





-
在这个信息爆炸的时代,时刻都产生着大量的数据,在这些数据中,有一类为不平衡数据,其各个类别的样本数目相差巨大[1]. 在软件缺陷预测领域,其缺陷数据集通常都是不平衡的[2]. 但是直接用传统分类方法解决不平衡数据的分类问题时,其效果往往都不理想. 这是因为不平衡数据集中多数类的数量远远大于少数类的数量,导致数据集没有足够的少数类信息进行分类预测[3]. 传统分类方法追求整体的准确率最大化,从而导致模型更偏向于多数类,但不平衡数据中的少数类在现实生活中的意义往往更大.
为了解决软件缺陷数据集的不平衡问题,有大量的方法被提出. 这些方法主要是在算法层面和数据层面上解决数据不平衡问题,算法层面有代价敏感[4]、集成学习和特征选择[5]方法. 数据层面的方法主要是过采样、欠采样和混合采样. 过采样中使用最频繁的是随机过采样(random over sampling),因为该算法的实现较简单并且效果还比较好. 文献[6]使用簇心或最接近簇心的样本代替原数据,基于此提出了两种聚类的欠采样方法. SMOTE(synthetic minority oversampling technique)算法存在一些不足,比如易引入噪声点、合成的样本有重复等问题,于是产生了很多改进算法[7-9]. 文献[10]提出了将SMOTE算法和数据清洗方法相结合,增加了多数类和少数类的可分性.
过采样和欠采样虽然可以平衡数据分布,但欠采样可能会删除对分类有价值的数据,过采样则会增加过拟合的风险而且可能引入不合理的样本数据[11]. 在软件缺陷预测领域,使用不同的缺陷数据集、分类技术和度量指标得到的最好抽样方法有时会出现矛盾. 这意味着没有一种抽样方法可以在所有软件缺陷数据上表现得很好[12]. 因此,由于有大量不同的抽样方法,软件研究人员和从业人员为新的软件缺陷数据选择适用的抽样方法将是非常困难但相当重要的,故本文提出了一种抽样推荐算法,为新数据集推荐适用的抽样方法.
HTML
-
在不平衡数据中,负样本为数量多的样本,正样本为数量少的样本,且正样本在现实生活中的意义大于负样本. 欠采样是指选取一些具有代表性的负样本,这样大大减少了负样本的数量,使得负样本和正样本的数量相当. 虽然提高了正样本分类准确率以及分类效率,但同时也丢失了负样本的数据特征,分类模型不能充分学习到负样本的样本特征,导致负样本的分类准确率降低. 下面将介绍几种主流的欠采样方法:
随机欠采样(random under sampler)的思想就是随机选取一些多数类样本并剔除掉. 这种方法的缺点是被剔除的样本可能包含着一些重要信息,致使学习出来的模型效果不好.
NearMiss本质上是一种原型选择(prototype selection)方法,为了在一定程度上解决随机欠采样的信息丢失问题,用于训练的样本都是从多数类样本中选取最有代表性的.
Tomek Link表示不同类别之间距离最近的一对样本,即这两个样本互为最近邻且分属不同类别[13]. 如果两个样本形成了一个Tomek Link,则要么其中一个是噪音,要么两个样本都在边界附近. 这样通过移除Tomek Link就能“清洗掉”类间重叠样本,使得互为最近邻的样本都属于同一类别,从而能更好地进行分类.
ENN的主要思想是如果有超过一半的k近邻点都不属于多数类的多数类样本,那么这个多数类样本会被剔除.
Cluster Centroids算法不是随机抽取原始样本,其每一个类别的样本都会用k-Means算法的中心点进行合成.
-
过采样是目前比较主流的处理数据不平衡的方法,其通过增加正样本的数量来平衡数据集中的正负样本,工作原理与欠采样相反. 过采样增加了正样本的数量和多样性,进而增加了正样本的数据特征,使得分类模型能够学习到更多的正样本特征,但同时这些生成的特征可能成为样本噪声,反而不利于分类模型对正样本的正确分类. 下面将介绍几种主流的过采样方法:
随机过采样的核心思想是随机的复制、重复少数类样本[14],最终使得少数类与多数类的数量相当从而得到一个均衡的数据集.
