



 下载:
下载:





-
开放科学(资源服务)标志码(OSID):

-
粮食从农田到餐桌,需要经过种植、收获、运输和储藏等诸多环节,每一个环节都蕴含着劳动者的心血和智慧,节约粮食,我们每个人都责无旁贷. 然而,随着人们生活水平的提高和生活节奏的加快,食物浪费现象也越来越严重. 李贺等[1]对我国餐厅食物浪费现状进行了调查研究,发现消费者餐饮浪费的主要原因为菜品不合胃口以及菜品份量大等. 据统计,近年来我国的城市餐厨垃圾产量占生活垃圾产量的55.86%,且年均增速达10%以上[2-3],常规的餐厨垃圾处理方法会对环境造成较大的危害[4]. 此外,食物浪费现象也和粮食安全问题有着密切的关联,据联合国粮农组织统计,全球餐厨垃圾产量每年约为13亿t,约占年食物制造总量的1/3,这一数量足以支撑世界12%的人口摆脱饥饿[5],因此,从源头消减和抑制餐饮浪费十分必要.
对餐桌上的菜品浪费情况进行监测,可以帮助餐馆淘汰掉浪费程度较高的菜品,但首先需要解决菜品种类的识别问题. Chen等[6]从网络上收集并整理了中餐菜品数据集VireoFood-172,提出了菜品种类识别以及食谱检索模型. 针对菜品图像识别过程中存在的不同类别菜品间的相似度较高(类间距离小),而有些相同种类的菜品其颜色、形状变化较大(类间距离大)的问题,一些学者对传统的识别模型进行了改进,引进了基于细粒度的识别模型以及集成学习方法,使菜品种类的识别准确率得到提升[7-9]. 比种类识别更进一步,一些学者研究了菜品识别中的目标检测问题[10, 11],可以定位出菜品图像边界框区域. 比菜品目标检测任务更进一步的就是菜品图像的分割问题,Poply等[12]采用目标检测框架和语义分割模型相结合的方式对菜品图像进行了分割,并由先验知识估计出菜品的体积和质量,从而进一步估算出菜品所含热量. Okamoto等[13]从网络上收集菜品所含的热量信息,采用有监督学习的方式,在DeepLab V3+[14]的基础上进行了改进,融合了菜品图像分割和菜品所含热量估计的任务.
很多学者都对菜品图像的种类识别、目标检测以及分割问题进行了探讨,然而针对菜品浪费度的检测问题目前还鲜有报道. 对菜品浪费情况进行检测,一种可能的方法就是估计出菜品的质量或体积,Hippocrate等[15]借助手机相机和餐具(如筷子)来估计食物的质量,进而估计食物所含的热量,但该方法是通过测算碗的体积,并提供特定食物的密度信息来估计食物质量,也就是说该方法只能估计盛满食物状态下的质量,而无法估计未盛满时的质量,因此很难应用于食物浪费情况的检测中. Chen等[16]通过SIFT[17]特征提取的方法来识别菜品种类,并用深度相机来估计食物体积,但不同食物对红外线的折射与反射效果不同,深度相机发出的红外线很容易受到影响,导致测量结果不准确. Hu等[18]采用了三维点云技术对食物的体积进行估计,但该方法需要采集到多个视觉下的图像并对场景进行三维重构,对图像采集的条件也较为苛刻,所采集食物的形状也要求较为规则,因此也很难应用于菜品浪费检测中.
针对以上问题,本文提出了通过语义分割技术来检测菜品的浪费程度,根据菜品食用前后分割得到的像素面积之比来衡量菜品的浪费程度,并根据训练集和验证集上菜品食用前后分割得到的像素面积比的统计信息,制定相应的浪费度等级. 在图像语义分割领域,自全卷积神经网络FCN[19]提出以来,深度学习方法在图像分割领域的应用变得越来越流行,后续也出现了一系列优秀的基于卷积神经网络的分割结构[14, 20-21],Liu等[22]提出了基于移动窗口的自注意力模型Swin Transformer,该模型在计算机视觉的下游任务(如目标检测和语义分割)上取得了优异的成就,在大数据集上的实验结果表明其性能优于卷积神经网络结构,因此,本文选用Swin Transformer结构作为主干特征提取网络,解码器部分则在UperNet[23]的基础上进行了改进,在双线性插值层之前增加了一层转置卷积操作,进一步提高了菜品图像的分割效果.
全文HTML
-
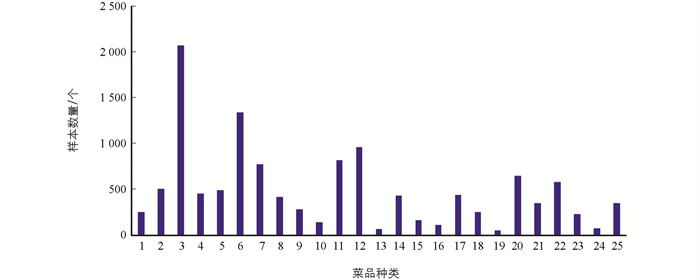
本实验所采集的数据为某高校食堂提供的菜品,实验使用1部红米note 9 pro手机和1个手机固定架来完成图像采集,手机分辨率为2 400×1 080像素,采集过程中将手机固定在菜品上方,记录下餐盘里的菜品从有到无的变化过程(图 1). 最终采集到的图片数量共为3 765张. 每一张图片中包含3到5个菜品样本,总的菜品样本数量为12 200个,总的菜品类别数为25类(图 2). 将25类菜品按1到25进行编号,每一类菜品的数量分布情况如图 3.
-
使用Labelme和EIseg软件对采集好的图像进行人工标注,生成对应的分割掩码信息. 标注过程中只标注每一类菜品的可食用区域,而不宜食用的菜品如花椒、辣椒、油等则标注为背景区域(图 4).
-
将3 765张数据划分为训练集、验证集和测试集,训练集用于模型训练,一共2 440张,包含8 163个菜品样本; 验证集数据一共698张,包含2 255个菜品样本,该部分数据用于判断模型的收敛性以及模型的训练效果,并控制模型达到一定条件后终止训练; 测试集数据有627张,菜品样本数量为1 782个,用于检验模型的泛化能力和最终效果. 测试集部分的数据单独进行采样,训练集、验证集的数据则是在所有图片打乱顺序后进行随机划分的.
-
为了增强模型的鲁棒性,防止模型过拟合,本实验对训练集的数据进行了增强(图 5),对训练集的图片以及标签图片同时旋转任意角度,来模拟不同角度下的拍摄效果[24]; 改变图像的亮度信息,对图像进行色彩抖动,来模拟不同光照条件下的拍摄效果. 最终,训练集的数据扩大为原来的3倍,共为7 320张,包含24 489个菜品样本.
-
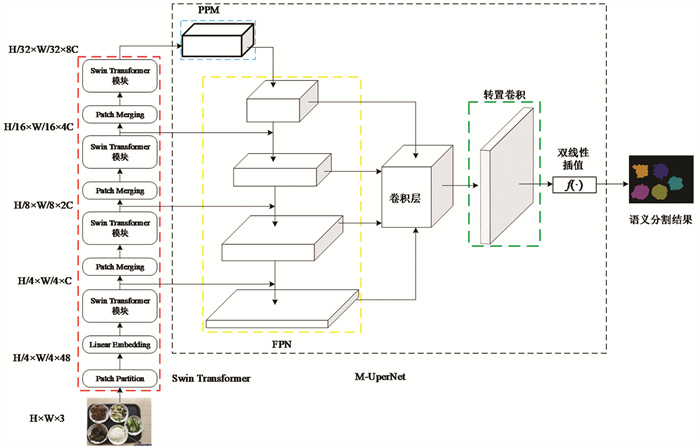
在目标检测、图像分割等图像处理下游任务上Swin Transformer都表现出了优异的性能[22],相较于传统的卷积运算,Swin Transformer中基于移动窗口的自注意力方式具有更强的特征提取能力,因此,本文选用了Swin Transformer[22]作为特征提取网络. 解码器部分则在UperNet[23]结构的基础上进行了改进,记为M-UperNet,模型的整体结构如图 6.
图 6中Swin Transformer部分为主干特征提取网络,其中Patch Partition的作用是将输入图像划分成若干个小方格,Linear Embedding为一次卷积运算,Swin Transformer模块为一次基于窗口的自注意力运算和一次基于移动窗口的自注意力运算的结合,本文利用了该主干网络4个不同尺度的特征层,其特征尺度分别为4倍、8倍、16倍和32倍下采样. PPM为金字塔池化模块,该模块融合了不同尺度的池化操作,从而能保留图片的全局上下文信息,提升分割模型的精度. FPN为图像特征金字塔模块,该模块将图像的不同特征层进行融合,利用高级语义信息的同时关注浅层的语义信息.
在UperNet结构中,图像的语义分割结果是在卷积层之后使用一次双线性插值得到的,不同于连续物体的分割,菜品浪费度检测的分割过程中会存在以下问题:当菜品食用到一定程度后,可食用菜品的区域可能是不连通的,直接用双线性插值方法还原出和原始图像相同大小的分割掩码时会引入一定的噪声,从而导致分割边界的模糊,所以本文在双线性插值之前引入了一层转置卷积[25]操作,如图 6中的转置卷积部分,卷积核大小为3,步长为2. 本文中输入图像的大小为224×224像素,卷积层得到的特征图大小为56×56像素,经过转置卷积层,得到的特征图大小变为113×113像素,最后再经过一次双线性插值运算还原出和输入图像相同大小的掩码. 通过加入转置卷积层,可以引入可训练的参数,从而减少信息的损失,使分割结果更为精细. 本文将改进后的解码器结构记为M-UperNet.
-
假设一张图片的真实标签经过one-hot编码后为Y,模型预测得到的标签为X,X和Y的形状为H×W×C,H和W分别为图片的高和宽,C为语义分割的类别数(包括背景),交叉熵损失[26]为
式中,L为交叉熵损失,xn,c为模型预测值X中第n个像素点标签为c的概率,yn,c为样本真实标签Y中第n个像素点标签为c的概率,并且yn,c∈{0,1},N为像素点总个数,N=H×W.
-
假设在一次完整的采样过程中一共采集了L幅图像,某类菜品未被食用(第1幅图像)时的像素点分割面积为S0,食用到第i幅图像时的分割面积为Si,用
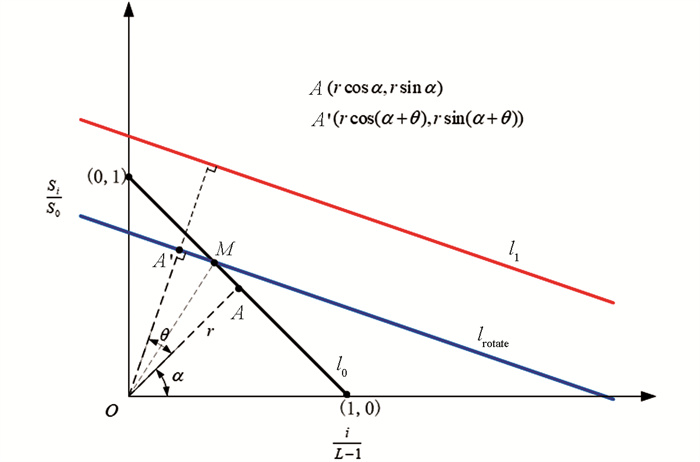
$\frac{S_i}{S_0}$ 衡量菜品的浪费程度,$\frac{S_i}{S_0}$ 越大说明浪费程度越严重,$\frac{S_i}{S_0}$ =0则说明无浪费. 将点$\left\{\left(\frac{i}{L-1}, \frac{S_i}{S_0}\right), i=0, 1, 2, \cdots, L-1\right\}$ 绘制于平面直角坐标系中,理想的情况下,进行均匀采样使得每次减少的面积相同,则$0 \leqslant \frac{S_i}{S_0} \leqslant 1$ ,且$\frac{S_i}{S_0}$ 呈等差数列递减,每次的递减量d=$\frac{1}{L-1}$ ,点$P\left(\frac{p}{L-1}, \frac{S_p}{S_0}\right)$ 和点$Q\left(\frac{q}{L-1}, \frac{S_q}{S_0}\right)$ 为此过程中的任意两个点,则两点间的斜率为所以,理想情况下这些点应该分布在直线l0:y=-x+1上,我们将该直线称为理想浪费度变化直线,然而在实际标注过程中发现由于每次采样的不均匀,这些点会分布在l0的两侧,设用最小二乘法拟合这些点得到的实际浪费度变化直线为l1:y=kx+b. 在理想情况下,我们将理想浪费度变化直线l0均分为4段,分隔点分别为(x0,y0)=(0,1),(x1,y1)=(0.25,0.75),(x2,y2)=(0.5,0.5),(x3,y3)=(0.75,0.25),(x4,y4)=(1,0),并以此划分出5个浪费度等级(表 1).
然而,对于实际浪费度变化直线l1来说,均匀地划分为4段来判断浪费度等级并不是很合理,直线l1相对于l0来说经过了一定的变换,如旋转和平移,因此分隔点也应进行相应的变换,设变换的映射关系为F,则直线l1的分隔点(xi′,yi′)=F(xi,yi),i=0,1,2,3,4. 接下来就求该映射关系F,假设l0绕原点旋转θ角度(逆时针方向取正,顺时针方向取负),并沿x轴和y轴分别平移m和n个单位后得到l1(图 7).
A点为l0的中点坐标,l0绕原点旋转θ后得到lrotate,lrotate经过垂直平移后得到l1,lrotate上与A对应的点为A′,M点是l0和lrotate的交点,容易求出M点的坐标:
$\left(\frac{1}{\operatorname{tg}\left(\alpha+\frac{\theta}{2}\right)+1}, \frac{\operatorname{tg}\left(\alpha+\frac{\theta}{2}\right)}{\operatorname{tg}\left(\alpha+\frac{\theta}{2}\right)+1}\right)$ ,α为OA与横坐标轴的夹角,r为OA的长度. 进而可求出lrotate的斜率,又因为lrotate的斜率等于l1的斜率,于是可由式(3)求出旋转量θ的值对于平移量m和n则可由以下方程组求出
最后,求出变换后的分隔点
式中,i=1,2,3,而(x0,y0),(x4,y4)分别取直线l1与x轴和y轴的交点.
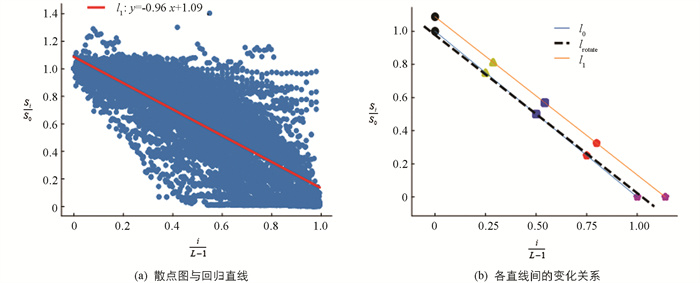
我们在训练集和验证集的数据上进行了计算,最终得到浪费度变化的直线分布情况. 图 8a中的散点为
$\left(\frac{i}{L-1}, \frac{S_i}{S_0}\right)$ 的分布,图 8b中理想浪费度变化直线l0上的5个点为理想情况下的分隔点,实际浪费度变化直线l1上的5个点为最终计算得到的分隔点(与l0上用相同记号标注的点相对应),最终,实际情况下的浪费度等级划分如表 2,鉴于某些散点存在$\frac{S_i}{S_0}>y_0$ 的情况,因此在定义第一个浪费度等级时本文不限制$\frac{S_i}{S_0}$ 的上界,其划分阈值为$\frac{S_i}{S_0}>y_1^{\prime}$ .
1.1. 数据采集及数据预处理
1.1.1. 数据采集
1.1.2. 数据标注
1.1.3. 数据集划分
1.1.4. 数据增强
1.2. 菜品图像语义分割模型
1.2.1. 模型结构
1.2.2. 交叉熵损失函数
1.3. 浪费度等级定义
-
模型训练的环境为Python:3.7,Pytorch:1.11.0,CUDA:11.3,GPU:RTX3060Ti; 训练过程中配置的超参数为输入图像大小:224×224,批量大小:24,学习率(lr):按
$l r=l r_0\left(1-\frac{e}{E}\right)^{0.9}$ 进行衰减,lr0表示初始学习率,设置为5e-4,E表示最大迭代次数,设置为200,e表示当前迭代次数. 迭代过程中,若验证集的平均交并比在20个回合内不再上升就停止迭代.本文中用到的分割效果评价指标有平均像素精度(mAP),平均交并比(mIOU)以及F1精度[27],用pii表示真正例,pij和pji分别表示假正例和假负例,P和R分别表示精度和召回率,各评价指标计算式为
不同模型在测试集上的评价指标值如表 3. 从表 3可以看出,相较于以卷积神经网络作为特征提取结构的模型DeepLabV3+[14],PSPNet[28],以Swin-Transformer作为特征提取结构的模型分割效果会更好. 此外,本文提出的Swin-T+M-UperNet模型效果更优,其平均交并比(mIOU)较原模型提高了1.02%. 在模型的解码器部分,通过引入转置卷积,增加了可学习的参数,相较于直接通过双线性插值恢复出和输入图像相同大小的掩码,可以保留更多的细节信息.
-
实验结果表明,菜品图像的语义分割结果中Swin-T+M-UperNet模型的分割效果最好,因此本文选用该模型进行浪费度检测,流程如图 9. 将未食用时的菜品图像和食用后的菜品图像分别输入到训练好的Swin-T+M-UperNet模型中得到对应的分割掩码,然后计算对应菜品分割掩码区域面积(像素点个数)的比值来判断每一类菜品的浪费度等级,右侧检测结果中的检测框为菜品未食用时每一个菜品分割区域的最大外接矩形框. 本文通过该区域来确定菜品的种类和位置,如图 9中初始时刻图像得到的分割掩码有6类:5类菜品加上1类背景(黑色区域),图中红色掩码区域对应菜品种类9,取该最大连通区域的外接矩形即可确定该类菜品位置,并可在矩形框外标注出菜品种类以及浪费度等级.
按照浪费度等级的定义,模型对测试集上的1 782个菜品样本进行了检测,最终检测结果的混淆矩阵分布情况如图 10. 从混淆矩阵可以看出,错判的样本主要分布在主对角线两侧,即这些样本的真实浪费度等级和错判等级之间是相邻的,检测的整体准确率为(689+337+255+311+103)/1 782=95.12%.
2.1. 模型训练结果
2.2. 浪费度检测
-
本文将图像语义分割算法应用于菜品浪费度检测中,在Swin Transformer和UperNet结构的基础上进行改进,增加了一层转置卷积,并与传统的以卷积神经网络为特征提取结构的模型进行了比较. 在测试集上的分割结果表明,以Transformer为特征提取结构的模型分割效果较好,改进的Swin-T+M-UperNet模型相较于原来的Swin-T+UperNet模型分割效果更优,在测试集上的平均交并比可以达到93.30%,提升了1.02%.
本文还根据训练集和验证集上菜品食用前后分割面积比的统计信息制定出了浪费度等级,首先在理想直线上划分出浪费度等级的分隔点,然后求出理想直线到实际直线间的变换关系,根据该变换关系求出实际直线上对应的分隔点,按照分隔点的划分阈值,将菜品的浪费程度划分为严重浪费、很浪费、一般浪费、轻度浪费和无浪费5个等级,同时提出了菜品浪费度检测的流程和方法,最终在测试集上的浪费度等级识别准确率能达到95.12%. 本文提出的检测方法具有一定的合理性,为餐饮浪费的检测和管理提供了一种可行的技术方法,可以帮助餐厅监测菜品的浪费程度,并从菜单里淘汰掉一些浪费程度较高的菜品,保留浪费度较低的菜品,从而做到从源头上减少浪费,也可以帮助优化餐馆的进货清单,提升餐馆的经济效益.
本文所研究的菜品对象在食用过程中像素分割面积呈现递减的趋势,但对于一些在食用过程中质量减少而像素分割面积变化很小的菜品(如汤类菜品),该方法还有一定的局限性,对此类菜品的检测还有待进一步去探索.