


 下载:
下载:
-
伴随农业信息化的快速发展, 农业科研协同办公平台中, 用户对科研信息的需求量和信息准确度越来越高, 且变化的增幅越来越大.然而面对巨大的网络信息资源, 用户在信息搜索时会查出很多与目标信息无关的网页[1].同百度、谷歌等通用搜索引擎相比, 聚焦农业信息的垂直搜索引擎[2-3]能为农业科研工作者提供更专业性的搜索结果.国外的农业垂直搜索引擎已经取得了一定的成果[4], 如Agriscape Search, WEBAgriSearch等.我国的农业垂直搜索引擎出现相对较晚, 自2007年首个农业搜索引擎上线以来, 目前国内农业搜索引擎主要有农搜网、搜农网等, 仍然处在发展时期, 存在一些不完善的地方, 且尚无专注农业科研的搜索引擎.首先搜索结果中仍包含了大量的无效信息[5], 搜索准确率和用户满意度较低;其次搜索结果过于模式化, 搜索结果都按照规定的分类模块显示, 而忽略了搜索的关键词是否与预设的分类有关联;农业领域信息缺乏, 目前存在的几个主流农业搜索引擎关注点大多在农产品市场价格方面, 而如研究热点、重大成果、实用技术、政策法规、领域热点等相关的信息非常稀少.构建智能化的农业科研办公平台是推动农业科研现代化、信息化发展的重要手段.本文在传统的农业垂直搜索引擎基础上, 保证数据源的精确性, 结合语义关联分析查询机制, 提供对农业信息的精确及时的检索查询, 为农业科研办公的智能化、信息化提供有力技术支撑.在农业科研办公平台中, 小部分数据来自于科研单位办公过程产生的以及手动输入的, 主要数据来源于外部互联网数据接入和抓取, 在不考虑合作数据对接共享的情况下, 如何高效获取平台外的信息成为亟待解决的问题, 而垂直搜索引擎是解决这一问题的工具.
全文HTML
-
现在传统的农业领域搜索引擎对数据来源定位不明确, 从质量不高的数据源中获取大量无效信息, 导致返回给用户的搜索结果包含很多干扰信息, 用户不得不自行对结果的有效性进行二次判断.
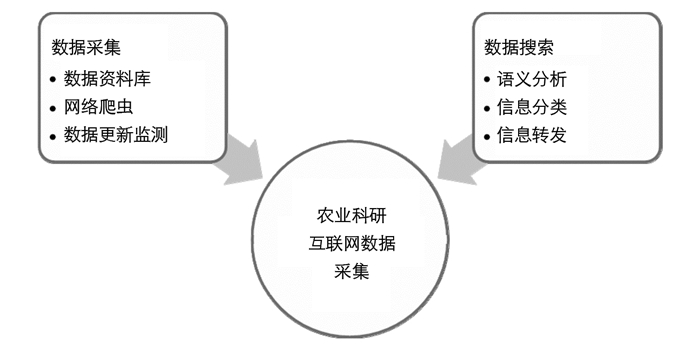
面向农业科研办公的垂直搜索引擎由数据收集模块(数据资源池、爬虫模块, 信息源数据监测模块), 智能搜索模块(语义分析、智能分类、信息转发模块)组成, 以实现数据粗采-筛选-精确搜索的一体化过程(图 1).
-
采用WebMagic+Phantom JS+Redis的网页数据抓取框架, 对数据源资料库中的网站模块进行更新监测和信息抓取.
本系统采用WebMagic爬虫框架[6-8]完成信息获取的基本工作, 通过内置的定时任务执行器对录入的指定网站进行广度优先的网页数据遍历.同时, 结合Phantom JS[9-11]的网页动态渲染技术, 获取html页面行和经过JavaScript渲染的数据源信息, 通过Redis[12-15]缓存框架对爬虫获取的数据进行缓存计算, 在缓存中对新获取数据的网页地址、正文标题及内容的MD5[16-17]加密值与数据库中数据相同项的MD5加密结果进行查重比较, 仅将url不重复且MD5对比结果不同的数据新增存入数据库, 将url重复但MD5结果不同的数据进行更新.开发可视化数据配置界面, 对数据获取需要的各个配置项进行定义, 并提供实时检测功能, 对正在配置的数据源进行实时检测, 及时发现配置上的问题.
系统集成了大量全面且定向精准的数据源:农业农村部、省厅级农业管理部门、农业科研单位、院校的官方网站、综合性及农业专业性资讯网站.同时对数据源网站进行了面向网站子模块的筛选:人工遍历以上数据源的各个子板块直至底层板块(定义详情页的上一级菜单为底层板块), 通过以往人工采集数据的经验指定包含农业领域相关内容多、更新速度快的底层板块, 对其更新内容进行监测和爬取.通过对数据源全面核对以及严格把关, 确保了系统抓取数据的全面性和精确性, 获取的数据丰富而不冗余.
对本地化的数据实时监控, 可视化各个数据源的数据更新情况及有效数据量, 帮助及时发现网站改版、地址变更等异常, 提醒对相应数据源的重新配置, 辅助系统维护, 对保持系统的数据质量起到监督预警的作用.
-
当前大多数的农业信息搜索引擎的检索方法都是进行基于全文检索的关键词模糊查询, 搜索过程相对简单, 但是所得到的结果只有包含搜索的关键词的信息, 相关度仅仅是根据词频来判断, 并且无法判断词之间的先后顺序、间隔距离等条件, 这样的结果往往不全面且信息相关度不准确.
本系统的智能搜索模块按功能分为搜索和转发两大子模块.本系统将神经网络应用到了搜索功能中, 通过计算语义相似度的方式匹配搜索结果, 增加返回信息语义范围的同时按照相关度进行排序, 使用户能更容易获得与之查询内容接近的信息内容;在搜索结果界面提供信息发布功能, 通过调用各个农业信息服务云平台的RESTful Api, 具有信息发布权限的用户可以将对应的信息发布至各个平台的对应分类目标板块中去, 从精准度和方便程度上提高了用户的使用体验.
-
传统的搜索引擎主要使用关键字匹配, 利用全文检索技术对爬虫数据建立索引, 并对索引进行关键词的模糊查询, 然后根据PageRank[18-19], Hyperlink-Induced Topic Search(HITS)[20-23]等面向链接的算法对查询结果进行排序[24].不同于水平搜索引擎的全领域信息搜索, 在农业科研信息垂直搜索引擎中, 被检索数据范围比水平搜索引擎少, 且对返回结果的精确度要求高, 使用面向链接的算法进行搜索会返回很多广告、站点导航等无效页面信息, 对搜索结果产生干扰.本文提出采用基于语义相似度[25-26]的搜索策略, 抛开网页之间的链接关系, 只考虑搜索内容和返回结果之间的语义关联程度.
本策略将搜索分为语义搜索和非语义搜索2类.非语义搜索即搜索内容仅由不含语义的单词或者词组组成, 如“我”“和”“并且”等, 这些词汇在停用词列表中, 在文本分词时已经从语料中去除;如果用户特意搜索此类单词, 本文将使用传统的全文检索模糊查询方法, 直接从数据库中进行匹配.包含停用词表之外单词的搜索内容定义为语义搜索, 该类搜索采用语义相似度搜索法进行匹配.
越专业的领域, 其专业词汇量越是有限, 而专业词汇对语义影响的权重值越高, 在进行语义分析工作之前, 从农业领域中总结出其专业词汇形成高优先级词典, 在分次和关键词提取时, 高优先级词典中的单词凭借其具有的高权值会优先被分词算法提取出来.
然后是将采集的大量农业科研互联网数据文档通过pyhanlp进行分词、去停用词处理, 形成清洁可用的训练语料库.通过word2vec模型对语料库进行词向量空间构建, 形成词向量模型.
(1) 语义分析模型
word2vec是Mikolov等提出的语言模型[27], 通过CBOW模型和Skip-gram模型实现对语料库中所有单词的词向量[28]的计算与表示.
在搜索过程中, 被检索语句ω中的每个词ωi都可以用训练好的word2vec模型计算表示出其在空间S中的向量坐标:
其中n为空间维度, vin为单词ωi在空间S中各个维度上的权值, 则文档中所有词的向量求均值可以用来表示该文档在的向量空间中的坐标:
其中k为文档d分词结果中单词个数.以此为依据计算文档向量S(d)与搜索内容t在空间S中的向量表示S(t)的余弦相似度[29-30], 即为所求的搜索排序依据:
其中ti表示单词t在向量空间中第i个维度的权值, vij(j=1, 2, …, n)为文档中第i个单词在向量空间中第j个维度上的权值.从公式可知, 如此表示文档向量仅考虑了文档中单词以及他们的词频, 并没有将词语排列顺序、前后间隔距离等因素考虑在内.因此本文针对有序查询语句, 采用Doc2vec模型进行语义相似度的计算. Mikolov在2014年提出了doc2vec, 对自己先前提出的Word2vec进行了改进[31].
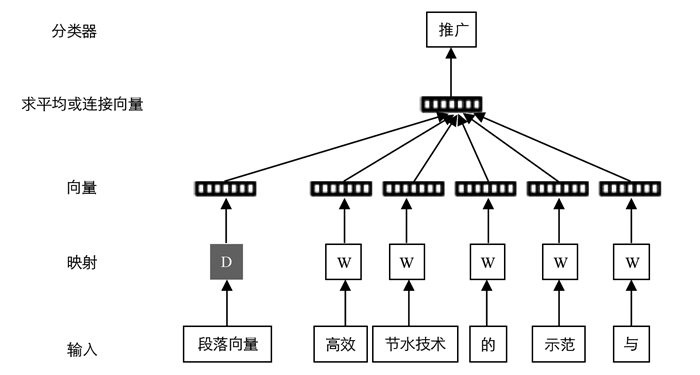
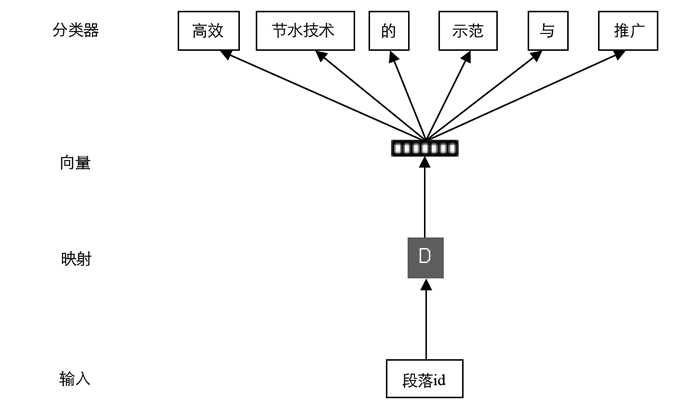
doc2Vec同样具有2种模型, 分别为:Distributed-Memory(DM模型)和Distributed-Bag-of-Words(DBOW模型).如图 2, DM模型跟Word2vec的CBOW(Continuous Bag-of-Word Model)相似, 在已知上下文和文档向量时, 计算目标词出现的概率, DBOW模型则是跟Word2vec的Skip-gram相似, 已知文档向量时, 计算文档中出现随机词组的概率.
与word2vec类似, 通过doc2vec模型计算出各个文档的空间向量, 与搜索语句的空间向量直接进行余弦值计算就可以得出对应的语义相似度.不同的是, 这样的计算结果受文档中词语先后顺序, 词与词间隔的远近等因素影响.而doc2vec相对于word2vec, 在模型的输入层增加了段落向量(Paragraph vector), 它类似于词向量, 用于表示一个段落的向量空间特征, CBOW模型中的训练过程中, 每次仅截取文本中的一部分词进行训练, 但是忽略了上下文中的其他词, 如此训练出的句子的空间向量, 只是文本中各个词的向量均值, 忽略了词序问题.虽然doc2vec的训练也是通过固定滑窗大小截取上下文的一部分词来训练, 但是他在同一个段落的滑窗移动的过程中共享段落向量, 即一段文本通过滑动滑窗会进行若干次训练, 但每次训练输入的Paragraph vector也不会因训练词组的改变而改变.这样段落向量更能表达这段文本的主旨, 也更能满足面向农业科研办公的互联网信息垂直搜索引擎对其理解能力、智能程度的需求.
(2)基于TF-IDF的算法改进
虽然word2vec和doc2vec模型都通过对文档全文分词后的词组进行计算, 但是在文档长度较大, 包含单词数量较多的情况下, 文档的特征比单独的词更复杂, 因此文档向量模型的训练所需训练文本数量大, 在训练样本数量不够充足的情况下会出现文档向量模型表达不准确的问题, 并且训练所需的计算量也高于词向量模型.现在从事农业领域自然语言研究的人员有限, 几乎没有相关的开源数据样本, 在纯人工收集的前提下, 样本数量的增大将会造成前期样本收集的时间成本增高, 对研究实验和生产应用都造成极大的阻碍, 并且对全文进行向量空间表达, 尤其是长文本的表达时, 由于其单词数过多, 文本特征数就有可能越多, 在这种情况下, 即使训练样本充足, 对模型进行训练时也容易产生过拟合现象[32].类似卷积神经网络[33], 在每次卷积计算之后通常会连接一次池化计算, 通过局部特征的提取进行降维, 不但减少模型训练和计算的复杂度, 也降低了模型的过拟合程度.本文提出在农业互联网信息垂直搜索引擎检索模块中通过文本的特征提取, 即通过tf-idf计算得出文档的关键词, 仅用关键词组成的语料来训练doc2vec向量模型, 在减少文档中参与语义相关度计算的单词量的同时又尽量不影响被检索文档的语义, 以此实现在训练样本数量受限的情况下, 增加模型的可靠性.
TF-IDF是计算单词对于其所在文本重要程度的一种统计方法[34-35]. TF表示词频(Term-Frequency), IDF表示逆文本频率(Inverse-Document-Frequency). TF是词条(t)在任意文档(d)中出现的频率. IDF则是反应t在整个语料库中被包含的文档数n, n和IDF呈反比.
通过计算每个文档中各个单词的TF-IDF值并排序选出文档重要度最高的k个词作为保留词, 去掉其他词语, 并对由保留词构成的文档进行训练文档向量模型训练得到各个文档的空间向量表示结果.最后通过计算搜索内容和被检索文本的向量余弦相似度作为语义相似度判断依据, 并筛选删除相似度低于设定阈值的结果, 然后相似度从大到小的顺序对被检索文档进行排序作为查询结果发送给用户.
1.1. 数据采集模块
1.2. 信息搜索模块
1.2.1. 搜索方法设计
-
查全率和查准率是评价搜索引擎性能的主要考核标准[36], 模型运算速度和模型训练速度则是作为模型优化程度的重要评价因素.查全率(recall)又称作召回率, 是衡量搜索引擎返回结果与用户查询内容相关度的能力, 如公式(6);查准率(precision)即为精度, 用于衡量搜索引擎去除不相关搜索结果能力, 如公式(7).
式中R表示搜索结果的信息数量, C表示搜索结果中相关信息的数量, T表示整个文档中的相关信息数(搜索出和未搜索出的相关信息的总和).
precision和recall互相影响, 若precision高但recall低, 查到的信息总量就少, 反之, 查到的有用信息所返回的信息基数就高, 对用户产生的干扰也就越强.因此, 存在一种新的评估指标, F1测试值:
由于垂直搜索引擎数据来自互联网爬虫工具, 信息量巨大, 无法统计互联网当中相关信息的具体数量, 因此将查准率作为评价搜索引擎的重要指标.
-
搭建信息爬虫系统, 以24个高校网站、49个科研机构网站、33个农业管理部门官方网站、23个媒体网站、225个农业商业网站、农业信息网站为数据源, 抓取近10万条近期数据, 人工定义500词的农业领域专业词典, 从总样本中筛选出38 749条与词典内单词相关的数据共63 M.标记10个单词, 10个无序三元词组以及10个完整句(分词后5个有序单词以上)的相关文档.
本实验在Intel i5-4590 CPU, 16GB内存主机上进行.在Python 3.5.4环境下, 安装MySQLdb, PyMySQL进行数据库操作, 安装pyhanlp, jpypel等工具进行分词和词向量处理.
实验步骤如下:
1) 连接mysql数据库, 提取人工筛选出的语料样本;
2) 通过pyhanlp中的crf分词算法, 在基础自然语言词典的基础上, 引入农业词典库, 对38 749条语料数据进行逐条分句、分词;
3) 采用pyhanlp自带停用词库进行停用词过滤并存入txt文档;
4) 人工检查过滤后生成的文档, 对未过滤而应当停用的单词进行记录并添加至停用词列表;
5) 用更新后的停用词文档再次进行过滤, 并通过tf-idf算法进行关键词提取, 提取个数为全文词数的8%;
6) 通过pyhanlp集成的word2vec训练生成词空间向量模型;
7) 用生成的word2vec模型训练doc2vec模型(记录计算时间);
8) 文档向量表示:
① 用word2vec模型表示每条数据中每个分词的词向量, 并求平均值;
② 用doc2vec模型表示每条数据全文分词的文档向量;
③ 用doc2vec模型表示每条数据关键词组的文档向量;
9) 相似度计算:用人工标记所用的50组无序单词/词组以及50个有序整句与步骤8中产生的a~c3种向量模型文档向量进行相似度计算, 统计并计算相似度阈值取0.1~1时, 关键词个数8%时的搜索结果的查准率.
-
实验影响因子有:8-①, 8-②, 8-③ 3种向量模型生成方法、搜索语句有/无序状、相似度筛选阈值.
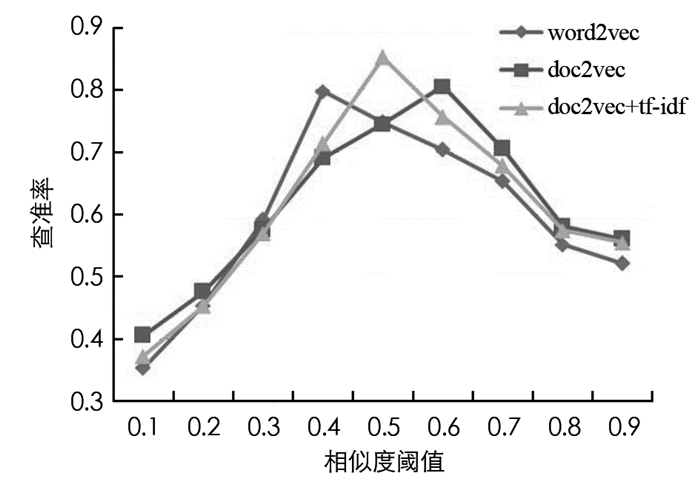
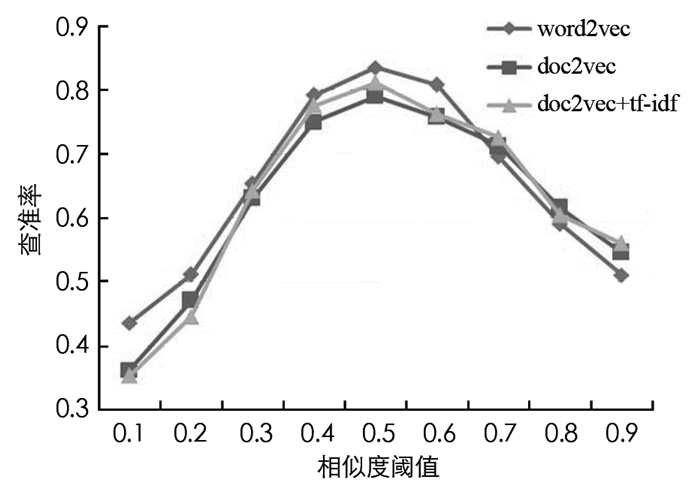
从图 4可以看出, 在搜索内容为有序整句的时候, 3种文档模型的查准率在阈值增加的过程中多呈现先快速增后缓慢减少的趋势.其中word2vec模型增加幅度最大, 在相似度阈值为0.4的时候打到最大查准率;doc2vec模型增幅最小, 在相似度阈值为0.6的时候达到峰值, 其峰值与word2vec模型的峰值相比略高, 但是几乎持平;doc2vec与tf-idf关键词提取相结合的文本向量模型增幅居中, 在相似度阈值0.5时达到峰值, 其峰值高于另外2个文本向量模型.可以判断本文提出的方法在整句搜索时, 有效文本相似度筛选阈值取值0.5时达到最高性能, 即表明其在数量有限的农业语料库优先中表现最为优异, 另外doc2vec模型在收到训练样本数量限制的情况下性能受到较大的负影响.
从图 5可知, 3种模型的查准率在有序和无序搜索时均呈现先增后减的趋势, 无序搜索3种模型的查准率随相似度阈值变化的幅度更为平缓, 且均在阈值接近0.5时达到峰值, 峰值情况下, 各向量模型的查准率从大到小依次为word2vec, doc2vec+tf-idf, doc2vec.本文提出的doc2vec+tf-idf方法在相似度阈值大于0.65时, 具有更高的查准率, 但word2vec模型的查准率峰值更高.
以农业科研领域的文本数据作为语料, 采用领域内的自定义分词词典和停用词表, 使用本文提出的doc2vec与tf-idf提取关键词结合的文本向量模型, 通过有序文本搜索时查准率更高;而基于word2vec均值的文本向量模型在对无序词组进行搜索时有更好的表现.针对不同的搜索场景动态选取对应的高性能搜索方法将进一步提高搜索引擎的性能.
2.1. 评价方法
2.2. 实验设计
2.3. 结果与分析
-
本文通过人工精确定位数据源、爬虫系统自动抓取海量农业信息互联网信息, 通过doc2vec与tf-idf结合的神经网络算法进行语义相似度匹配搜索.实验结果, 证明本方法在有序文本搜索时具有较高的准确性, 但word2vec在无序离散的词汇组合搜索时则有更高的查准率.因此, 针对不同的文本搜索场景选用不同的搜索方法将进一步提高农业科研协同办公平台信息搜索引擎的性能.在下一步的研究工作中, 将对用户搜索内容的有序和无序分类进行判断, 以决策针对性的搜索方法, 达到更高的准确率;对文本进行预分类, 同时判断用户搜索内容的类型, 在同一分类下进行搜索, 通过缩小搜索范围, 降低搜索运算的时间、提升搜索效率.