



 下载:
下载:


-
开放科学(资源服务)标识码(OSID):

-
柑橘是我国南方广大农村重要的水果经济作物,也是我国南方农村脱贫攻坚和乡村振兴的重要产业之一[1]。氮素是植物生长的三大必需营养元素之一[2],通过监测作物氮含量,可以及时、快速地诊断作物氮素状况,从而为作物生长及时采取相应的氮素调控策略。此外,氮也是蛋白质[3]和叶绿素[4]的重要组成成分,对柑橘的生长发育至关重要。监测柑橘叶片氮水平可以为柑橘氮素及时采取相应调控措施提供技术支撑[5]。然而,目前柑橘叶片氮含量测定方法涉及田间大量叶片的采集、烘干、制样、消煮等繁琐的前处理,使用试剂耗材和化学仪器的测定过程也可能带来环境污染问题,且费时费工、成本昂贵,在大规模的田间实验中难以推广实施。
近年来,高光谱成像技术作为一种快速、高效的非破坏性检测手段,为叶片氮含量的测定提供了新的可能。高光谱技术无需对作物样品进行破坏性离体采样与化学分析,即可获得作物生长的即时信息。已有研究利用各种算法预测植物叶片氮含量并取得了一定进展。例如,文献[6]利用非支配的精英策略遗传算法优化极限学习机(NAGA2-ELM)预测粳稻叶片氮含量,训练集的决定系数(R2)达0.82,均方根误差(RMSE)为0.30;文献[7]利用支持向量机对水稻氮含量进行预测,预测R2为0.75;文献[8]使用岭回归、支持向量机、人工神经网络、决策树和随机森林等机器学习算法预测柑橘叶片氮、磷、钾、硫、铜等元素含量,其中随机森林建模的精确度较高,氮元素模型的训练集R2达到0.91;文献[9]利用基于核极限学习机(KELM)、支持向量机以及随机森林等算法预测茶叶在充足阳光和弱光下的叶绿素含量,以确定合适的回归模型。目前,高光谱技术在预测植物叶片元素含量方面的研究多聚焦于传统机器学习算法,对优化算法的探讨较少。鉴于此,本研究结合遗传算法和蝙蝠算法对偏最小二乘回归模型进行优化,以提高模型的性能和预测精度。
本研究首先对比分析了原始光谱反射率、经过4种预处理后的光谱反射率和柑橘叶片氮含量之间的相关性,然后采用支持向量机回归(SVR)、偏最小二乘回归(PLSR)以及结合遗传算法和蝙蝠算法的智能化优化偏最小二乘回归(O-PLSR)来构建预测模型。通过比较各模型的预测精度,筛选最适宜的预处理方法、特征波段选择算法以及模型方法,以期为柑橘叶片氮含量的快速、准确估测提供一种有效的技术途径。
全文HTML
-
试验于2023-2024年度在重庆市北碚区歇马街道西南大学柑桔研究所沃柑园和龙回红脐橙园进行。果园地处北纬29°45′、东经106°22′,气候为亚热带季风气候,年均气温为18 ℃,其中:沃柑园土壤为紫色土,土壤pH值为7.39,碱解氮含量99.82 mg/kg,有效磷含量109.75 mg/kg,速效钾含量258.04 mg/kg,有机质含量为26.71 g/kg,以20年生枳(壳)为基砧、血橙为中间砧的沃柑为试材;龙回红脐橙园土壤为紫色土,土壤pH值为7.46,碱解氮含量98.38 mg/kg,有效磷含量110.39 mg/kg,速效钾含量275.37 mg/kg,有机质含量为30.69 g/kg,以2年生的枳壳砧和枳橙砧龙回红为试材。
-
2023年11月,随机选取14株沃柑树和56株龙回红脐橙树(枳橙砧龙回红28株,枳壳砧龙回红28株),共70株样本树。从样本树树冠四周中部位置随机采集8片叶子混合为一个样品。沃柑树重复3次采样,共采取42个样本。龙回红树单株重复,共采取56个样本。共有98个样本进行光谱数据采集与氮素含量化学检测分析。采集后的样品立即放入事先准备好的带有冰袋的保鲜盒中临时保存,迅速带回实验室用去离子水洗净并擦干样品,用高光谱成像仪进行图像数据采集;再将样品放置于恒温干燥鼓风箱杀青、烘干后用H2SO4-H2O2法消煮;最后用半微量凯氏定氮法测氮含量[10]。98个样本随机分成建模集(78个)和验证集(20个),其叶片氮含量检测结果如表 1所示。
-
使用中国台湾五十铃光学公司的光谱成像数据采集软件和HIS Analyzer软件分别进行图像采集和图像校正。使用ENVI 5.6提取平均光谱。使用python 3.11对光谱数据进行预处理,提取特征光谱,建立模型。使用SPSS 25.0软件进行相关性分析。
1.1. 研究区概况
1.2. 数据测量
1.3. 软件使用
-
如图 1所示,利用高光谱成像系统获取柑橘叶片高光谱图像数据,其中ROI表示感兴趣区域。该系统由摄谱仪(ImSpector V10E,芬兰)、电子倍增电荷耦合器件(EMCCD)相机(Raptor photonics,FA285-CL,英国)、照明系统(150 W/21 V,Illumination Technologies,Inc.,美国)、移动平台、计算机组成,该系统采集400~1 000 nm波长范围内的图像。采集过程将叶片固定于反射率可忽略不计的黑色纸板上。将黑色纸板置于移动平台,设置平台移动速度为1.78 nm/s。采集图像后进行黑白校正,校正公式如下:
式中:Rc为图像的相对反射率;Rx为样品图像;Rw为白板校正图像;Rd为黑板校正图像。
-
选择整个叶片作为ROI,使用ENVI 5.6提取平均光谱数据。提取过程为:设置阈值;从某一波段(band300)生成二值化图像;通过掩膜处理得到ROI;求ROI区域的平均光谱。
在本实验中,为了减轻光的散射以及噪声的影响,需要对光谱数据进行预处理。采用标准正态变换(SNV)、小波变换(WAVE)、Savitzky-Golay平滑滤波(SG)、一阶导数(D1)、二阶导数(D2)对原始光谱(OS)进行处理。
-
竞争自适应重加权采样法(CARS)[11]是将蒙特卡洛采样和偏最小二乘结合为一体的特征选择方法。CARS对波段进行循环分析,保留偏最小二乘模型中回归系数绝对值权重较大的值,去除较小的值,并将较大的值作为新的子集继续进行循环分析,具有达尔文“适者生存”的特点。经过多次CARS循环,去除非信息变量。选择PLS模型交叉验证来评估新子集的降维效果。最终选择均方根误差小的子集中保留的波段为特征波段[12-13]。
-
连续投影算法(SPA)是前向特征波段选择方法。SPA首先利用向量投影的方法,将当前波长投影到其他波长,比较投影向量的大小,将投影向量最大的波长作为待选的波长;然后基于多元线性回归选择最终的波长[14-15];最后,在校正模型的基础上通过计算交叉验证均方根误差(RMSECV)来获得特征波长[16]:
式中:yi与
$ \hat{y}_i$ 分别为模型预测氮含量的真实值和预测值,m表示预测值的数量(和真实值的数量相同)。 -
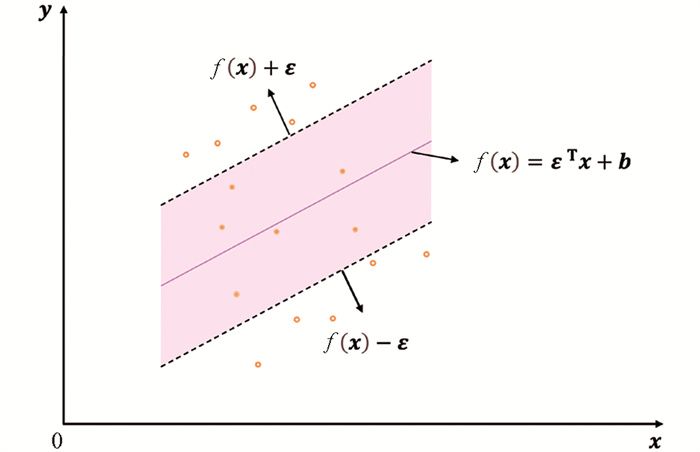
支持向量机回归(SVR)构建了一个宽度为2ε的间隔带。在输入空间和超平面找到一个函数点,若其训练值位于间隔带内,则预测是正确的。图 2中± ε表示支持向量的随机误差,f(x)=εT x + b为超平面[17-18]。本研究利用SVR预测叶片氮含量,以光谱特征为变量,将这些特征投射至高维超平面,而后进行泛化拟合。
-
PLSR适用于自变量和因变量之间存在多重共线性的情况,通过主成分分析对因变量进行降维,建立新的综合变量,这些综合变量能够在很大程度上解释自变量和因变量之间的协方差[19]。
-
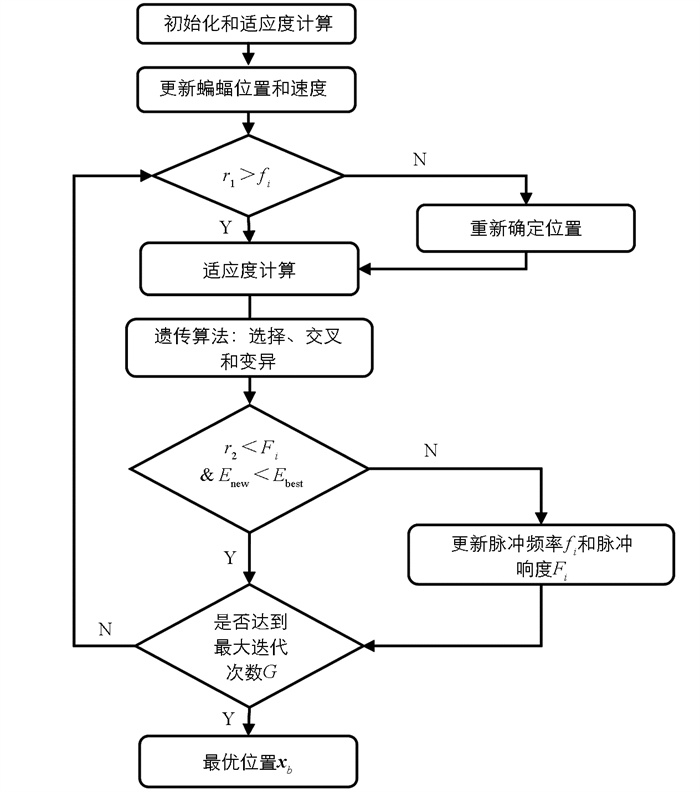
蝙蝠算法是模拟蝙蝠通过超声波寻找食物的过程。蝙蝠在寻找食物时会根据当前位置和食物的信息进行移动,并通过回声定位感知食物的位置和距离,在接近食物时脉冲的发射频率会增加、脉冲的响度会减小[20-21]。所以蝙蝠算法中有两个关键操作:更新蝙蝠个体位置、调整脉冲的发射频率和响度。
基于此,引入了遗传算法,进行选择、交叉和变异。每次迭代过程中,选择最优的个体传入下一代。子代进行两两交配,每个个体以Pm的变异率进行染色体变异[22],最后形成一个新的种群,提高了算法的搜索能力。具体流程图见图 3。
混合蝙蝠智能算法优化PLSR的具体步骤如下:
1) 参数初始化。设置蝙蝠个数nbats(即种群规模)和最大迭代次数Mmax,随机生成初始蝙蝠的位置xi和速度v。
2) 定义适应度函数用以评估模型的性能。目标函数的值为度量的标准。
3) 更新蝙蝠个体的位置和速度,随机生成一个[0, 1]上的r1。若r1大于当前蝙蝠的脉冲发射频率fi,则进行局部搜索重新确定位置;否则在目标空间随机生成一个值。计算新位置的适应度并执行遗传算法算子操作,包括选择、交叉和变异。然后随机输出一个[0, 1]上的数r2,若r2小于当前蝙蝠个体的脉冲响度Fi,且当前个体的适应度的值小于目前最优个体的适应度值(即当前蝙蝠个体的位置被接受),则更新脉冲发射频率和脉冲响度,输出新的最优个体的位置xb,判断是否达到最大的更迭次数G,若是,返回具有最佳适配度的参数配置。
4) 利用最佳配置构建模型,使用训练集数据进行模型训练。
-
模型的验证指标采用预测值和实测值的R2,RMSE。R2越接近于1,RMSE越小说明模型精度越高。计算公式为:
式中:yi与
$ \hat{y}_i$ 分别为模型预测氮含量的真实值和预测值,yi表示真实值的平均值,m表示预测值的数量(和真实值的数量)。
2.1. 高光谱数据采集与校正
2.2. 高光谱数据预处理
2.3. 特征波段的选择
2.3.1. 竞争自适应重加权采样法
2.3.2. 连续投影算法
2.4. 模型建立
2.4.1. 支持向量机回归模型
2.4.2. 偏最小二乘回归模型
2.4.3. 混合蝙蝠算法智能优化
2.5. 模型评价
-
对不同光谱变换后各波段的氮含量与反射率的相关性分析结果如图 4所示。从图 4可知,OS在300~400 nm各波段反射率与氮含量之间几乎没有显著的相关性,在400~800 nm各波段反射率和氮含量呈显著的负相关,且在676 nm处两者相关性最高(R2=-0.437)。SNV变换后的500~600 nm和700~800 nm波段范围内的相关性得到显著提高,且在523 nm(R2=-0.595)和737 nm(R2=-0.642)处相关性最强;经D1变换后的光谱在774 nm处相关性最强,达到0.527;经D2变换后的光谱在613 nm和640 nm处与N相关性显著,分别为-0.581和-0.597;经SG变换后的光谱和OS的相关性系数曲线基本一致,且在675 nm和676 nm处相关性最高,为-0.437。综上所述,SG预处理效果更理想,可能是因为在相关性的分析中,SG变换后的光谱和OS的相关性曲线基本一致,在某些波段上,SG变换后的光谱的相关系数甚至高于OS。
-
图 5为基于CRAS算法选取的OS及各种预处理后的特征波段。以D1为例,随着迭代次数增加,被选取的特征波段数量在不断减少,RMSECV也呈下降趋势,当运行到21次时RMSECV达到最小值,随后又开始逐渐增加。因此在迭代次数为21时确定特征波段,此时选择的特征波段数为33。从D2变换后的光谱中选取24个特征波段,从SG变换后的光谱中选取91个特征波段,从WAVE变换后的光谱中选择37个特征波段,从原始波段中选取33个特征波段。总体而言,经CRAS算法筛选的特征波段分布均匀。
-
将SPA算法与氮含量相结合,筛选特征波段,结果见图 6。以D1为例,由图 6b可以看出,随着模型中变量数的增加,RMSE大体上呈下降的趋势,当变量数为24时,RMSE的下降趋势变缓。因此在所有波段中选24个特征波段,从D2变换后的光谱中选取24个特征波段,从SG变换后的光谱中选取15个特征波段,从WAVE变换后的光谱中选取11个特征波段,从原始波段中选取11个特征波段。
-
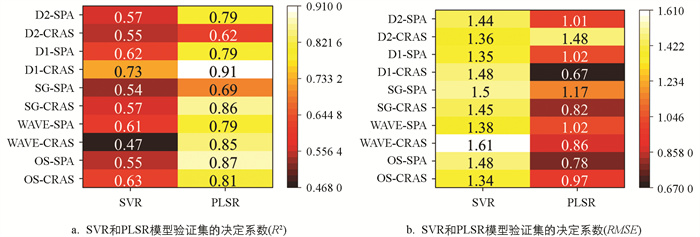
使用不同预处理变换、特征波段选取算法预测氮含量的精确度尚不清楚,因此建立不同的模型预测柑橘叶片氮含量,结果如图 7所示。
对于OS预处理方法,PLSR模型预测氮含量的准确度高于SVR模型。经过同种算法选择特征波段后,不同预测模型也会得出不同的精确率:经过SPA特征波段选取后,PLSR模型比SVR模型的R2提高了58.2%,RMSE减少了47.3%;经过CRAS特征波段选取后,PLSR模型比SVR模型的R2提高了28.6%,RMSE减小了27.6%。
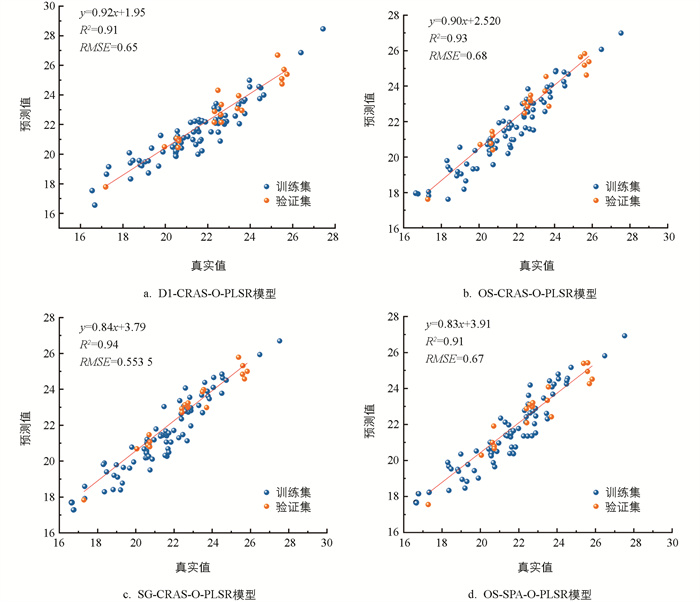
光谱变换后建立的PLSR模型精确度高于SVR模型,因此,使用PLSR模型估计柑橘叶片氮含量具有较高的精确度,总体性能稳定。D1预处理、CRAS特征波段选取后PLSR模型(D1-CRAS-PLSR)的R2为0.91,RMSE为0.67,故D1-CRAS-PLSR为预测柑橘叶片氮含量的最优模型。
-
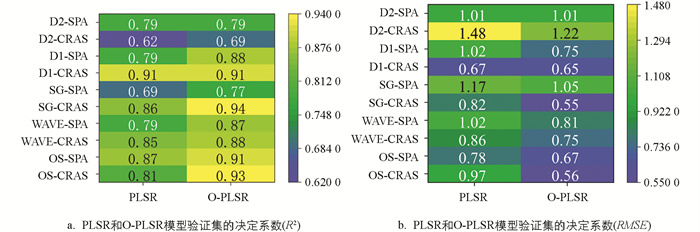
为了建立更有效的回归预测模型,在PLSR模型的基础上进行优化,提高算法的精确度。通过遗传算法(GA)和蝙蝠算法(BA)结合智能优化PLSR,提高预测精度,表现为更高的R2和更低的RMSE(图 8)。与PLSR相比,O-PLSR均在不同程度上提高了模型的预测水平,R2最大可提高14.8%,且SG预处理,经SPA特征波段选取的PLSR模型(SG-SPA-O-PLSR)的R2达到了0.94,RMSE为0.55(图 9)。
3.1. 光谱变换及相关性分析
3.2. 特征波段的选取
3.2.1. 基于CRAS算法进行特征波段选取
3.2.2. 基于SPA算法进行特征波段选取
3.3. PLSR和SVR模型估计氮含量结果
3.4. 基于HBA混合蝙蝠智能算法优化PLSR模型预测氮含量
-
建模前对原始光谱进行适当的预处理,可减少数据中的噪声和干扰,增强光谱反射率和柑橘叶片氮含量之间的相关性,从而提高模型精度。本研究中,采用O-PLSR建模,原始光谱和经SG平滑处理后的光谱建模效果表现更佳,决定系数R2分别为0.91、0.94。SG平滑后建模效果得到增强,可能是因为原始光谱存在波动或突变,数据平滑可以降低光谱的噪声,使光谱数据变平滑、连续。相较之下,经WAVE、SNV、D1、D2预处理后建模效果变差,可能原因是光谱预处理过程中数据可能出现了失真或信息丢失,导致具有固有特征和模式的部分数据在预处理过程受到一定影响。
对于特征波段选取,OS运用CRAS和SPA分别筛选了33个和15个特征波段,分别占全波段的6.6%、3.0%。SPA筛选的特征波段少于CRAS,在相同的建模方法下,利用CRAS建模的R2为0.93,利用SPA建模的R2为0.91,表明CRAS筛选特征波段的算法优于SPA,这与文献[23-24]的研究结果一致,原因可能是CRAS算法在消除冗余信息的过程中尽可能多地保留了有效信息,提高了建模精度。
在采用OS以及经SG、SNV、WAVE、D1、D2预处理后的光谱进行建模时,PLSR的建模准确度均高于SVR,这与文献[25-26]的研究结果类似。原因在于PLSR建模过程中能处理多重共线性问题,当输入的特征之间存在较高的相关性时,PLSR可通过建立潜在的变量来减少特征之间的相关性,从而提高模型的稳定性和预测能力。相比之下,SVR对于多重共线性的处理能力较弱。此外,PLSR可通过降维的方式降低样本数与噪声问题,而SVR对样本的数量和噪声的限制较为敏感。
目前,机器学习在分析处理高光谱数据信息方面得到了广泛应用。PLSR已经广泛运用于预测作物营养元素等领域,但在PLSR优化方面仍然需不断提升。本研究结合遗传算法和蝙蝠算法对PLSR进行了优化,证明了该算法在柑橘叶片氮含量预测中的有效性。通过遗传算法和蝙蝠算法相结合,在全局和局部进行搜索和优化,提高了PLSR模型的性能,获得了最优的回归结果。通过SG-CRAS-O-PLSR模型显示出较好的叶片氮含量估测能力,验证集R2可达0.94,进一步验证了O-PLSR对作物元素含量的预测能力。因此,O-PLSR算法可预测柑橘叶片氮含量,便于对柑橘生长动态信息进行实时监测。
-
通过相关性分析、特征波段筛选及模型建立,研究提出了SG为柑橘叶片氮含量高光谱预测的最佳预处理方法,且SG-CRAS特征波段选取方法表现出更高的准确性。智能优化的PLSR模型(SG-CRAS-O-PLSR)精度相对最高(R2为0.94,RMSE为0.55)。为提高预测精度,今后可扩大样本容量,并涵盖不同品种的叶片光谱信息,提供更稳定、可靠的柑橘氮素无损监测技术。