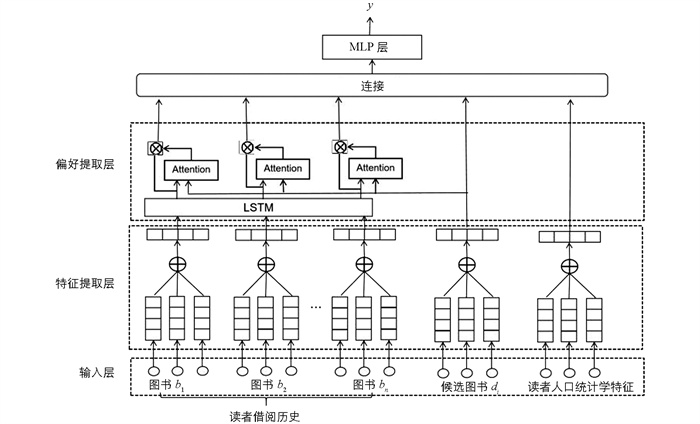
-
模型输入层是能够表达读者和图书特征的信息,包含读者证件号、单位、性别、类别等属性,以及图书书名、摘要等内容特征. 在图书推荐场景中,借阅记录是读者对图书偏好的重要表达和挖掘读者兴趣偏好的重要信息,因此是模型输入层的重要部分. 此外,为了缓解用户冷启动问题,本实验将每学期的教材信息按单位和年级组关联到相关人员的借阅记录中,当新读者缺少历史借阅行为时,模型能根据其专业背景提供相关图书推荐.
-
模型的特征提取层是对输入信息进行特征提取. 图书推荐与其他推荐的最大不同就在于图书本身含有标题、摘要等大量的文本信息,这些文本信息可以通过NLP技术进行特征提取,并生成图书向量表示. 目前,在业界流行且效果得到广泛认可的NLP技术,大都基于深度学习模型来实现. 本实验利用BERT模型提取读者的借阅历史与候选图书的语义特征,从而获得读者借阅行为向量和候选图书向量. 此外,读者人口统计学特征通过pytorch的embedding模块获得向量表示.
-
偏好提取层通过分析读者行为挖掘读者兴趣,从而学习读者偏好. 首先,将在特征提取层提取的读者借阅图书向量输入LSTM网络进行训练,经过训练后的特征向量再与候选图书进行交互,然后计算每本图书不同的注意力权重,得到符合读者兴趣偏好的图书特征向量.
-
用户的兴趣偏好一般隐藏在用户行为中. 读者的历史借阅行为正是其对图书偏好的具体表现,要想得到读者的阅读爱好,就需要从读者的借阅记录中找出读者与图书之间的关联,挖掘出两者更深层次的联系. 同时,由于读者的借阅行为会随着时间改变而改变,本研究认为读者的借阅偏好受时间序列所影响,因此采用LSTM模型初步提取读者偏好特征.
-
由于读者对不同图书的喜好程度不同,在推荐过程中需要更加关注那些能反映读者兴趣的图书,本文引入注意力机制(Attention)来刻画不同图书对读者偏好的影响. 对LSTM模型提取出的特征,通过增加注意力机制为读者借阅行为赋予不同的权重,越相关的图书分配系数越高,从而区分借阅记录中图书的重要程度,实现借阅行为偏好的动态抽取. 计算过程如式(7)-式(9)所示.
其中,kT表示推荐图书的表示向量k的转置,qj代表读者借阅的第j本书的向量表示; 两者内积后得到的结果sim(qj,k)利用softmax函数进行指数归一化,计算出与候选图书的注意力权重分数aj; c表示最终的读者偏好向量; n代表读者总的借阅数量.
2.1. 输入层
2.2. 特征提取层
2.3. 偏好提取层
2.3.1. LSTM兴趣提取
2.3.2. 引入注意力机制的偏好提取
-
本研究实验运行的硬件环境为Intel Corei9-10900X@4.0 GHz CPU,NVIDIA RTX3080Ti GPU,64 GB RAM; 软件环境基于Pytorch框架,采用Python 3.7版本以及Google提供的BERT-base(Chinese)预训练模型.
-
本研究的数据来源于武汉轻工大学图书馆2017-2021年的真实借阅数据,以及该馆的馆藏图书信息、读者信息等. 对于测试集与训练集的划分,本研究采用留一策略. 测试数据正样本选择读者借阅历史中最近那次的借阅记录,其余作为训练数据正样本. 负采样率训练集按1∶5、测试集按1∶50的比例随机选取. 为保证模型训练效果,借阅记录选择10本以上的读者进行模型实验,共获得736位读者的图书借阅记录. 为了保证读者借阅数量的一致性,保留读者最后借阅的10条记录,最终得到的训练集为39 744条记录,测试集为37 536条记录,统计结果如表 1所示.
-
推荐问题一般可以转化成1个二分类问题,常使用交叉熵损失函数作为目标函数,如式(10)所示.
式(10)中,y表示样本的真实标签,1为正样本,0为负样本,p表示模型的预测值.
-
本研究采用命中率(HR)和归一化折损累积增益(NDCG)两个指标作为评价标准衡量推荐性能,两个指标值高低代表推荐结果的好坏. HR表示图书推荐列表中至少有一本能够预测正确,如式(11)所示; NDCG用来评估图书推荐列表中的排序结果,根据图书相关性位置进行评分,评分越高代表推荐效果越好,反之则推荐效果越差,如式(12)所示.
式(11)中,N代表推荐次数,hits(i)代表推荐列表是否命中第i个读者所借阅的图书.
式(12)中,ri代表推荐列表命中第i个读者真实借阅图书的位置.
-
为了选择最佳负采样比例,本研究分别按1,2,…,10等不同数值比例配备负样本数量进行对比实验. 实验结果如图 5所示,每个正样本如果仅选择随机采一个负样本,性能极差; 随着负采样比例增加,系统性能随之提高. 然而,当负采样比例达到5之后,推荐模型的评价指标上升趋势逐步放缓,推荐效果不再明显提升,证明过度的负采样不仅会增加训练开销,同时不会明显提升推荐效果. 经综合考虑后,本研究选择正负样本比例按1∶5进行随机负采样.

-
不同的隐藏层设置会影响推荐效果,本研究尝试了几种不同的隐藏层设置方案,当正负样本比例设置为1∶5时,针对不同的隐藏层方案,HR@10和NDCG@10的值如表 2所示. 实验结果显示,当模型不设置隐藏层时模型性能最差; 随着隐藏层宽度和深度增加,模型性能逐步提升; 隐藏层设置为32 RuLU+16 ReLU+8 ReLU时,模型性能最优,推荐效果最好.
-
为了验证本研究提出模型的推荐效果,选择了以下几种模型进行实验对比:①传统的ItemCF(Item-based Collaborative Filtering)模型[27]; ②传统的PMF(Probabilistic Matrix Factorization)模型[28]; ③深度学习BERT-MLP模型; ④深度学习BERT-LSTM-MLP模型. 上述4种推荐算法与本研究提出的DRPM模型的实验结果如图 6所示.
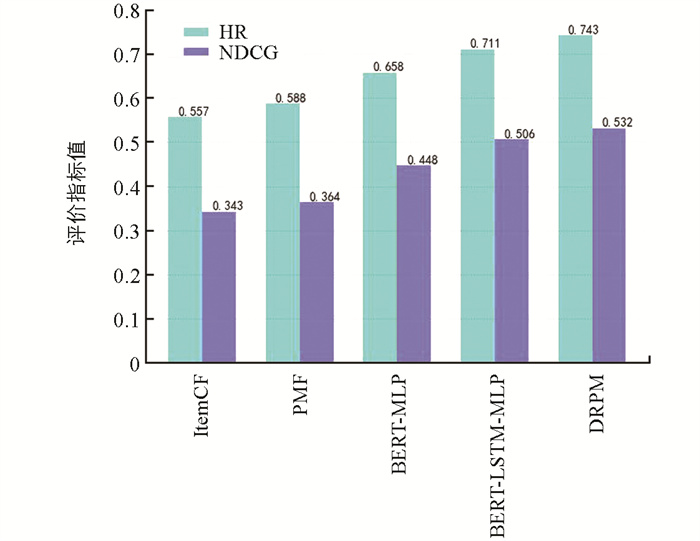
由图 6可知,深度学习模型性能要优于传统推荐模型. 相比传统的ItemCF、PMF模型仅利用人与物之间的交互行为,深度学习模型由于融合了更多的特征,能够挖掘出数据间更多的潜在关系,因此具有更强的表达能力和泛化能力. 在深度学习推荐模型中,加入了LSTM的BERT-LSTM-MLP模型,能够捕捉到序列数据特征,比将BERT模型提取的图书特征向量直接输入多层感知机的BERT-MLP模型效果更好,但推荐效果与本研究提出的DRPM模型相比仍有差距. DRPM模型HR和NDCG指标分别达到74.3%和53.2%,由此说明循环神经网络LSTM处理时序数据能够提升模型性能,且注意力机制能够进一步提高推荐效果,同时也说明本研究提出的DRPM模型在图书推荐方面性能优于其他模型.
3.1. 实验环境
3.2. 实验数据与数据预处理
3.3. 目标函数
3.4. 评价指标
3.5. 超参数选择
3.5.1. 负采样比例
3.5.2. 多层感知机隐藏层设置
3.6. 对比实验结果
-
本研究基于深度学习技术,提出了基于读者兴趣挖掘的深度学习推荐模型. 该模型运用自然语言处理技术中的BERT模型对图书文本特征进行向量表示; 采用LSTM模型学习读者的借阅历史,分析读者借阅偏好; 引入注意力机制学习读者兴趣演化,为读者的借阅行为赋予不同的权重,挖掘读者动态的兴趣向量. 同时将教材信息引入读者借阅记录中,缓解了读者冷启动问题. 实验结果表明,该模型在图书推荐上效果好于其他对比模型.
未来的工作将在提高模型可解释性方面进行探索. 可解释性推荐也是目前推荐算法中一个重要的研究方向,解释性强的推荐会增加用户满意度和信任度,从而提高推荐说服力和推荐成功率,未来会尝试在本研究的基础上进行该方面的探索.
 DownLoad:
DownLoad: