





-
无线传感器网络(Wireless Sensor Networks,WSN)是由传感器节点组成的分布式传感网络[1-2],在安全监控、事件跟踪和目标检测等与监控相关的应用中起着至关重要的作用[3].由于节点电池很难更换或者充电,使得节能成为无线传感网络的重要研究问题之一[4-5].虚拟骨干网(Virtual Backbone Network,VBN)将网络划分为骨干节点集和普通节点集,骨干节点作为中继节点以完成通信过程中消息传递的任务,非骨干节点平时可以处于休眠状态,负责发送本节点数据监测[6-7]. VBN通过将路由任务限制在骨干节点上来提高网络的路由效率,降低网络运行过程中的能耗.
连通支配集(Connected Dominating Set,CDS)是构建VBN的主要方法,较小的VBN可以保证较高的通信效率,构造最小连通支配集是一个非确定性多项式(Non-deterministic Polynomial,NP)完全问题[8].遗传算法(Genetic Algorithm,GA)是一种基于自然选择和遗传学的启发式搜索算法[9],GA从染色体的初始群体开始计算每个染色体的适合度因子,选择具有较高适合度的染色体进行育种以产生后代.新产生的后代中只有具有更高适合度评分的染色体才能存活,并且会收敛到最优解[10].染色体由许多基因组成,染色体中的每个基因都被映射到网络中的一个节点,算法中的染色体表示网络中可能存在的CDS.
构造最小连通支配集(Minimum Connected Dominating Set,MCDS)是WSN节能需要解决的关键问题.针对WSN中的MCDS问题,文献[11]提出了一种最小连通支配集的分布式贪婪近似方法,用于构造节点随机分布和均匀分布的低成本、小尺寸的CDS.文献[12]提出了一种用于解决最大独立集的改进协作覆盖算法,该算法将控制点的选择从两跳邻居扩展到三跳邻居,在完全覆盖的条件下,覆盖效率得到了提高.文献[13-14]提出了两种基于群体的最小权重连通支配集(Minimum weight connected dominating set,MWCDS)优化算法,它结合贪婪式启发算法和遗传搜索来解决MWCDS问题,迭代贪婪算法通过部分破坏和贪婪地重构单个解来细化种群,但是这些优化算法之间存在一个权衡,交叉会使解决方案的质量降低.
在研究了现有MCDS算法的基础上,为了进一步延长网络寿命,本文提出了一种基于启发式遗传算法的均衡节能虚拟骨干网构建(Balanced Energy Efficient Virtual Backbone Construction,BEE-VBC)算法.该算法通过考虑节点的最大能量、邻居覆盖范围、可靠传输、节点处理能力和数据速率等多个因素设计的适应度函数来选择一组最大适应度节点,为了确保支配节点间的连通性,使用启发式遗传算法确定最优的CDS,将得到的最优CDS作为VBN向基站进行数据传输和转发,以此使其具有更好的覆盖率和更少的能量消耗,进而提高网络的寿命,以显示本文BEE-VBC算法具有更好的网络生存期和数据包传输率.
HTML
-
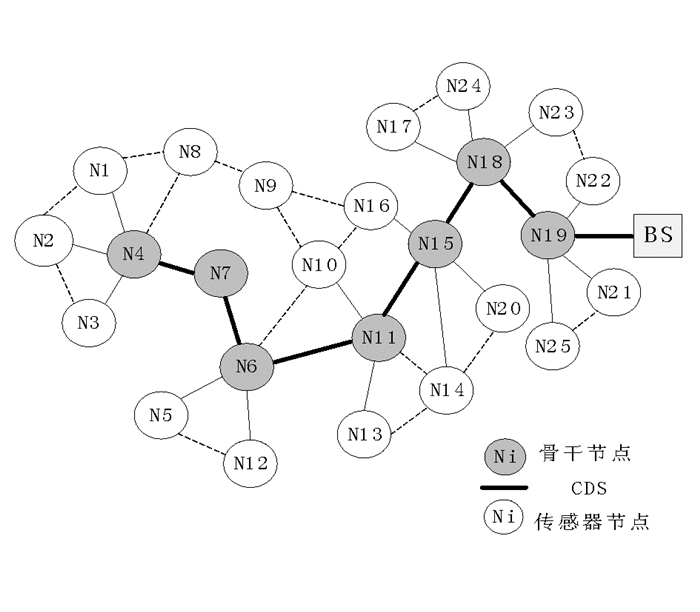
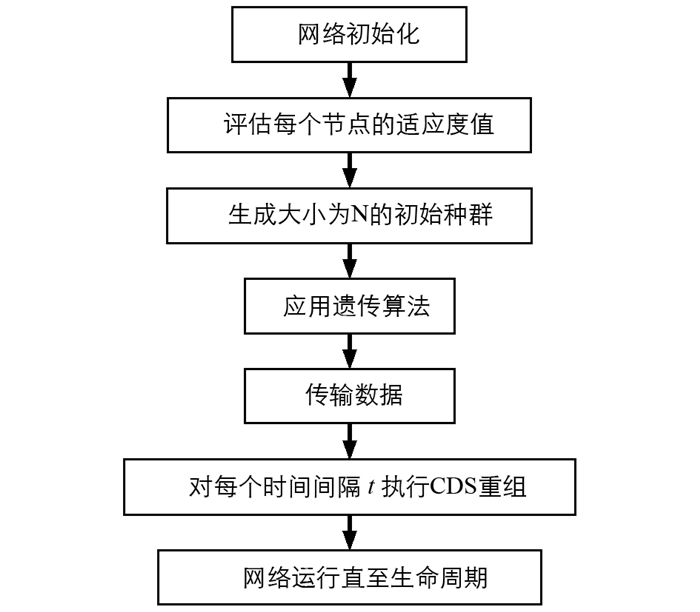
本文BEE-VBC算法通过使用适应度函数及其在世代中进化选择的最佳节点集来产生节能的CDS,通过节能的CDS进行数据传输以提高网络寿命. 图 1显示了连通支配集(CDS)的网络模型,BEE-VBC算法分6个步骤进行,具体流程如图 2所示.
-
无线传感网络由一个基站(Base station,BS)和n个随机部署在现场的传感器节点组成.网络建立阶段由基站公告信息(BS Announcement Message,BSA-msg)和传感器加入信息(Sensor Nodes Joining Message,SNJ-msg)组成. BSA_msg由发送者ID、序列号(Sequence Number,Seq_No)、基站位置和访问节点列表(Visit Node list,VisNode_List)组成.
为了保证BS与传感器设备之间的通信,BS以固定的时间间隔执行BS_Timer. BS向网络中所有传感器节点广播带有其ID和序列号的BSA_msg. BS的单跳邻居接收BSA_msg,并通过检查列表中的Seq_No来检查分组的新鲜度,只有最新的消息才会被考虑,然后节点检查VisNode_List来验证路由循环.随后,节点通过在Sender_ID字段中插入ID,在Seq_No字段中插入其广播ID来更新列表,它还在VisNode_List中添加自己的路由信息.然后,节点将重新广播BSA_msg,直到网络中的所有节点接收到该消息,每个节点接收到消息后,存储BS的位置和ID.传感器节点join_timer将通过由BSA_msg创建的路由将SJ_msg发送到BS.与传感器节点转发的BSA_msg不同,该消息是单播消息,包括确定适应度函数所需的参数.
-
构造CDS可以分为4个部分:适应度因子测定、人口初始化、选择过程和遗传操作.
-
构建合适CDS的第一步是为网络中的所有节点确定适应度因子,适合度系数由公式(1)给出.
式(1)、式(2)中:节点的最大可用能量ξME定义为初始能量和消耗能量之差,最大带宽μ是指节点的最大可能数据传输速率,Np为数据包数量,psize为数据包大小,t为时间段.可靠性R为成功传输次数与尝试传输次数的比率,节点的处理能力CNH可以计算为邻居的数量与网络规模的比值.
平均能量需求ξreq取决于分组的大小以及发送器和接收器之间的距离,TxE(m,d)为传输能量,ETxsp为单包传输能量.数据和控制消息的传输减少了节点的能量,平均节点能量定义为
式(4)、式(5)中:w1和w2为相应的权重,avg为所有时间间隔的平均减少能量,θ为所有时间间隔之间的能量偏差平均值,ERi为时隙ti的能量消耗.
业务偏差φt使用标准偏差方法计算, Ti为数据包数(传入和传出).
-
第一代人口的创建称为人口初始化,每条染色体都由一组显性基因构成,这些显性基因可以形成CDS.初始种群由所有可能的CDS集合形成,初始种群中的染色体数等于网络中的节点数N,即种群的规模为N.为了探索遗传多样性,所有染色体都随机选择显性基因.本文初始种群是以这样一种方式生成的,即所有节点都至少有一次机会成为控制者,通过形成初始解集来实现,网络中每个节点在消除冗余的情况下是每个解决方案中的CDS节点,对每个单独的解决方案,依据节点分布情况和相邻节点连通性来估计每个染色体中显性基因的数量.
设计的解决方案如下:首先将解决方案的数量等于网络中的节点数量;对于i的所有值,用第i个基因的位值“1”(支配节点)初始化其第i个解;邻居节点集基因设置为“0”(被支配节点);确定下一个适应值较高的基因,并设置为“1”;继续赋值,直到所有基因都被赋值.因此,初始种群G1={C11,C12,C13,……,C1N}是以上述方式为所有解决方案的所有基因赋值之后创建的,确保了每个节点都有至少一次机会成为支配节点.
深度优先搜索与线性搜索共同搜索网络中的节点,形成初始解(CDS).本文算法是一个3层体系结构,传感器节点形成第1层,CDS节点形成第2层,BS形成第3层.搜索操作从根节点开始,将节点ID与CDS中的节点列表进行比较,如果节点ID存在于CDS的指针列表中,则使用指针终止搜索,否则调用线性搜索来寻找与CDS中每个节点连接的指针.
-
选择过程是通过选择高质量的亲本染色体来产生质量提高的新一代染色体.首先依据公式(8)计算每条染色体的平均适应度(Average Fitness Value,AFV),并根据AFV对所有染色进行排序,最后选择两个适应度最大的亲本(P1和P2)进行遗传操作,产生第一个高质量的新后代.
式(8)中F(gii)表示基因gii的适应度,AFV(C11)表示亲本P1的平均适应度.
-
对上面所选择的染色体进行遗传操作以产生更多标准CDS.交叉操作将当前亲本染色体上的随机k点作为一个交叉点,两个染色体的基因在该交叉点上互换,以此来产生两个更好的后代.选择随机交叉而非均匀交叉的原因是均匀交叉需要较长的时间才能到达收敛点.本文k值设定为
$\frac{n}{2}$ .杂交产生的后代会产生突变,突变会导致位“0”的基因翻转为“1”,位“1”的基因翻转为“0”.在该算法中,突变是以随机方式进行的,突变率MR为50%.
所产生的变异后代必须检查其适应度.如果支配节点可以确保它们之间的连通性并且至少有一个支配者拥有通往基站的路径,则变异有效,变异后代将被保留于下一代,否则将亲本染色体保留到下一代中.
变异的有效性可以确保染色体形成连通的支配集.从遗传算法的每次迭代中为下一代选择有效且高度拟合的n个子代,重复以上操作直至达到收敛点或最大迭代次数,最后一次迭代的最大拟合解返回优化的连通支配集.计算最后一次迭代中每个染色体的AFV,将AFV最大的一个作为最适合的染色体,选择等效的CDS作为用于数据传输的虚拟骨干网.
根据覆盖率和适应值的不同,为每个支配者节点分配所覆盖的被支配者的数量.本文算法通过在高度拟合的节点上施加更多的载荷和在较低的节点上减少负荷来平衡能量.
-
数据传输是指使用VBN从传感器节点向BS传输数据的过程.选择最佳CDS作为VBN,所有被支配节点执行感测操作,并将感测数据发送到它们各自的支配节点,并将支配节点聚集数据转发到下一个支配节点,通过这个过程数据被转发到BS.在数据和控制消息的传输过程中,节点的能量会随着时间推移而降低,感测、转发和数据收集的操作均会消耗能量.数据传输主要发生在CDS中的支配节点上,为了降低通信成本,本文算法在特定的时间间隔t0中进行CDS重构. t0为支配节点能量耗尽的平均时间,t0的影响因素主要为节点平均能量、所有时间间隔的平均能量减少量、感测转发收集数据所消耗能量的平均速度.
-
在CDS重组之前,如果任何节点耗尽能量则进行分布式局部修复.如果出现节点故障和链路故障,CDS将在没有丢失连接和数据的情况下进行维护;如果任何节点达到其能量阈值,则它将故障消息广播到其支配节点和CDS中的其他支配节点.节点故障的判定条件由公式(11)给出.
分布式维护如下方式进行:如果节点电池达到耗尽阈值而发生链路故障,则位于链路另一端的节点[例如存在边缘E(vi,vj)节点]将广播节点故障并与另一个最近邻居节点进行连接,因为它存储有邻居节点的路由列表,并使用如下概率值公式选择邻居节点.
式(12)中Tc为输入业务计数,它提供节点输入分组的数量.具有最高概率的节点将被选择为邻居节点,以此确保分布式维护就发生在本网络中.
1.1. 网络构建
1.2. 连通支配集(CDS)构造
1.2.1. 适合度因子测定
1.2.2. 人口初始化
1.2.3. 选择过程
1.2.4. 遗传操作
1.3. 数据传输
1.4. 分布式维护
-
本节在网络模拟器NS-2上进行BEE-VBC算法的仿真,节点随机分布在200 m×200 m的区域内,所有节点具有相等的初始能量(同质网络). 表 1给出了BEE-VBC算法的仿真参数.
图 3给出了本文BEE-VBC算法与分布式连通支配集构造(Distributed construction of Connected Dominating Set,DCCDS)和最小权重连通支配集(Minimum Weight Connected Dominating Set,MWCDS)的CDS节点数量.
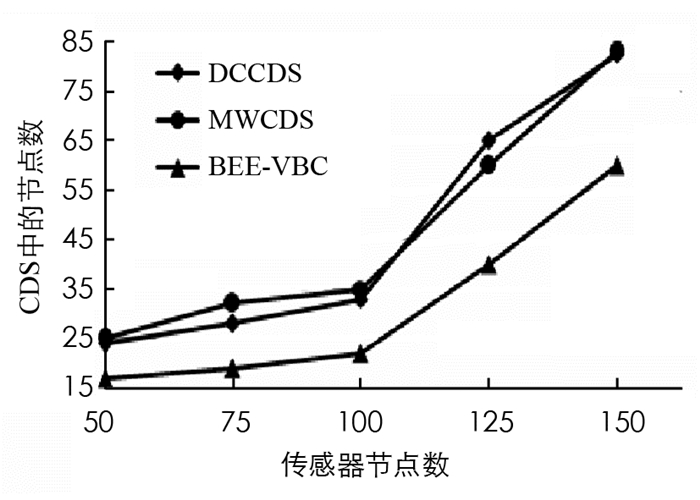
从图 3中可以看出,BEE-VBC算法所需要的CDS节点数量明显少于其他2种算法,这是因为本文BEE-VBC算法将CDS作为网络的虚拟骨干网用于数据从节点到基站的传输,另外两个算法是基于集群协议的,没有使用虚拟骨干网.
节点的能量消耗定义为初始能量和剩余能量之间的差值,网络的平均能耗按公式(13)计算.其中Ei为节点的初始能量,Eres为节点的剩余能量,N为节点数.
图 4给出了节点数不同时各算法的平均能耗.从图 4中可以看出,本文BEE-VBC算法的平均能耗明显小于其他两种算法,这是因为该算法运用适应度函数来选择优化CDS的能量因素,例如最大可用能量、平均能量减少和节点传输数据的能量需求.
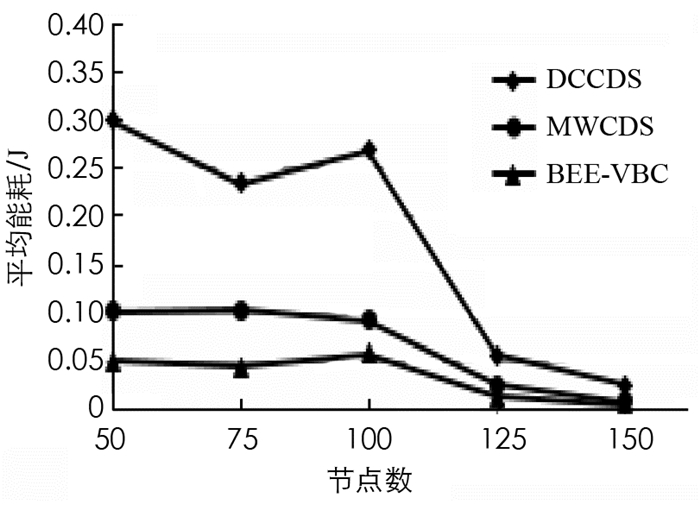
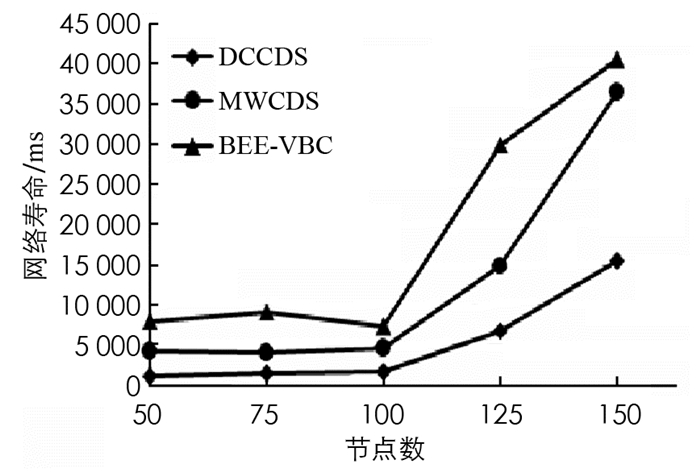
图 5给出了各算法的网络生存周期曲线,从图 5中可以看出,本文BEE-VBC算法在能量消耗方面具有更好的表现.使用该算法的WSN有更长的网络寿命,其原因是本文CDS的构造使用最大适应度节点,减少了骨干网中用于数据传输的转发节点数,从而导致冗余传输数量减少.
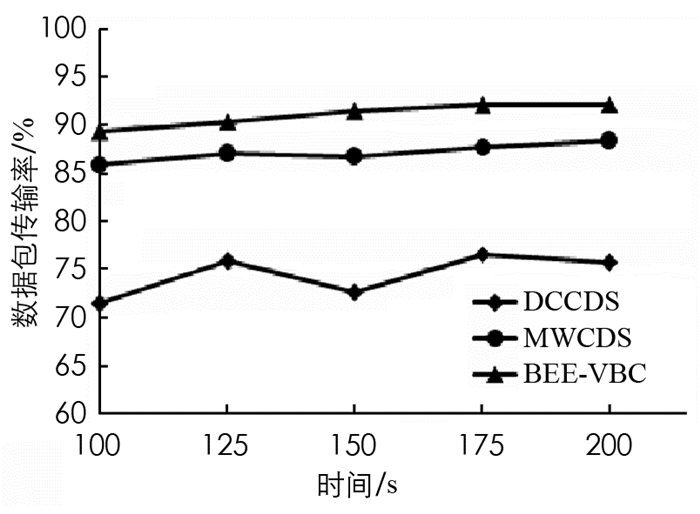
数据包传输率(Packet Delivery Ratio,PDR)定义为成功传递数据包的数量与源生成数据包数量的比值,较高的PDR意味着较小的数据包丢失. 图 6给出了不同时间段的PDR,与现有算法相比,本文BEE-VBC算法具有更好的PDR,这是因为本文算法进行了分布式维护,以确保节点数据可以传输到基站.
-
为了延长无线传感网络的网络寿命和平均能耗,本文提出了一种基于启发式遗传算法的无线传感网络节能均衡虚拟骨干网构建(Balanced Energy Efficient Virtual Backbone Construction,BEE-VBC)算法.本文的BEE-VBC算法通过使用能量、邻居覆盖、可靠性、数据速率和流量偏差等多个因素设计的适应度函数来选择最大适应度节点,并使用启发式遗传算法确定最佳的连通支配集(CDS).由于可能的连通支配集是在高度拟合的支配集帮助下经过世代进化形成的,因此最终迭代中具有最高平均适应值的CDS将是最优的,以此实现WSN网络的寿命改善.实验表明与现有算法相比,本文BEE-VBC算法在能量消耗、网络生存期和数据包传输率方面均优于现有方法.未来的工作是通过有效的数据聚合技术来减少传输次数,进一步提高网络性能.
 DownLoad:
DownLoad: