





-
近年来随着移动互联网的兴起,各种新闻文章、科学论文等文本数据量爆炸式增长[1],如何让用户快速、准确地在海量互联网信息中获取具有代表性的内容已经成为一个急需解决的问题. 基于此,各种文本摘要算法应运而生.
文本摘要生成是从原始文本中获得最重要的部分并呈现给用户的过程,其目的是减少文本数量,提取出最相关的信息来简化文本内容,节省用户时间. 从文本摘要的获取方式上来看,可以将其分为抽取式和生成式[2]:前者是对原始文本中的句子进行权重计算并排序,最终选择靠前的适量句子来组成摘要;后者是由模型根据文章大意生成新句子,摘要内容可以包含原始文本中不存在的词语或句子.
文献[3]首次提出“自动摘要”概念,开创了文本摘要的先河. 文献[3]认为文章中的词频和单词在句子中的相对位置是衡量词语是否重要的有效指标,最重要的句子就是包含重要词语的句子,而摘要则是将最重要的句子拼合起来. 目前,国内外学者针对抽取式文本摘要任务做了进一步研究[4-9].
WordNet是一个英语词汇数据库[10],基于同义和反义来描述词语和概念间的语义关系类型. 文献[11]用GAN生成文本摘要,引入WordNet增强判别器的作用. 文献[12]提出了一种结合统计特征和阿萨姆语WordNet的单文档阿萨姆语文本摘要. 文献[13]利用基于WordNet的Lesk算法分析单词语义,改进句子排序算法,利用Seq2Seq双注意模型进行联合训练.
在传统抽取式算法中,TextRank算法只考虑文本的相似度,忽略文本的语义特征,从而导致摘要内容过度冗余. MMR算法则提出一种惩罚机制来解决冗余问题,但其抽取的文本摘要存在对原文概括能力不足的问题,且并未考虑诸多因素对摘要内容的影响. 本文基于此提出了一种MMR和WordNet的新闻文本摘要生成算法,有效解决了文本内容概括不全面、摘要内容冗余、关键词提取时出现异词同义的问题,该方法提高概括摘要内容能力的同时降低摘要内容的冗余度,提升了生成摘要的质量.
HTML
-
文献[14]借鉴谷歌的PageRank算法[15],提出了TextRank算法. 其基本思想是将新闻文本划分为词语或句子来构建图模型,迭代各个节点的权重直至收敛,并通过投票机制对这些词语或句子的重要性进行排序. TextRank算法的公式如(1)式所示:
其中:WS(Vi)代表节点Vi的权重,Wji代表两个节点Vi和Vj之间的相似程度,WS(Vj)代表上一个节点Vj的权重,In(Vi)为指向Vi的节点集合,Out(Vj)为Vj指向的节点集合,求和运算代表节点Vi在新闻文本中总的权重[16]. d为阻尼系数,用于做平滑处理,代表某一节点指向其余节点的概率,通常取0.85.
-
TF-IDF算法分为TF和IDF,其中TF表示词频,IDF表示逆向文件频率[17]. 该算法反映了词语在文本中的重要性,也反映了词语在数据集中的重要性[18]. TF-IDF算法的公式如(2)式所示,具体计算过程如(3)式,(4)式所示:
其中:ni,j表示在文本j中词语i的次数,
${\sum _k {{n_{k, j}}} }$ 表示文本j中所有词语的总次数,|D|表示数据集中的文本数量,|{j:ti∈dj}|表示含有词语i的文本数量. -
最大边界相关法(maximal marginal relevance,MMR)[19]的基本思想是在保证句子与新闻文本之间相似性的同时,使文本摘要更加全面和多样. MMR算法公式下
其中:D代表整篇新闻文本,S代表候选摘要句集,Vi代表当前待抽取的句子,Vj代表目前已经抽取出的摘要句,λ是控制MMR算法摘要多样性的超参数,第一个相似度sim1(Vi,D)表示句子Vi与整篇新闻文本的相似度,第二个相似度sim2(Vi,Vj)表示句子Vi和Vj之间的相似度.
1.1. TextRank算法
1.2. TF-IDF算法
1.3. MMR算法
-
本文算法流程图如图 1所示:
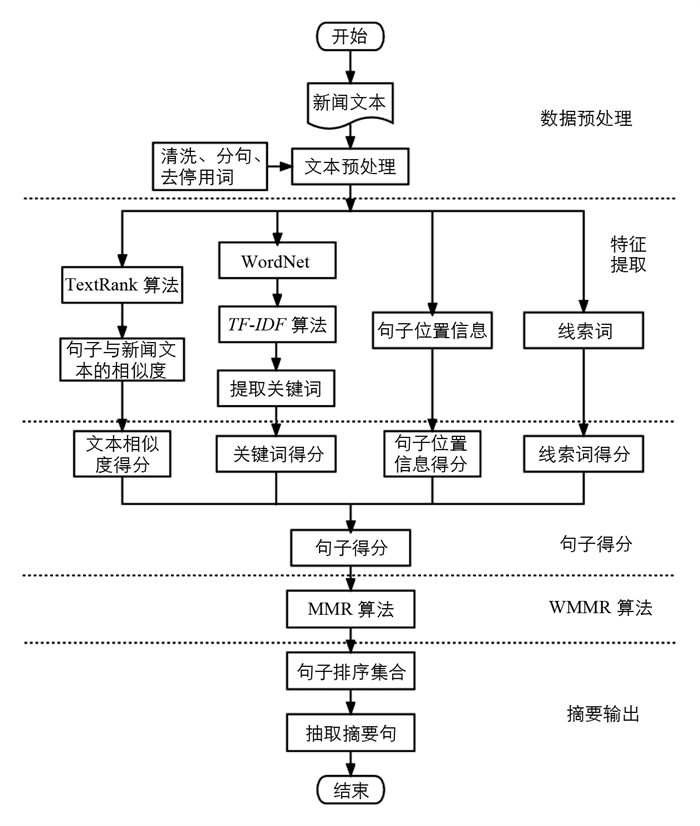
-
数据预处理的主要步骤为:
1) 清洗数据中的多余空字符、网页标记和图片标记,对重复的新闻文本进行去重处理;
2) 将新闻文本和参考摘要分开保存;
3) 首先以句号、感叹号和问号为结束符对新闻文本进行分句,其次采用jieba分词的精确模式对句子进行分词,最后进行去停用词操作.
-
特征提取主要是提取句子与新闻文本的相似度、关键词、句子位置信息和线索词这4部分特征.
-
文本摘要的提取在很大程度上取决于句子与新闻文本中其他句子的相似度. 如果一个句子与其他句子的相似度越高,那么这句话越能概括新闻的大致内容,因此对相似度高的句子赋予更高的权重.
-
从新闻的关键词中大致可以了解该篇新闻的总体内容,含有关键词的句子相较于新闻中的其他句子更能体现新闻的内容,因此对含有关键词的句子赋予更高的权重.
-
新闻中句子的重要性通常与句子位置有关,位于新闻首段和尾段的句子一般是对整篇新闻的总结,因此对这些句子赋予更高的权重.
-
本文将标注新闻来源的词语或具有概括性的词语统称为线索词. 标注新闻来源的词语包括“……网”“……报”“……社”等,具有概括性的词语包括“总之”“综上所述”“总而言之”“归根结底”等. 含有线索词的句子通常具有较强的指向性或总结性,更能概括新闻内容,因此对含有线索词的句子赋予更高的权重.
-
本文通过(1)式所示TextRank算法计算每个句子与新闻文本的相似度,最终得出该句的文本相似度得分.
-
计算关键词得分前先使用WordNet合并同义词,输入分词后的中文词语,输出该词语对应的所有英文同义词序列,统计英文单词的词频,将该词频替换(2)式所示TF-IDF算法中的TF分数.
使用替换后的TF-IDF算法公式来提取关键词. 抽取每篇新闻文本中前20个关键词,将其作为关键词表,并使用kw表示关键词集合. 将单个关键词的权重置为0.1,如果句子中含有a个关键词,关键词权重值Wkw(Vi)置为0.1·a;不包含关键词的句子Wkw(Vi)置为0. 权重计算如(6)式所示:
-
由于本文使用的数据集没有进行分段,并且经过测试得出抽取数据集中的尾句效果不佳,因此本文选择抽取新闻文本的前三句,并分别赋予不同的权重. 使用sp表示句子位置信息集合. 当句子位置处于第1,2,3句时,句子位置信息权重值Wsp(Vi)分别置为1,0.79,0.72(由后面3.3.3节的实验得出);其他位置Wsp(Vi)置为0. 权重计算如(7)式所示:
-
本文从数据集中收集了包含“新华社”“大河报”“人民日报”“央广网”“中国新闻网”在内的373个新闻来源词,收集了包含“总之”“综上所述”“总而言之”“归根结底”等在内的12个具有概括性的词语. 使用cw表示线索词集合. 如果句子中含有线索词,线索词权重值Wcw(Vi)置为1;不包含线索词的句子Wcw(Vi)置为0. 权重计算如(8)式所示:
-
为了使得算法的摘要与原始的文本内容更加吻合,本文对2.3节4个主要特征值分别赋予相应的权重,并设计一个加权算法计算最终的句子得分,算法公式如(9)式所示:
其中:α,β,γ,δ分别为文本相似度、关键词、句子位置信息、线索词得分的加权系数,取值区间为[0, 1],并且满足α+β+γ+δ=1.
-
WMMR算法在MMR算法基础上进行改进,用(9)式中计算得到的最终句子得分W(Vi)替换公式(5)式中的句子与新闻文本的相似度sim1(Vi,D). 替换后的公式如(10)式所示:
-
在计算句子得分后排序,输出排名前三的句子作为该新闻文本的摘要,同时为了确保最终摘要的可读性与连贯性,在输出摘要句时将其按照新闻文本的原始顺序输出.
2.1. 数据预处理
2.2. 特征提取
2.2.1. 句子与新闻文本的相似度提取
2.2.2. 关键词提取
2.2.3. 句子位置信息提取
2.2.4. 线索词提取
2.3. 特征得分
2.3.1. 文本相似度得分
2.3.2. 关键词得分
2.3.3. 句子位置信息得分
2.3.4. 线索词得分
2.4. 句子得分
2.5. WMMR算法公式
2.6. 输出摘要
-
本文采用NLPCC2017 Shared Task3评测任务的数据集(简称为NLPCC2017)进行实验,共有50000篇带有参考摘要的新闻文本. 该文本特点是不分领域和类型,且篇幅较长[20].
-
本文使用ROUGE(Recall-Oriented Understudy for Gisting Evaluation)[21]指标对算法得到的自动摘要进行评估. 该评测方法的内部原理是将专家撰写的摘要作为参考摘要,通过统计参考摘要和自动摘要之间重叠的基本单元数,来衡量参考摘要和自动摘要之间的相似程度,从而得到生成摘要的分数[22]. 它是一种对n元词召回率进行抽象评价的方法. ROUGE的评测方法中最常用的是ROUGE-N(基于N元词). ROUGE-N的公式如(11)式所示:
其中:gramn代表n-gram的长度,{ReferenceSummaries}代表参考摘要,Countmatch(gramn)代表参考摘要和自动摘要之间重叠的基本单元数,Count(gramn)代表参考摘要中基本单元数.
本文采用ROUGE-1(基于1元词)、ROUGE-2(基于2元词)和ROUGE-L(基于最长子串)的结果来评测实验效果.
-
λ因子是MMR算法中的一个重要参数,其取值区间为[0, 1],本文为了选择最佳的λ因子进行了多次实验. 由于λ=0时,忽略文本相似度对算法的影响,不适用于本文算法,因此不考虑λ=0的情况. 文献[23]研究发现当λ因子以小于0.1的级数增加时,ROUGE值变化不明显,因此以0.1的间距选择10个点绘制折线图(图 2).
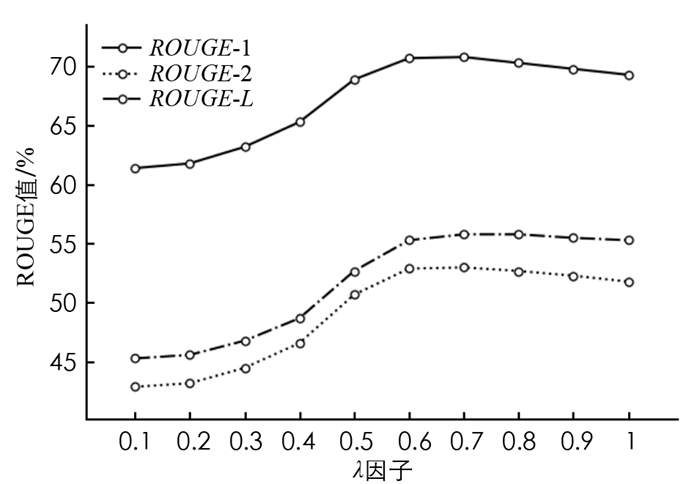
由图 2可以看出,随着λ因子的增大,ROUGE值呈先上升后下降的趋势. 当λ=0.6时,ROUGE-1值达到最佳结果;当λ=0.7时,ROUGE值均达到最佳结果. 因此本文将WMMR算法中的λ因子设置为0.7.
-
本文在提取关键词时采用TF-IDF和TextRank两种算法,在不考虑WordNet对关键词提取算法的影响且文本相似度、关键词、句子位置信息、线索词的加权系数设置为0,1,0,0的前提下,将关键词数设置为20、单个关键词权重设置为0.1,测试两种算法的性能,测试结果如表 1所示.
由表 1对比得出,在提取关键词时,TF-IDF算法的ROUGE值均高于TextRank算法,因此本文采用TF-IDF算法提取关键词.
-
本文分别抽取新闻文本的第一、二、三、四句以及尾句,测试句子位置信息对ROUGE值的影响,测试结果如表 2所示.
由表 2可以看出,抽取第一、二、三、四句以及尾句的ROUGE值呈递减趋势,证明在该数据集中抽取尾句的效果并不理想,因此本文选择抽取新闻文本的前三句.
为了得到最优的句子位置信息权重,在文本相似度、关键词、句子位置信息、线索词的加权系数设置为0.9,0,0.1,0的前提下,进行了5次实验:①将前三句的权重均置为1;②将第一、二、三句的权重分别置为1,0.5,0.5;③将第一句权重值置为1,第二句的权重由第二句ROUGE-1值和第一句ROUGE-1值的比值得出,即0.433 0.548 ≈0.79,同理第三句的权重值为0.396 0.548 ≈0.72;④将第一句权重值置为1,第二句的权重值为0.72(由第二句ROUGE-2值和第一句ROUGE-2值的比值得出),同理第三句的权重值为0.62;⑤将第一句权重值置为1,第二句的权重值为0.79(由第二句ROUGE-L值和第一句ROUGE-L值的比值得出),同理第三句的权重值为0.71. 实验结果如表 3所示.
由表 3对比得出,第三次实验的ROUGE值综合表现最佳,因此本文将新闻文本前三句的权重分别置为1,0.79,0.72.
-
为了综合考虑文本相似度、关键词、句子位置信息、线索词对句子权重的影响,本文根据以上4种影响因子的加权系数α,β,γ,δ(取值区间为[0, 1],并且满足α+β+γ+δ=1)设置不同的加权系数组合. 并通过大量实验来选取ROUGE值最佳的组合,其中具有代表性的11组参数组合结果如表 4所示.
由表 4可以看出,当组别为8,即α=0.5,β=0.15,γ=0.2,δ=0.15时,ROUGE值最高. 证明文本相似度对于摘要生成的效果影响最大,关键词、句子位置信息、线索词对于摘要生成的效果影响相对较小.
-
通过一个实际例子[24]来对比WMMR算法和基线算法的摘要结果. 以句号为结束符对文本进行分句,如表 5所示. 其中,Lead3和Last3算法适用性不强,不予考虑. TextRank,MMR,WMMR 3种算法共同选取了新闻的第1句,故不考虑第1句对算法效果的影响. TextRank算法选取第6,8句,关于车辆行驶方向等描述存在重复,可以看出TextRank算法只考虑文本的相似度,忽略文本的多样性,从而导致摘要内容存在冗余问题. MMR算法选取第8,10句,其中第10句无实质性价值,因此MMR算法追求文本的多样性,可以解决冗余问题,但其抽取的文本摘要存在对原文概括能力不足、描述不准确等问题. 本文提出的WMMR算法选取第2,5句,不存在表述重复问题,并且描述出了标题内容中的“门卫大爷吓一跳”,综合考虑了诸多因素对摘要内容的影响,提高了对新闻文本摘要内容的概括能力,同时降低了摘要内容的冗余度,提升了生成摘要的质量.
-
通过实验得出最佳的加权系数组合后,为了验证算法的有效性,将Lead3算法、Last3算法、TextRank算法、TextRank+Word2Vec算法[25]、MMR算法、MMR+Word2Vec算法[26]、WMMR+Word2Vec算法、WMMR算法进行对比,对比结果如图 3所示.
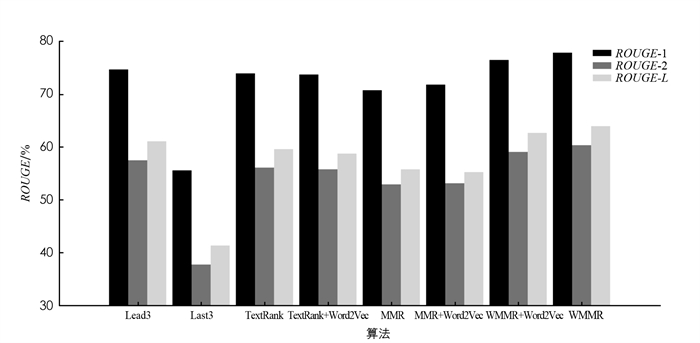
其中,TextRank+Word2Vec算法、MMR+Word2Vec算法和WMMR+Word2Vec算法中的Word2Vec模型采用CBOW训练方式,使用中文维基百科语料库训练,窗口大小设置为10,词向量维度设置为200.
