





-
随着我国经济社会和高等教育的发展,国家高度重视对贫困生的资助,但如何提升资助育人成效,对贫困生进行精准识别和对贫困度进行客观计算,成为长期以来高校贫困生认定工作中的热点和难点问题,较大程度地影响了贫困生资助的公平性和公正性[1].
随着校园卡建设向服务深化、技术融合、平台互连的方向发展,校园卡承载了金融消费和身份识别两大主要功能,被广泛应用于食堂、校园超市、图书借阅、考勤等校园业务场景中,方便了学生的日常生活;校园卡的数据也成为了获取学生生活和经济情况的有效途径. 目前利用校园卡数据进行分析和数据挖掘处理,客观评定学生的经济状况,已经有一些初步研究. 比如,饶亮[2]以校园一卡通数据为研究对象,运用改进了的Apriori方法挖掘困难学生群体一卡通中各项数据的关联规则,发现其中的相关性和潜在规律. 文献[3]基于学生基本信息、校园卡消费信息等数据,运用随机森林算法和决策树进行贫困生的判别. 柴政等人[4]通过分析学生校园一卡通的消费记录,然后利用基于神经网络的数据挖掘方法进行贫困生的识别. 陆桂明等人[5]基于学生的校园卡消费数据,结合学生的消费和生活规律,运用机器学习中XGBoost(eXtreme Gradient Boosting)模型和主成分分析法、过采样算法,对高校贫困生进行预测. 程茜宇[6]利用校园一卡通数据,以深度学习方法为技术依托,构建精准识别模型进行高校贫困生的识别. 何功炳[7]基于改进的主成分分析法对一卡通消费数据进行简约处理,再利用GBDT(Gradient Boosting Decision Tree)算法实现贫困判定模型的训练以及贫困生的预测.
这些研究主要集中在理论研究上,能运用于实际工作中的方法和系统较少. 鉴于此,本文在已有研究成果的基础上,利用校园一卡通消费数据和学生基本信息,构建贫困生认定指标体系,建立基于熵值法的客观数据模型,计算学生的贫困指数,客观地识别出贫困生,并通过Java EE技术实现相应的管理平台并运用于实际工作中.
HTML
-
熵值法通过信息熵来计算指标权重,被广泛应用于分析评价领域中,能较科学地考虑数据之间的相关关系和变异程度,从而弥补了不精准的主观赋权模式的不足. 基于熵值模型的贫困生认定系统的研究主要包含2个关键问题,一是如何利用校园卡的消费数据和学生的基本信息来科学地构建贫困生认定指标体系;二是如何确定所构建的指标体系的权重.
-
指标体系的构建是贫困生认定模型中极为重要的一步,而指标设计是否合理将对认定结果起决定性作用. 一般情况下,通过人工经验进行贫困生认定指标体系的构建. 本文采用人工经验与文献分析相结合的方式构建指标体系,根据校园卡消费数据和学生基本信息,构建出学生消费恩格尔系数、月均食堂消费水平、早餐月均消费额校均比、中餐月均消费额校均比、晚餐月均消费额校均比、食堂就餐率、助学贷款总额、勤工助学次数等8项贫困生评定的指标,具体指标及其说明如表 1所示. 其中,恩格尔系数表示学生食堂消费占个人消费支出总额的比重. 依据恩格尔定律公式[6],本文恩格尔系数可表示为
其中,食堂消费支出是指学生利用校园卡在学校各食堂进行餐饮消费的支出;校园购物消费是指学生利用校园卡在学校商贸超市等进行购物的消费支出.
-
传统的指标赋权方法如专家评判法、层次分析法等具有很大的主观性和盲目性,而熵值法是一种客观的赋权方法[8],能够克服主观赋权的不足. 其原理是利用信息熵的特性,依据指标变异性的大小来确定指标的客观权重[9]. 一般情况下,若某个指标的信息熵Ej越小,表明该指标的变异性越大,其涵盖的信息量就越多,在综合评价中起到的作用就越大,因此其权重就越大;反之,如果某个指标的信息熵Ej越大,表明该指标的变异性越小,其涵盖的信息量就越少,在综合评价中起到的作用就越小,因此其权重就越小[10]. 计算步骤为:
1) 构建矩阵. 根据设计的指标,取各指标的数据值,构建矩阵R
式(1)中,m是指标个数,n是对象个数,rij为指标i在区域j上的值[11]. 本文依据设计出的指标,将校园卡消费的原始数据经过预处理后得到贫困生指标数据,从而构建出以上矩阵.
2) 数据标准化处理. 由于各指标之间计量单位等属性差异很大,因此需要对数据采取标准化处理,用min-max标准化法对得到的指标数据进行线性变换[12],得到标准化后的数据Cij,其取值范围为[0, 1],计算公式为
式(2)、(3)中,max(rij)、min(rij)分别为某指标所在行中的最大、最小值. 式(2)适用于正向指标,式(3)适用于逆向指标.
3) 计算贡献度. 将数据矩阵R经过标准化处理后,建立新数据矩阵P,然后确定各指标的贡献度Pij[13],
$ \boldsymbol{P}_{i j}=\frac{\boldsymbol{P}_{i j}}{\sum\limits_{j=1}^{n} \boldsymbol{P}_{i j}}$ .4) 计算各指标的信息熵. 根据公式(4)计算各个指标的信息熵Ej,
式(4)中,
$K=\frac{1}{\ln n}, \boldsymbol{P}_{i j} $ 为贡献度.5) 计算指标权重. 在上述计算中,若
$ {\mathit{\boldsymbol{P}}_{ij}} = 0,\mathop {\lim }\limits_{{p_{ij}} \to 0} {\mathit{\boldsymbol{P}}_{ij}} = 0$ ,在确定各指标的信息熵值后,根据下述公式来计算指标的权重:其中,1-Ei表示第i项指标的差异系数,差异系数越大,指标就越重要.
-
贫困指数是用以衡量一个学生贫困程度的指数,用PM表示,其取值范围在0~1之间,数值越大贫困程度越高. 依据本文构建的贫困因子及其权重,学生贫困指数的计算逻辑表示为:
其中,当0≤X7≤5000时,Y7=(X7*W7)/5000;当X7>5000时,Y7=W7;当0≤X8≤3时,Y8=(X8*W8)/3;当X8>3时,Y8=W8. PM代表贫困生的贫困指数,将贫困指数排序,根据从高到低的原则可以得出学生的贫困程度.
1.1. 贫困生认定指标体系的构建
1.2. 确定指标权重
1.3. 贫困指数的计算
-
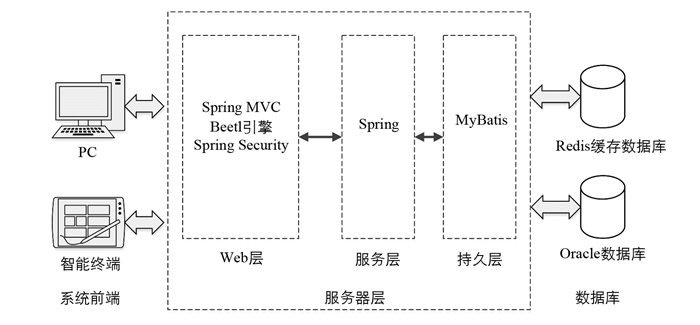
为了达到系统高扩展性、高效性和高度安全的目标,本文设计的系统由系统前端、服务器层、数据库3层结构组成,系统结构图如图 1所示. 系统前端分为智能终端和PC浏览器端;服务器层采用Web层、服务层和持久层3层结构进行设计,持久层实现与数据库的交互操作,服务层通过调用持久层的接口实现业务逻辑,Web层通过调用服务层的接口实现客户端的请求处理;数据库层采用Oracle数据库存储系统数据,同时采用Redis作为缓存服务器以存储规则数据、系统数据等热点数据[14].
-
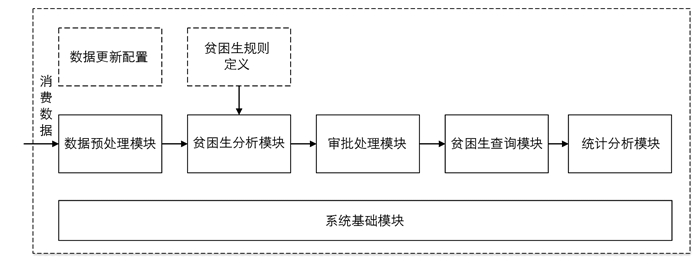
本文设计的系统通过选取贫困指标建立数学模型,对贫困生的贫困指数进行量化计算,根据定义的贫困生规则帮助学校找出真正的贫困生,辅助学校进行贫困生的精准资助. 本系统包含8个子模块:数据预处理模块、贫困生分析模块、贫困生查询模块、统计分析模块、贫困生规则定义、数据更新配置、审批处理模块和系统基础模块. 系统功能结构图如图 2所示.
1) 数据预处理模块:本文对校园卡消费数据首先进行预处理,预处理的内容主要包含:
① 对学生每月食堂消费的次数、总金额进行统计处理. 考虑到食堂消费的时段问题,定义一日三餐的时间,早餐时间段为06:00-9:59,午餐时间段为11:00-14:59,晚餐时间段为16:30-21:30;根据这3个时间段统计得到学生每月三餐消费的次数和金额. 同时,根据学生每月食堂消费的次数,并结合每月上学的天数计算学生的食堂用餐率.
② 消费异常处理. 在同一个时间段内,如果学生的消费次数>1次,则视为消费异常. 为排除该情况对模型的干扰,在消费次数>1的情况中,将单次消费金额≤阈值β(本文β取值为10)的情况认为是正常消费,将此时间段内的消费金额进行累加,得到学生该餐的消费总金额;若消费金额>阈值β,则将此时间段内的消费均值作为学生该餐的消费金额. 另外,对于消费金额为0的记录同样视为消费异常,将此类数据进行剔除处理.
③ 个体异常处理. 由于高校的管理模式,有些学生使用校园卡的次数较少,本文对每学期校园卡消费总次数≤50次的学生视为异常个体,将其数据记录剔除不予考虑. 另外,对于学生某一餐缺失的数据,其该餐的消费金额记为0,消费次数不计,此类处理不会影响该生整体的消费水平和模型分析的准确性.
④ 超市消费处理. 对学校超市的消费数据进行处理,得到学生每月超市消费的次数与金额.
2) 贫困生分析模块:该模块为系统的核心模块,根据预处理之后的数据得到学生消费特征数据,结合系统定义的贫困生规则,按照熵值法模型计算各指标的权重,进而计算学生的贫困指数,并进行排序;依据排序和规则划定贫困生等级,得到最新的贫困生名单,并进入审批环节.
3) 贫困生查询模块:该模块主要用于查询在校贫困生的情况,主要包含两类,一类是历史贫困生名单,另一类是新增的贫困生名单. 历史贫困生名单是上一期根据贫困生规则定义生成并经过审批后,实际执行的贫困生名单;新增贫困生名单是在本次评定周期内,根据贫困生规则定义进行分析,并结合历史贫困生数据,通过审批后生成的最新贫困生名单.
4) 统计分析模块:该模块结合图、表等形式呈现在校贫困生的整体信息,如全校贫困生的历史人数对比、院系人数分布、籍贯和政治面貌分布等;同时,也对全校贫困生的消费情况进行分析,便于学校全面了解在校贫困生的整体情况.
5) 贫困生规则定义:该模块主要是对学校的贫困生评定规则进行定义,包括贫困因子权重配置、贫困等级评定配置. 贫困因子权重配置就是学校可根据实际情况对系统默认的因子权重进行一定的调整,贫困等级评定配置是学校根据系统分析出的学生贫困指数量化分值排名来配置学校贫困生的贫困等级. 比如,将贫困指数量化分值排名前5%的学生认定为特别贫困;将贫困指数量化分值排名前5%~15%的学生认定为困难生;将贫困指数量化分值排名前15%~30%的学生认定为一般贫困生.
6) 数据更新配置:考虑到学生在校学习的时间情况,该模块用于对原始消费数据的抽取和分析处理的时间周期进行配置. 系统每学期进行一次数据抽取和分析,抽取周期默认为3个月的消费数据. 比如,每年上学期的数据抽取3月、4月和5月份的数据进行分析处理,数据更新时间设置为9月1日;每年下学期的数据抽取10月、11月和12月份的数据进行分析处理,数据更新时间设置为3月1日.
7) 审批处理模块:本文设计的系统通过自动化分析与人工评定相结合的方式得出最终的贫困生名单,因此,该模块主要是实现对自动化分析评定结果的审批处理. 系统默认设计四级结果审核机制,分别是辅导员审核、院系审核、学工部审核、学校审核,学校可根据实际自定义审批流程.
8) 系统基础模块:该模块是系统的基础模块,包含用户管理、角色管理、菜单管理、权限管理以及参数配置等. 用户管理用于对学生及用户的基本信息进行新增或者同步管理;角色管理用于配置和分配用户角色;菜单管理用于配置系统功能菜单;权限管理用于对用户角色进行权限分配;参数配置模块用于配置各类系统参数.
-
本系统除了系统基础模块涉及的用户表、角色表、权限表、菜单表、系统参数表等基础数据表外,涉及的主要业务数据表有学生基本信息表、一卡通消费原始记录表、消费数据预处理记录表、学生消费特征数据表、贫困指数表、贫困生规则定义表、贫困生等级定义表、审批结果表等,以上几个数据表设计如图 3所示.

2.1. 系统架构设计
2.2. 系统功能设计
2.3. 数据库设计
-
本系统的实现以Spring Boot 2为基础,通过Maven构建多模块项目,模块之间松耦合设计,方便模块的升级与增删. 前端基于BootStrap 4的HTML页面和语法直观、性能超高的Beetl模板引擎进行开发. 后端服务器基于Spring Boot 2.0+Spring Security+Spring MVC+MyBatis的技术体系进行开发,从而去除了大量的配置操作,简化了开发流程[15]. 将Tomcat作为后端服务器;采用Spring Security作为安全访问框架,实现对用户身份的认证和资源访问权限的控制;使用MyBatis作为持久层框架,同时引入Mapper和Page Helper插件,可以快速对表进行增删改. 通过这几种经典技术的组合,使系统安全稳定并具有可扩展性. 在系统实现过程中,利用熵值法求指标权重的代码,原始消费数据预处理实现代码,利用预处理数据计算消费特征数据的实现代码,以及计算贫困指数的实现代码为该系统实现的主要核心代码. 其中,利用熵值法求指标权重的Java实现代码如下:
public static List < Double> getWeight(List < List < Double>>list){
//用于存放每种指标下所有记录归一化后的和
List < Double> listSum=new ArrayList < Double>();
//用于存放每种指标的差异系数
List < Double> gList=new ArrayList < Double>();
//用于存放每种指标的最终权重系数
List < Double> wList=new ArrayList < Double>();
double sumLast=0;
//计算k值k=1/ln(n)
double k=1 / Math.log(list.get(0).size());
//数据归一化处理(i-min)/(max-min)
for (int i=0;i<list.size();i++) {
double sum=0;
double max=Collections.max(list.get(i));
double min=Collections.min(list.get(i));
for (int j=0;j<list.get(i).size();j++){
double temp=(list.get(i).get(j) - min) / (max - min);
sum += temp;
list.get(i).set(j,temp);
}
listSum.add(sum);
}
//计算每项指标下每个记录所占比重
for (int i=0;i<list.size();i++) {
//每种指标下所有记录权重和
double sum=0;
for (int j=0;j<list.get(i).size();j++)
if(list.get(i).get(j) / listSum.get(i) == 0){
sum +=0;
}
else{
sum +=(list.get(i).get(j)/listSum.get(i))*Math.log(list.get(i).get(j)/listSum.get(i));
}
}
//计算第i项指标的熵值
double e=-k * sum;
//计算第j项指标的差异系数
double g=1-e;
sumLast+=g;
gList.add(g);
}
//计算每项指标的权重
for (int i=0;i < gList.size();i++){
wList.add(gList.get(i) / sumLast);
}
return wList;
}
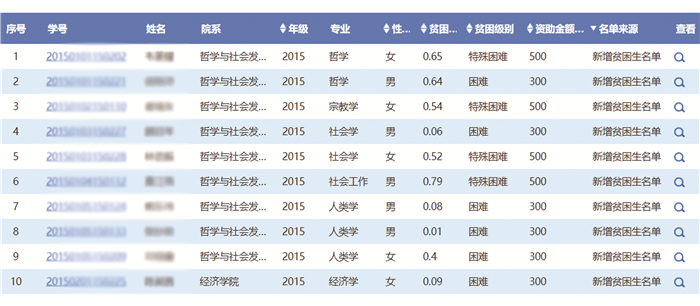
经过编程实现,利用熵值法求出本文设计的8个指标权重分别为:W1=0.182 1,W2=0.153 3,W3=0.102 1,W4=0.124 2,W5=0.105 6,W6=0.087 2,W7=0.128 3,W8=0.117 2. 经过测试,本文设计与开发的系统所分析的结果示例图如图 4所示. 按照系统审批流程,系统分析结果经过相应的审核流程后,可最终确定贫困生资助名单和资助等级.
-
高校贫困生认定系统的研究重点包括两方面,一是识别出哪些学生更符合学校的补助标准;二是根据数据分析出学生的补助等级. 因此,为了验证系统分析结果的准确性,本文利用某高职院校2016级4 218名学生在2017年的一卡通消费数据和基本信息数据进行测试分析. 结合该校的实际情况,系统将贫困指数量化分值排名前2%的学生认定为特别贫困;排名前3%~5%的学生认定为普通困难;排名前6%~10%的学生认定为一般贫困. 根据测试结果,验证系统分析出的贫困生名单与学校当年实际评定名单的符合度.
按照设定的分析比例,系统分析出的422个学生总名单中有367个学生与实际名单和贫困等级相吻合,精准度达到86.97%. 其中,特别贫困生的准确率为82.14%,普通贫困生的准确率为84.25%,一般贫困生的准确率为90.52%. 通过测试结果显示,该系统对于贫困度相对较低的学生的识别准确率相对高一些,能较为准确地筛选出学生所属的贫困等级范围,学校再结合人工审核的方式进行最终评定,将提高学校贫困生认定工作的效率.
3.1. 系统实现
3.2. 结果分析
-
为实现高校对贫困生的精准资助,提高资助育人成效,解决贫困生认定工作中难量化、不客观的问题,本文利用校园卡消费数据、学生基本信息数据,结合恩格尔定律,设计了学生消费恩格尔系数、月均食堂消费水平、早餐月均消费额校均比、中餐月均消费额校均比、晚餐月均消费额校均比、食堂就餐率、助学贷款总额、勤工助学次数等8项贫困生认定指标,并运用熵值法计算各指标的权重,客观计算出学生的贫困指数,确定贫困等级. 最后,通过Java EE技术实现了相应的系统,经过测试系统可以很好地运用于实际工作中,能帮助学校解决贫困生评定过程中存在的难量化、不客观等问题. 未来,将研究利用学生的移动支付和网络支付等途径的消费数据,使数据更加完整,涵盖的范围更加广泛,系统识别的准确性也将进一步得到提高.
 DownLoad:
DownLoad: