


 下载:
下载:

-
云计算已成为通过网络交付复杂云服务被广泛采用的范例,并为科学计算领域提供了更高效的技术与支撑环境[1]. 它以网络化的方式聚合计算能力与通信资源,使用虚拟化技术将大量成本低、计算能力弱的资源整合为一个强大的资源池. 因此,云计算能够实现统一管理和资源调配,提升云服务性能和价格优势[2].
在过去几年里,云服务器的数量及背后基础设施的复杂性都在迅速增加. 云计算基础设施在未来几年应对日益增长的资源需求的能力,将对未来新兴数字技术的发展起到至关重要的作用. 在基础设施即服务(infrastructure as a service,IaaS)系统中,资源监控和资源管理是特别关键的任务. 在这些系统中,大量且不断增长的数据被收集,用于管理客户委托的虚拟环境[3-4]. 在这些云系统中,数据中心管理员通常采用黑箱方法,其中每个虚拟机(virtual machines,VM)都被认为是独立于其他虚拟机的,这对监控和管理任务的可伸缩性造成了负面影响.
文献[5-6]研究表明,IaaS云系统中的可伸缩性问题,可以通过在资源使用时聚类具有相似行为的VM来改善,即对相似行为的VM进行聚类化分组管理. 例如,自动测定相似的VM,然后允许系统来识别每个类的几个虚拟机代表,紧随其后的是同一个类的其他成员. 这些理论已被用来提高监控策略的可伸缩性,最近还被应用到一个VM管理案例中,即IaaS数据中心的服务器整合中. 在文献[7-8]中,作者通过使用基于类的方法,提出了云监控和管理可扩展性的建议. 在文献[9]中,作者利用资源相关性和主成分分析对虚拟机行为进行建模,并提出了一种K均值聚类算法. 在文献[10]中,作者基于直方图的表示对VMs行为进行建模,使用Bhattacharyya距离来度量VMs的相似性,提出了一种用于聚类的谱算法. 但是,上述聚类技术只能应用于超过24 h的时间序列,即使在这种条件下它们也具有对VM错误分类的问题. 因此,在VM识别准确率和时效性上,现有聚类技术无法满足云计算数据中心监控及管理的可扩展性要求.
针对以上问题,本文提出一种基于深度学习的VM分类算法,通过提高VM分类的准确率和实时性,达到提升云数据中心监控及管理可扩展性的目的.
全文HTML
-
IaaS系统是利用VM自动聚类来实现云监控和管理的可伸缩方法. 第一层由本地管理层组成,它在数据中心的每个物理服务器上执行:利用服务器上承载的VM资源度量实时监控过载情况,当监控到负载过重的服务器时利用动态VM迁移. 第二层是全局管理层,它托管在管理节点之上:负责定期执行整合技术,将VM放在尽可能少的服务器上,降低基础设施成本,避免昂贵的资源过度供应.
基于VM聚类的云计算系统将运行相同客户应用软件的相似VM分组在一起. 由于可伸缩性原因,聚类处理往往应用于同一客户的VM. 在聚类之后,每个已标识的类只选择很少的VM代表. 一般选择3个VM代表,因为所选择的代表可能会意外地更改其与类相关的行为. 对每个类的VM代表进行高采样频率监控,为周期性整合任务收集信息. 假设非代表性VM遵循相同类代表的行为,使用更粗的粒度进行监控,可识别影响类更改的行为漂移.
由于IaaS云系统的提供者和管理员通常将每个VM视为一个黑箱,需要独立于其他VM进行监控和管理,从而加剧了这些任务的可伸缩性问题. 因此,自动聚类管理的IaaS云系统具有以下优势:①监控系统可扩展性;②服务器整合过程的可扩展性;③系统资源需求估算效率.
-
卷积神经网络能够非常有效地解决涉及多媒体数据的复杂任务,例如图像和视频处理,它适用于识别输入数据中的简单模式,然后用于在后续操作中形成更复杂的模式,最终提供充分的信息进行输出和分类处理.
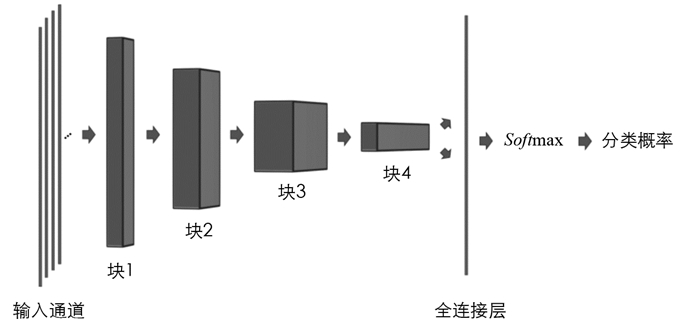
神经网络由几个卷积层和最后一个完全连接层组成. 本文模型也由一系列可变块和一个最终完全连接层组成,用于输出分类.
VM行为被描述为一组时间序列,每个时间序列描述特定度量(如存储器利用率、CPU利用率、网络流量等). 由于每个度量是一系列跨时间采样的样本,本质上是一维信号,因此本文利用特定类型的卷积(即一维卷积)作为网络中的基本块,并且将每个度量视为独立卷积运算的输入通道.
一维卷积是深度学习线性操作,用于从一维数据中提取特征,目的是识别特定窗口内的局部模式,称为内核大小(Ks). 内核中包含用于执行操作的可学习参数. 设内核沿着时间维度移动的特定步幅为s,由于内核所关注的每个数据补丁执行相同的计算,因此在一个位置学习的模式也可以在另一个位置识别,这使得一维卷积具有平移不变性.
为简化模型,设N是批量大小,C为通道数(对于第一层,通道对应于VM度量),L为信号序列的长度(称为输入),然后设一个带有输入大小(N,Cin,Lin)和输出(N,Cout,Lout)的卷积1D层,此时输出张量的值为
式(1)中,*是卷积运算符,in put[i,k]和out[i,j]分别为模型输入和模型输出,ω和b为学习参数.
步幅s是控制内核步长的一维卷积的参数:如果大于1,则以更大的步长扫描数据,因此更省时,可使初始尺寸长度减小. 此效果可以看作池化处理,即能够减少数据维度.
批量标准化[11]是一种流行的操作,它对每次考虑的批处理维度上的数据进行标准化,其中批处理是训练阶段用于加速基于梯度优化数据集的子样本. 本文每个卷积层之后均使用批量标准化,这有助于深层网络更快地收敛. 最后,采用非线性激活函数ReLU(Recti fied linear unit)在训练期间稳定梯度.
-
在本文提出的深度学习网络中,每个块由一个内核大小为3且步幅为2的卷积1D层组成. 然后,每个块后面是批量标准化层和ReLU激活函数. 根据输入序列长度W,该块重复着可变的次数,并且最少两次. 在最后一个块之后,数据将被应用于全连接层,然后输出分类结果.
模型的块数由下式计算得到
式(2)中,W长度定义为窗口. 改变块的数量可简化模型:模型需要有一个带有神经元的最终层,感知域可以在整个输入序列上观察并利用信息. 鉴于这里使用不同的输入序列长度进行实验,此时需要一个灵活的模型,即可以根据输入数据的情况调整网络结构的深度. 一般神经元的接受场是神经元可访问的输入数据部分,并且可以影响其激活.
输入序列长度为32个时间步长的通用模型如图 1所示. 图 1中概述了数据形状如何通过网络的每个块进行更改,直到最终的全连接层. 每个度量标准都显示为一列值,因此将M个度量标准放在一起,可得到(W,M)输入形状. 同时添加Batch-Size维度N,它一次考虑批量大小的输入样本以优化网络,可获得(N,W,M)训练的最终输入形状.
此模型中给出的最终out分类的概率为
式(3)中,out是模型的输出,其计算方法为
式(4)中,
$ \circ $ 是神经网络块的连接运算符,Nb是式(2)中定义的块数,FC是最终的完全连接层,每个块定义为式(5)中,AReLU表示激活函数,BN表示批量标准化层,C1D表示卷积1D层,X表示输入张量.
2.1. 深度学习模型
2.2. 基于深度学习的云计算虚拟机分类算法
-
在实验部分,目的是验证本文算法对VM分类的准确率和实时性,从而验证本文算法在提高云框架可扩展性方面的可行性.
-
实验使用的数据集来自Modena大学和Reggio Emilia机构,由8台真实的云虚拟机组成,经过几年的监控,分为Web服务器和SQL服务器.
-
在输入数据的预处理中,将每个通道的均值和单位方差标准化均为零. 由于初始数据流被划分为多个输入序列,其长度定义为窗口W,因此可利用数据增强技术来处理大于64个时间步长的序列. 具体而言,在序列之间应用75%的叠加,这样可以得到更多的序列用于训练和评估.
以每个类中具有相同数量的样本为准则,将数据集分成3个部分,训练集、验证集和测试集,分别选择0.7,0.2和0.1比例的数据组成数据集.
对于训练阶段,使用交叉熵作为损失函数来评估模型的预测,并在训练阶段反向传播误差. 在所有实验中,使用默认配置的Adam优化器[12]. 在对学习速率和权重衰减超参数进行网格搜索后,可发现在大多数情况下,学习率为0.000 3,权重衰减为0.001 2. 然而,当观察到10个连续时期的验证损失没有减少时,可将学习率降低0.6倍.
在每个训练阶段完成后,便在验证阶段(使用数据集的验证部分)评估整个模型的性能. 在实验中,每个模型训练110次,观察所有模型在这个范围内的收敛情况. 在验证阶段中,需使用之前从未使用过的测试数据进行评估,并得出最佳的性能模型.
-
为了比较本文算法的性能指标,这里选择了当前较优的Ag算法[4]、PCA集群算法[9]相比较. 由于我们的目标是快速准确地识别虚拟机,因此评估识别精度如何随窗口长度W而变化很重要. 具体而言,实验中W的范围在4~256步长之间,这里的步长单位为5 min,即W范围为20~1 280 min之间.
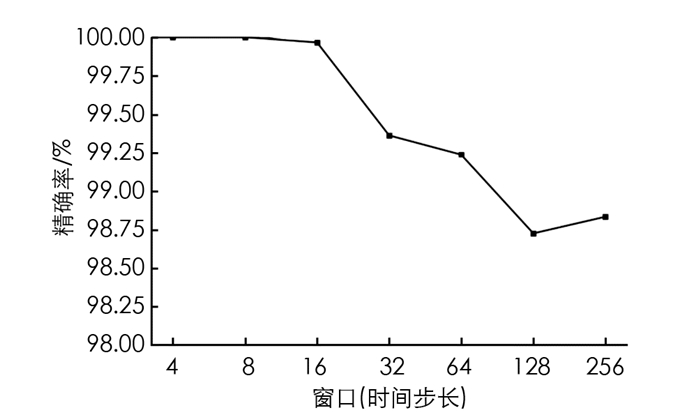
首先,对本文算法进行初步评估,即测试本文算法在不同步长情况下的精度,结果如图 2所示. 查看数据,可观察到每个步长的准确度始终高于98.5%. 特别是在短时间窗口的情况下,能够达到这种准确率,意味着本文算法近乎能够实时地对VM进行识别分类. 另外,本文算法随着窗口增加而降低其性能,可能受到模型复杂度和卷积内核大小固定的影响.
在对本文算法初步评估之后,与Ag算法、PCA集群算法进行比较,其错误率的实验结果如表 1所示. 表 1给出了对于窗口W所考虑的替代方案的误差,窗口W的范围为4~256个时间步长.
通过观察表 1可知,对于PCA算法,错误率从17.9%降低到15.1%. 对于Ag算法,错误率不是单调的,而是保持在[1.8%,2.4%]范围内. 随着窗口增长,我们观察到灰色区域(未分类的虚拟机)明显减少,即由47.8%降至18.7%. 进一步观察可以发现,本文提出的算法在每种窗口条件下,均表现出了最佳的性能. 此外,对于小窗口(W≤8),本文算法实现了零错误率,因此本文算法可满足云计算平台的准确性要求.
3.1. 实验数据
3.2. 实验设置
3.3. 实验结果与分析
-
本文的研究重点是提升云基础架构的可扩展性问题,即通过对表现出相似行为的虚拟机进行分类,从而实现提高监控和管理可扩展性的解决方案. 由于现有VM群集和分类方法的特点是在准确的VM识别和及时响应之间进行权衡,无法同时满足VM识别的准确率和实时性. 为了解决这个问题,本文基于深度学习技术,提出了一种新颖的VM分类算法. 通过来自真实云数据中心的数据验证了本文算法的有效性,在VM识别率和响应时间方面均具有较好的性能表现.