



 下载:
下载:
-
在地理信息系统(GIS)的空间数据模型中, 河流通常以线状矢量数据的形式进行存储.近年来, 随着数字地图的广泛应用和WebGIS的迅猛发展, 大范围、高精度的多级河流矢量数据占用存储空间大、网络传输速度慢的问题越来越突出, 因此, 迫切需要一种能够合理并高效压缩多级河流矢量数据的方法.
经典的矢量数据压缩算法有光栏法、垂距限值法、角度限值法、Douglas-Peucker算法[1]等.其中, Douglas-Peucker算法从曲线的整体特征出发进行压缩, 具有平移、旋转的不变性的特点, 并且实现简单, 效率较高, 压缩效果好[2], 得到了广泛应用.其基本原理为:对于目标曲线, 首先设定一个距离阈值D, 然后将曲线首尾2点相连形成一条线段, 对于曲线上的其余各点, 求其与此线段的距离, 并记下最大距离Dmax;比较Dmax与D的大小, 若Dmax<D, 则将曲线上的中间各点全部舍去;若Dmax>D, 则以该最大距离点为界, 将曲线分为2部分, 再分别对这2部分重复以上过程, 直到结束.
国内外已有不少学者对Douglas-Peucker算法及其改进算法进行了研究, 如任意阈值下曲线无自相交简化的算法[3];利用径向距离作为曲线内点取舍的补充约束条件, 对Douglas-Peucker算法进行改进, 有效控制其压缩的面积误差[4];公共边对象化Douglas-Peucker改进算法[5], 通过将公共边的相关信息封装成类, 解决压缩公共边时出现“裂缝”问题等.上述研究对Douglas-Peucker算法进行了不同程度的改进, 改善了压缩质量, 但针对的均是普通的矢量数据, 而多级河流矢量数据有其自己的特征, 如支流与干流之间的空间邻接关系, 利用常规的矢量数据压缩方法往往会丢失空间特征信息.与此同时, 随着数据量的增加, 传统的串行计算技术和单纯地对压缩算法进行优化已达到瓶颈.为了满足快速、高效压缩矢量数据的要求, 迫切需要新的思路和方法提高压缩效率.
并行计算是相对于串行计算而言的, 是指在同一时间间隔内增加操作系统进程数、利用多台计算机共同实现一个任务的计算方法[6], 在数字地形分析[7]、图像处理[8]、水文模型[9]等许多领域具有广泛的应用.在矢量数据压缩的并行计算方面, 近年来也有学者进行了一定的研究, 如对不同的等高线压缩算法进行并行计算的适宜性研究[10], 在综合考虑算法时间复杂度等多个因素的基础上分析了压缩算法的并行计算适宜性;利用Douglas-Peucker并行算法在多核处理器上实时综合地图线要素[11], 将串行Douglas-Peucker算法改进为使用多核处理器的并行算法等.本文将矢量数据压缩算法与并行计算技术结合, 在Douglas-Peucker算法的基础上提出了一种顾及空间邻接关系的多级河流矢量数据并行压缩算法, 以期在保持空间邻接关系的前提下, 实现多级河流矢量数据的快速、高效压缩.
全文HTML
-
空间关系是空间实体之间由于空间位置和形状的不同而形成的相互之间的各种联系[12].邻接关系是其中的一种表现形式, 具体到多级河流数据中则体现为干流与支流之间的邻接关系.由于Douglas-Peucker算法每次针对单个曲线进行压缩, 如果直接利用该算法压缩多级河流数据, 会造成压缩后多级河流之间断裂等空间邻接关系的不一致现象(图 1).因此, 在压缩多级河流数据时, 有必要对Douglas-Peucker算法进行改进, 以保持其空间邻接关系.
保持多级河流空间邻接关系的关键在于压缩时多级河流之间邻接结点的保存, 为此要提取待压缩数据的空间邻接结点.本文利用ArcGIS对多级河流矢量数据的邻接结点进行提取.具体方法为:首先对多级河流矢量数据建立拓扑关系;其次建立河流网络数据, 通过网络分析模块提取网络数据中各线之间的结合点;最后建立河流数据与结合点之间的空间连接关系, 生成结合点的Join_Count属性(即该点连接的线个数), 删除Join_Count小于3的点, 余下的即为多级河流的空间邻接结点.
-
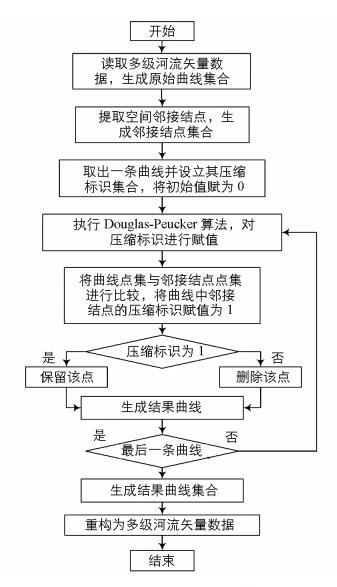
在提取空间邻接结点的基础上, 顾及空间邻接关系的多级河流矢量数据串行压缩算法流程见图 2.
1) 读取多级河流矢量数据, 生成原始曲线集合Lini{L0, L1, …, Ln-1}, 其中每条曲线由一个点集P{P0, P1, …, Pm-1}构成, 记录曲线中每个点的地理坐标(x, y).
2) 提取多级河流数据的空间邻接结点, 生成邻接结点点集R{R0, R1, …, Rr-1}.
3) 对于每条曲线的点集P, 设立压缩标识集合F{F0, F1, …, Fm-1}, F的编号与点集中点的编号一一对应, 其初始值为0.以任意点Pi(0 ≤ i ≤ m-1) 为例, 当Fi=0时, 舍弃Pi点;Fi=1时, 保留Pi点.
4) 设定压缩阈值, 逐条曲线执行Douglas-Peucker算法, 对曲线中每个点的压缩标识F进行赋值, 然后将点集P与邻接结点的点集R进行比较, 当二者之中有相同的点时(即坐标相等), 将其压缩标识F赋值为1.
5) 利用压缩标识F逐条曲线执行判断, 当Fi=0时, 将Pi点从点集P中舍去;Fi=1时, 保留Pi点.将压缩后的点集P整合为结果曲线集合Lres{L0, L1, …, Ln-1}, 并重构为多级河流矢量数据, 完成压缩.
1.1. 多级河流空间邻接关系保持方法
1.2. 算法流程
-
近年来, 各种并行硬件和软件层出不穷, 本文选择目前较为流行的MPI(Message Passing Interface)作为并行计算的开发环境.主从模式和对等模式是MPI的2种基本并行计算模式[13].主从模式中, 主节点负责管理和协调其他子节点;对等模式中, 各计算节点地位相同.根据多级河流矢量数据压缩算法的特点, 本文采用主从模式, 算法描述如下:由主节点对压缩任务进行划分, 并将任务分配到各子节点;各子节点负责各自的压缩任务, 并将结果返回给主节点;主节点完成压缩结果的合并与输出.
-
并行计算的任务分配有任务并行和数据并行2种模式.任务并行是将需要执行的各个任务分配到各计算节点上执行;数据并行是将需要处理的数据分配给各计算节点, 再由各节点对分配到的数据进行相似的操作.本文提出的压缩算法中, 由于压缩过程相对简单且联系较为紧密, 不易进行任务分解;而多级河流矢量数据以曲线集合的形式进行存储, 便于数据分割.因此, 本文采用数据并行的方法进行任务的分配, 即将待压缩的曲线集合分配到各个计算节点上分别进行压缩.
-
根据任务分配方式, 各计算节点执行各自的压缩任务后, 需要将结果返回给主节点, 并由主节点完成结果的合并与输出, 这需要通过节点间的通信来实现.
MPI提供了集合通信和点对点通信2种方式[14].由于集合通信要求每次传输的数据量相同, 而各计算节点分配到的曲线段数据量并不相同.因此, 本文采用点对点的通信方式, 即在各子节点完成压缩任务后, 通过调用MPI_Send函数将各曲线的压缩结果返回给主节点, 主节点通过调用MPI_Recv函数接收数据;完成所有子节点的数据接收工作后, 主节点将各子节点的压缩结果进行合并, 重新形成曲线集合, 完成压缩任务.
-
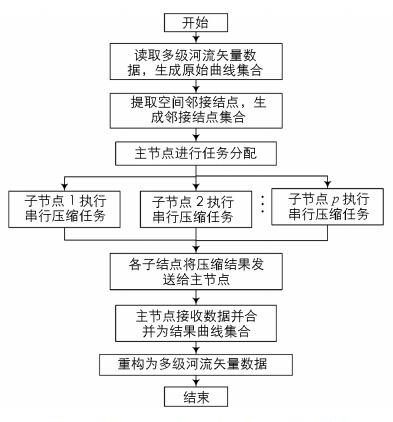
在确定并行计算模式、任务分配和通信方式的基础上, 本文设计了多级河流线状矢量数据的并行压缩算法(图 3), 具体流程如下:① 读取多级河流矢量数据和空间邻接结点数据, 由主节点通过任务分配方式将数据分发给各子计算节点. ② 各子节点执行多级河流矢量数据串行压缩算法, 完成各自的压缩任务. ③ 各子节点通过通信方式将压缩结果返回给主节点, 同时由主节点进行数据接收和合并, 在所有曲线完成压缩后生成结果曲线集合Lres{L0, L1, …, Ln-1}. ④ 由主节点将结果曲线集合重构为多级河流矢量数据, 完成压缩.
2.1. 并行计算模式
2.2. 任务分配
2.3. 通信方式
2.4. 并行算法流程
-
为了评估多级河流矢量数据并行压缩算法的有效性, 本文设计了验证性实验.实验环境为4台微机构成的小型集群系统, 微机的配置为:Inter(R) Core(TM) i5-4460 CPU @ 3.20GHz四核, 8GB内存.编程环境为Visual Studio 2012和MPICH2 1.4.1p1, 使用C语言开发.试验数据采用三峡库区重庆段的河流1:25万矢量数据, shapefile格式, 大小为16.9 MB.空间邻接结点采用ArcGIS 10.2软件平台进行提取.设置不同阈值时分别利用Douglas-Peucker算法和本文提出的多级河流矢量数据并行压缩算法进行压缩.由于原数据河网过于密集, 本文只对长江及部分主要支流进行显示, 压缩算法有效性评估见表 1, 并行算法与串行算法运行结果见表 2.
线状矢量数据压缩的精度评定一般采用点位评估法[15], 即通过原始曲线上点与压缩后曲线的相对位移偏差大小来衡量压缩精度, 多级河流矢量数据的相对位移偏差计算方法如下:
式中:ε为相对位移偏差;Li为第i条河流曲线压缩前长度;n为河流曲线总条数;Di为第i条河流曲线压缩后的平均位移偏差, 计算方法如下:
式中:di表示压缩前河流曲线中第i个坐标点与压缩后河流曲线的距离;m为此条河流曲线压缩前的坐标点个数.
加速比是衡量串行运算和并行运算时间关系的一个指标, 其计算方法为:
式中:v为阈值;p为节点数;S(v, p)为加速比;Ts(v), Tp(v, p)分别为串行运算时间和并行运算时间.
-
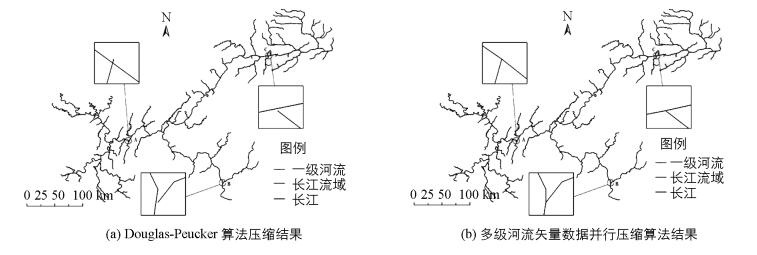
1) 数据压缩有效性分析.利用Douglas-Peucker算法进行压缩时, 压缩后的多级河流矢量数据出现拓扑关系丢失现象(图 4(a)), 而本文提出的多级河流矢量数据并行压缩算法不会出现拓扑关系丢失(图 4(b)).同时, 由表 1可知, 在阈值为100 m、500 m、1 000 m时, Douglas-Peucker算法压缩结果的相对位移偏差分别为0.000 35, 0.003 87, 0.014 88, 空间邻接结点保持率分别为74.21%, 65.29%, 57.16%, 压缩率分别为29.68%, 65.14%, 75.71%;而多级河流矢量数据并行压缩算法压缩结果的相对位移偏差分别为0.000 29, 0.003 17, 0.012 43, 空间邻接结点保持率均为100%, 压缩率分别为29.54%, 64.95%, 75.52%.结果表明, 顾及空间邻接关系的多级河流矢量数据并行压缩算法可完整地保持空间邻接关系, 且由于保留了空间邻接结点, 与Douglas-Peucker算法相比压缩精度有所提高, 但同时压缩率有所降低, 这是因为消耗了存储空间用于储存空间邻接结点.
2) 串行与并行算法结果比较分析.由表 2可知, 在阈值为100 m、500 m、1 000 m时, 串行算法的运行时间分别为7.802 s, 6.313 s, 5.79 s;计算节点p=2时并行算法的运行时间分别为4.843 s, 3.484 s, 3.034 s, 加速比分别为1.611, 1.812, 1.908;p=4时的运行时间分别为2.948, 2.533, 2.356, 加速比分别为2.647, 2.492, 2.458.说明并行算法比串行算法的运行效率更高, 且计算节点为4时的运行时间要少于计算节点为2时的运行时间. p=2和p=4时平均加速比分别为1.779和2.507, 并不能达到理想的状态(即S=p).这是因为并行计算并不是简单地将计算任务平均分配给各子节点执行, 在实际计算中, 并行算法会在节点间通信上比串行算法花费额外的时间, 而且会受到节点间网络环境的影响, 甚至可能会遇到信息阻塞、程序死锁等问题.
3.1. 实验验证设计与结果
3.2. 分析与结论
-
1) 顾及空间邻接关系的多级河流线状矢量数据并行压缩算法能有效保持空间邻接关系.利用该算法进行压缩时, 多级河流矢量数据的平均相对位移偏差为0.005 22, 与Douglas-Peucker算法相比降低了16.48%;空间邻接结点保持率达到100%, 比Douglas-Peucker算法平均提高了35.15%, 在有效地压缩多级河流矢量数据的同时, 保持了其空间邻接关系.
2) 并行压缩算法能有效提高压缩效率.与串行算法比较, 在不同阈值条件下, 并行算法运行时间明显缩短, 计算节点为4时平均加速比达到2.507, 提高了多级河流矢量数据的压缩效率.
3) 如何保持压缩时多级河流的其他空间关系, 如保证多级河流在简化后不出现错误交叉的现象, 尚需进行进一步的研究.