由图 3可以看出,在面对同一数据集时,Last3算法效果最差,ROUGE值最低,证明该新闻文本的结尾部分对整篇新闻的总结性较弱;MMR算法、MMR+Word2Vec算法、TextRank+Word2Vec算法、TextRank算法的ROUGE值较Last3算法有小幅度提升,但稍逊于Lead3算法,证明MMR算法、TextRank算法在抽取摘要时存在不足;Lead3算法在传统算法中效果最好,证明该新闻文本的开头比结尾部分更能代表整篇新闻的内容,但这种仅抽取前三句的方法并未考虑诸多因素对摘要内容的影响. 将本文提出的WMMR算法与Word2Vec模型相结合,效果略逊于WMMR算法,证明Word2Vec模型不适用于本文算法.
本文提出的WMMR算法效果优于上述传统算法,ROUGE值均达到最高,相较于TextRank算法提升4个百分点,相较于MMR算法提升7个百分点,相较于表现较好的Lead3算法也有3个百分点的提升. 这说明该算法既解决了MMR算法、TextRank算法等传统算法在抽取摘要时的不足,又综合考虑了诸多因素对句子权重的影响,进一步证明本文算法的有效性.
-
在“神策杯”2018高校算法大师赛的比赛数据(简称为神策杯2018)、搜狗实验室整理的搜狐新闻18个频道2012年6月与7月的新闻数据(简称为SogouCS)上验证WMMR算法的普适性. 为了保证实验条数的一致性,选取神策杯2018、SogouCS数据集的前50000条数据分别进行测试. 结果如图 4-5所示.

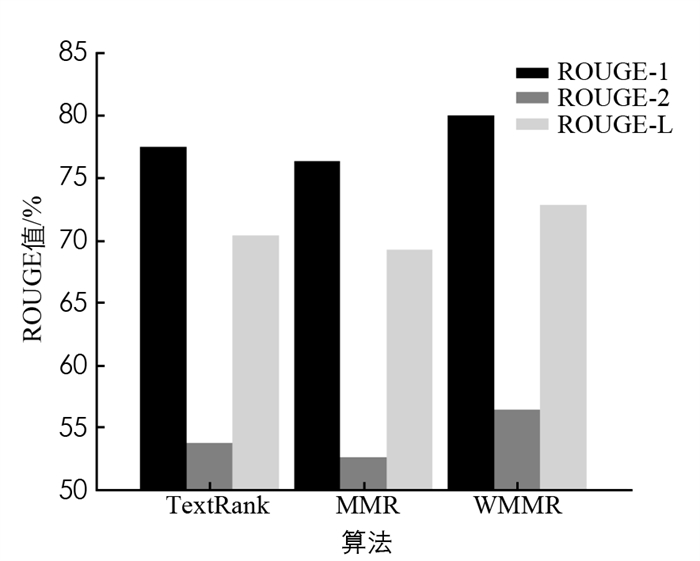
由图 4,5可以看出,在神策杯2018、SogouCS两个不同的公开数据集上,本文提出的WMMR算法效果均优于MMR与TextRank传统算法,证明本文算法具有普适性.
3.1. 实验数据
3.2. 评价标准
3.3. 实验过程
3.3.1. λ因子选择
3.3.2. 关键词提取算法选择
3.3.3. 句子位置信息权重选择
3.3.4. 加权系数选择
3.4. 摘要结果分析
3.5. 实验结果分析
3.6. 普适性验证
-
本文提出了一种基于MMR和WordNet的新闻文本摘要生成算法——WMMR. 该算法综合考虑文本相似度、关键词、句子位置信息、线索词等特征对句子权重的影响,从而优化MMR算法中的句子得分,并在计算关键词得分时引入WordNet合并同义词.
在三个公开数据集上验证本文算法的有效性. 实验结果表明,本文提出的WMMR算法ROUGE值均最高,整体上明显优于其它传统算法,有效地提升了生成摘要的质量. 但本文只进行了抽取式文本摘要的方法优化,后续将尝试进行生成式文本摘要的方法优化.
 DownLoad:
DownLoad: