





-
开放科学(资源服务)标识码(OSID):

-
随着智能终端的普及,数据驱动的机器学习模型在智能感知与决策支持等场景中发挥着重要作用。然而,数据通常分散存储在用户或设备侧,且包含敏感信息,直接共享这些数据易引发隐私泄露风险,形成数据孤岛问题,制约智能模型的发展[1]。联邦学习(Federated Learning,FL)[2-3]通过在本地训练模型、仅上传参数,实现了在不集中原始数据前提下的协同建模,在一定程度上缓解了数据孤岛与隐私风险。然而,传统联邦学习依赖多轮模型参数交互,深度模型参数规模庞大,带来显著通信开销,限制了其在资源受限设备上的部署。同时,上传的模型参数仍可能泄露敏感信息[4-5],攻击者可通过成员推理攻击[6-7]或模型反演攻击[8]恢复训练数据特征,对隐私构成威胁[9]。
为增强隐私保护,已有研究引入多方安全计算、同态加密、可信执行环境及差分隐私(Differential Privacy,DP)[10]等技术。其中,DP因具备严格的理论隐私保证和较高效率而被广泛采用。但现有方法多在梯度或参数层面注入噪声[11-13],在高维空间中往往需要较大噪声强度,导致模型性能下降。
为解决分布式学习场景中存在的通信低效和隐私泄露问题,引入数据集蒸馏[14]的思想,提出基于合成数据的联邦学习方案。在该方案中,通过数据集蒸馏技术生成小规模的合成数据,并在联邦学习中替代高维模型参数进行服务器与用户之间的交互,可以显著降低联邦学习的通信开销。此外,不同于传统方法仅对模型参数进行一次性聚合,合成数据可在服务器端被重复用于多轮次的模型训练与更新,使得全局模型能够充分收敛并得到更优的性能。这一特性也为构建一次性交互联邦学习策略提供了可能,即每个用户仅需一次性上传其本地生成的合成数据即可实现协同训练。
然而,合成数据仍有可能泄露原始数据的分布信息,难以抵御成员推理攻击。为保障合成数据隐私安全,在基于分布匹配(Distribution Matching,DM)[15]数据集蒸馏框架中引入差分隐私技术,并设计了一种新的自适应噪声注入策略,使合成数据在满足本地差分隐私要求的同时,在用于模型训练时仍能得到较高准确度。主要贡献如下:1) 提出了一种基于数据集蒸馏的一次性交互联邦学习框架,用户仅需一次性上传小规模的合成数据,服务器端即可基于该数据进行多轮次模型训练,以得到高准确度的全局模型。2) 不同于传统联邦学习依赖高维模型权重或梯度的多轮次交互进行模型更新,该方法在整个训练过程中仅涉及一次小规模的低维合成数据交互,从而有效避免了模型参数传输带来的高通信开销。3) 将差分隐私处理嵌入合成数据的生成阶段,有效降低全局敏感度,并提出自适应噪声注入策略,在满足本地差分隐私保护的同时保障较高的模型准确度。4) 从理论上证明了所提方案能满足本地差分隐私要求,并在满足Non-IID分布的基准数据集上进行了性能对比实验。实验结果表明,该方法在模型准确度和通信效率方面均优于其他隐私保护联邦学习方法。
HTML
-
联邦学习可以在本地原始数据不出域的情况下,仅与服务器交换模型参数信息,实现分布式协同训练,已被广泛应用于隐私敏感的分布式学习场景。目前,学术界已提出了大量关于联邦学习的研究成果。其中,FedAvg算法[16]是最经典的一种联邦架构,其通过增加本地训练轮次来减少通信频率,在一定程度上提升了通信效率。然而,该类方法仍依赖多轮模型参数交互,在大规模系统或资源受限环境中通信开销依然较高。
为进一步降低通信成本,研究者提出了一次性交互联邦学习范式,通常结合数据集蒸馏技术,使用户端仅需上传一次小规模合成数据即可完成全局模型训练或模型更新过程的重构。例如,FedSynth[17]利用合成数据进行交互,随后基于合成数据恢复用户端模型更新并进行聚合;Zhou等[18]提出了DOSFL方案,该方案基于本地真实数据集蒸馏得到合成数据,合成数据随后在服务器端聚合,并用于更新全局模型;Song等[19]设计了FedD3方案,该方案通过在用户端采用Coreset-based或KIP-based的数据集蒸馏方法,将原始数据压缩为少量合成样本,并一次性上传给服务器,实现一次性交互联邦学习。尽管现有的一次性交互联邦学习在通信方面保持高效,但其对用户端模型的初始化一致性较为敏感,且蒸馏计算开销相对较高。
-
在联邦学习的训练过程中,无论通过模型参数还是合成数据进行服务器与用户端之间的交互,都可能遭受诚实但好奇(honest-but-curious)服务器或恶意窃听者发起的成员推理攻击[6-7]和模型反演攻击[8]。为防御这些恶意攻击,现有研究引入了安全多方计算、同态加密和差分隐私等防御技术。其中,最具代表性的工作包括Bonawitz等[20]提出的安全聚合机制,以及文献[21-22]中设计的基于同态加密的联邦学习方案,但这些方法通常存在较高的通信与计算开销。
相比之下,差分隐私因其严格的隐私理论保证和较低的计算复杂度,已被广泛应用于联邦学习的隐私保护。文献[23-24]提出在模型参数更新阶段注入DP噪声,以抵御隐私泄露,但该方法仍面临较高的通信开销,且添加的噪声会影响模型性能。为兼顾通信效率与隐私保护,近几年已有研究开始将DP引入数据集蒸馏过程,并通过合成数据交互来降低通信开销。例如,Chen等[25]在合成数据的表示层添加DP噪声;PPFL-DC则利用DP-SGD方式更新合成数据所需的梯度[26];NDPDC基于DM方法在固定裁剪阈值下对合成数据进行DP保护[27];FedDM则在合成数据梯度中引入DP噪声,并通过多轮训练保障模型的较高准确度[28]。
然而,上述方案通常采用固定差分噪声,或者对高维模型权重添加噪声,这在一定程度上降低了合成数据的可用性,并导致模型训练准确度下降。
1.1. 联邦学习方案
1.2. 隐私保护策略
-
基于分布匹配的数据集蒸馏(DM)[15]方法的核心思想是通过对齐真实数据与合成数据在多种嵌入空间中的特征分布,以此生成能够有效替代原始数据的小规模合成数据集。在DM中,原始数据集T与待学习的合成数据S会分别经过一系列随机增强A(·,ω),并在不同的嵌入空间ψ∂(·)中进行特征提取。最小化两组特征分布之间的差异是该方案的优化目标,其优化目标的表示如下:
xi是数据集T中的一个样本。通过在不同嵌入空间对原始数据与合成数据的分布进行对齐,DM方法能够逼近高维的特征分布,以提升合成数据的泛化能力,且在合成数据生成过程中无需进行传统数据集蒸馏(如DD[14])的双层优化,因此该方法是一种高效的数据集蒸馏方法。
-
定义1(差分隐私[10]) 设D为数据集,机制M:D→R,其中D为定义域、R为值域。若对于任意邻接数据集d,d′∈D(即二者有且仅有一个样本不同)以及任意输出集合S⊆R,机制M都满足
则称机制M满足(ε,δ)-差分隐私,其中ε>0为隐私预算。ε越小,表示隐私保护越强。
敏感度与噪声机制:为了近似实现差分隐私,通常采用向查询函数f的输出注入差分噪声,以保证差分隐私保护。函数f的l2敏感度定义如下,
在该方法中,采用高斯噪声机制M来实现差分隐私保护,其添加噪声的形式可表示为
其中,N(0,σ2I)表示均值为0且协方差矩阵为σ2I的正态分布,I为单位矩阵。
此外,差分隐私机制还具有顺序组合和并行组合两种重要性质,具体表述如下。
定理1(顺序组合[29]) 假设机制M1,M2,…,Mm分别满足ε1,ε2,…,εm-差分隐私,则由这些机制组成的联合机制M(d)=(M1(d),M2(d),…,Mm(d))满足
$ \sum\limits_i^m \varepsilon_i-$ 差分隐私。定理2(并行组合[29]) 假设机制M1,M2,…,Mm分别作用于互不重叠的数据集D1,D2,…,Dm,且分别满足(ε1,δ1)-差分隐私,(ε2,δ2)-差分隐私,…,(εm,δm)-差分隐私,则由这些机制组成的联合机制M(d)=(M1(d),M2(d),…,Mm(d))满足
$ \left( {\mathop {\max }\limits_i {\varepsilon _i},\mathop {\max }\limits_i {\delta _i}} \right) - $ 差分隐私。
2.1. 数据集蒸馏技术(DM)
2.2. 差分隐私技术
-
本节首先介绍基于数据集蒸馏的一次性交互联邦学习的主要流程,整体系统模型如图 1所示。随后,对方案中ANIS策略的具体实现进行详细说明。
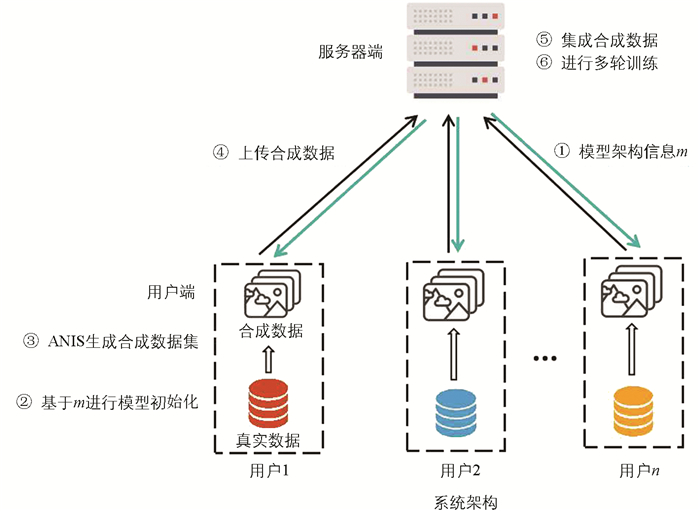
该方法通过在用户端生成并上传少量高质量的合成数据,替代传统联邦学习中多轮模型参数或梯度交互,从而显著降低通信开销并缓解隐私泄露风险。该方案包含2个核心组件:1) 高效的一次性交互联邦训练架构;2) 用于合成数据生成的自适应噪声注入策略。
-
在用户端阶段,服务器首先向所有参与用户下发学习任务的模型架构信息m,如算法1的步骤1所示。随后,每个用户端i在本地执行R轮合成数据训练过程,如算法1的步骤2-9所示。具体而言,在每一轮本地训练中,用户端基于模型架构m对模型参数进行随机初始化,以避免模型初始化对合成数据生成产生偏置。在算法1步骤5中,从用户i的真实数据集Di中按类别随机采样小批量数据Bi={Bi1,Bi2,…,Bic}。为了在保证合成数据有效性的同时防止隐私泄露,在用户端合成数据更新过程中引入自适应噪声注入策略,对合成数据Si的更新过程进行差分隐私保护,如算法1步骤6所示。该策略基于差分隐私技术,在合成数据优化过程中动态注入差分噪声,从而限制单个样本对合成结果的影响,增强隐私安全性,具体实现过程见算法2。用户端在合成数据训练过程中对不同类别数据分别进行生成训练,每个类别的数据合成都经过R轮迭代。最后,将不同类别的合成数据组合在一起,每个用户端得到其最终的合成数据集Si={Si1,Si2,…,Sic},见算法1步骤8。
-
完成本地合成数据生成后,每个用户端仅需一次性将其合成数据Si上传至服务器,见算法1步骤10。在算法1步骤11中,服务器对来自所有用户端的合成数据进行聚合,形成统一的合成数据集S={S1,S2,…,SN}。随后,服务器端进行全局模型训练,如算法1步骤12-16所示。全局模型基于架构信息m进行随机初始化,并使用聚合后的合成数据集S进行集中训练。服务器执行最多G轮模型更新,或当模型满足收敛条件时提前终止训练,最终得到全局模型参数。
算法1:基于数据集蒸馏的一次性交互联邦学习 输入:N={1,2,…,N}为本地用户集合,R为本地训练轮次,G为全局模型训练轮次,Di为用户i的真实数据集,Si为用户i的合成数据,σ为噪声乘子,ηs为合成数据更新学习率,Cir为用户i在第r轮的裁剪阈值,m为学习任务的模型架构信息,Bic为用户i中类别为c的小批量数据。 输出:全局模型θ 1. 服务器向各用户下发m 2. for i=1,2,…,N do: 3. for each round r=1,2,…,R do: 4. 基于m随机生成模型参数θir 5. 从Di中随机选择小批量数据Bi={Bi1,Bi2,…,Bic} 6. 基于Bic和方案更新Sic 7. end for 8. 合并更新后的Sic,得到Si={Si1,Si2,…,Sic} 9. end for 10. 将合成数据Si上传至服务器 11. 服务器端合并用户合成数据,得到数据集S={S1,S2,…,SN} 12. for j=1,2,…,G do: 13. 基于m随机生成全局模型参数θ 14. 基于S进行训练,并更新θ 15. if模型收敛:break 16. end if 17. end for -
在合成数据生成过程中,如何兼顾数据的隐私保护与可用性至关重要。为此,提出一种用于合成数据生成的自适应噪声注入策略(ANIS)。该策略利用差分隐私机制防御来自诚实但好奇服务器的成员推理攻击,并通过自适应噪声调节在隐私保护与数据可用性之间实现有效平衡。
ANIS的实现过程如算法2所示。在每轮合成数据更新中,用户首先基于当前模型对合成数据进行前向计算,提取特征表示并计算任务损失(步骤2-3),进而获得用于更新合成数据的梯度。为限制单样本对更新的影响,ANIS在步骤4中引入梯度裁剪机制,并根据前若干轮梯度的l2-范数平均值自适应地设定下一轮裁剪阈值,使阈值随训练过程平滑收敛。完成裁剪后,用户对小批量梯度进行聚合,并依据裁剪阈值与噪声乘子注入高斯噪声,实现差分隐私保护。其中,裁剪阈值为梯度范数设置的最大允许值,噪声乘子σ为控制加入噪声强度的参数;随后利用加噪梯度更新合成数据。最终,ANIS输出经隐私保护的合成数据及对应裁剪参数,用于后续一次性交互联邦学习阶段。
算法2:自适应噪声注入策略ANIS 输入:Bic,Sic,当前轮数r,θir,ηs,σ 输出:更新后合成数据Sic和裁剪阈值Cir+1 初始化:用户i前几轮的合成数据更新梯度gir-1,gir-2,Cir,σ 1. for each sample (xk,yk)∈Bic: 2. ψ∂=θir. embed //构建嵌入函数 3. 计算当前样本的任务损失 $ \mathscr{L}$ $ \mathscr{L}=\left\|\psi_{\vartheta}\left(A\left(x_k, \omega\right)\right)-\frac{1}{\left|S_i^c\right|} \sum\limits_{s \in S_i^c} \psi_{\vartheta}(A(s, \omega))\right\|^2$ 4. 裁剪合成数据更新梯度: $ g_i^{r, k}=\nabla \mathscr{L} / \max \left(1, \frac{\|\nabla \mathscr{L}\|_2}{C_i^r}\right)$ 5. end for 6. 计算平均梯度 $ g_i^r=\frac{1}{\left|B_i^c\right|} \sum\limits_{k=1}^{\left|B_i^c\right|} g_i^{r, k}$ 7. 对梯度注入差分噪声: $ \bar{g}_i^r=g_i^r+N\left(0, \sigma^2 C_i^{r 2} \boldsymbol{I}\right)$ 8. 更新合成数据 $ S_i^c=S_i^c-\eta_s \bar{g}_i^r$ 9. 更新裁剪阈值Cir+1=(‖gir‖2+‖gir-1‖2+‖gir-2‖2)/3 10. return Sic和Cir+1
3.1. 高效的一次性交互联邦训练架构
3.1.1. 用户端:隐私保护的合成数据生成
3.1.2. 服务器:一次性交互与全局模型训练
3.2. 自适应噪声注入策略(Adaptive Noise Injection Strategy,ANIS)
-
本节基于Rényi差分隐私(Rényi Differential Privacy,RDP)框架,对所提出的一次性交互联邦学习方案进行隐私性分析。
在该一次性交互联邦学习框架中,用户真实数据始终保留在本地,服务器仅能访问经隐私保护的合成数据。因此,系统的隐私风险主要来源于合成数据生成过程。
1) 单轮合成数据更新的RDP保证
在第r轮合成数据更新中,用户以采样率
$ q=\frac{\left|B_i\right|}{\left|D_i\right|}$ 从本地数据集中抽取小批量数据Bi,并对逐样本梯度进行l2-范数裁剪,裁剪阈值为Cir。随后,向裁剪并聚合后的梯度中注入均值为0、标准差为σCir的高斯噪声。根据Rényi差分隐私理论,对于任意Rényi阶数α>1,单轮合成数据更新机制满足(α,εRDP(r)(α))-RDP,其中,2) 多轮合成数据生成的RDP组合
在合成数据生成阶段,用户共执行R轮更新。由于RDP具有顺序组合性质,用户i在完成全部合成数据生成后满足(α,εRDP(i)(α))-RDP。其中,
$ \varepsilon_{\mathrm{RDP}}^{(i)}(\alpha)=\sum\limits_{r=1}^R \varepsilon_{\mathrm{RDP}}^{(r)}(\alpha)$ 当各轮训练采用相同的采样率与噪声乘子时,上式可简化为εRDP(i)(α)=R·εRDP(single)(α)。3) 一次性交互联邦学习的隐私特性
与传统联邦学习在每一轮训练中都上传梯度或模型参数不同,该方法采用一次性通信策略,即每个用户仅在完成合成数据生成后向服务器上传一次合成数据。随后,服务器端的全局模型训练仅依赖于满足RDP约束的合成数据。根据差分隐私的后处理不变性,服务器端训练过程不会引入额外的隐私泄露。因此,整个一次性交互联邦学习框架的隐私损失不会随着服务器端全局训练轮数的增加而累积。
4) 从RDP到(ε,δ)-差分隐私的转换
根据RDP到(ε,δ)-差分隐私的标准转换定理,对于任意δ>0,机制Mi同时满足(εi,δ)-差分隐私,其中,
5) 隐私保证
由于不同用户的数据集是相互独立的,且各用户的合成数据均在本地独立生成,方案整体满足差分隐私的并行组合性质。因此,所提出的一次性交互联邦学习方案满足(ε,δ)-差分隐私,其中(ε,δ)=
$ \max\limits_i\left(\varepsilon_i, \delta\right)$ 。
-
实验数据集:MNIST[30]、Fashion-MNIST[31]和CIFAR-10[32]。其中,MNIST和Fashion-MNIST各包含60 000张训练图像和10 000张测试图像,图像大小为28×28像素,共10类;CIFAR-10包含50 000张训练图像和10 000张测试图像,图像大小为32×32像素,具有3个颜色通道,同样为10类。实验主要在高度标签偏斜的Non-IID场景下进行评估,即每个用户仅拥有单一类别的训练样本。
训练模型:每类合成数据的数量为10,真实图像的批大小设为256,合成图像更新的学习率设置为ηs=1.0,每个客户端执行10 000次迭代。对于服务器端,全局模型采用SGD优化器进行训练,模型的学习率设置为ηθ=0.01。其余对比方案均按照其对应文献中的参数设置进行实验。此外,在基于差分隐私的策略中设置噪声乘子σ=1。
-
在本节中,在3个高度偏斜的Non-IID数据集上进行了实验评估。将所提出的联邦学习(FL)架构与传统FL方法FedAvg以及基于数据集蒸馏的一次性交互FL方法(如DOSFL、FedD3)进行对比评估,对比结果如表 1所示。结果表明,所提出的方案在Non-IID数据集上的模型准确度均高于其他联邦学习方案。
为验证该方案在差分隐私保护下的模型准确度,与常见的差分隐私联邦学习DPFL、基于DC的差分隐私联邦学习PPFL-DC(优化更新策略:服务器端的合成数据先聚合再全局更新)、基于DM的差分隐私学习NDPDC以及基于DM的差分隐私联邦学习FedDM 4种代表性方案进行对比。根据表 2结果可知,所提出的方案在3个Non-IID数据集上均取得了高于其他方法的模型准确度。其中,该方案的模型准确度显著高于DPFL和PPFL-DC方案,但仅略高于NDPDC和FedDM方案。其主要原因在于,NDPDC为集中式训练方式,在一定程度上避免了Non-IID导致的偏置;而FedDM方案对基于批量数据训练得到的模型梯度进行裁剪,从严格意义上讲并不能满足标准差分隐私保护。本方案模型准确度略高,得益于自适应噪声注入策略,有效降低了差分噪声对模型准确度的负面影响。
-
为验证ANIS策略的有效性,针对不同梯度裁剪阈值及裁剪策略下的模型准确度进行对比分析。图 2a中,对比了一次性交互联邦学习在不同裁剪阈值下的模型准确度。从实验结果可以看出,当裁剪阈值等于1时,得到的模型准确度相较于其他裁剪阈值更优,并接近于不添加差分噪声的方案。因此,选择合适的梯度裁剪阈值对模型准确度至关重要。
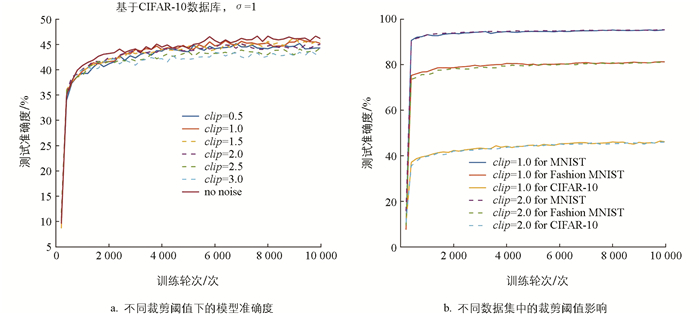
当裁剪阈值过大,所注入的差分噪声幅度增加,会影响模型准确度;若裁剪阈值过小,则梯度偏离原始值过大,同样会导致模型准确度下降。根据图 2b在不同数据集上得到的实验结果可以看出,不同裁剪阈值可能得到接近的模型准确度,进一步表明裁剪阈值与模型准确度之间存在显著关系。
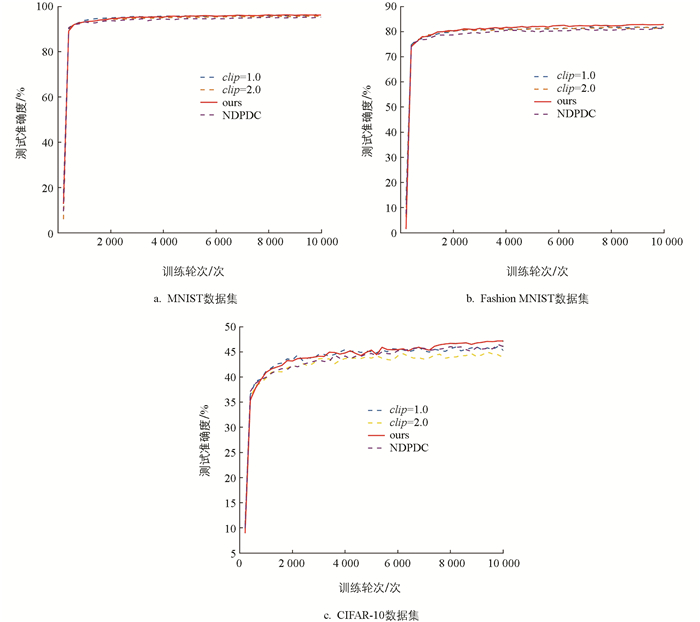
此外,对不同阈值裁剪策略下的模型准确度进行了对比,包括对合成数据更新梯度添加固定裁剪阈值(即clip=1.0和clip=2.0)的方法、NDPDC中对合成数据添加固定裁剪阈值的方法以及所提出的自适应噪声注入策略ANIS。对比结果如图 3所示,ANIS在多个数据集上的模型准确度均优于其他固定阈值策略。由此表明所提出的自适应策略能够有效提升模型准确度。
-
对联邦学习架构下不同方案的通信开销进行了对比分析,包括上传通信开销与下载通信开销。其中,FedAvg、DPFL为传统联邦学习架构,PPFL-DC、FedDM、DOSFL、FedD3为基于数据集蒸馏的联邦学习方法,而NDPDC为集中式学习,因此不参与通信开销对比。为更直观地进行对比,设模型参数大小为W,合成数据大小为H,模型结构信息大小为G,DOSFL的本地迭代次数为K,FedAvg、DPFL、PPFL-DC、FedDM的全局训练轮数为T,其中W≫H≫G。
在上述设定下,FedAvg、DPFL的通信开销为2WT,PPFL-DC、FedDM的通信开销为2HT,DOSFL的通信开销为KH+W,FedD3的通信开销为H+W,所提出方案的通信开销为G+H。可以看出,所提出的一次性交互联邦学习方案的通信开销明显低于其他方案。
综上所述,所提出的一次性交互联邦学习方案在模型精度与通信开销方面均具有一定优势,是在Non-IID数据环境下表现较好的联邦学习方案。
5.1. 实验设置
5.2. 模型性能
5.2.1. 模型准确度对比
5.2.2. ANIS的有效性验证
5.2.3. 通信开销分析
-
本文针对数据分散场景下隐私保护与通信效率难以兼顾的问题,提出了一种结合数据集蒸馏与差分隐私的一次性交互联邦学习方法。不同于传统多轮参数交互方式,该方法以低维合成数据作为唯一交互载体,用户仅需一次上传经差分隐私保护的合成数据,服务器即可集中训练与复用,从而降低通信开销并减少模型参数泄露风险。在隐私方面,将差分隐私机制引入合成数据生成阶段,通过自适应噪声控制实现隐私预算与模型性能之间的平衡,并在理论上具备抵御成员推理攻击的能力。实验结果表明,在Non-IID数据环境下,该方法在准确率和通信效率方面均表现出较好的性能。总体而言,该工作为高隐私、低资源场景下的分布式建模提供了一种可行的技术路径。
 DownLoad:
DownLoad: