





-
相比其他技术,如环境传感器和可穿戴传感器,视频图像动作识别技术具有更高的效率和更低的成本,然而由于人类姿势和图像质量的大量变化,人类行为的可靠检测对于研究者来说仍然是一项极具挑战性的工作[1-3]. 人类行为识别(Human Action Recognition,HAR)是将人类行为转化为数字行为的过程,具有复杂的动作理解能力,在智能监控、网络视频搜索和检索、病人监护、运动分析、人机交互等多媒体应用中起着重要的作用[4].
在人类行为识别领域,许多研究者提出了不同的方法来促进该方面的进步. Jalal等[5]实现了用于姿势估计的身体部位估计与检测,Uddin等[6]使用深度递归神经网络对翻译和尺度不变特征进行活动识别. 现有典型的两种特征类型为:人造局部特征和深度学习特征提取. 吴亮等[7]提出了基于时空兴趣点和概率潜动态条件随机场模型的在线行为识别方法,应用时空兴趣点(STIP)对行为特征进行提取,Nguyen等[8]提出了用于动态纹理识别的密集轨迹(DT)定向光束方法,这类方法在识别上有局限性[9-10]. 对于深度学习特征方法,Xiao等[11]提出了分层动态贝叶斯网络的动作识别方法,Yang等[12]提出的非对称3D卷积神经网络的动作识别方法,打破了识别上的局限性[13].
对于大规模的特征识别,传统深度方法具有局限性,需要考虑并行化处理方法. 文献[14]实现了MapReduce框架下的深度神经网络特征提取,但是局限性是MapReduce不适合迭代算法. Apache Spark通过使用弹性分布式数据集(RDDS)高效地执行分布式应用程序,更适合分布式视觉算法的开发.
在现有动作识别特征提取算法的基础上,本文提出基于Spark框架的特征提取并行解决方法,实现分布式环境中视频序列提取局部特征. 该方法基于Spark框架,针对现有轨迹池深度卷积描述符(TDD)特征、改进密集轨迹(IDT)和潜在概念描述符(LCD)特征,设计特征提取并行算法,最后设计局部特征聚合描述符(VLAD)并行实现,将提取的局部特征聚合到全局表示中,识别视频中的动作.
HTML
-
IDT框架与DT的基本框架一致,不同之处是对光流图像的优化、特征正则化方式的改进[8]. ①估计相机运动来消除背景上的光流以及轨迹;②特征正则化方式由L1范数取代原理的L2范数正则化,能够提升分类准确率.
TDD特征具有人造设计特征和深度学习特征的优点,有区分的卷积特征映射通过深度结构来学习,然后使用轨迹控制的pooling方法融合卷积特征. 首先设计深度的ConvNet提取卷积特征映射,选择具有较好性能的双流ConvNet,该双流ConvNet包含两个单独的ConvNet,即空间网和时间网. 空间网旨在捕获静态外观线索,这些线索在单帧图像上训练,而时间网旨在描述动态运动信息,其输入是堆叠的光流场体积.
双流ConvNets训练完成后,将其视为通用特征提取器,以获取视频的卷积特征映射. 对于每帧或每卷,将其作为空间网络或时间网络的输入. 对时空网络进行两种修改,①删除目标图层之后的图层进行特征提取;②在每个卷积或池化层之前,对层输入进行零填充,通过这种填充可以很容易地将视频中轨迹点的位置映射到卷积特征映射的坐标上. 空间网络和时间网络的输出是卷积特征映射,该卷积特征映射将在下一部分中用于提取TDD.
TDD的提取包括两个步骤:特征映射正则化和轨迹合并. 时空正则化方法可确保每个卷积特征通道在相同间隔内变化,从而对最终TDD识别性能做出同等贡献. 在特征正则化之后,基于轨迹和正则化的卷积特征映射,使用轨迹池提取TDD.
对于卷积神经网络(CNN)潜在概念描述符(LCD)特征,本文CNN架构采用的是2014年ImageNet大规模视觉识别挑战赛牛津大学视觉几何组卷积神经网络分类任务获胜解决方案中具有16个权重层的配置,前13个权重层是卷积层,其中5个紧随其后的是最大合并层,最后3个权重层是全连接层.
-
本节设计了在Spark环境中并行LCD提取方法,然后给出了TDD的并行实现方法,给出IDT并行描述,最后设计了VLAD编码的并行实现.
-
在Spark上提取潜在概念描述符:利用CNN特征映射提取深层的局部特征,给定一帧It,t=1,…,T,T为视频持续时间,将CNN中间层的过滤器作为特征提取器,将CNN特征映射Mt的像素变成帧It中相应补丁的局部特征. 其中,Mt∈RH×W×C是帧It的特征映射,H是高度,W是宽度,C是通道数.
局部特征称为潜在概念描述符(LCD),为了使群集内存受益,原始视频数据将从分布式文件系统(HDFS)加载到Spark RDDS. 最初,flatMap()函数将视频输入文件作为输入,读取所有帧并将其放入帧RDD中,flatMap()函数由Spark执行,并应用于每个视频以获取所有RGB帧.
进行flatMap()转换后,使用BigDL加载预训练的卷积神经网络(VGG19)模型并将其传递给Map()函数,该函数利用Conv5层将所有RGB帧转换为CNN特征映射. 最后,将帧It的CNN特征映射传递给flatMap()函数以获取LCD特征{LCDtj},该特征将存储在HDFS中.
-
在Spark上提取轨迹合并的深度卷积描述符:首先采用CNN的中间层来计算视频序列中每个帧的特征映射,通过使用改进轨迹的方法来检测一组轨迹,然后遵循轨迹约束的采样和合并策略,获得深度卷积描述符. 通过在以轨迹点为中心的时空网络上合并局部CNN响应,将卷积特征映射与改进轨迹组合在一起,并将多个标度上的采样点作为IDT的原始实现进行跟踪.
-
在特征提取阶段之后,对局部特征进行编码生成全局表示,该全局表示将在随后的分类阶段中用于训练和测试.
2.1. LCD的分布式表示
2.2. TDD的分布式表示
2.3. VLAD编码的分布式表示
-
为了评估基于Spark框架的特征提取分布式算法的性能,在9个节点(包括1个Master节点和8个Slave节点)的计算机集群上进行人类动作识别实验,每个节点具有相同的配置:Win10操作系统,I7处理器、8 GB运行内存,使用Hadoop版本为2.7,Spark版本为2.3.3,所有数据都放在同一HDFS群集上. 实验数据集为动作识别数据集UCF101,该数据集是最大的动作数据集之一,在实际场景中从YouTube收集了13 320个具有101个动作类的视频剪辑,每类动作由25个人做动作,分辨率为320×240,共6.5 G.
图 1给出了分布式特征(IDT,LCD和TDD)的运行时间,由图 1可以看出本文所提的Spark分布式特征方法的可行性和可扩展性. 另外,也可以看出当将节点数目从1增加到8时,特征提取过程明显加快. 即随着运行节点数量的增加,分布式特征提取的时间几乎呈线性下降. 这种良好的可伸缩性性能是因为Spark的内存计算能力,可以最大程度地减少I/O和网络通信的时间.
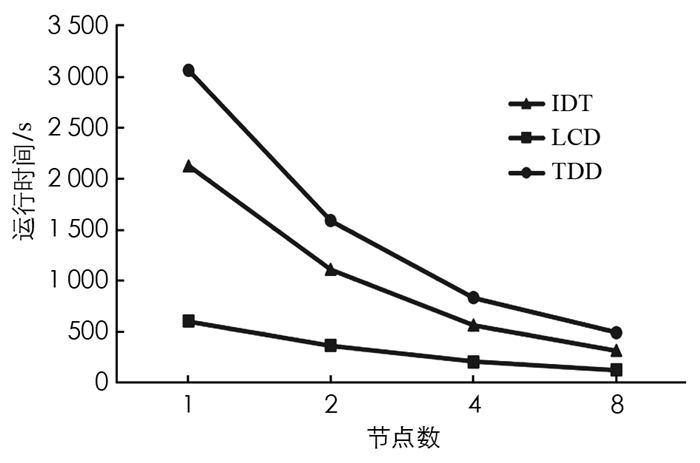
此外,LCD的提取过程比IDT的提取过程快,这是因为从LCD的RGB帧中提取CNN特征映射,而IDT中的光流计算和特征跟踪操作需要更多的时间来执行. 当在大量节点上运行时,IDT会花费额外的时间在本机程序和Spark workers之间进行通信. 同时,LCD的所有特征提取过程都完全在Spark workers上运行,而无需本机库与Spark之间的通信. TDD是3种特征提取方法中最耗时的,其执行时间几乎等于LCD和IDT提取时间之和. 这是因为从给定的原始视频中提取TDD的过程,是计算CNN特征映射和提取顺序执行轨迹的组合.
图 2给出了不同特征提取方式执行分布式特征编码时执行时间的比较结果.
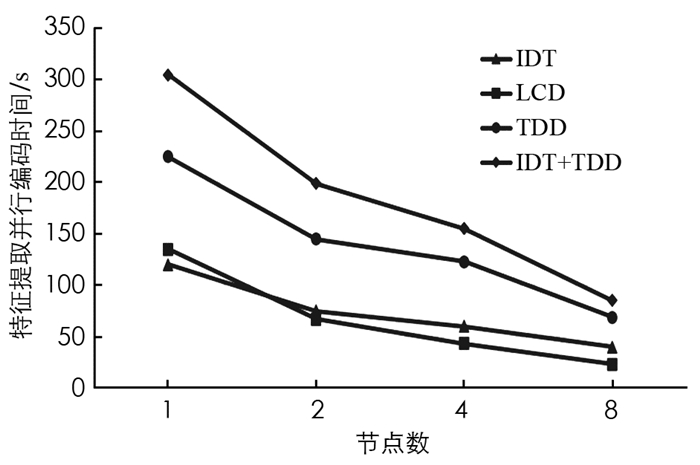
从图 2中可以看出,随着运行节点数量的增加,编码过程显著加快. 从图 2中还可以看到IDT和LCD的编码时间没有太大差异,原因是编码时间受特征数量和特征维数影响,并且对于这两个特征,这些因子的值相近. IDT特征的数量相当于TDD特征的数量,这是因为它们都采用了同样的轨迹约束采样策略. 本文进一步比较了在描述符级别将IDT和TDD组合在一起的结果,由于特征尺寸较大,组合特征的编码时间比其余3个特征更长.
然后使用目标检测、动作识别问题中最常用的度量标准——平均精度均值(Mean Average Precision,MAP)作为指标,来验证本文所提的分布式特征提取方法的有效性,实验结果如图 3所示.
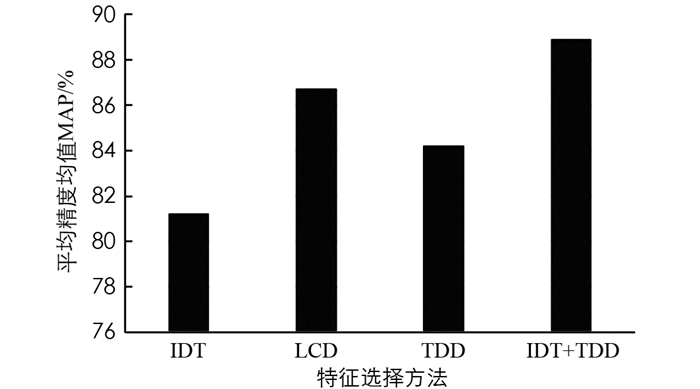
从图 3中可以看出,使用VLAD编码,深度学习特征MAP要优于手工制作特征MAP. 尽管LCD是TDD的简化版本,具有更简单的采样策略,但LCD的精度更高. 另外,TDD拥有外观信息,而IDT捕获运动信息,由于IDT和TDD彼此具有很强的互补性,因此组合特征可提高MAP.
由图 1-图 3中数据可以得出,在4个特征中,LCD在精度和处理时间之间的权衡要比其他特征更好,组合特征方法可以提高准确性,但同时又会牺牲时间.
-
利用Spark提供的内存计算和容错功能来解决大规模的人类动作识别问题,本文提出了基于Spark的分布式动作识别特征提取方法. 设计了用于人类动作识别的几个特征提取的分布式解决方案,包括IDT,LCD,TDD以及VLAD编码的分布式实现. 在数据集UCF101上的实验可以得出,本文方法提高了人类动作识别的实时性能,并具有令人满意的可扩展性,其中LCD在精度和处理时间之间的权衡要比其他特征更好.
 DownLoad:
DownLoad: