


 下载:
下载:

-
序列模式挖掘(Sequence Pattern Mining,SPM)是一个广泛应用的热门数据挖掘任务,用来挖掘频繁出现的有序事件或子序列[1-2],在挖掘Web使用模式、分析客户购买行为、挖掘DNA序列等方面有很大的应用价值.由于大数据具有大容量、多样性、高速度、低价值密度和准确性等特征[3-4],每当数据发生变化时,都必须重新运行序列模式挖掘算法,这是因为从旧数据获得的频繁项,在更新的数据中可能变为不频繁项,并且在更新的数据中可能会出现新的频繁项[5].如果序列数据库的规模比较大,则有可能会产生大量的候选序列模式,故传统的SPM不可扩展[6].传统的序列模式增量维护算法不能很好地适应大序列数据库,必须设计分布式挖掘算法来处理大数据[7].
MapReduce是一种遵循分而治之的策略来处理大数据问题的分布式编程框架,它对程序员隐藏了数据划分和分配、任务调度、机器间通信和容错的内部细节,允许没有任何经验的程序员在分布式系统中有效地处理系统的资源[8]. MapReduce模型不仅简化了分布式编程的任务,而且实现了对大数据集更好的处理[9].后向挖掘算法用于高效序列模式的增量挖掘,该算法4个显著的优点:①提供一种简单的方法来检测稳定序列;②引入了唯一的稳定序列性质,即稳定序列的任何扩张也是稳定的;③稳定序列属性,通过跳过对稳定序列的支持计数来提高挖掘速度;④验证了序列新支持计数的过程很简单.
为了使增量挖掘算法可以很好地适应大序列数据库,已经有大量序列模式增量维护的算法研究.文献[10]提出了一种利用MapReduce框架从大数据集中挖掘频繁项集的位向量积算法,该算法运用位向量数据结构来维护压缩的事务,从给定的事务列表中有效地搜索频繁项集,其优点是只需扫描一次数据集.文献[11]提出了一种用于高效序列模式挖掘的纯数组结构(Array Structure for High-utility Sequential,AHUS)和并行策略,该算法运用高效用序列模式挖掘来发现序列数据库中效用值等于或大于给定最小效用阈值的所有序列模式的任务,运用AHUS并行挖掘来同时识别高效用序列模式(High-utility Sequential Pattem,HUSP),具有较好的可扩展性.文献[12]提出了基于云均匀分布式词汇序列树算法的序列模式挖掘算法.该算法使用两阶段MapReduce框架发现序列模式,无需启动多轮MapReduce即可显著提高整体性能,并在云中的机器之间提供完美的负载平衡,实现了极高的可扩展性,并提供了比现有的云端算法更好的负载均衡.
基于文献[12]的研究,通过设计新的CRMAP数据结构和后向挖掘算法,提出了基于MapReduce的高效分布式增量序列模式挖掘(IncSPM)算法,用来解决大数据环境中序列模式挖掘的增量维护问题.文献[12]是一种广度优先搜索算法,它们组合较小的序列产生候选序列,生成可能不会出现在数据库中的候选序列.本文算法通过后向挖掘算法来有效利用先前挖掘生成的序列模式,引入一种高效的CRMAP数据结构来生成出现在输入数据库中有希望的候选对象,以减小搜索空间.基于CRMAP数据结构,设计候选生成规则和早期修剪机制以避免输入数据库中生成错误的候选序列,从而使本文算法具有良好的线性可扩展性.实验结果显示,本文IncSPM在处理时间、内存消耗和可扩展性方面的有实质性的提高.
全文HTML
-
以往的序列模式挖掘MapReduce算法没有处理增量维护问题,不能利用以前挖掘生成的序列模式,每当数据增加时,它们都会在更新的数据集上重新运行算法.在大数据环境中,通过扫描整个数据集来重新挖掘所有序列模式是不可接受的,本文采用后向挖掘来进行序列模式的高效增量挖掘.序列s的更新数据集(Updated Dataset,UD)中输入序列集合称为s的投影pjs,序列s最后一个项目集中的项集称为序列s的结尾ends,输入序列s的相应属于增量数据集(Increment Sequence Dataset,IncSD)中项目集称为序列s的增量incs,更新数据集UD中所有输入序列的incs并集称为UD的增量并集,其增量incs包含末端输入序列的集合被称为序列s的末端投影endpjs,属于pjs而不属于endpjs的输入序列的集合称为序列s的SD投影.
在后向挖掘中,长度为k的序列在向后方向上被扩展到长度k+1,具有项j的序列〈akak-1…a2a1〉的项集扩展表示为〈{j∪ak}ak-1…a2a1〉,同样具有项目j的序列〈akak-1…a2a1〉的序列扩展被表示为〈jakak-1…a2a1〉.在生成新的序列s之后,如果该序列的末端投影为空,则表明任何输入序列的增量不包含s,并且s是稳定的.因此,UD中稳定序列的支持数与原始数据集SD中的支持数相同.
-
同现反转映射(Co-occurrence Reverse Map,CRMAP)数据结构用来解决大多数序列模式挖掘算法的性能瓶颈-评估数据库中不存在的模式所花费的时间,可以处理候选序列的组合爆炸问题.
CRMAP是将每个项目j映射到序列中位于其前面的一组项目的数据结构.本文定义了两个CRMAP结构,即CRMAPi和CRMAPs. CRMAPi以不少于最小支持数(Minimum support,min_sup)序列将每个项目j映射相对于项集扩展在其之前的一组项目,CRMAPs以不少于min_sup序列将每个项目j映射到相对于序列扩展在其之前的一组项目.
引理1 当且仅当x∈CRMAPi(y)时,相对于项集扩展〈(x,y)〉的长度为2的向后扩展序列被认为是频繁的.
证明:根据CRMAPi的定义,如果项目x没有映射到CRMAPi(y),则相对于少于min_sup序列的项集扩展而言,x出现在y之前,故〈(x,y)〉不频繁.
引理2 当且仅当x∈CRMAPs(y)时,相对于序列扩展〈(x,y)〉的长度为2的向后扩展序列被认为是频繁的.
证明:根据CRMAPs的定义,如果项目x没有映射到CRMAPs(y),则相对于少于min_sup序列的序列扩展而言,x出现在y之前,故〈(x,y)〉不频繁.
1.1. 后向挖掘
1.2. 同现反转映射数据结构
-
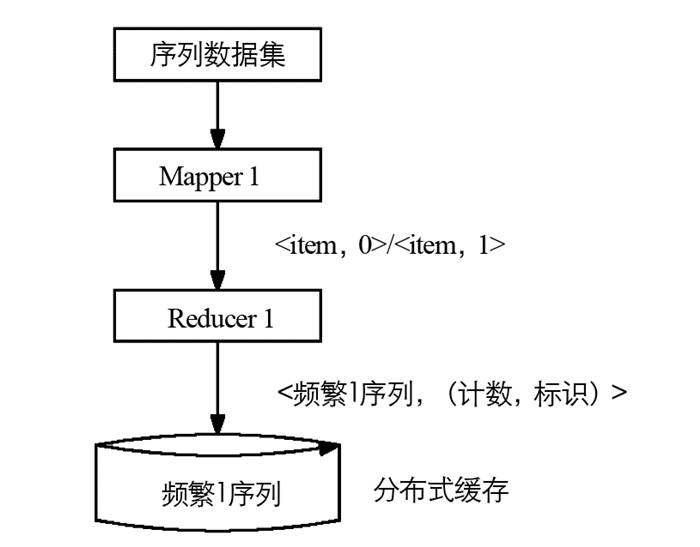
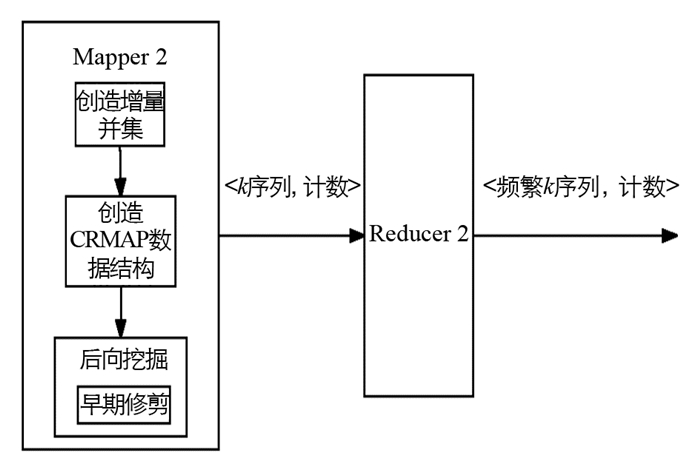
本文所提出的算法由两个MapReduce阶段组成.第一个阶段读取序列的输入分裂并找出频繁1项集(1模式)的支持计数,并通过标志变量来识别1模式是否属于增量数据集(IncSD).第二阶段创建CRMAP数据结构,并利用CRMAP数据结构通过向后扩展的方式高效地生成候选数据.此外,后向挖掘中使用的早期修剪属性避免了输入数据库中生成错误的候选序列,从而加快挖掘过程.
-
本文算法第一阶段用来挖掘频繁1序列.每个Mapper1读取输入的序列数据集并识别项目x是否属于相应序列的增量数据集IncSD,如果项目属于IncSD,则相对于项目x将1存储在分布式缓存F中,否则存储为0.然后,Mapper将项目x及其在F中的相应值作为输出〈key,value〉.
Reducer1将〈x,value〉作为输入,并将项目计数和标志变量初始化为0,其中标志变量用来标识该项是否属于IncSD. Reducer1计算与每个项目相关的值的数量,在收到关于项目的值1之后,Reducer1立即将标志变量更改为1,这有助于在IncSPM的第二阶段找到增量并集,最后将频繁1项集及其对应的计数和标志作为第一阶段的输出,并将其存储在名为Litems的分布式缓存文件中.本文IncSPM算法的第一阶段流程如图 1所示.
-
将第一阶段输出的原始数据集中的频繁1项集、最小支持计数和标志作为第二阶段的输入,然后Mapper2创造增量并集和构造CRMAP数据结构,使用早期修剪属性进行后向挖掘,最后使用Reducer2挖掘频繁k序列.具体流程图如图 2所示.
-
第二阶段中的SETUP函数读取分布式高速缓存文件Litems并找到增量并集.对在分布式缓存文件Litems中的每一个项目,判断其标志是否等于1.如果等于1,则将该项目加入增量并集,否则将1模式(项目和计数)分配给原始数据集中的频繁顺序模式L1UD.
-
本文构造CRMAP数据结构生成出现在输入数据库中有希望的候选对象,以减少算法的运行内存.
CRMAPi构造:根据定义,CRMAPi是项目与其前面项目列表(共现列表,CL)相对于项集扩展的映射.序列从最后一个项集扫描到第一个项集,以便找到项集中每个项目的CL.如果CRMAPi中存在对应于itemi的条目,则从itemi的CRMAPi中检索itemi的CL,通过检索到的CL检查共现项itemj来找到它的计数.如果项目j先前在CL中不存在,则它包含在CL(itemi)中;如果CRMAPi中对应于项i的条目不存在,则通过包括同现项itemj来创建项i的CL. itemi的CRMAPi用相应的CL更新.
CRMAPs构造:根据定义,CRMAPs是项目与其前面项目列表相对于序列扩展的映射,除了相对于序列扩展找到项的CL之外,创建CRMAPs的步骤与创建CRMAPi的步骤相同.
-
后向挖掘算法的输入为序列、序列第一项的CRMAPi和CRMAPs、序列的末端映射和SD映射,输出为更新的数据集UD中的频繁序列模式. 1模式的末端投影用于寻找其向后延伸的末端投影,通过读取序列的CRMAPi和CRMAPs来推断序列可能的后向扩展,如果序列的CRMAPi不存在,则不存在项目集扩展.从序列的末端投影找到这些生成序列中的每个序列的末端投影,扫描序列的SD投影以找到从其延伸的序列的SD投影,通过将endpj的大小和SDpj的大小相加获得这些序列的支持计数.当所有扩展的支持计数满足最小支持阈值,它们被包括在频繁序列列表中并且调用递归调用.
-
在创建CRMAP数据结构后,生成候选集.为了减少候选者数量,本文基于后向挖掘设计了两个候选生成规则,以避免产生太多输入数据库中不存在的假数据,从而高效生成候选序列.
定义1 对于长度为k-1的给定序列模式s=〈ak-1ak-2…a2a1〉,将属于CRMAPi(y)的所有x扩展生成项集候选Ck=〈{xak-1}ak-2…a2a1〉,其中y是ak-1中的第一项.
定义2 对于长度为k-1的给定序列模式s=〈ak-1ak-2…a2a1〉,将属于CRMAPs(y)的所有x扩展生成序列候选Ck=〈{xak-1}ak-2…a2a1〉,其中y是ak-1中的第一项.
-
序列模式挖掘中最耗时的操作是计算支持计数.如果在计算支持计数之前对生成的候选者进行修剪,则可以提高挖掘速度.本文基于CRMAP数据结构定义了3个早期修剪属性,根据3个定义的属性对长度大于等于3的序列进行早期修剪.
定义3 如果Ck+1中包括的新项目不存在于Ck的第一项集中任何项目的CRMAPi中,则可以修剪任何项目集扩展候选Ck+1.
定义4 如果Ck+1中包括的新项目不存在于Ck的第二项集中任何项目的CRMAPs中,则可以修剪任何项目集扩展候选Ck+1.
定义5 如果Ck+1中包括的新项目不存在于Ck的第一项集中任何项目的CRMAPs中,则可以修剪任何序列扩展候选Ck+1.
-
本文第二阶段MapReduce平台中的SETUP函数初始化map或reduce阶段中使用的资源,每个Mapper读取其输入分割并修剪序列中不频繁的项目,随后创建CRMAPi和CRMAPs,找到每个1模式x的投影和末端投影.检查每个1模式以确定其是否属于增量并集,以此找到稳定的1模式并扩展它们以找到它们的频繁超序列.如果发现1模式不稳定,则为每个不稳定的1模式调用后向挖掘函数,在调用时向该函数传递5个参数:不稳定的1模式x、x关于序列扩展的同现表、x关于项集扩展的同现表、x的末端投影和x的SD投影,其中x的SD投影是x的投影和x的末端投影之间的差.
Reduce2将k和值v作为输入,并将项目计数初始化为0. Reducer2计算与每个项目相关的值的数量,在收到关于项目的值之后,将项目计数增加.如果项目计数大于最小支持计数与|UD|之积,则输出k和项目计数,并将它们写入Hadoop分布式文件系统HDFS的文件里.
2.1. 挖掘频繁1序列
2.2. 挖掘频繁k序列
2.2.1. 发现增量并集
2.2.2. 构造CRMAP数据结构
2.2.3. 后向挖掘算法
2.2.4. 生成候选序列
2.2.5. 生成早期修剪序列
2.2.6. 具体算法实现
-
所有实验均是在具有1个主节点和8个数据节点的Hadoop集群上进行,单个节点在具有Intel Xeon CPU 2.5GHz/6-Core处理器和16 GB内存的机器上执行,每个节点都运行在装有Hadoop 1.2.1的CentOS 6.5服务器上,所有算法均使用JDK 1.8.0_31实现.采用两个真实数据集Kosarak和Twitter[12]进行实验,Kosarak数据集包含990 002个序列和41 270个项目,Twitter数据集包括12 053 495条推文、510 603个用户和1 434 862个不同的项目.
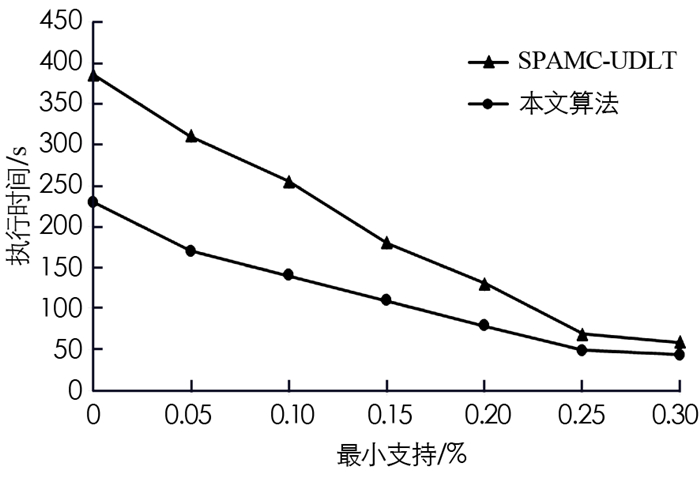
图 3和图 4给出了本文算法与SPAMC-UDLT[12]算法在不同数据集上的性能评估.可以看出执行时间随着最小支持度的增加而减少,本文算法的执行时间优于SPAMC-UDLT算法,这是因为本文算法简单地将末端投影和SD投影的大小相加来计算支持计数.此外,使用CRMAP数据结构新的候选生成减少了搜索空间的大小,并且在后向挖掘期间应用的早期修剪属性在很大程度上减少了错误候选的数量.
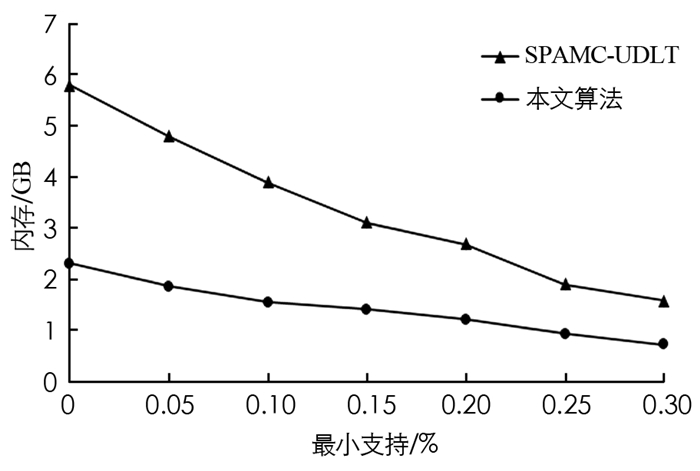
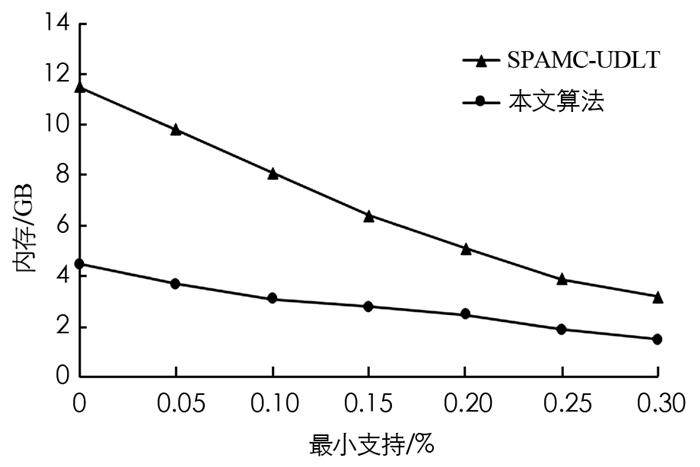
图 5和图 6给出了各算法在不同数据集上的内存使用情况,可以看出内存消耗随着最小支持阈值的增加而减少,本文算法的内存消耗优于SPAMC-UDLT算法,这是因为IncSPM利用共生信息生成候选序列,从而减少了候选序列的数量.此外,本文算法的早期修剪属性通过修剪错误的候选对象在很大程度上减少了内存使用.
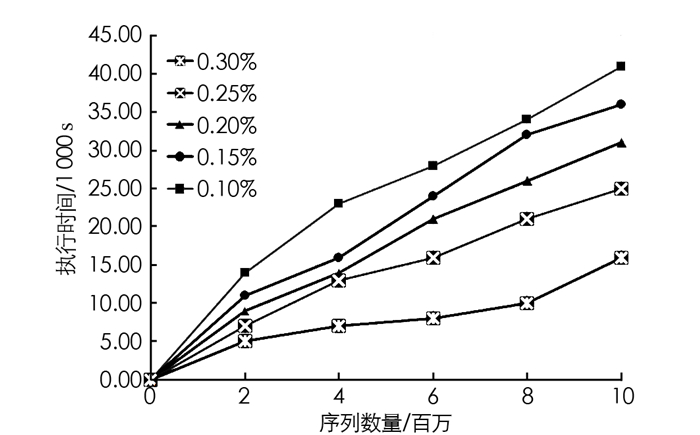
图 7给出了最小支持在0.1%~0.3%的情况下,本文算法相对于序列数量变化的可扩展性.从图 7可以看出,本文算法具有良好的可扩展性,这是因为本文设计的2个候选生成规则和3个早期修剪属性可以有效地避免在输入数据库中出现过多的错误候选生成,从而致使候选序列高效生成.
-
为了使增量挖掘算法能够很好地适应大序列数据库,本文利用MapReduce分布式平台,提出了一种高效的增量序列模式挖掘(IncSPM)算法,用来处理大数据环境中的序列模式增量维护问题.该算法通过结合候选序列的后向挖掘来避免挖掘更新数据库中支持度不变的序列,同时引入高效的CRMAP数据结构来生成出现在输入数据库中有希望的候选对象,以减小搜索空间.基于CRMAP设计高效的候选生成规则和早期剪枝属性以避免输入数据库中生成错误的候选序列,加快挖掘过程.实验表明,本文算法在执行时间、内存和可扩展性方面均有明显的提高.未来的工作是解决在数据被删除和修改时更新序列模式的问题,并尝试在其他大数据处理框架(如Apache Spark)上实现所提出的算法.