


 下载:
下载:
-
开放科学(资源服务)标识码(OSID):

-
监督学习方法利用大量标记的训练样本来构建预测模型,在很多领域获得了较大成功. 但由于数据标注往往需要很高成本,在很多任务上很难获得全部真实标记的强监督信息,因此样本标注可能不完全、不确切和不精确,这些学习任务被称为弱监督学习. 偏标记学习[1-2]是弱监督学习中的一种,它属于不确切学习的范畴. 偏标记学习任务中训练样本对应一个候选标签集合,集合中只有一个真实标记. 偏标记问题广泛应用于现实世界中的许多场景,例如图像分类[3]、网络挖掘[4]和自然语言处理[5-7]等领域.
现有的偏标记学习策略有很多,总体上有3种类型:基于平均的消歧策略[8-9],在训练过程中平等对待所有候选标签;基于辨识的消歧策略,将候选标签集中的真实标记视为潜在变量[10];基于流形假设的消歧策略,流形假设认为相似样本的模型输出应该具有相似性,以此对偏标记数据进行消歧训练[11]. 近年来,偏标记学习研究不断发展,有的偏标记方法不仅可以利用具有人工特征的关系型数据集,也可以利用图像数据集进行模型学习,如近些年的LWS方法[12]、PRODEN方法[13]、CC方法[14],以及结合一致性正则化的深度偏标签学习方法[15]. 但这些偏标记学习方法大部分假设全部样本都具有候选标签集的弱监督信息,而在很多实际问题中,获取全部偏标记仍然需要耗费很大成本,而无标记数据则相对容易获得. 对于一部分样本带有偏标记,大部分是无标记数据的学习场景,称为偏标记半监督学习,目前对这类问题的研究较少. 2019年Wang等[16]提出的PARM模型中通过模型分类器更新无标记数据标签置信度矩阵来处理偏标记半监督问题. 2022年Li等[17]提出主动偏标记学习,从主动学习的角度同时利用无标记和偏标记数据,用偏标记弱监督信息建立代表性无标记样本的选取策略. 但这些偏标签半监督的研究大多针对人工特征数据集,无法应用于图像数据. 目前针对图像数据的半监督学习方法有很多[18-19],其中深度半监督模型甚至取得了与完全监督学习相媲美的结果. 但是传统的半监督方法中的标记样本是带有精确标记的,尚不能处理和利用偏标记信息,在偏标记半监督问题场景下还不能达到理想的效果. 因此,将偏标记和半监督学习两种弱监督框架结合起来,针对少量偏标记样本、大量无标记样本进行有效学习,对于进一步降低标注代价,扩展弱监督学习应用范围有着重要的意义和价值.
本研究基于包含3种损失项的目标函数,结合一致性正则化和伪标记方法提出了一种处理图像数据的偏标记半监督学习算法. 在学习过程中首先对偏标记和无标记数据进行强弱增强处理,偏标记样本的伪标记基于其弱增强生成且被限制于相应的候选标签集合中. 一致性正则化认为同一个样本的不同增强应该具有类似的模型输出,本研究采用高置信度伪标记的样本计算两种增强后的输出交叉熵损失,提高参与训练过程样本的可靠性. 实验结果说明,本研究的方法比现有处理图像数据的半监督学习方法和相关偏标记学习方法具有更高的精度和稳定性,收敛速度也有一定提升.
全文HTML
-
最近有不少研究将偏标记学习同深度学习相结合,深度偏标记学习已成为一种趋势. 其中,LWS算法[12]是一种能够处理图像数据的深度偏标记学习算法,它通过风险一致性构建损失函数进行模型训练学习. 风险一致意味着分类器是一致的,也就是说偏标签学习产生的最佳分类器与完全监督学习产生的最佳分类器相同. PRODEN[13],CC[14]等算法也是近年被提出的能够处理图像数据的深度偏标签学习算法.
图像分类半监督学习问题近年来得到了广泛的研究,起初Lee等[20]运用伪标签方法给无标记样本打上伪标签进行训练,随后Miyato等[21]提出了一致性正则化方法,取得了不错的效果,FixMatch[18],FlexMatch[19]等算法结合了一致性正则化方法和伪标记方法,通过伪标记方法给无标记样本赋予伪标记,根据伪标记利用一致性正则化方法进行模型训练,分类性能达到与完全监督相近的效果.
另外,主动偏标记学习也是一种能较好解决偏标记半监督问题的方法[17]. 主动偏标记学习的关键问题在于如何利用弱监督信息建立有效的样本选择机制,筛选出无标记样本中最具信息量和代表性的样本进行人工标注,再利用人工标注后的样本进行模型训练. 但是此方法不适用于无法进行人工标注或者成本太高的情况.
以上工作可分别适用于偏标记学习、半监督学习以及人工特征的主动偏标记学习等场景,但对于本研究所关注的图像分类问题中的偏标记半监督学习场景,仍有待进一步研究和改进.
-
偏标记半监督学习问题是基于偏标记学习基础上提出的更为困难的学习问题. 本研究讨论的问题背景为训练数据中含有极少量的确切标记数据Ds,少量的偏标记数据Dp和大部分的无标记数据Du. 学习任务是建立图像分类模型对未知图片进行预测. 问题符号表示如下:
在q分类的偏标记学习问题中,偏标记数据集Dp={(xp1,Sp1),…,(xpm,Spm)},其中xpi∈Xp,Xp为偏标记数据的样本空间,xpi所对应的候选标签集Spi⊆Y,Y={1,2,…,q},其中有且只有一个正确的标签. 另外含有大部分无标记数据Du,其中Du={xu1,…,xun},xui∈Xu,Xu为无标记数据的样本空间. 学习任务是在数据集D=Ds∪Dp∪Du上建立有效的分类器,对未知类别的图像进行分类预测. 其中|Ds|≪|Dp∪Du|,且|Dp|<|Du|,|A|表示集合A的基数.
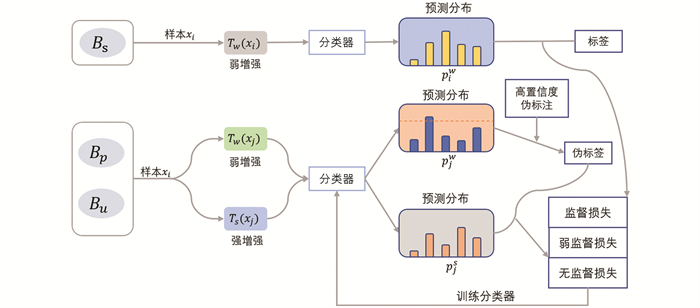
另外,用Bs,Bp和Bu分别表示训练过程一个Batch中的标记、偏标记和无标记样本集合;Tw(x)和Ts(x)分别为样本x的弱增强样本和强增强样本;p(y∣Tw(x))则为样本的类别预测分布. 本研究所提方法(CR-SSPL)框架如图 1所示,其主要思路是在目标函数中加入有效可靠的弱监督信息和无监督信息. 强弱增强技术借鉴了对比学习的思路,有利于学习器进行更准确的特征表示,带有高置信度阈值的伪标注技术则保证只添加可靠的样本信息参与训练过程,一致性正则化准则最小化同一样本增强后输出相似,提升学习器的预测性能.
具体来说,CR-SSPL首先对Batch中的样本进行强弱数据增强,输入到分类器分别进行预测得到预测分布. 通过弱增强样本的分类器输出,对偏标记和无标记样本选取高置信度的伪标记,并参与训练过程. 一致性正则化方法计算出弱增强样本的高置信度伪标记和强增强样本输出的标准交叉熵损失,作为在偏标记训练集上的偏标记监督损失项lp和无标记样本集上的无监督损失项lu,与监督损失一同构成最终的损失函数,更新模型参数. 随后利用更新的模型再次得到弱增强样本的伪标记,依次循环迭代直到收敛,最终得到模型分类器.
-
一致性正则化是半监督算法中常用的一种方法,其基本思路是认为同一样本的增强版本拥有类似的模型输出. 对于同一样本不同的增强版本之间不同的模型输出可以得出两个模型输出之间的差异,可以基于差异最小化进行模型训练.
式中:M为所考虑样本的总数;um为第m个样本;T(um)为样本um的增强样本,得到的增强样本的类别预测分布是p(y∣T(um)). 值得注意的是,因为增强函数T(·)的随机性,上式中的两个部分值并不相同. 增强函数T(·)和损失函数都可以根据问题进行改变替换. 在本研究中采用了弱增强和强增强两种方法,弱增强函数为Tw(·),强增强函数为Ts(·). 在弱增强方法中,我们只对图像进行随机地翻转和平移增强策略;在强增强方法中,我们使用了RandAugment[22]数据增强策略,RandAugment是AutoAugment[23]的一种变体,它不需要使用标记数据提前学习,对于每个样本都是进行随机增强.
伪标记方法也是半监督学习中流行的方法之一. 它通过模型来获取无标记数据的人工标记. 在实际应用中,通常取模型输出中标记最大值的标记作为无标记数据的伪标记. 同时,对于标记最大值可以做一个阈值的要求来确保伪标记的可信度. 伪标记采用如下损失函数:
式中:Ⅱ(·)为指示函数;qm为样本um的预测分布;
$\hat{q}_{m}$ 为其伪标记. 一般来说,$\hat{q}_{m}$ 采用硬标记的形式,也就是基于argmax(qm)生成一个one-hot向量. H($\hat{q}_{m}$ ,qm)是$\hat{q}_{m}$ 与qm之间的交叉熵. -
在2.1所描述的问题背景下,数据集只含有极少量的标记和偏标记,同时包含大量的无标记样本. 本研究所提方法CR-SSPL的损失函数由3个部分组成:其中ls为确切监督损失项,lp为偏标记监督损失项,lu为无监督损失项.
式中:确切标记数据只通过弱增强处理来产生弱增强样本Tw(xb);ls为Tw(xb)的模型输出与标记的标准交叉熵损失;B为标记样本个数.
对于偏标记数据,通过弱增强处理来产生弱增强样本Tw(xb),将Tw(xb)的模型输出变换为one-hot向量,其中伪标记为样本候选集合中的最大值,保证了伪标记一定存在于原始的标签候选集;通过强增强处理来产生强增强样本Ts(xb),lp为Tw(xb)的硬输出
$\hat{p}\left(y \mid T_{w}\left(x_{b}\right)\right)$ 与Ts(xb)的预测分布之间的标准交叉熵损失. 用kB表示偏标记样本个数,lp表示如下:本研究在弱增强样本的伪标记生成过程中,对弱增强样本输出的候选标签的最大值做了阈值的要求,以此来确保伪标签的可靠性,对于低于阈值的样例,并不将它的损失计算到lp中(公式5):
由于每个类别的学习难度并不相同,这里需要通过评估每个类别的学习状况来动态地设置每个类别的置信度阈值,具体地,通过动态阈值函数τp(·)动态设置每个类别的阈值.
式中:σt(c)为c类在阶段t时候的贴上伪标签的偏标记样本个数;N为所有的偏标记样本数目;τ为人为选取的固定值,本研究的τ大小设置为0.95. σt(c)的值越大,表示第c类的学习程度越好,此时第c类的置信度阈值τp(c)也会相应地增大,以挑选更可靠的样本进行训练,以此来达到更好的训练效果.
对于无标记数据的处理方法和偏标记数据的处理方法类似,分别用Tw(·)和Ts(·)来生成弱增强样本Tw(xb)和强增强样本Ts(xb),将Tw(xb)的模型输出转变为one-hot向量,lu为Ts(xb)的模型输出和one-hot向量的标准交叉熵损失.
最终,总的损失lall为3个损失项的和,当然也可以给予3个损失项不同的权重比例以获得更好的结果,在本研究中3个损失项的权重都为1.
算法1 基于一致性正则化的偏标记半监督学习算法(CR-SSPL)
Input:标签集Y={1,…,q};一个Batch中的标记数据集ds={(xb,pb):b∈(1,…,Bs),pb∈Y};偏标记数据集dp={(xb,pb):b∈(1,…,Bp),pb⊆Y};无标记数据集du={ub:b∈(1,…,Bu)};未知样本x*;最大迭代次数T;偏标记数据动态阈值τp;无标记数据动态阈值τu
Output: x*的预测标签y*
Progress:
(1) while i<T do
(2) for c=1 to q:
(3) 更新公式(6);
(4) 从数据集中随机选取一个Batch的
(5) 数据集,对数据进行数据增强;
(6) for b=1 to Bs:
(7) 计算公式(3);
(8) for b=1 to Bp:
(9) 计算公式(5);
(10) 更新动态阈值τp;
(11) for b=1 to Bu:
(12) 计算公式(7);
(13) 更新动态阈值τu;
(14) 通过公式(8)计算损失,通过随机梯
(15) 度下降更新模型参数;
(16) i←i+1
(17) end while
(18) 预测未知样本x*的标签
2.1. 问题陈述和方法框架
2.2. 一致性正则化和伪标记方法
2.3. 基于动态置信度阈值的损失函数
-
通过设置不同的偏标记样本比例、偏标签生成概率,在5个基准数据集上共生成45个不同情况的数据集进行实验,与4个代表性的深度半监督方法以及偏标记学习方法在分类精度和收敛速度上进行对比,验证所提方法的有效性.
-
实验选取了5个基准数据集:MNIST[24],Fashion-MNIST[25],SVHN[26],Cifar10和Cifar100[27],在此基础上通过不同设置生成相应的偏标记数据集. 在数据集中的每个类别上仅有4个确切标记样本.
对于q分类问题中的每个样本来说,除了样本的真实标记一定存在于偏标记样本的候选标签集合,其余的(q-1)个标记都以概率β来添加到样本的候选标签集合之中. 其中在前4个数据集上的β∈{0.1,0.3,0.5},对于Cifar100采用的β∈{0.05,0.1,0.2},β的值越大意味着每个偏标记样本具有越多的候选标签数量,监督信息更加不准确,分类问题更加困难. 同时,为了研究偏标签样本数量对于分类器性能的影响,我们还设置不同的偏标记数据Dp与无标记数据Du所含样本数量比例,具体的比例大小为|Dp|/|Du|∈{1/9,1/4,2/3}. 因此,最终一个原始数据集对应了9种不同情况,共得到45个偏标记数据集.
-
本研究所提方法CR-SSPL和以下4个深度学习相关方法进行比较:① FlexMatch[19],一种基于一致性正则化和伪标签的图像半监督学习算法,其性能已达到与强监督相近的效果. 在FlexMatch算法中,将偏标记样本看作无标记样本来训练,标记样本设置和所提方法相同;② FIX-SSPL:模型架构与所提CR-SSPL相同,但采用固定的置信度阈值,本实验中取为0.4;③ LWS[12]-CNN,一种可以处理图像分类问题的偏标记学习算法,通过风险一致性构建损失函数进行模型训练学习. LWS-CNN方法采用原文的推荐设置;④ LWS[12]-WRN,LWS的架构中采用WideResnet神经网络模型.
需要指出,LWS是近期深度偏标记学习代表性方法,文献[12]的研究显示,与同类PRODEN[13]和CC[14]相比,LWS算法在MNIST,Fashion-MNIST,SVHN,Cifar10数据集上的所有情形下都取得了更高的分类精度,因此在同类方法中选取了LWS进行对比.
-
基于PyTorch使用NVIDIA Tesla T4 GPU进行了实验,在所有方法实验中都采用28层的WideResNet神经网络模型,对于LWS算法同时进行了其推荐设置的实验. 采用了动量为0.9的SGD优化器,衰减权重为5e-4,学习率为3e-3,同时在Cifar100数据集上的batchsize大小为64,其余4个基准数据集的batchsize大小为16. 使用固定阈值的SSPL方法阈值设置为0.4.
-
从表 1至表 3中可以看到,CR-SSPL和FIX-SSPL在所有数据集以及各种实验设置下的精度都要优于对比算法的精度(每列最高精度加黑表示). 这是由于CR-SSPL能够同时利用弱监督信息和无监督信息来进行模型训练,这是半监督学习算法FlexMatch和偏标记学习算法LWS所不具有的. 同时,CR-SSPL在绝大多数数据集上要优于FIX-SSPL方法,其中,在MNIST数据集上CR-SSPL的分类精度劣于FIX-SSPL,我们猜测在学习难度较低的任务下,随着学习的深入,动态阈值会更新到较高的数值,一些未达到阈值然而对模型学习有利的样本会被舍弃,因此产生这样的现象;在学习难度较高的任务下,动态阈值机制会比固定阈值机制的精度有较大提升,这也在CIFAR100数据集中得到了验证.
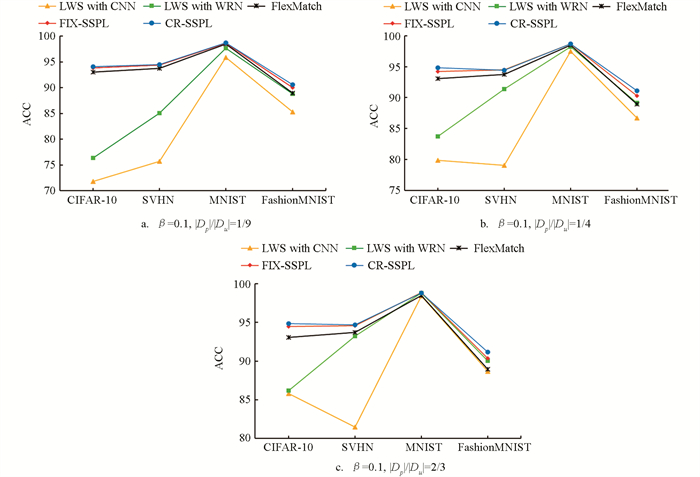
为了更清晰地显示不同设置下各算法的表现,以及偏标记样本比例和参数β对于结果的影响,在图 2中我们固定了β=0.1,画出不同的|Dp|/|Du|取值时5种比较算法和基准半监督算法Flexmatch的精度折线图. 横轴为4个不同的数据集,纵轴为各算法对应的测试精度. 由于CIFAR-100类别多,难度大,精度相比其他数据集较低,因此单独把它的结果做成图 3.
从图 2和图 3可以看到,在相同数据集和相同的β下,偏标记数据相对于无标记数据的占比,即|Dp|/|Du|的值越大,CR-SSPL相对于其他算法的精度提升也就越多;从不同的数据集来看,在学习难度较低(即Flexmatch取得很高精度)的数据集上,CR-SSPL提升空间较小,比如在MNIST数据集上,Flexmatch的精度已经达到98%以上,CR-SSPL算法和对比算法的精度几乎持平,但仍然有所提高.
对于学习难度较大的分类问题,所提方法相对其他对比算法有非常明显的优势. 从表 3中可以看到,在CIFAR100数据集上,|Dp|/|Du|=2/3且β=0.05时,CR-SSPL算法的精度比FlexMatch算法高20.34%,比LWS提升6%~10%. 通过图 3也可以清晰看到所提方法在CIFAR-100数据集上的优势,在所有数据和设置下CR-SSPL都取得了明显最优的结果. 由此可见,在越困难的学习场景下,偏标记信息对于模型学习的重要性也就越高;同时相比于LWS算法,CR-SSPL算法的精度也有很大的提升,无标记数据的无监督信息对于模型学习也有很大的作用.
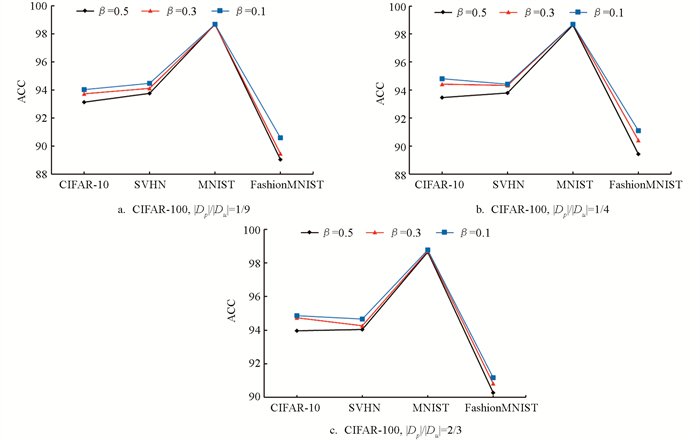
参数β对于分类精度也有重要的影响,参数β表示生成偏标记数据集时添加到候选标签集合的概率. β值越大,表示一个样本的候选偏标记越多,监督信息越弱. 从图 4中可以看到,在相同的算法和相同的|Dp|/|Du|值下,算法分类精度随着参数β的增大略有降低,因为β值越大意味着越模糊的标签信息,学习的难度也随之增大. 但对于所提方法,在前4个数据集上β由0.1到0.3到0.5变化时,精度下降的幅度不超过1%,具有较强的稳定性.
-
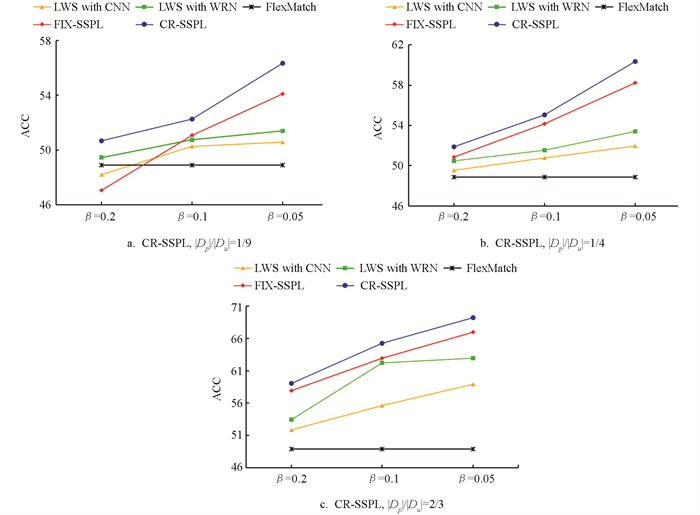
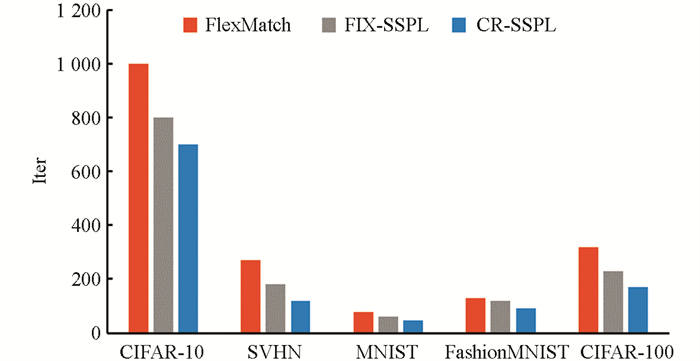
CR-SSPL不仅在分类精度上优于其他对比算法,所需的收敛迭代速度也比其余算法更快. 从图 5中可以看出,在相同最大迭代次数下,CR-SSPL算法模型收敛所需的迭代次数远小于FlexMatch算法,也就是说CR-SSPL算法的模型学习效率远高于FlexMatch算法,利用偏标记数据中的弱监督信息帮助模型训练,不仅提高了模型的分类精度,还缩减了模型的训练时间,提高了模型的收敛速度. 另外,与FIX-SSPL算法相比较,使用CR-SSPL算法的模型收敛速度也要更快,这是由于前期训练过程中模型的分类精度较低,大多数样本的最大类别预测值达不到固定阈值,少部分能够达到固定阈值的样本才能进行模型训练,自然要比CR-SSPL算法耗费更多的训练时间. 另外,由于CIFAR-100训练时采取了较大的Batch Size,故图 5中CIFAR-100的训练迭代次数较少.
3.1. 实验设置
3.1.1. 数据集及偏标记数据生成方法
3.1.2. 对比算法
3.1.3. 程序运行环境及部分参数设置
3.2. 分类准确率结果及对比分析
3.3. 收敛速度结果及分析
-
本研究在拥有极少量标记样本、少量偏标记样本和大量无标记样本的图像分类问题上,运用一致性正则化方法和伪标签方法提出了一种新的图像分类偏标记半监督学习算法(CR-SSPL),CR-SSPL在45种不同情况下数据集的分类精度都优于其他对比算法,同时在模型收敛速度上也有提升. 本研究主要贡献在于:①将弱监督和无监督学习结合起来,设计了包含3个损失项的新目标函数;②利用一致性正则化方法和伪标签方法充分利用了样本中的3种监督信息,通过置信度阈值考虑了参与训练的伪标记样本的可靠性;③ CR-SSPL在细粒度的大数据分类问题中显示出了显著优势. 未来将在本研究基础上进行扩展,研究偏多标签半监督学习问题.