


 下载:
下载:




-
基于视频流的人工智能研究在人们的生活中显得越来越重要,其用于分析人们的行为,为人们保障安全或提供更便利的服务[1-2].目标跟踪作为众多人工智能的基础,在计算机视觉中扮演着重要的角色[3-4].目标跟踪分为单目标跟踪和多目标跟踪,单目标跟踪着重于处理规模及光照变化的问题,而多目标跟踪算法的重点在于保持被跟踪物体的一致性.现实应用中,进行多目标跟踪面临的最大挑战是身份转换问题,其主要由相似物体间的遮挡和交错造成[5].
针对该种遮挡问题,目前研究者已提出众多解决方法.文献[6]提出轨迹片段置信度的在线多目标跟踪方法,将属于同一目标的轨迹片段关联起来,其主要解决遮挡和面貌相似问题.文献[7]提出一种应用于局部长期遮挡拥挤场景中的多目标跟踪的方法,其以顺序标签为基础,通过设定硬性约束条件对跟踪目标的视频特征进行标记.文献[8]利用身体部位对目标进行实时跟踪,其首先将所探测的行人关联在一起,以获得轨迹片段;然后利用身体部位的关联信息,恢复与部分关联不一致的行人关联;最后,对所有轨迹片段执行实时关联.
目前虽然开展了大量研究并提出多种方法来处理多目标跟踪系统中过度遮挡造成的身份转换问题,但该问题依旧存在,并且没有找到合适的方法应对过分长期完全遮挡的多发性问题.此外,目前大多数方法依赖于学习算法,存在过拟合现象,难以适用于不同场景中.
本文在非重叠摄像中对目标进行识别,以着重解决由过度长期遮挡造成的身份转换问题,本文提出的跟踪方法分为两步.首先利用粒子滤波器还原跟踪人群的轨迹片段,利用可信因子判定是否存在被遮挡现象;然后使用再次识别法将这些片段融合起来,还原被跟踪人群的全部轨迹.
全文HTML
-
按照遮挡时间可以将遮挡分为短期遮挡和长期遮挡.对于短期遮挡,按照遮挡程度可分为部分遮挡和全部遮挡,部分遮挡可以用跟踪目标的局部描述符而不是整体描述符来处理;对于长期的完全遮挡,为了避免不同程度遮挡造成的身份转换问题,需要能够进行与跟踪系统相融合的再次识别功能.
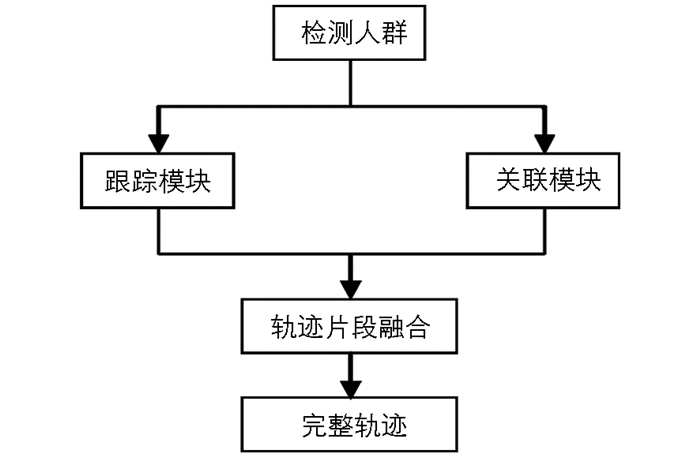
因此,本文提出了基于两种模块(跟踪模块和关联模块)的多目标关联跟踪方法.首先在跟踪模块,在单一摄像机跟踪系统下利用专门的粒子滤波器还原跟踪人群的全部轨迹,并确定遮挡程度.然后,在关联模块,通过局部特征描述符将跟踪模块中的跟踪人群相对应,这些对应可以将属于同一个人的轨迹片段融合起来,还原跟踪目标的全部轨迹,具体流程图如图 1所示.
-
本文多人跟踪方法包含9个重要方面:
1) 相机:包含网络中相机的外在和内在参数
2) 轨迹片段:包含所有从网络相机还原出的轨迹.轨迹由进入点、离开点、进入时间、离开时间和标识符定义.
3) 检查点:包含每个相机视图中待分析表明的标识部分.
4) 位置:包含所有轨迹的位置.
5) 标志:包含从每一个位置的面貌中提取的所有标志.
6) 标志类型:包含所有使用过的标志的信息.
7) 匹配方法:包含所用于测量的用过的匹配法的信息.
8) 匹配分割:包含经过重新识别的配对.
9) 轨迹:包含每个个体的所有轨迹信息.
下面从跟踪模块和关联模块描述整个方法,这两个模块都会涉及到上述9个方面的某些方面.
-
本文多目标关联跟踪系统的第一个模块为跟踪模块,其用于还原每个跟踪个体的轨迹片段,这些轨迹片段是视频帧中表现的同一目标的一连串探测结果.
本文针对每一个跟踪目标使用粒子滤波器还原目标轨迹片段[9].每个跟踪目标均用矩形表示,其中中心点为(x,y),高为h,宽为w.为了根据跟踪目标在时间t-1时的位置预测其在时间t时的新位置,本文采用了运动模型,运动公式如公式(1)和公式(2)所示:
式中,Pos(x,y)和Sp(u,v)分别表示跟踪目标在X轴和Y轴上的位置和速度.
预测的新位置用于预测粒子滤波器中粒子的新位置.然后,根据这些粒子所测出的整体颜色直方图与HSV色彩模型中跟踪人群的整体颜色直方图之间的差别对这些粒子进行加权.根据公式(3),这些加权的粒子用于计算所预计的跟踪目标的平均位置.
式中,Pos(x,y)是跟踪目标的预测位置,wt(i)是位置为(Pos(x,y))(i)的粒子的权值,N是粒子滤波器中使用的粒子数量.
粒子跟踪(头部)的过程图如图 2所示. 图 2中,第一个场景的初始化的粒子框图如第2排第1列所示,第2列是后续帧的粒子滤波跟踪结果.第二个场景的初始化粒子框图如第2排第3列所示,粒子跟踪过程如第4列所示.在跟踪过程中,为了去除低权值的粒子,复制高权值粒子,利用重采样方法,采样后的(头部)颜色粒子即代表真实位置,下一轮滤波,再将重采样的粒子输入到状体转移方程,直接获得预测粒子,也即预测位置.
最后,根据跟踪目标的整体颜色直方图和预测新位置的整体颜色直方图之间的差,计算可信因子,具体如下式:
式中,[H,S,V]pre是粒子滤波预测的直方图,[H,S,V]tar是原来目标位置的直方图,可信因子τ是一个向量形式,维度取决于HSV的维度,本文HSV含有40个bins中(H中15个,S中15个,V中10个),因此可信因子是40×1维向量,通过取向量的模来定义新的预测是否属于同一个跟踪目标,本文的阈值选取4.0,如果可信因子低于阈值,则属于同一个跟踪目标,否则,表明跟踪目标被遮挡丢失,轨迹中止.
-
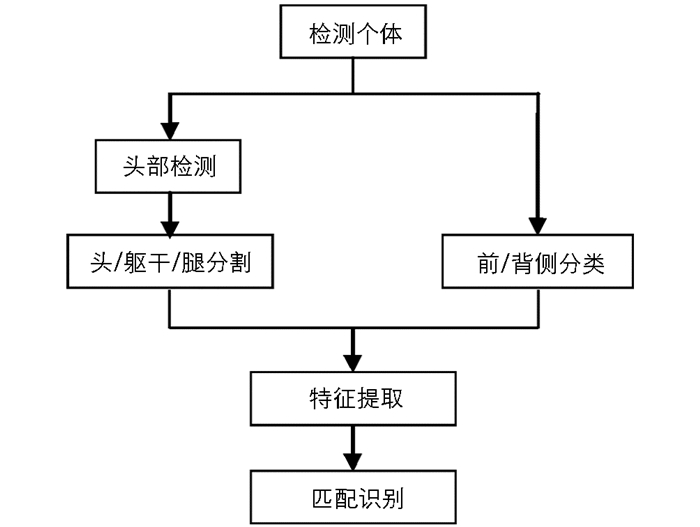
本文多目标关联跟踪系统的第二个模块为关联模块,其用于获取跟踪模块中跟踪目标之间的对应关系.为了重构跟踪目标的整体轨迹,将属于同一跟踪目标的轨迹片段融合起来.关联模块主要由两个步骤组成:提取特征描述符和匹配.首先提取代表人体不同部位的特征描述符,组成特征向量集,然后比较不同人体间的特征向量集,进行匹配操作,该模块的具体流程图如图 3所示.
本文将人体分为以下几种特征组合:正/背侧、头部、躯干和腿,使用这种分割法可以降低拥挤情景下不同目标人体可能发生的混淆,以更好地处理遮挡问题.
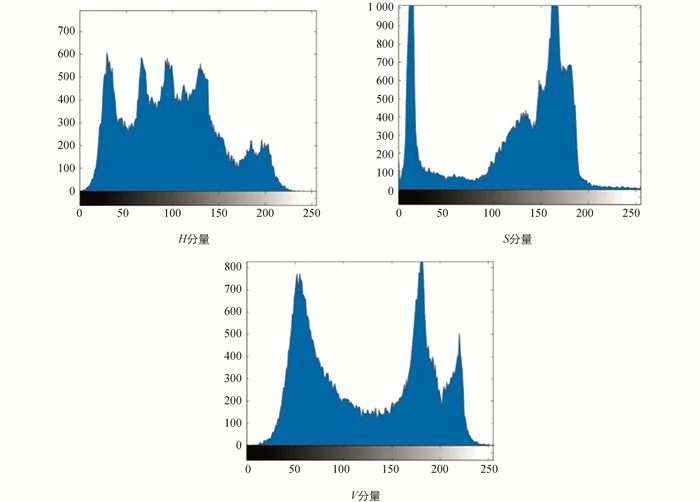
用与同一区域(头对头,躯干对躯干,腿对腿)相符合的HSV颜色直方图和同一个类(正面对正面,背面对背面)作比较.在这些试验中本文采用了在HSV色彩模型中包含3个直方图的描述符(每个部分一个直方图),如图 4所示.每一个直方图都被编入40个bins中(H中15个,S中15个,V中10个).这样,人体的每一个部分都能用40个空间的描述符表示.除去人体的每个部分位置的结构限制之外,用120个空间的描述符号代表个体.
-
由于在拥挤情景下头和肩是人体最明显的部位,因此本文的方法以头部检测为基础,为达到此目的,本文研究图形的结构属性用于头部检测,该图形与最有可能代表头部的提取片段的二维轮廓相符合.
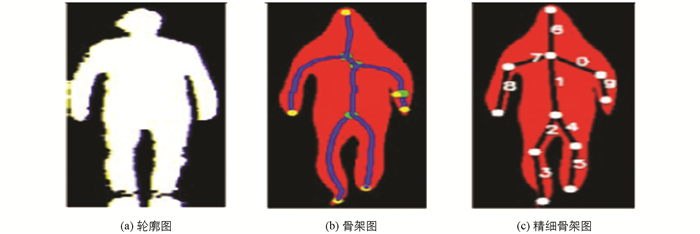
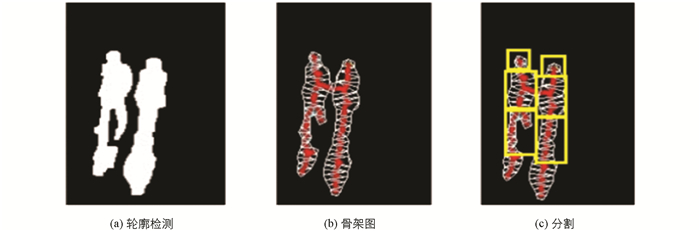
在这种算法中,头部检测分为3步.首先使用文献[10]的背景减除法提取人体轮廓,如图 5(a)所示;其次是使用文献[11]计算几何学的方法计算每一个人体的骨架图,先计算出人体轮廓的终点和分支,如图 5(b)所示,然后得到整体骨架的各节点结果,如图 5(c)所示;最后一步为头部定位,对于有终点的骨架,以纵轴为基准,约束倾斜度,倾斜度满足条件,则标定为头部.
-
为了减少整体描述符对不同人之间造成的混淆,将人体部位分为头、躯干和腿.在人体的每一个部位提取区别于其他部位的描述符,并在匹配过程中将其与相对应的部位作比较,这样的分割是以之前所提到的头部探测法为基础,一旦检测到头部,就很容易定位轮廓,并将身体分为3个部分,即较高的部分是头部,中间部分是躯干,较低的部分是腿.为了表示个体,本文采用了一个人体平面刚性模型,其中人体的3个不同部分都用矩形表示.人体的宽假定为40 cm,高假定为170 cm,其中,头部假定长20 cm,躯干长70 cm,腿长80 cm.
该种模型简单准确,可除去影子带来的反光,以及人体不同部位间比例等造成的额外噪声.过程如图 6所示,图 6(a)为检测的人体轮廓,图 6(b)为计算的骨架图,图 6(c)显示头、躯干、腿的分割结果.
通过使用该模型,可以在拥挤情景(人与人互相遮挡)下将人群进行分割.由于头部检测允许将个人分开,有时候一个人会对应两个头.在这种情况下,问题就变成了检测目标应该对应哪个头.为了解决此问题,本文计算了两个部位之间的重复率.如果重复率高于固定阈值,则只保留离摄像机最近的头.
实际情况下,摄像机的安装位置很大程度上取决于场景的建筑风格.本文考虑最坏情况下,即摄像机安装在天花板上,在此情况下,摄像机的光轴与地面垂直,因此,离摄像机光轴很近的人结构信息很少,骨骼结构退化.这样,个体的头部就会与胸部相混淆,且与终点相对应的明显分块会被视为噪音,此时,就不能检测到头部.该种情况下,同时出现不同目标之间严重遮挡的概率非常低,所以跟踪模块已可以定位到目标,此时,再次识别的关联模块就不是特别需要.
-
第一模块(跟踪模块)的输出是一列有序的位置,它是某个时段内跟踪目标的位置,这些有序的探测可用于将个人的面貌分为正面姿态和背面姿态,这种分类可以通过预测摄像机与跟踪个体的距离得以完成.如果距离逐步增加,则是背面姿态,反之是正面姿态.
为计算此距离,本文采用了3D配准技术. 3D配准用于计算刚性几何变换(平移变换T和旋转变换R),其可以通过计算目标帧与摄像参考帧之间的关系求得.为了预测该转换,本文采用了3D参考帧中代表头部的模型进行计算.头部的大小设定为20 cm×20 cm,中心点在探测人群的脸部. 2D图像点是其配对物,根据目标帧头部与摄像机参考帧相符合的终点坐标进行计算.由于摄像机是校准好的,本文使用文献[12]有关2D/3D点数对的算法计算参数T和R.
头部与摄像机之间的距离用平移变换矢量T中的z来表示.如果z不断增加,则表示目标是背面姿态,反之为正面姿态.
-
在匹配过程中,本文采用基于颜色的再次辨别算法,将相同区域特征描述符(头、躯干、腿、前/背面)进行比较.由于HSV色彩模型的有效性,本文选择其颜色直方图作为描述符,并且使用EMD(Earth Movers Distance)[13]的度量方法来匹配颜色直方图描述符.
再次辨别法是基于K最近邻算法的计算[14].对于每一个Pi,i=1,…,m,m是需要识别的个体的数量,即查询集.每一个个体Pi都与所有m*N个体进行比较,其中N为所有辨别的个体数量,即模型集.从需要辨别的集合中选出K最近邻集合,并计算该集合中各个识别个体的出现次数,如果所选个体的数目高于一定的阈值,且识别个体与所选个体的距离低于指定阈值时,识别得到确认.
图 7给出了基于颜色再识别与K最近邻算法的匹配结果.第一纵栏表示检索图像R,它聚集了个体的不同面貌,而这些个体是模型集中N个个体进行再识别的.每一个体都利用含有n个面貌的集来表示.在图 7例子中,n=8(8横栏).再次识别需要选出检索图像R中面貌的K最近邻域.例如,当k=2时,面貌集的个数为2*8个.本文还计算了该集中这些面貌出现的数量.通过选出出现率最高的个体来做出决定.因此,如果该集的平均距离低于固定阈值,则可确认再次识别.需要说明的是本文所述的匹配程度也即平均距离,平均距离K最近邻算法的样本距离,本文设定的固定阈值为1.0.
2.1. 跟踪模块
2.2. 关联模块
2.2.1. 头部探测
2.2.2. 头/躯干/腿分割
2.2.3. 前/背侧分类
2.2.4. 匹配过程
-
为分析本文提取特征的有效性,与传统的人体全局特征进行比较.比较的特征集分别为传统全局特征[6](GF)、只有前/背侧特征(PF)、只有头部躯干腿的局部分割特征[7](SF)、前/背侧特征与头部躯干腿局部分割特征的组合(PF+SF).由于k值对于最终实验结果具有一定影响,对k值的比较在3.4节给出,k取3最优,对两个公开数据集k值均取3,操作界面如图 8所示.
-
本文使用标准CLEAR MOT度量[15]进行评估.其中,多目标跟踪精度(Multiple Object Tracking Precision,MOTP)的定义如下,用MMOTP表示.
该度量是所有视频帧中,成对匹配目标的估计位置总误差.该度量可以显示跟踪器对目标精确位置的估计能力,与其识别目标配置、保持连续轨迹等能力无关.
多目标跟踪准确度(Multiple Object Tracking Accuracy,MOTA)的定义如下,用MMOTA表示.
式中mt,fp和mmet分别为在时间t处的漏检、误检和错误匹配的数量. MOTA可被视为从以下3个误差比中推导而出.视频序列中的漏检比例,是通过所有帧中存在的总目标数量计算得出,如公式(6),误检的比例计算如公式(7),错误匹配比例的计算公式如公式(8).
MOTA度量将误警率、漏报率和标识切换率结合为一个理想值为100%的单一数值[15];将主要跟踪(MT,>80%)轨迹数量,主要丢失(ML,<20%)轨迹,轨道碎片(FM,轨迹被干扰的时间量)和标识切换(IDS,跟踪轨迹改变与之匹配的时间量)作为评估标准,这些度量定义具体见文献[15].
-
PETS2009是最为常用的多人(或多目标)视频数据,包含简单和复杂的视频场景,如遮挡和相似目标干扰等. PETS2009的跟踪例图如图 9所示. 4种不同特征提取的多目标跟踪方法的量化结果如表 1所示.从表 1可以看出通过增加前/背侧特征(PF+SF),进一步改善了个体的空间描述特性,目标检测性能进一步提高,说明提出的模型比较稳定,漏检和误检更少.而SF[7]波动性比较大,ML等于0.5%,说明是有不少轨迹丢失的.
-
BU-Marathon数据集除了包含一些可见光视频,还包括了一些红外视频,这些视频除了人物,经常出现自行车、摩托车等,是一种较为复杂的公开视频数据集. BU-Marathon的跟踪例图如图 10所示.在该数据集上,上述4种不同特征提取的多目标跟踪方法的量化结果如表 2所示.从表 2可以看出,本文提出的PF+SF依然表现出较好的跟踪效果,漏检和误检更少. SF[7]波动性依然比较大,ML等于1.5%,有更多轨迹丢失,这可能是因为BU-Marathon数据集含有一定数量的红外视频,而红外视频比一般可见光视频提取HSV较为弱势.从总体上看,PETS2009数据集的量化结果比BU-Marathon更优,这是由数据集差异造成的.
-
为了评估摄像机跟踪系统在管理遮挡时的跟踪效果,本文自己采集视频流组成已标记的数据集,视频时长为5 min.在场景中共出现200个不同的个体,对其中的9个人进行跟踪记录,在这些场景中,用9个数据集中已有的个体来模仿部分遮挡和全部遮挡.
由于自采集的视频数据都较为简单,采用准确率和召回率两种评价方法.准确率ρaccu和召回率ρcall分别如公式(4)和公式(5)所示:
式中,Ni表示个体i正确识别的个数,Mi表示个体i返回的个数,N表示所有个体的识别数量,m为个体数.
-
利用公式(4)和公式(5)对整体检测结果进行评估,实验结果如表 3所示.可以看出,与传统的全部特征GF相比,本文提出的头部躯干腿局部分割特征SF的精确率和召回率显著提高,通过增加前/背侧特征(PF+SF),进一步改善了个体的空间描述特性,目标检测性能进一步提高,说明本文提出的模型具有更高的检测性能.
同时,由表 3可以看出,k值的选取对检测结果有较大的影响.在PF+SF情况下,当k=3时,检测效果最好,检测准确率ρaccu达到90.5%,原因是k表示所选邻域的数量,当k太小时,检测结果易受噪声影响,k太大时,失去最近邻信息的意义,所以k=3时效果最佳.
-
表 3给出9个个体的整体检测结果,下面对其个体检测结果进行评估.以PF+SF特征组合为例,当k=3时,计算个体之间的错分关系,得到的混淆矩阵如表 4所示.可以看出,个体1和个体6的检测准确率均达到100%,其他个体的检测准确率均达到85%以上.
-
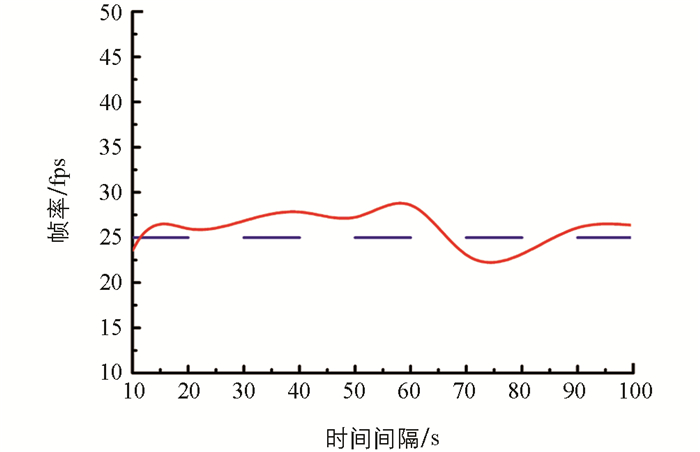
算法的运行速度取决于很多因素,例如处理器结构、内存大小、操作系统、编程语言、编程和优化技术等.因此,将多个使用不同编程语言和不同平台环境的算法进行比较并不可取,一般只能从某个侧面估计运行速度.本文方法在Intel(R) Core(TM) i5 CPU@ 2.89 GHz的8GB内存台式PC机上,运用matlab2007b混合编程.本文方法的PF+SF特征组合基本能达到25fps的视频处理速度,帧率曲线图如图 11所示,即基本满足实时处理要求,使得观察者不会觉得处理后的视频出现顿卡和掉帧现象,满足实际应用的需求.
3.1. 度量方法
3.2. 公开数据集1:PETS2009
3.3. 公开数据集2:BU-Marathon
3.4. 自采集视频数据
3.4.1. 整体检测
3.4.2. 个体检测
3.5. 视频处理速度
-
本文提出了一种针对身体遮挡情况下的多目标跟踪系统.该跟踪系统包括两个模块,第一个模块是跟踪模块,它针对每一个跟踪个体采用粒子过滤器来还原轨迹片段,但是无法确定轨迹片段中的所有轨迹是否都属于同一个人.第二个模块是关联模块,它用于融合轨迹片段,并还原跟踪个体的全部轨迹,关联模块是最重要的部分,其首先探测人体头部,进而将人体分割为头部、躯干和腿3部分,以及将人的面貌分为前侧和背侧两种,之后利用HSV颜色直方图方法提取各部分特征描述符,利用K最近邻方法探测个体之间的匹配程度,以实现轨迹片段的融合.本文的多目标跟踪系统通过使用关联模块,可以避免由严重遮挡造成的身份转换问题,提高检测准确率.