


 下载:
下载:
-
在电网审计领域中,如何根据所发现问题的自然语言描述对审计问题进行规范化的定性和归类是当前尚未解决的关键问题.一方面,随着信息化的快速发展,电网各企业积累了大量的非结构化审计报告文本,文本中包含了审计人员人工记录的审计问题描述、审计问题定性和问题分类.受审计人员个性化语言表达和主观判断的影响,这些文本具有非特征性和歧义性的显著特点,主观的问题分类与国网电力审计问题库的问题类目标准定义存在较明显的不一致.因此,如何基于电力审计问题报告文本对审计问题进行科学规范的分类是提升审计管理质量和效能的现实需求.另一方面,电网企业的审计报告和国网电力审计问题库大多是短文本,信息有限,同时又具有鲜明的行业特征(例如:文本相似度高,分类边界模糊等[1-2]),这些特征给电力审计领域短文本分类带来一定阻碍,有待进一步研究.
近年来,短文本的分类问题得到广泛关注,已对此提出多种方法.其中,通过将短文本向量化来构建文本表示模型是当前的主流方法.该类经典方法包括向量空间模型(Vector Space Model,VSM)、Word2vec模型、Doc2vec模型等. VSM模型最初由文献[3]提出,这种模型将单词以向量的形式表示出来,因此也常被称为词袋模型(Bag of Words,BoW)[3].词袋模型灵活简单,在处理少量文本时能达到不错的效果,但由于词袋模型和词汇数量密切相关,当处理的数据较大时,容易造成维度灾难.文献[4]提出的Word2vec模型是当下比较流行的文本建模方法.这种方法将单词放入神经网络中训练得到词向量,该方法不受词汇量的约束,能够人为设置向量维度,可与其他特征提取方法结合计算词向量,这种模型结构克服了词袋模型的缺点. Doc2vec模型[5]是基于Word2vec模型提出的句向量算法,该算法能从句子、段落等较长的文本中学习得到固定长度的特征表示,从而实现文本向量化.目前,Word2vec模型、Doc2vec模型已应用到中文文本的分类问题中,并取得了较好的分类效果.文献[6]提出了基于Word2vec模型的中文短文本分类方法,将词性作为特征计算加权向量.这种方法适用于词性对分类结果有很大影响的问题,比如情感分析领域中,对分类结果有较大影响的形容词和副词应具有较高权重,但不太适合于以反映客观事实为核心的审计报告类公文.文献[7]在Word2vec模型以及信息增益的基础上,考虑了同义词集以及词语位置信息,并结合特定规则调整词语的特征权重,以决策树作为分类器对审计文本进行了分类.文献[8]提出了改进的Doc2vec模型,并结合专业词典增强文本特征以实现专业领域文本分类.但是,这些方法均不太适用于分类标签多,分类标签具有层次结构,且训练数据集有限的电力审计分类问题.
由于审计报告文本存在审计问题主观定性、审计问题详细描述等粗、细粒度不同的属性,国网电力标准问题库文本也存在审计问题一、二、三级类目等不同粗、细粒度特征,可考虑对不同粒度属性分阶段处理实现分类.基于类似的分阶段分类思想,一些现有研究将粗、细(coarse-to-fine,CTF)策略[9]应用于分类过程,提出两阶段分类模型.文献[9]采用粗、细两阶段分类法对医学细胞图像实现了分类,粗粒度分类阶段采用聚类算法对原始数据集进行了粗粒度的划分,细粒度分类阶段采用卷积网络对粗粒度数据集进行了进一步分类.文献[10]提出了一种基于两阶段学习的半监督支持向量机分类算法,该算法第一阶段采用标签传播算法去除数据噪声,第二阶段采用支持向量机对去噪数据进行分类.但是,这些方法并未针对粗、细粒度属性进行分阶段分类的设计,不太适用于电力审计分类问题.
本文从电力审计文本存在的多种粒度属性共存、文本相似度高、文本特征类间分布差异较大等特点出发,提出一种两阶段电力审计分类方法.具体来说,本文针对两类审计文本展开研究.第一类审计报告文本数据包含待分类的所有问题样本,每个样本包括主观问题分类、主观问题定性、主观问题事实描述3项.根据这3项属性的层次结构关系,本文将主观问题分类视为粗粒度属性,将主观问题定性和主观问题事实描述视为细粒度属性.第二类国网电力审计标准问题库文本数据包括一级类目、二级类目、三级类目3项.同样基于不同级别类目之间的层次结构关系,比如一级类目“人力资源管理”下可包含“福利保障管理”等多个二级类目,每个二级类目下又可包含类似“超计划、超范围、超标准劣质福利”等多个三级类目,本文将一级类目视为粗粒度属性,将二级类目和三级类目视为细粒度属性.本文所提方法将对粗、细粒度属性分成两个阶段进行分类处理.将本文提出的方法应用到2016年国网重庆市电力公司审计问题汇总数据,结果表明,该方法能够提高审计问题的分类准确性和计算速度,实现非结构化电力审计问题的标准化归类.
全文HTML
-
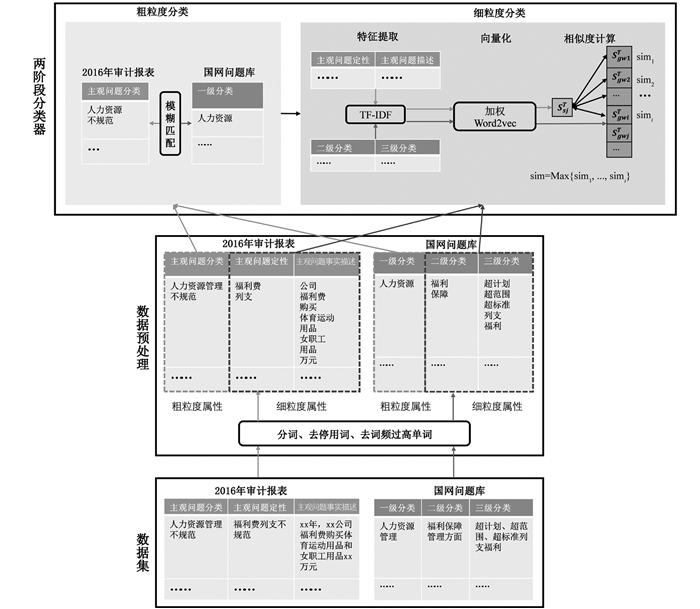
本文提出的两阶段电力审计短文本分类方法包含粗粒度分类、细粒度分类两个阶段(如图 1所示).在第一个粗粒度分类阶段,针对粗粒度属性进行处理,采用不考虑语义信息的模糊匹配方法[11],通过字符串近似查找将审计报告中的审计问题预归类到标准问题库中的一级类目.在第二个细粒度分类阶段,首先将粗粒度分类的结果用于词频—逆文档词频(Term Frequency-Inverse Document Frequency,TF-IDF)算法[12]的文本特征项权重计算,然后将获得的关键词权重与Word2vec方法结合进行文本特征向量化,最后采用余弦相似度计算审计报告中的审计问题和粗分类结果中所包含的二、三级类目的对应细粒度属性的相似程度,从而得到最终分类结果.
-
由于审计问题报告中的粗粒度属性(即审计人员主观判定的审计问题分类和审计标准问题库中的问题一级类目)具有较强的相似性,因此可采用模糊匹配方法[13]对审计报告中的问题进行粗粒度分类.模糊匹配适用于不考虑语义信息,通过计算字符串相似性的方式来衡量两个文本的匹配程度,匹配程度越高表明两个文本字符串越相似,越可能属于同一类.编辑距离算法(Levenshtein Distance算法)[11]是一种经典的模糊匹配方法.编辑距离是指两个字串之间,由一个转成另一个所需的最少编辑操作次数.这里的编辑操作包括将一个字符串转换成另一个字符串,插入一个字符,删除一个字符.通常编辑距离越小,两个字符串的相似度越大.
针对两个给定的字符串,首先计算这两个字符串的编辑距离.由于编辑距离和相似度成反比,因此可采用如下公式将编辑距离转换为相似度值sim:
其中,ld是字符串str1和str2的编辑距离,sim∈[1, 100].通常,如果sim值大于某个相似度阈值(通常设为60)[11],则判定两个字符串模糊匹配成功;反之,匹配失败.
采用模糊匹配方法将审计问题与标准问题库中一级类目进行匹配,可以得到多个候选分类结果,从而缩小分类的计算空间.比如,在审计报告中,审计人员将某个审计问题主观定性为“工程管理不规范”,采用模糊匹配在标准问题库中得到“工程项目管理”和“工程财务管理”两个可能结果.这样,只需要在这两个一级类目下去进一步匹配二级、三级类目,得到最终结果.
-
在细分类阶段,为了在粗分类结果下进一步细化分类结果,得到定性更准确的二、三级分类结果,需要进一步比较审计报告文本和审计标准问题库文本的相似性.在这一阶段,本文首先采用TF-IDF算法对审计问题报告和审计标准问题库的细粒度属性进行特征提取,然后采用加权Word2vec模型,通过词向量化和句向量化两个子步骤实现文本特征向量化,最后在粗分类结果的基础上,采用余弦相似度计算审计报告中的审计问题描述和审计标准问题库中二、三级类目对应问题描述的相似性,从而得到最终分类结果.
-
文本的核心信息常常由某些关键单词传达,即可通过抽取关键词得到文本特征.文本特征提取主要根据一定规则抽取文本的核心信息,从而达到降维、简化计算的目的. TF-IDF[12]是一种经典的特征提取方法,该算法实现简单,易于理解,且克服了使用词频衡量单词重要性的缺点,已在文本分析中广泛应用. TF-IDF通过计算特征的词频(Term Frequency,TF)和逆向文本频率(Inverse Document Frequency,IDF)两个指标对特征集合中的每个特征(即单词)进行统计评估,使得每个特征获得一个权值,权值越大的特征通常更加重要,并具有更好的分类能力. TF-IDF的计算公式为
其中:TFdw是单词w在文本d中的词频;IDFdw是单词w在文本d中的逆文档词频,IDFdw=log$\left(\frac{N}{n_{w}}+1\right)$,单词w的IDF值越大通常说明w具有更好的类别区分能力;N为语料库中文本数量总和;nw为语料库中出现单词w的文本数量;TFdw-IDFdw为单词w在文本d中的权重.
经典TF-IDF算法未考虑特征项在不同类的分布差异.如果某一特征项在某个类别中大量出现,而在其他类中出现较少,这样的特征项就可能具有较强的分类能力,应给予较高的权重.因此,本文将考虑审计文本特征在一阶段粗分类结果上的分布差异,通过增加在某一类中频繁出现的特征项的权重来扩大类间区分度.改进后的IDF计算公式为
其中:mc,w代表粗分类结果中类c出现单词w的文本数量;nw代表所有文档中包含单词w的数量;kw代表除类别c外,出现单词w的文本数量;N为文档总量.
-
Word2vec模型[4]是一种经典的基于神经网络的文本特征向量化模型. Word2vec通过重构语义上下文,将词汇空间映射到一个高维实向量空间.但是经典Word2vec模型主要考虑词和词之间的关系,没有考虑单词在文本中的重要程度,因此向量化后的文本特征可能不具有很好的分类效果.针对这一问题,本文将Word2vec模型训练的词向量与TF-IDF获得的权值结合计算单词的加权词向量,计算方式为
其中:veci代表采用Word2vec模型训练的第i个单词的词向量;TFdw-IDFdw(i)是通过TF-IDF计算的第i个单词的权值.
Word2vec包括两种计算模型:Skip-gram模型[4]和Continuous Bag of Words (CBOW)模型[4]. Skip-gram模型采用中心词预测上下文的策略,而CBOW模型采用上下文预测中心词的策略.由于CBOW模型在处理小样本数据集上的表现优于Skip-gram模型,因此本文采用CBOW模型训练词向量.
句向量是句子的向量化表示,可通过每个句子中所有单词的词向量的求和平均作为该句的句向量.计算公式为
其中:senvec代表当前句向量;m表示当前文本中的单词个数;wordveci代表第i个单词的加权词向量.
-
余弦相似度计算是计算文本相似度的常用方法,通过计算向量空间中两个向量夹角的余弦值衡量两个个体间差异的大小[14].本文基于审计问题和标准问题库细粒度属性的句向量化结果,采用余弦相似度计算二者的相似度,相似度最高的类目即为最终分类结果.余弦相似度的计算方式为
其中:senveci是审计问题文本中细粒度属性“主观问题定性”和“主观问题事实描述”的加权句向量;senvecj是审计标准问题库中二、三级类目的加权句向量.
1.1. 阶段一:基于模糊匹配的粗分类
1.2. 阶段二:基于模糊匹配结果的细分类
1.2.1. 基于TF-IDF的文本特征提取
1.2.2. 基于加权Word2vec的文本特征向量化
1.2.3. 基于余弦相似度的相似性计算
-
本文基于国网重庆市电力公司2016年审计发现问题汇总报告和国网电力审计标准问题库两个文本进行实验.其中:国网重庆市电力公司2016年审计发现问题汇总报告是待分类文件,包含21个主观问题分类项、242个主观问题定性项和309个主观问题事实描述;国网电力审计标准问题库是标签文件,包含16个一级分类项、66个二级分类项和276个三级分类项.基于这些文本数据,将本文提出的两阶段电力审计短文本分类方法与Doc2vec模型、Word2vec模型、加权Word2vec模型等3类模型的分类效果进行对比实验.由于审计发现问题汇总报告和国网电力审计标准问题库中包含多种形式的非结构化数据,且存在噪声,因此首先对文本数据进行分词、降噪等预处理.
在数据预处理阶段,首先采用哈工大语言技术平台(Language Technology Platform,LTP)分词工具[15]对审计发现问题报告和审计标准问题库文本进行中文分词.分词过程采用LTP内部分词表和外部分词表结合的方式.在实验分析过程中,外部分词表根据电力审计领域专家知识和审计领域常见词集自行建立.接着采用哈工大的停用词表[16-17]来剔除不相关、无语义信息的副词、虚词等.然后对经过分词和去停用词操作后的词集进行词频统计,剔除掉类似“管理”、“方面”、“不规范”等在绝大多数记录中出现,即对分类贡献较小的高频词汇.
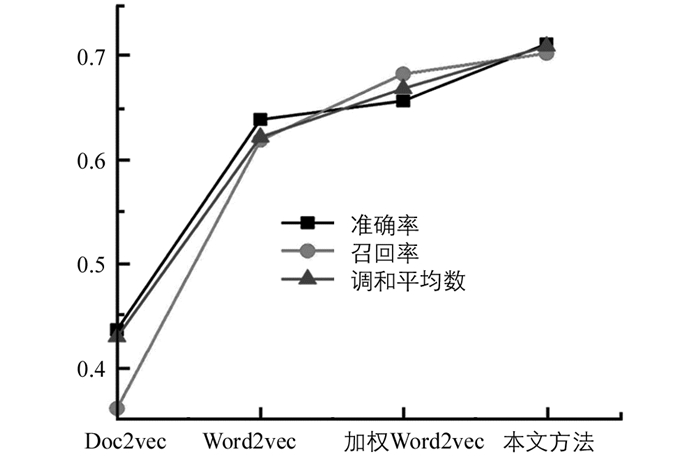
基于预处理后的数据,本文所提方法与其他3个短文本分类方法在分类准确率、召回率和调和平均数等分类性能指标的对比结果如图 2所示.结果表明,本文所提的两阶段电力审计短文本分类方法在各个分类评价指标上均是最优值,表明本文方法较大地提升了审计问题分类性能.
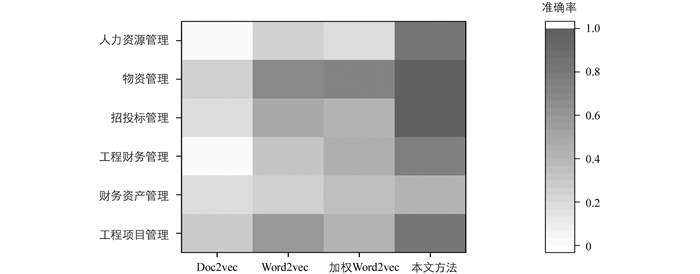
为进一步分析本文方法的有效性,对审计发现问题汇总数据涉及的“人力资源管理”、“物资管理”、“招投标管理”、“工程财务管理”、“财务资产管理”和“工程项目管理”等6个审计标准问题一级类目上的分类性能进行了对比,结果如图 3所示.结果表明,与其他单阶段的分类方法相比,本文提出的两阶段分类方法在所有一级类目上的分类准确率都优于其他方法.表明基于模糊匹配的粗粒度分类能在一定程度上弥补句子向量化后语义信息不充分、特征不明显的问题,从而提升分类效果.
-
本文针对电力领域审计问题标准化归类的现实需求,从电力审计文本信息有限、部分内容相似程度较高、分类特征不明显的特点出发,提出了一种两阶段电力审计短文本分类方法.该方法针对审计文本中存在的粗、细粒度属性,综合运用模糊匹配、TF-IDF、加权Word2vec等技术并对权重计算方式进行了重定义.基于模糊匹配的粗分类结果能在一定程度上弥补传统Word2vec方法文本特征抽取不充分的问题.细分类阶段重定义的加权文本特征提取方式通过调整单词权值,提高单词的类别区分度.基于真实电力审计数据的实验结果表明,本文提出的方法具有更好的分类效果,能够为审计问题的定性和分类提供有力支持,有利于提升审计工作效率,并支持后期审计管理人员的深入分析.