


 下载:
下载:
-
传统监督学习框架下多种算法对单一语义具有较好性能[1],但是现实中对象常表现出多义性,因此需要建立多个标签子集,多目标学习也变得越来越受关注.多目标学习在数据挖掘中的应用日益成为广大学者研究的焦点[2].多目标学习指其中的一个示例有多个类别标记与之相对应,其最终实现示例预测多个类别的标记[3].这样的例子有:某个基因序列[4],其可能具有多个功能,如“新陈代谢”和“合成白细胞”等.
有关多标记学习的研究已有很多,目前提出的学习方法和策略主要有两类:①提出新的算法或改进的算法,文献[5]中给出一种k近邻方法的多标记分类方法,并进行改进使得其性能更优.文献[6]提出了基于概率隐语义分析(Probabilistic latent semantic analysis,PLSA)模型的多标记假设重用文本分类算法,解决了多标记文本分类时文本标记关系不明确以及特征维数过大的问题.文献[7]中提出了一种用于多标签学习的多层ELM-RBF神经网络方法,在单标签和多标签数据集上都有较好性能.该类方法在多标记分类上局限性比较大. ②基于转换的PT(Problem Transformation)策略[8-9],总共包含有PT1~PT5等5种方法.其中,PT5的实现思路是首先把(xi,Yi)的多标记示例经过一定的处理后将其分成|Yi|个单标记数据集,接着再将得到的|Yi|个单标记数据集经过一定的处理后形成与之对应的一个单标记分类模型.确定一个合适的阈值是该方法实现的关键,阈值的取值大小直接影响分类器的性能.文献[10]中提出了一种标签优先标记集合(LPP)转换方法,根据标签的重要性排序来解决标签依赖性问题.文献[11]提出了一种基于标签间相关性的多标签分类方法,它使用了问题变换方法和算法适应方法,该方法分类准确性更高.
上述基于问题转换方法的关键是确定最低阈值,然而阈值的设定还没有一个准确的原则,如设置过高,类别标记会被漏判,如设置过低,则会出现多判.如何确定最低阈值还是目前的一个难题,针对这个问题,本文提出了一种基于最低阈值的多标记学习算法(TFEL,Threshold For Each Label),根据类别标记学习为每个类别得到一个最低阈值.当分类器将一个测试示例预测为某个类别标记的分值大于为该类别标记学得的最低阈值时,则将该类别标记添加到该测试示例的最终分类结果中.实验结果表明,本文提出的TFEL方法具有较好的分类效果.
全文HTML
-
PT5是将(xi,Yi)的多标记示例经过一定的处理后形成|Yi|个单标记数据集,比如,(x1,{y1,y2})可以转换成(x1,y1)和(x1,y2)2个单标记示例,接着分配一个单标记分类器给上述各个数据集.同时,所有的单标记分类器都会有一个对应的分布,表示每个对象属于相应类别的概率,并根据分布为每个对象输出一组类标记集合.通常情况下取threshold=0.5为最低阈值.进行类别yl包含示例xi的概率预测时,如果该数值大于最低阈值,则将类别yl合并到示例xi预测类别集合.公式表示形式为
在PT5方法中,为其设置一个适当的最低阈值对该方法非常重要,在现有的多标记学习算法中设置一个适合的最低阈值也十分必要.阈值设置得过高或过低都会影响到预测结果.当我们设置的阈值过高时,得到的预测结果就可能不全;当我们设置的阈值过低时,就会得到大量的无用类别.因此,在所有的类别中设置同一个阈值是不恰当的.
为解决设置最低阈值的难题,基于最低阈值多目标学习,本文提出了TFEL学习算法.在使用该算法时,对于类别yl(1≤l≤|Y|),都将会有一个阈值与之对应,在本文中将其记为thresholdl,同时所有类别的标记集合记为Y.如果一个示例xi预测为类别yl,可能性f (xi,yl) > thresholdl,将其代入式(2),并将yl的类别标记添加到对xi预测的类别标记集合中,即
TFEL方法对传统单标记学习算法和现有多标记算法中的阈值确定具有通用性.
-
对于多标记学习中如何设置适合的最低阈值,本文提出了一种新的学习算法——基于最低阈值的多标记学习算法(TFEL,Threshold For Each Label).
-
TFEL方法通过对训练数据集学习,根据标记学习为每个类别得到一个阈值.
-
在TFEL算法中,首先对训练数据集进行训练得到每个类别yl的概率f (xi,yl).然后将f (xi,yl)存储在相应集合中,如式(3)、式(4)所示.再对概率f (xi,yl)进行学习,为每个标记yl得一个最低阈值.
在上式中,对于类别yl中所有示例的数据集记为Dl+;对于Dl+示例中属于yl的概率f(xi,yl)的集合记为Λl+.同理,对于类别yl中所有示例的数据集记为Dl-;对于Dl-示例中属于yl的概率f(xi,yl)的集合记为Λl-.如式(5)和式(6)所示,其分别属于Λl+中的最小值与最大值区间和Λl-中的最小值与最大值区间.
在上式中,由集合Λl+中的最小概率ΛMinl+和最大概率ΛMaxl+构成的区间记为Ξl+.同理,由集合Λl-中的最小概率ΛMinl-和最大概率ΛMaxl-构成的区间记为Ξl-.
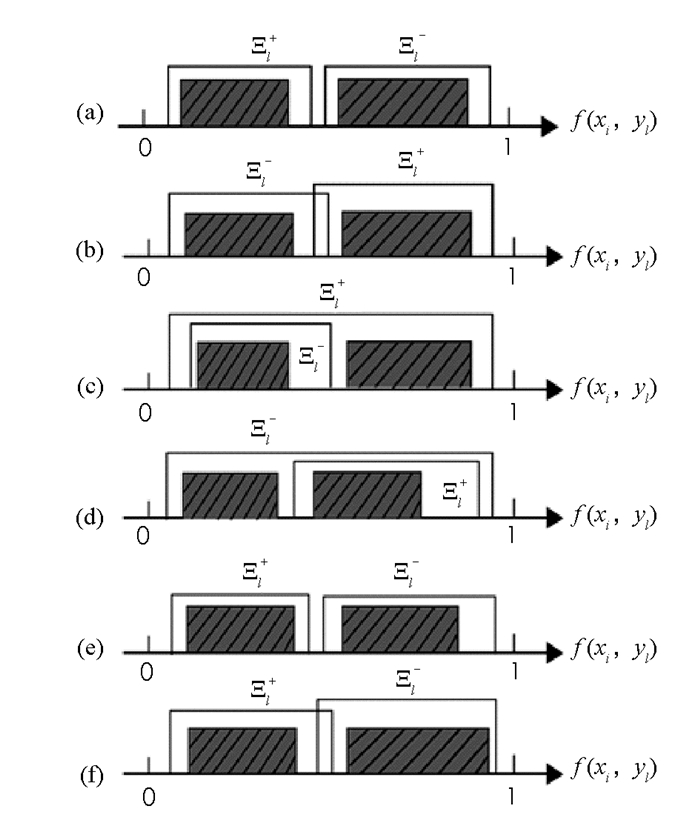
如图 1所示,区间Ξl+和Ξl-存在6种位置关系. 图 1(a)表示所有正例比负例被预测为yl的概率f (xi,yl)都高,图 1表示的是最理想状态. 2个区间有交集的情况如图 1(b)-图 1(d)所示,最常见的情况如图 1(b)所示.正确的可能性大小和f (xi,yl)存在的位置有关系,对于一个测试示例,当其被预测为类别yl的f(xi,yl)值位于交集中时,那么预测结果很有可能是错误的.当其被预测为类别yl的f (xi,yl)值位于交集两侧时,那么预测结果很有可能是正确的.其他情况如图 1(e)-图 1(f)所示,在训练集中对于本应该属于类别yl的示例,其被预测为不属于类别yl的概率要比预测为属于类别yl的概率要大,可以看出该分类器性能较差.
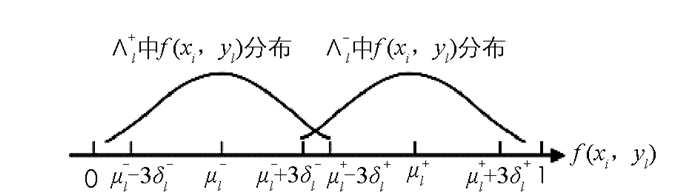
由最大值ΛMaxl±和最小值ΛMinl±可以确定区间,从图 1(a)-图 1(f)中的阴影部分可以看出,Λl+和Λl-中的分值集中分布在某一段区间上.通过χ2拟合度检验得知,Λl+和Λl-集合中的值f(xi,yl)均近似服从正态分布,如图 2所示.
-
确定正态分布中的参数μ和参数δ是求解TFEL方法中最低阈值的前提.因此,求得参数μ和δ的准确值对阈值确定很关键.本文根据无偏估计法求出其近似值,求解方法如式(7)和式(8)所示.
对Λl+中所有概率值求标准差和均值,分别记为
$ \hat{\delta }_{l}^{+}$ 和$ \hat{u }_{l}^{+} $ .同理,对Λl-中所有概率值求标准差和均值,分别记为$ \hat{\delta }_{l}^{-} $ 和$ \hat{u }_{l}^{-} $ .由正态分布图中的3δ标准可知,阈值thresholdl可能会有以下3种:式9-式10中参数均利用式7-式8中计算得到的估计值.
-
TFEL算法伪码的实现过程如下:
In:
集合D用于表示多标记数据集的集合,则有D={(x1,Y1),(x2,Y2),…,(x|D|,Y|D|)};
集合Y表示所有类别标记的集合,则有Y={y1,y2,…,y|Y|};
f(,):计算概率的函数;
thrType:阈值类型(Minl,Maxl,Midl)以及i的值;
t:测试示例;
Out:fTFEL(t)对测试示例t预测的类别标记集合.
Process:
1) 计算Λl+和Λl--,1≤l≤|Y|;
2) 根据式7-式8计算ui,δi,ul±和δl±,1≤l≤|Y|;
3) 根据上一步计算得到的结果和给定的thrType计算thresholdl,1≤l≤|Y|;
4)
$ {{f}_{TFEL}}(t)=\underset{{{y}_{l}}\in Y}{\mathop{\cup }}\, \{{{y}_{l}}\}:f(t, {{y}_{l}})>\text{threshol}{{\text{d}}_{l}} $
2.1. TFEL方法中的阈值确定
2.1.1. TFEL方法阈值分析
2.1.2. TFEL方法阈值计算
2.2. TFEL算法实现
-
多标记学习算法常用的评估标准有Hamming Loss,Average Precision,Average Precision,Coverage和α-Evaluation等.本文选取2个最适合的评估标准Hamming Loss和α-Evaluation.
-
根据Hamming Loss评估标准,用计算器分类器可以得出对象预测出的类别标记集合和实际对应的类别标记集合差异个数. D为多标记数据集,M表示数据集中对象的总数,f(x)为多标记分类器,xi为测试数据对象,Yi为xi对应的类标记集合,该评估标准可表示为式(12)所示.
其中,f(xi)ΔYi=(f(xi)-Yi)(Yi-f(xi)). Hamming loss的值越小说明分类器的性能越好,反之则差.
-
假定多标记数据集D,类标记集合Y={y1,y2,…,yL},示例xi对应的类标记集合为Yi,分类器得到的类标记集合为Pi.没有预测到的类标记集合用Mi=Yi-Pi表示;预测的错误类标记集合用Fi=Pi-Yi表示.
其中,参数α≥0,β≥0,γ≤1,β=1|γ=1,该值越大,表明分类器的性能越好.
-
为验证TFEL算法的有效性,从UCI下载数据集iris和diabetes.这2个数据集中均存在属性相同,而对应类别标记不相同的示例.实验中将这些属性相同,对应类别标记不相同的示例类别标记预处理成他们所属多个类别标记的集合.例如,存在示例(x1,y1),(x1,y2)和(x1,y3),则将示例的类别标记预处理成{ y1,y2,y3},即(x1,{y1,y2,y3}).预处理后的数据集信息如表 1所示.
为了方便获得一个示例属于每个类别标记的概率f(xi,yl),基于贝叶斯算法对分类模型进行建模.为确定阈值大小对分类结果的影响,本文根据TFEL和朴素贝叶斯算法,为每个类别设置一个最低阈值,同时为每个类别标记选取9组值.将i取1,2和3分别代入公式(9)和公式(10)中,thresholdl产生3组不同的取值(Minl,Maxl和Midl),然后通过TFEL方法对测试数据集进行分类.设定β和γ参数的取值均为1,通过Hamming Loss和α-Evaluation评估标准对分类结果进行评估.
-
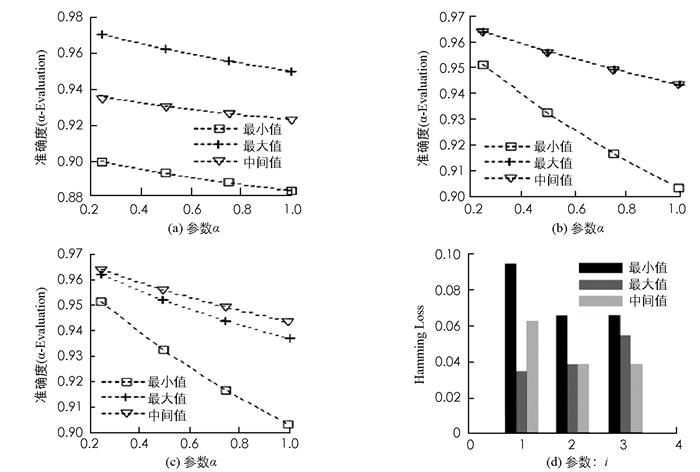
利用TFEL方法对数据集iris分类后的评估结果如图 3所示.
其中,图 3(a)、图 3(b)和图 3(c)分别是式9-式10中参数i取1,2和3时的分类结果,图 3(d)是当i取不同值时,对Hamming loss评估值的比较.通过对比图 3(a)-图 3(d)得出,当thresholdl和Maxl相等时,分类器性能达到最佳,当i=1时,准确率达到最高,Hamming loss评估值达到最低.
-
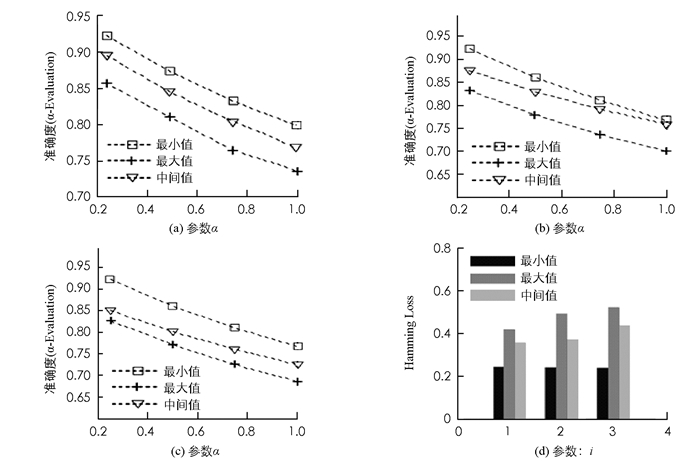
为了确定当阈值thresholdl = Maxl时,是否对每个数据集分类器都能得到最佳性能,实验利用TFEL方法对diabetes数据集进行分类,分类后的评估结果如图 4所示.
其中,图 4(a)、图 4(b)和图 4(c)分别是式9-式10中的参数i取1,2和3时的分类结果,当thresholdl=Minl时,分类器的准确率均高于其他2组取值. 图 4(d)中,当thresholdl=Mini时,Hamming loss评估值均小于其他2组评估值.通过总结图 4(a)-图 4(d)得出,当分类器对diabetes数据集的整体分类性能达到最优时,thresholdl=Minl.
实验结果表明,TFEL方法能有效的对多标记数据集进行分类,同时对于不同的数据集,在取不同的阈值时,分类器都可以表现出良好的性能.
3.1. 算法评估标准
3.1.1. Hamming Loss
3.1.2. α-Evaluation
3.2. 实验设计
3.3. TFEL方法对iris数据集分类
3.4. TFEL方法对diabetes数据集分类
-
通过对多标记学习详细的理论研究,本文结合最低阈值知识提出了多标记学习TFEL算法.通过训练数据集可以得到每一个类别标记的最佳最低阈值,这样能够使分类器的分类性能达到最佳.通过对该算法进行大量实验,结果表明TFEL算法具有较好的分类效果.但本文算法也具有一定的不足,后续工作需要:①对单标记数据进行预处理得到数据集,将TFEL方法应用于现有的多标记数据集;②将TFEL方法中的阈值确定方法应用于现有的多标记学习算法,并进行分析比较;③进一步研究数据集中每一个类别正负例个数的分布对最低阈值的影响.