


 下载:
下载:
-
开放科学(资源服务)标识码(OSID):

-
5G技术的快速发展推动了互联设备的爆炸式增长,如移动设备、传感器和物联网终端等,这些设备已广泛融入现代社会的各个领域[1]。然而,移动设备面临着计算能力的固有限制[2],需要将计算任务卸载到边缘网络以提升服务质量。这种对移动边缘计算(Mobile Edge Computing,MEC)的依赖加剧了移动网络的负担,特别是MEC计算资源的有限性难以满足用户不断增长且多样化的计算需求[3-4]。此外,现实世界网络环境的复杂性、多样性以及任务间错综复杂的依赖关系进一步复杂化了卸载过程,凸显了对有效解决方案的迫切需求[5]。
传统的集中式网络架构常面临高延迟及不可预测的服务质量下降问题,而MEC提供了一种可行的替代方案,有望缓解这些挑战[1, 6-7]。相比云计算,MEC具备多项优势,包括通过分布式架构降低延迟并增强对用户需求的响应能力。尽管MEC带来了显著的性能提升,它和云计算仍然面临类似于区块链挖掘过程中观察到的风险[8-9],例如环境因素和网络波动可能导致的任务卸载失败。有效应对这些挑战对于优化5G及未来移动网络的性能和可靠性至关重要。
在评估MEC相关风险时,前景理论提供了重要的理论框架。该理论强调个体在不确定环境下的决策行为,特别是如何在风险与回报之间权衡选择[10]。前景理论指出,个体在面临潜在损失时往往更倾向于冒险,而在面临潜在收益时则更倾向于风险规避。这一特性与MEC中的任务卸载决策密切相关,因为移动用户和网络运营商需评估任务卸载的潜在风险和回报,包括延迟、服务质量和计算资源的可用性[11]。因此,深入理解不同情境下的用户决策行为,有助于制定更高效的任务卸载策略,降低潜在的服务中断风险,从而优化网络整体性能[12-13]。此外,将前景理论应用于风险评估不仅能更准确地预测用户对MEC业务的接受程度,还能促进MEC在5G环境中的广泛采用。
为此,本文提出了一种基于前景理论的MEC混合任务风险卸载和资源分配(Prospect Theory-Based Risk Offloading and Resource Allocation,PTRORA)算法。该算法采用前景理论衡量风险与收益的平衡关系,并基于任务的最大可容忍时延确定其优先级。随后,通过异步优势动作—评价(Asynchronous Advantage Actor-Critic,A3C)算法优化计算资源分配,以提高任务执行效率。本文的主要贡献如下:
1) 针对现实环境中任务卸载失败带来的挑战,本文提出了一种基于前景理论的卸载决策方法,以平衡卸载风险与收益。该方法能够更细致评估风险,改进不确定性下的决策,并通过A3C算法实现动态任务卸载和资源分配优化。
2) 针对任务服务质量问题,提出了一种基于任务最大可容忍时延的资源分配策略,构建一个优先级驱动的高效资源分配框架。该策略通过任务分类提高资源分配的精度,在保证系统性能的同时有效降低时延。
3) 仿真结果表明,PTRORA算法在卸载决策过程中充分考虑了卸载失败风险,表现出优越的性能。实验结果进一步验证了所提算法在降低任务时延和能耗方面的有效性,相较于基线方法,实现了更优的用户体验与系统可靠性。
全文HTML
-
随着云服务向边缘的扩展,MEC在降低任务执行延迟、提升服务质量方面展现出显著优势。这一转变使得卸载优化成为MEC中的一个关键问题[12]。近年来,研究人员对卸载决策的优化展开了广泛研究,重点关注如何在计算资源有限的情况下,实现高效的任务调度与分配[14]。相关研究主要致力于最小化任务延迟,提高能效并优化整体服务质量[15]。
国内外在MEC任务卸载方面取得了诸多研究进展,但MEC中的动态因素,如网络带宽波动和用户移动性,依然可能导致卸载失败从而降低业务性能[16]。为应对这些问题,近年来机器学习算法被引入到MEC任务卸载领域,以增强卸载决策在动态环境下的适应性[17-18]。文献[19]提出了一种面向任务依赖关系的优化策略,旨在提高动态MEC环境下卸载决策的效率和可靠性。该方法动态调整资源分配并优化跨边缘设备的任务执行,采用A3C算法有效降低延迟并提高系统性能。文献[9]探讨了MEC中的区块链挖矿任务卸载问题,基于前景理论构建博弈模型,以优化矿工与MEC服务器的效用,为计算卸载提供了一种新的卸载思路。文献[20]研究了一种最小化长期成本的任务卸载模型,针对不可分割的、延迟敏感的任务以及边缘负载动态性问题进行优化。其方法允许设备自主做出卸载决策,以减少任务丢失率和平均延迟,而无需获取其他设备的任务信息或卸载选择。文献[5]提出了一种面向多类型任务的均衡卸载算法,该算法在MEC内对卸载任务进行优先级划分,并根据优先级和负载情况执行不同的卸载决策,在降低系统时延的同时,提高任务完成率。
此外,博弈论与强化学习也被广泛应用于解决MEC中的资源竞争与协同优化问题。例如,文献[21]提出一种基于Stackelberg博弈的资源分配策略,通过粒子群算法求解最优定价与资源分配,以激励用户共享闲置资源。在强化学习方面,文献[22]采用深度确定性策略梯度(DDPG)算法对车联网中的任务卸载与资源分配问题进行建模与优化,有效降低了任务处理时延。
上述研究为MEC中的任务卸载决策和资源分配提供了有效的基础思路。然而,现有研究方案忽视了MEC任务卸载失败造成的影响,这将可能直接导致系统性能显著下降,特别是在延迟敏感的应用程序中[23]。为此,本文提出了一种基于前景理论的卸载框架以最小化卸载失败对系统性能的影响。该方法根据任务优先级定义,采用A3C算法分配MEC计算资源,确保不同任务的时延需求得到满足,解决了任务卸载失败对系统性能的负面影响,提升了系统的整体稳定性和服务质量。
-
本文所提系统模型如图 1所示,其中包含多个移动设备(Mobile Devices,MDs)和一个移动边缘计算MEC基站。MDs生成两种类型的任务:独立任务和依赖任务。任务可通过无线网络转移到MEC基站进行计算,也可以完全在本地处理。
-
MDs产生多个任务,每个任务具有不同的依赖关系。本文将任务集分为独立任务和具有线性依赖关系的任务,后者采用有向无环图(Directed Acyclic Graph,DAG)表示。针对DAG任务的卸载和资源分配策略,DAG记作G=(V,L),其中V={V1,…,VM}表示包含M个任务的任务集合,L代表任务之间的依赖关系。ea,a+1∈L表示任务Va+1必须在任务Va计算完成后才能执行计算[19],a=1,2,…,M-1。任务Va输入数据大小为Sa(单位为bit),Ca是完成1 bit任务所需的CPU周期数,则任务Va所需的总CPU周期数为Ia=Sa × Ca。计算中间结果记为ΔVa,任务卸载决策集合为α={α1,α2,…,αM},其取值为1或者0,其中0表示任务在本地执行计算,1表示任务卸载至MEC服务器计算。例如:决策集合{0,0,1,0,0}表示第三个任务卸载到MEC上执行,其余任务均在本地执行。对于独立任务,其执行不受依赖关系的约束。表 1为本文所用变量列表。
-
如果任务在本地执行,则卸载决策用0表示。为简化计算,第一个依赖任务被视为独立任务,因为它只影响后续任务。当前驱节点和后继节点都在本地计算时,中间结果传输时间可以忽略不计,则独立任务或依赖任务第一项的本地计算时延可表示为:
其中:Ia为任务所需要的总CPU周期数;f表示本地计算能力。
本地计算的能耗可表示为:
其中γ表示任务Va本地执行时的计算功率。
-
当任务卸载到MEC进行计算时,MDs通过无线链路传输卸载后的任务,则数据传输速率为[19]:
其中:B为MDs和MEC之间无线链路的带宽;σ为信道噪声功率密度;P为MDs的发射功率;h为链路的信道增益。假设上传和下载的信道增益相同。任务卸载到MEC执行由传输时延和计算时延两部分组成,其中上传时延和能耗表示为:
其中Rup为上传速率。MEC的计算时延如下表示:
其中F表示MEC根据任务优先级分配的计算能力。
依赖任务的中间数据会产生一定的下载延迟和能耗,可分别表示为:
其中Rdown为下载速率。因此,任务Va在MEC的总时延表示为:
根据式(5)、(8),任务Va执行的能耗可由下式得到:
MDs的总时延T和总能耗En可以分别表示为:
2.1. 混合任务模型
2.2. 本地计算模型
2.3. 卸载模型
-
前景理论用于描述决策在不确定环境下的行为特点,即决策不仅关注预期结果,还关注预期结果与实际结果之间的差距。当决策处于盈利状态时,决策者倾向于规避风险;而处于亏损状态时,则更倾向于承担风险。本文选用Tversky函数作为A3C模型的奖励函数[24]。参考文献[8],将参考点设为0增益值,任务的效用值表示如下:
其中:gn(t)是适应度函数,即不考虑前景理论的原始价值函数;μ、λ和ζ为前景参数,且0<μ,ζ<1,λ>1。
本文选择Prelec函数作为概率权重函数,其原因与选择Tversky函数相同,两者都用于捕获风险下的决策,同时在风险感知中纳入了不对称性[24]。Prelec函数表示如下:
其中:β为理性参数,其值越小,表示离绝对理性下的理想结果越远;p是任务卸载成功的概率,p∈[0, 1],如果卸载失败将导致惩罚,之后任务将在本地执行。当卸载成功时,适应度值为:
当卸载失败时,适应度值为:
其中D为惩罚因子。由此,gn(t)表示为:
-
当任务卸载成功时,将为其定义优先级,并根据任务的优先级分配MEC的计算资源[5]。优先级κ的定义如下:
其中:Tmax表示当前任务的截止时间;ρ是一个常数,用于对不同类型的延迟敏感任务进行分类。根据3GPP对延迟应用中不同类型任务的定义,本文参照文献[25]的定义将任务分为4类,即κ=1,2,3,4,κ值越小,优先级越高,分配的计算资源越多。
本文将MEC计算资源划分为计算能力相同的整数块,每块的计算能力C=2 MHz,卸载至MEC的任务分配至少C的计算能力,任务在MEC上分配的计算资源表示为:
-
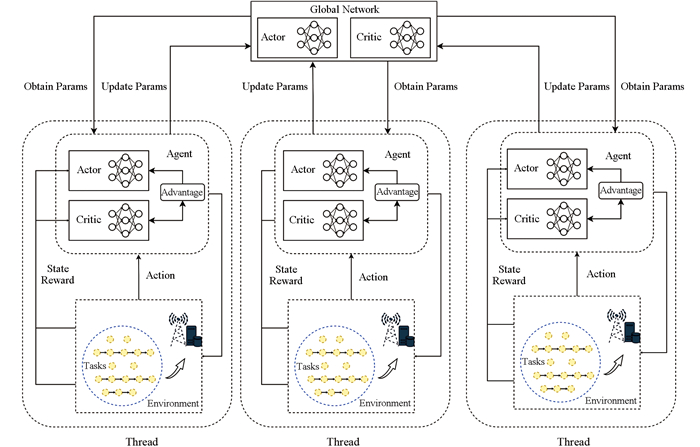
A3C作为一种深度强化学习算法,支持在单机上使用标准的多核CPU或GPU进行多线程异步执行。在该架构下,每个线程中的智能体独立地与环境交互,不断学习并优化卸载策略。具体而言,在每一轮训练过程中:首先,每个异步智能体根据其当前状态和策略选择动作;随后环境根据该动作转换至新的状态,并给予相应的即时奖励;接着,智能体利用这些反馈信息更新全局网络参数,以提高策略的有效性。其核心目标是最大化代理的长期累积奖励,以实现最优决策。A3C模型结构如图 2所示。
本文对状态空间、动作空间和奖励函数定义如下:
1) 状态空间
S={s(t),t∈τ}表示系统空间,s(t)表示在时隙t的状态,包括以下参数:
① 在t时隙,MDs和MEC之间的信道增益,这里假设上传和下载之间的增益是相同的,均为h(t),仅有带宽不同。
② 任务的大小Sa(t),所需的CPU周期数Ca(t),任务发射功率Pa(t)和截止时间TVa,max(t)。
③ 任务的依赖矩阵g。
t时隙的系统状态可以表示为:
2) 动作空间
A={α(t),t∈τ}表示为动作空间。在每一个时隙t中,α(t)∈A包含以下参数:
① 卸载决策α。α=1表示卸载至MEC计算,α=0表示本地计算。
② 根据任务优先级分配的计算资源
$ \mathscr{R}(a) $ 。因此,时隙t的动作可以表示为:
3) 奖励函数
奖励值是评价卸载策略和资源分配策略的指标,与优化目标相关。在本文的MEC系统中,选择Tversky函数作为奖励值。由于奖励值与优化目标负相关,针对时延最小化这一优化目标,我们选择幂函数作为适应度函数,其中η是方程(18)中的常数。奖励函数可以表示为:
综上所述,PTRORA的算法过程可以表示为:
算法1 PTRORA算法
1. 初始化:
(1) 创建全局共享网络:初始化全局Actor网络参数θ和全局Critic网络参数θv;
(2) 初始化异步线程数N,全局步数global_step和线程锁,每个线程拥有独立的本地Actor网络(参数θ)和本地Critic网络(参数θv);
(3) 初始化独立线程的网络参数;
2. FOR EPISODE=1,2,3,…,DO
3. 根据式(20)初始化全局训练参数和环境状态;
4. 异步线程智能体从全局网络中加载参数,设置θ′=θ和θv′=θv;
5. FOR M=1,2,3,…,DO
6. 异步线程智能体根据式(17)执行动作;
7. MEC根据式(18)为异步线程智能体分配计算资源;
8. 异步线程获取奖励和下一状态;
9. 计算本地Actor和Critic网络的梯度,异步更新全局Actor和Critic网络参数(θ,θv);
10. IF global_step mod 3==0 DO
11. 异步线程互斥更新全局网络;
12. 同步本地网络:将更新后的全局网络参数(θ,θv)拷贝到本线程的本地网络中;
13. END IF;
14. END FOR;
15. END FOR。
3.1. 前景理论卸载框架
3.2. 任务优先级定义
3.3. A3C算法
-
本节使用Python进行仿真实验。根据表 1参数设置,本实验中MDs总共生成了M=16个任务,包括独立任务集和依赖任务集。任务大小S和所需的CPU周期数C均为随机生成。MDs节点P的发射功率随机选择为0.1 W或0.2 W,任务截止时间Tmax在50 ~ 200 ms之间随机选择,步长为50 ms。此外,随机生成任务的关系矩阵。实验中,设置异步线程数N=3、成功率p=0.5。同时探讨了不同带宽以及移动终端路径对系统卸载决策的影响。参考文献[26]表征链路信道增益h,将平均信道增益建模为
$ \bar{h}=A_d \times \left(\frac{3 \times 10^8}{4 \pi \cdot f_c \cdot d}\right)^{d_e} $ ,其中:Ad=4.11,载波频率fc=915 MHz,d为MDs距离,路径损耗指数de=3。无线信道增益用瑞利衰落模型表示为$ h_{\text {up }}=0.06 \bar{h} $ 。经典上行链路—下行链路信道模型中[27],下行链路信道与上行链路信道相关,其系数设为0.7。为了评估PTRORA算法,在相同实验环境、任务实例下将PTRORA算法与全本地计算(All Local,AL)、依赖任务卸载与资源分配(Dependent Task Offloading and Resource Allocation,DTORA)、绝对成功卸载计算(Absolutely Successful Offloading,ASO)和随机卸载计算(Random Offloading,RO)算法在任务执行延迟和系统能耗方面进行了比较。各个算法特点如下:
1) AL:所有任务都在本地执行计算。
2) DTORA:基于DQN的依赖任务卸载与资源分配[20]。
3) ASO:不考虑卸载成功和失败概率的卸载方案。
4) RO:任务随机选择卸载到MEC进行计算或本地计算。
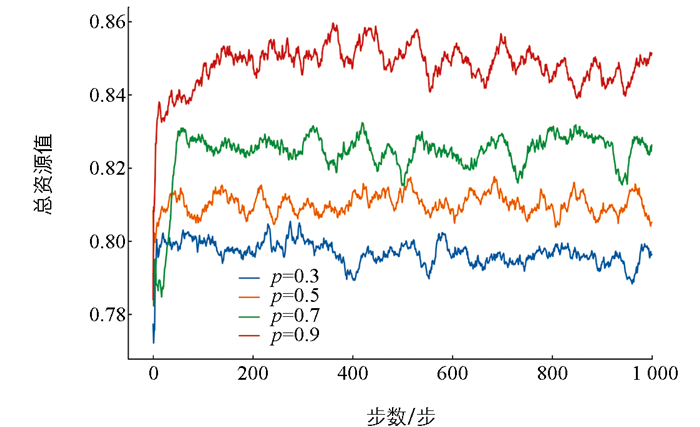
图 3展示了在不同卸载成功率p下,总奖励值的变化趋势。结果表明,卸载成功率对任务卸载决策具有显著影响。当卸载成功率较低时,由于传输失败的概率较高,系统更倾向于选择本地计算,以降低因卸载失败导致任务重试或超时的风险,从而减少整体惩罚。相反,随着卸载成功率的提升,卸载计算能够更稳定地减少任务执行时延,提高资源利用率,从而提升系统获得更高总奖励值的可能性。
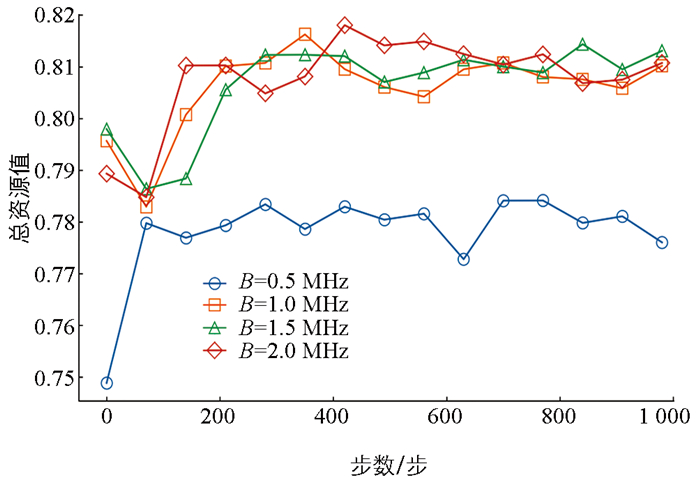
图 4展示了在不同带宽条件下系统总奖励值的变化趋势。结果表明,带宽对卸载决策具有一定影响。在相同卸载成功率下,随着带宽的增加,传输时延显著降低,从而提升系统奖励值。然而,当带宽超过某一阈值时,传输时延的变化趋于平缓,卸载决策更多受到卸载成功率的制约。因此,在低带宽条件下,由于传输时延较长,系统倾向于选择本地计算,以降低因卸载失败带来的惩罚,避免任务时间超过截止时延。而当带宽达到较高水平时,系统将综合考虑本地计算与卸载计算的收益与风险,并基于前景理论进行决策评估,做出更合理的卸载决策。
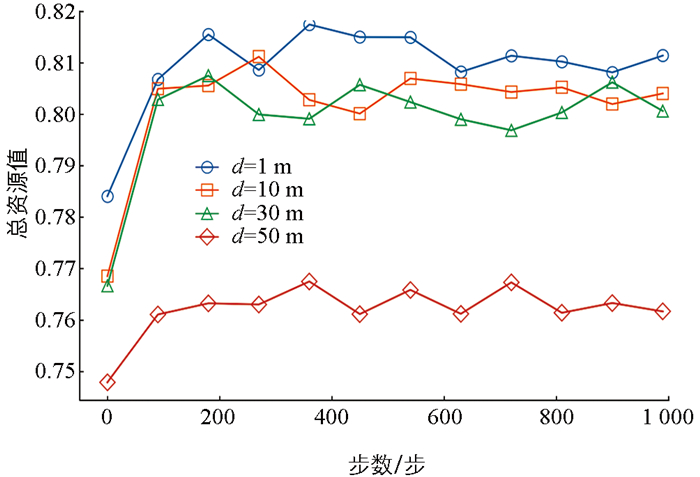
图 5展示了终端移动距离对系统决策的影响。结果表明,随着MDs远离边缘服务器,路径损耗加剧,信道增益逐渐降低,导致传输时延增加,从而影响卸载决策。当距离超过一定阈值时,网络带宽显著下降,此时卸载计算的时延和成本可能高于本地计算。在前景理论的视角下,系统倾向于采取更保守的本地计算策略,以降低潜在风险并减少因卸载失败带来的惩罚。
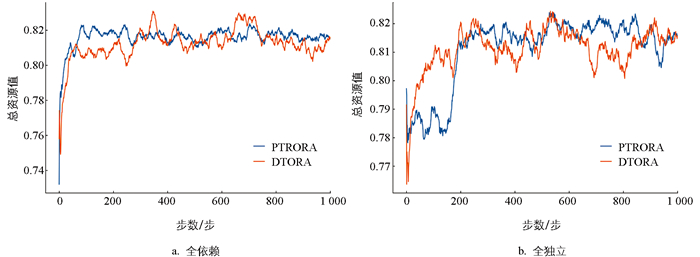
图 6展示了DTORA和PTRORA算法在完全独立决策和完全依赖任务决策两种不同环境下的累积奖励趋势。在这两种环境中,两种算法的奖励趋势表现出高度相似性,表明它们在不同环境中做出了可比较的决策。
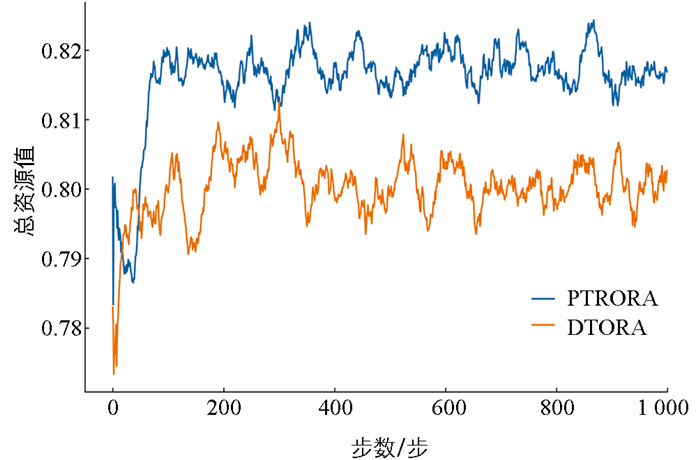
图 7展示了混合环境中DTORA和PTRORA的总奖励值趋势变化。结果表明,DTORA的奖励值约为0.8,而PTRORA的奖励值约为0.82。这表明在混合环境下,尽管DTORA在全独立和全依赖任务场景中与PTRORA的决策表现相似,但在包含不同依赖关系的混合任务环境中,其决策效果略显不足。PTRORA由于在卸载决策过程中能够更精准地权衡任务间的依赖关系与资源分配策略,因此在混合环境下展现出更强的适应性,从而获得更高的系统奖励值。说明针对复杂任务依赖结构的优化机制在提升整体性能方面具有重要作用,进一步验证了前景理论驱动的卸载策略在动态环境中的有效性。
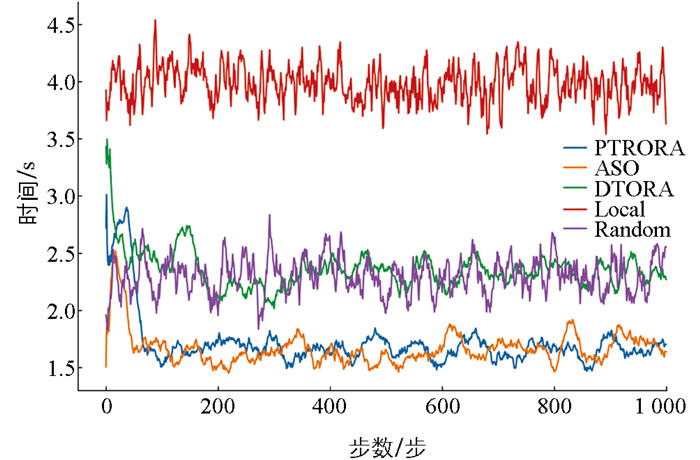
图 8展示了不同方法的总延迟趋势比较。AL计算受限于自身计算能力,其总时延最高。这是由于所有任务均需在本地处理,缺乏并行计算能力,从而导致任务执行时间大幅增加。随机卸载由于具有不稳定性,在此不做具体对比。混合环境下,DTORA由于未能充分优化任务卸载策略,导致其总时延高于PTRORA。相比之下,PTRORA结合前景理论优化决策,使得系统能够做出更为理性的决策,并根据任务优先级合理分配计算资源。因此,PTRORA在降低系统总时延方面表现更优。值得注意的是,PTRORA的最终延迟趋势接近绝对成功条件下的理想时延,这表明本文算法可以在不确定网络环境下做出有效的卸载决策。
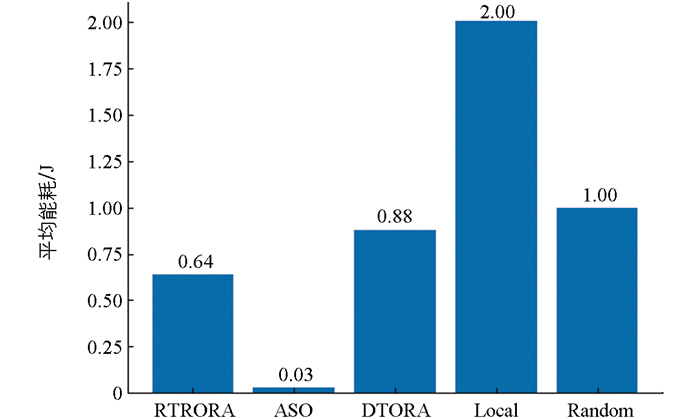
图 9展示了混合环境下5种方法的能耗对比情况。其中AL计算能耗最高,这主要是由于本地计算受限于设备计算能力,导致任务执行时间延长,从而增加了总能耗。RO计算紧随其后。ASO将全部任务卸载至MEC,显著降低了MDs任务执行时的能耗,因此其能耗最低。在混合任务环境中,DTORA由于未能有效优化卸载策略,导致其能耗高于PTRORA。相比之下,PTRORA通过前景理论评估卸载的风险与收益,合理分配MEC的计算资源,从而减少了总能耗。实验结果显示,与DTORA、AL和RO相比,PTRORA的能耗分别降低了27.3%、68.0%和36.0%。
-
本文提出了一种基于前景理论的混合任务风险卸载与资源分配算法。针对任务卸载失败带来的挑战以及异构任务环境的复杂性,将前景理论引入卸载决策过程,以优化风险与收益的权衡。通过A3C深度强化学习算法,依据任务的最大可容忍时延对任务进行分类,并据此分配计算资源,从而提升任务执行效率和用户体验。仿真结果表明,与现有研究成果相比,所提算法有效减少了卸载失败的影响,同时显著降低了任务时延与能耗,验证了其在动态计算环境下的优越性。未来的研究方向将进一步聚焦信道状态的时变性和终端移动性对卸载决策的影响,针对MEC网络中无线信道相关的优化问题进行拓展。