


 下载:
下载:




-
开放科学(资源服务)标识码(OSID):

-
随着全球化不断推进和信息技术的迅猛发展,跨语言理解在自然语言处理(Natural Language Processing,NLP)领域扮演着重要的角色[1]. 自然语言处理(NLP)是数据挖掘的一个前沿方向,融合了机器学习与统计学、数学、语言学等学科,近年来发展迅速[2-4]. 通过统计和机器学习方法,计算机能够快速地处理、分析并运用文本的深层语义信息,像人类一样理解并生成自然语言. “自然语言”的含义是自然进化形成的人类语言,如中文、英文、拉丁语等,有别于Java、C++等程序语言.
在互联网时代,人们可以通过网络轻松地获取来自不同语言和文化背景的信息,这使得跨语言NLP任务变得尤为关键. 例如,机器翻译、情感分析和命名实体识别等任务都需要处理多种语言之间的转换和理解. 然而,不同语言之间存在结构、词汇、语法和文化等方面的差异,这给跨语言理解带来了巨大的挑战.
传统的机器学习方法在处理跨语言任务时往往需要大量的人工特征工程和领域知识[5-6],这些方法通常依赖手工设计特征来捕捉不同语言之间的差异和共性,然后使用分类器或回归模型进行训练和推理. 然而,这种方法面临多个问题. 首先,人工特征工程耗时耗力,并且对不同语言之间的差异和数据稀缺性处理困难. 其次,这种方法可能无法充分利用深层语义和上下文信息,导致在跨语言理解任务中的性能不尽如人意.
神经网络和深度学习模型在NLP领域取得了显著的突破和成功[7-9],相比于传统的机器学习方法,神经网络和深度学习模型具有更强的表示能力和泛化能力,能够从大规模数据中自动学习特征和模式,并且能够处理复杂的语言结构和语义关系. 在跨语言NLP领域,神经网络和深度学习模型的应用也取得了一定的成果,通过迁移学习和跨语言数据的利用,能够有效地解决语言差异和数据稀缺性带来的挑战. 其中,BERT(Bidirectional Encoder Representations from Transformers)是一种最具代表性的深度学习模型. BERT是跨语言NLP领域中基于模型的迁移学习方法,它在多个跨语言NLP任务上取得了最先进的性能,并成为了跨语言NLP任务的基准模型.
在跨语言学习领域,Vázquez等[10]通过重用多语言神经机器翻译的编码器进行零样本二元情感分类,他们使用特定于任务的分类器组件扩展了该编码器,并用新语言执行文本分类. Verma等[11]提出了ULMFiT模型,该模型通过在通用领域语料库上预训练通用语言模型,使用判别式微调对目标任务数据上的模型进行微调,从而应用于任何NLP任务. Gu等[12]使用针对特定任务训练的双向LSTM,通过查看整个句子来呈现词嵌入中词的上下文敏感表示. 还有一些学者研究生成了两种基于Transformer的语言模型,分别是OpenAI GPT和BERT[13]. OpenAI GPT是一种单向语言模型;而BERT是第一个深度双向、无监督的语言表示模型,仅使用纯文本语料库进行预训练[14-15]. Pelicon等[16]使用BERT通过在斯洛文尼亚语中训练分类器,并使用其他语言的文本进行推理来执行情感分类. Kim等[17]将预训练好的嵌入向量迁移到LSTM结构建立了Docbert模型,在实现参数压缩的同时保持了BERT在文本分类任务中的准确性. 贾明华等[18]定性地研究了BERT-Large中每层Transformer在不同NLP任务中的贡献.
基于以上研究,本文结合迁移学习和深度学习模型,提出一种M-BERT迁移学习模型,用于解决跨语言NLP任务中的关键问题. 通过实验对比了本文提出的方法与其他先进算法在多个跨语言NLP任务上的性能差异,结果证明本文方法在各项任务中都取得了显著优于现有算法的结果,具有较高的性能. 本文的目的与研究意义旨在探索一种基于NLP迁移学习的方法,结合深度学习模型(M-BERT模型),用于提高跨语言理解的性能. 通过迁移学习,可以利用源语言的丰富资源和知识来改善目标语言的学习能力,从而解决数据稀缺和语言差异带来的问题. 同时,通过引入深度学习模型,可以利用其强大的表示学习能力和上下文理解能力,进一步提高跨语言理解的准确性和泛化能力.
全文HTML
-
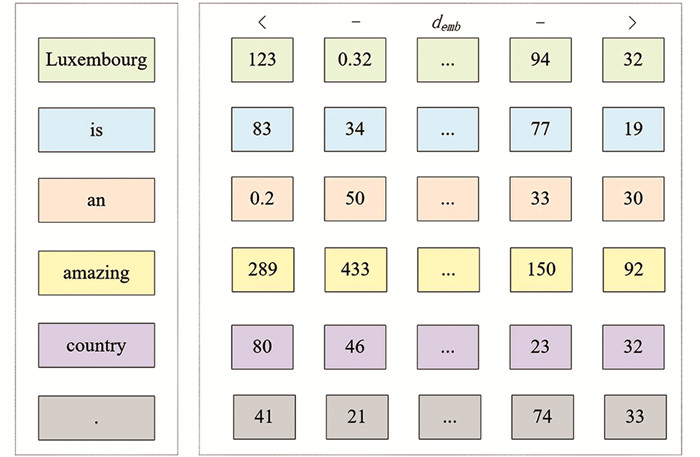
输入分3个阶段处理:标记化、将标记映射为数字表示、词嵌入. 在标记化之后,每个标记都被映射到语料库词汇表的不同整数,称为映射标记. 每个标记都获得一个唯一的数字表示. 此外,还需要填充以确保批次中输入序列的长度相同. 标记化、映射和词嵌入都是将词转换为向量的过程,与神经词嵌入的完成方式类似. 本文给出下面这个小型句子:“卢森堡是一个了不起的国家”. 首先,将其标记化:
“Luxembourg is an amazing country.”(卢森堡是一个了不起的国家.)得到的标记为——[“Luxembourg,” “is,” “an,” “amazing,” “country,” “.”(“卢森堡” “是” “一个” “了不起的” “国家” “.”)].
然后进行映射,在语料库的词库中每个标记被分配成一个唯一的整数. 例如
[“Luxembourg,” “is,” “an,” “amazing,” “country,” “.”]→[34, 34, 15, 684, 55, 193]. 接着,得到序列中每个单词的嵌入. 序列中每个短语都与一个嵌入维向量有关,模型将在整个学习过程中发现该向量,并可以把它看作是对每个记号的向量查找. 这些向量作为模型参数处理,通过反向传播进行调整,与其他权重的优化方式相同.
因此,本文搜索与每个标记相关的向量. 例如:
然后通过堆叠每个向量来生成一个尺寸为:(输入长度)×(嵌入维度)的矩阵K,如图 1所示. 其中demb表示嵌入向量的维度(embedding dimension).
最后,需要使用填充来确保批处理中所有输入序列的长度相同. 因此,本文通过包含“pad”标记来延长一些序列. 将第9个长度进行填充后的序列为:[“〈pad〉,”“〈pad〉,”“〈pad〉,”“Bangladesh,” “is,”“a,”“beautiful,”“country,”“.”]→[5, 5, 5, 34, 90, 15, 684, 55, 193].
-
BERT算法的优势通过学习位置嵌入获得,生成的文本序列被表示为矩阵,尽管这些表示没有考虑单词存在于不同位置的事实,但它能够根据单词的位置来改变单词的表征含义,目的并不是要改变这个词的完整表达,而是稍微改变它,以编码其位置.
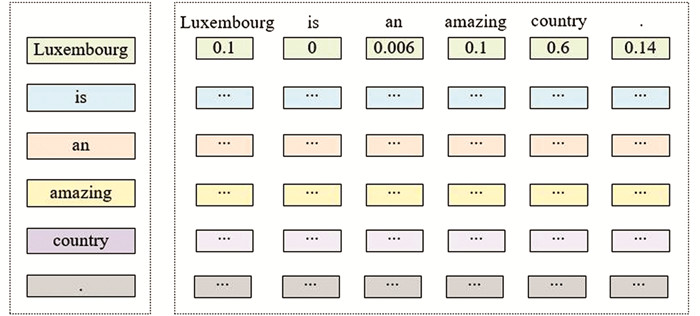
该分析采用一种策略,使用不可学习的正弦函数将[-1, 1]之间的数字添加到标记嵌入中. 编码器其余部分根据词的位置(即使是同一个词)以略微不同的方式表示这个词,另外一些词则处于同一序列中不同的特定位置. 我们希望网络既能理解绝对位置,也能理解相对位置. 本文选择的正弦函数可以将位置表示为彼此的线性组合,从而使系统能够学习标记位置之间的相关关系. 将具有位置编码的矩阵U添加到K合并该信息,就变成了U+K.
BERT采用正弦函数合成. 从数学角度来讲,标记在序列中的位置用x表示,嵌入特征的位置用y表示. 正弦函数用如下公式描述.
给定文本U的位置嵌入矩阵如图 2所示. 与学习的位置表征相比,这种确定性方法具有许多明显的优势. 例如,输入长度参数可以无止尽地增加,因为函数可以在任意位置计算. 此外,需要学习的参数更少,因此可以更快地训练模型. 得到的矩阵是I=K+U,大小是(输入长度)×(嵌入维度),它是第一个编码器块的输入.
-
BERT编码器是一种基于注意力机制和前馈神经网络相结合的变压器编码方法,编码器由多个编码器块叠加而成,每个编码器块包括两个前馈层和一个双向的自注意力层.
当数据通过编码器块时,对于一个给定的输入序列,通过位置编码产生的位置信息会返回一个尺寸为(输入长度)×(嵌入维度)的矩阵. 一个特定的块负责建立输入表示之间的关系,并在输出中对其进行编码.
-
编码器架构是围绕多头注意力构建的,它使用各种权重矩阵多次计算注意力b,然后将结果串联起来. 头部是每一个注意力平行计算的结果,下标x被用来表示一个特定的头和它相应的权重矩阵. 计算完所有头后,将它们进行连接,产生一个尺寸为(输入长度)×x(b×d_q)的矩阵. 最终,添加了由维度(b×d_q)×(嵌入维度)的权重矩阵M0组成的线性层,产生了维度为(输入长度)×(嵌入维度)的最终输出.
式(2)中,headx=Attention (VMxV,ZMxZ,QMxQ). 在这种情况下,V,Z和Q为各种输入矩阵的占位符.
-
在缩放点积注意力机制中,每个头由3个不同的投影(矩阵乘法)定义:
输入矩阵X通过这些权重矩阵分别投射,计算头部.
本文使用这些Zx,Vx和Qx来确定缩放后的点积注意力.
式(5)中,Zx和Vx投影的点积可以用来量化标记投影的相似度. 考虑到wx和ty分别是第x个和第y个通过Zx和Vx的投影,其点积为:
表示tx和wy之间方向上的相似性. 此后,矩阵被按元素除以dz的平方根进行缩放,下一阶段将逐行实施softmax. 因此,矩阵的行值会收敛到0~1的数值,从而将其加到1. 最后,Qx将这个结果相乘,得到头部.
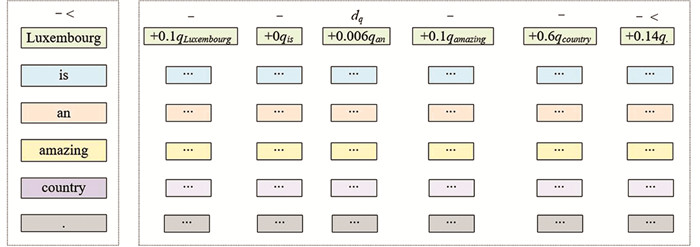
在先前的例子“Luxembourg is an amazing country.”中,“Luxembourg”的结果表示如图 3所示.
然后将其乘以qx,得到图 4的结果.
图 4生成了一个矩阵,其中每一行都由通过qx投射的标记表征组成,如图 5所示.
图 5特殊的头代表着“Luxembourg”和“country”的结合,我们可以计算出每个编码器块存储这些不同关系所需的b次(b个头). 以前面的例子为第一头.
在此阶段,“Luxembourg”被表示为:
使用b个不同的学习投射将b个加权的标记表达变化串联起来,得到标记表示. 前馈神经网络(FNN)在位置基准下建立多层结构,每一层的输出通过以下方式进行计算:
式(9)中,M1和M2分别是(嵌入维度)×(d_F)和(d_F)×(嵌入维度). 标记向量表示法不会相互“影响”,它等于逐行进行计算,然后将各行堆叠在一个矩阵中. 该步骤的输出尺寸为(输入长度)×(嵌入维度),且输出被传递到丢弃层、添加层和规范层. 在位置感知前馈网络与丢弃层、添加层和规范层网络之间始终有一个名为子层的层. 子层是具有相同输入和输出的层(多头注意力或前馈),每个子层之后以10%的概率应用丢弃层(子层(i)). 该结果应用于子层输入i,产生i+丢弃层(子层(i)). 在多头注意层中通过一个标记x与其他标记的关系,用原始表示法来补充完成. 然后,利用每行的平均值和标准差构建一个标记行级的标准化,从而增加网络的稳定性.
1.1. 输入嵌入
1.2. 位置编码
1.3. 编码器块
1.4. 多头注意力机制
1.5. 缩放点积注意力
-
M-BERT与BERT具有类似的模型架构,是一种优化的BERT变体,可在跨语言NLP任务中实现最先进的性能. M-BERT保留了BERT的模型结构,通过执行额外的预处理操作,确保该架构可以适合各种庞大的多语言数据集. 本文所提出的方法由两个阶段组成:第一阶段包括收集和处理与数据集相关的数据;第二阶段重点关注模型架构,主要包括3个任务,即训练设置、参数估计和模型训练.
-
训练M-BERT模型的第一步是构建合适的无标签文本语料库. 由于BERT是基于Transformer的机制,因此需要庞大的语料库才能完成训练. BERT最初使用从庞大的英语维基百科和图书语料库中检索到的33亿个单词,用作训练M-BERT模型的输入.
训练M-BERT至关重要,因此本文根据原始数据对多语言数据集进行结构化. 多语言数据集提供3种变体:原始数据、预处理V1和预处理V2. 我们使用预处理V1来预训练模型,使用预处理V2进行微调. 整个数据集的确切大小为39 GB,包括3个版本,V1和V2变体,每个版本包含约2 000万个观测值. 此外,训练语料库包含约8.21亿个单词和170万个特殊单词,主要处理不同长度字符串中的文本数据. 每个子语料库都采用了严格的清洁和过滤过程,而且噪音、表情符号、URL标签、HTML标签以及所有无意义的内容(例如电话/传真号码、电子邮件地址等)都已被消除. 任何高级语言操作(例如词干提取和词形还原)都没有应用于训练. 由于BERT是基于上下文并且具有句法能力,因此通过这些操作(词形还原和词干提取)将单词更改为词根会降低句法能力和上下文词义. 数据集中除英语外的所有外语都被删除,因为它们的出现率低于0.01%,并且没有任何显著的影响. 与V2相比,预处理V1中的标点符号并未被删除,因为它有助于识别单词关系. 表 1总结了从拟合到预训练模型V2之前数据集的属性.
-
单语言BERT过程在所有语言中几乎都是相同的. 预训练过程首先根据可用的语料库形成词汇表,然后字节对编码(BPE)主要用于生成有词组和无词组的词汇,正确执行这些步骤可以显著提高模型的性能. 如果句子被标记化(即每个单词分成的部分越少),模型效果会更好,因为标记化的句子更准确. 本文的预培训过程分为两个基本活动:第一个是掩码语言建模,第二个是下一个句子预测. 我们使用交叉熵损失训练掩码语言模型(MLM)来预测随机掩码标记. 其中,80%的被选标记被替换成专属标记,10%的被选标记被替换成随机标记,10%的被选标记保持不动. 流程如图 6所示.
该流程中,右边的编码器用来开发M-BERT预训练模型,并使用多语言无监督数据集. 左边的编码器则接受来自预训练模型(右边的编码器)的训练参数,并被用作下游任务的微调.
-
模型设置对于获得所需的输出至关重要,这也是为何需要仔细选择模型配置值的原因. 前馈层大小,即中间大小为3 072,本文将pad id设置为0. 编码器和池化器的非线性激活函数(函数或字符串)为gelu,用于初始化所有权重矩阵的截断正态初始化器的标准差为0.02. 将use_cache设置为True来指示模型是否必须提供模型的最新键/值注意力.
-
由于本文模型基于BERT架构,因此在训练设置中主要使用原始的BERT配置和技术. 此任务通过保持接近原始实施的参数,确保配置设置产生与主BERT相同的性能,并且需要经常设置原始实施和超参数值. 本文对所需的模型进行了修改,将模型设置为12个编码器块、768个维度和12个注意力头,包含102 k的庞大词汇量,几乎是原始BERT的3倍. 这种设置可以使得模型更加稳健,并且在计算上更具挑战性. 本文模型的基础建立在拥抱面变压器版本4.2.2之上. 我们将值1e-12设置为分母,以便在归一化层中保持数值稳定性. 由于向后传递速度较慢,本文选择梯度检查点为false节省内存. 对于注意力概率以及嵌入、编码器和池化器中的所有全连接层,我们将层下降率定为0.1,并使用自适应矩估计(ADAM)优化器对目标函数进行了优化,这非常适合涉及大量数据或参数的情况,与M-BERT一样. 选择学习率为1e-6,β1=0.900,β2=0.999,采用1e-6ε保持数值稳定性. 预训练全部在Google Cloud TPU V3上进行,用时120 h.
2.1. 数据收集与处理
2.2. 训练设置
2.3. 参数估计
2.4. 模型训练
-
使用4个标准评估指标(准确率、精确率、召回率和F1值)来衡量本文模型的性能质量. 为了进行计算,配备了Intel i9-CPU、64G-RAM和单个NVIDIA GeForce RTX3070 GPU的PC机.
-
(1) JRC-Acquis多语言数据集
JRC-Acquis数据集是一个较小的数据集,包含20种语言的并行文档. 该数据集与EU-RLEX57K数据集重叠并包含其他文档,使用EuroVoc的描述符进行标记. 本文实验选择了英语、法语和德语的文件.
(2) EURLEX57K多语言数据集
本文收集了与EURLEX57K数据集中文档相同的德语和法语文档,使用原始EURLEX57K数据集中的CELEX ID将数据分为训练集、开发集和测试集. 并行语料库中的文档,按照EURLEX57K数据集的分割方式进行. 因此,最终数据集包含3种语言(英语、法语和德语)的并行文本.
在所有这些实验中,本文使用IRC Acquis英语训练数据模型,并使用法语和德语测试集进行测试.
-
将本文模型与其他3种自然语言处理模型(Alpaca、Transformer-XH、XLM-RoBERTa)使用JRC-Acquis多语言数据集的英语部分在法语和德语上并行测试,联合训练方案的结果如表 2所示.
表 3为4种NLP模型在联合训练方案中使用EURLEX57K多语言数据集的英语部分,在法语和德语测试集上训练的结果.
由表 2和表 3法语和德语测试集上的结果可知,在联合训练方案中本文模型具有最高性能,最高达到96.2%的准确率. 然而,当使用联合训练方案时,法语和德语的结果存在一定的差异,表明相对于从英语表示迁移到德语表示,多语言模型更擅长从英语表示转移到法语表示.
-
图 7显示了本文模型在不同文档方面的表现,除了在中等文档中观察到的F1值分数较低外,总体预测得分普遍较高,且小文档与大文档之间的得分情况比较相似. 所得分数表明,文件大小作为一个因素与性能质量无关,意味着文档大小只影响计算性能. 准确率得分呈现的平均值为93%,这是因为该模型具有较高的TN(真阴性)比率,而不是TP(真阳性)比率.
如模型构架中所述,本文使用向量参数减少处理大文档时的计算成本,并进行了多次实验来分析模型的质量和计算性能,如表 4所示. 结果显示,本文模型在F1值指标上优于所有先进的NLP处理模型;其次是XLM-RoBERTa模型,它使用最少的数据进行训练,但却体现出了仅次于最佳模型的性能. 同等实验条件下,就执行时间而言,本文模型的预计计算时间为975.26 s,比XLM-RoBERTa模型的计算时间减少了199.59 s,比Transformer-XH模型的计算时间减少了420.46 s,比Alpaca模型的计算时间减少了900.17 s. 实验结果表明,本文模型不管在质量性能还是计算性能上都具有最佳表现.
-
为了进一步评估本文模型的性能,本文通过对54个文本文档进行人工评估来进行定性分析(表 5). 这些文档从16 281份文档中随机抽取,请3位语言学专家使用五点李克特量表根据3个标准评估这些文档. 每位专家都获得18份样本文档,以便与3份原始文档(黄金标准参考文献)进行比较. 每个样本中的平均单词数约为115个.
评估的3个标准为:① 充分性(原文含义的保留程度),语境合理性(上下文语句是否健全合理)和语法性(生成语句的正确性). 根据双尾独立样本t检验,在p<0.05时,带有+的基础预训练模型与本文的++模型有显著区别. 星号*表示最佳结果.
表 5的实验结果证实,本文模型在3个标准评估中均取得了不错的结果,特别是在充分性和语法性上获得了最高分,分别是4.16和3.83,平均分数为3.88,优于所有其他对比模型. 该实验还证明,为跨语言NLP任务微调一个全面的预训练多语言模型(如本文模型)比使用现有的NLP处理模型更直接,并且可以产生更好的性能.
3.1. 实验设置与评估指标
3.2. 数据集
3.3. 结果评估
3.3.1. 不同模型对比评估
3.3.2. 模型性能评估
3.3.3. 人工评估
-
跨语言NLP任务面临着语言差异和数据稀缺的挑战. 为了解决这些挑战,研究者们提出了一系列方法,包括基于迁移学习和基于神经网络的方法. 本文结合迁移学习和深度学习模型,提出一种新的方法来提高跨语言理解效果. 首先,构建BERT模型;然后,通过一系列预训练操作完成M-BERT模型构建,并在目标任务上进行微调;最后,为了将所学到的知识应用于目标语言任务并提高目标语言的理解能力,本文采用迁移学习策略,将M-BERT作为特征提取器用于源语言领域和目标语言领域之间的特征转换. 这种迁移学习的方式能够在不同语言之间实现知识共享和迁移,提高目标语言任务的性能. 在实验部分,我们选择多个常见的跨语言NLP任务,并与其他先进算法进行了比较. 实验结果表明,本文提出的方法在这些任务上优于所有对比的先进算法. 通过对比实验和定量评估实验,验证了本文方法的可行性和优越性,该方法能够将源语言上学到的语义知识迁移到目标语言上,从而弥补目标语言中的数据稀缺性. 下一阶段将深入研究在M-BERT中的多层次语言提取编码,以便正确理解和分析该模型对不同信息的获取. 此外,还将评估其他BERT架构,如DeeBERT、MobileBERT、SpanBERT和AlBERT,进一步探究更先进的NLP处理模型,从而更好地应用于跨语言研究领域.