SMOTE的思想是通过在少数类样本之间插值来生成少数类的新样本. 具体地,对于一个少数类样本Xi使用k近邻法,求出离Xi距离最近的k个少数类样本,样本之间用n维特征空间下的欧氏距离进行度量. 然后从k个近邻点中随机选取一个,使用下列公式生成新样本:
其中
$ \mathop X\limits^ \wedge$ 为选出的k近邻点,δ是一个随机数且取值范围为[0, 1].Border-line SMOTE算法会先将所有的少数类样本分成3类noise,danger和safe,根据少数类样本的k近邻数来判断属于哪一类,如果所有的k近邻数都是多数类就属于noise类别,超过一半的k近邻数是多数类就属于danger类别,超过一半的k近邻数是少数类就属于safe类别. 该算法只会从danger类别的少数类样本中随机选择,然后用SMOTE算法合成新的样本. 因为danger类别处于边界附近,而处于边界附近的样本更容易被误分.
ADASYN(adaptive synthetic sampling)名为自适应合成抽样,其最大的特点是每个少数类生成新样本的数量是自动机制决定的,而SMOTE对每个少数类样本生成的数量都相同. ADASYN给每个少数类样本施加了一个权重,周围的多数类样本越多则权重越高,导致它易受离群点的影响.
-
欠采样和过采样相结合的方法称为混合采样,通过样本生成模型生成一部分新的正样本,通过样本筛选模型选取一部分具有代表性的负样本,从而达到正负样本的数量相当. 混合采样旨在减少负样本的特征丢失,同时减少正样本的噪声生成. 主流的混合采样方法有SMOTEENN和SMOTETomek.
-
协同过滤算法是目前推荐系统中最常用的一种推荐策略,许多互联网公司如阿里巴巴、百度和腾讯等已经成功应用到实际系统中,其主要思想是根据用户的历史评价数据进行分析,计算得出用户间的相似性,结合相似度给出最终的推荐列表[15-16]. 协同过滤算法一般分为两种类型,分别是基于模型的协同过滤和基于近邻的协同过滤[17]. 基于模型的协同过滤是找一个包含用户和项目之间关系的优良子空间,这样就可以计算出评分[18]. 基于近邻的协同过滤易于理解,算法比较简单,但是在用户项评分比较稀疏的情况下,很难找到稳定可靠的近邻[19].
1.1. 欠采样
1.2. 过采样
1.3. 混合采样
1.4. 协同过滤算法
-
由于数据特征与抽样方法性能之间存在一些内在的关系,即两个数据集的特征之间具有很高的相似度则被认为具有相同的适用抽样方法,故本文提出一种抽样推荐算法,用于自动选择新缺陷数据的适用抽样方法. 抽样推荐算法的框架如图 1所示,该算法由抽样方法排序、数据相似性挖掘和基于用户的推荐3个部分组成. 由图 1可知,首先通过抽样方法在历史数据集上排序来建立一个在特定分类器下的抽样方法排名存储库. 然后基于数据特征,通过挖掘新数据与历史数据之间的相似性[20],构建一个相似性存储库. 最后使用上述抽样方法排名存储库和数据相似性存储库构建一个三层网络,在此基础上为新数据集推荐适用的抽样方法.
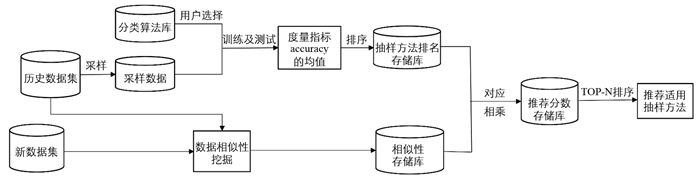
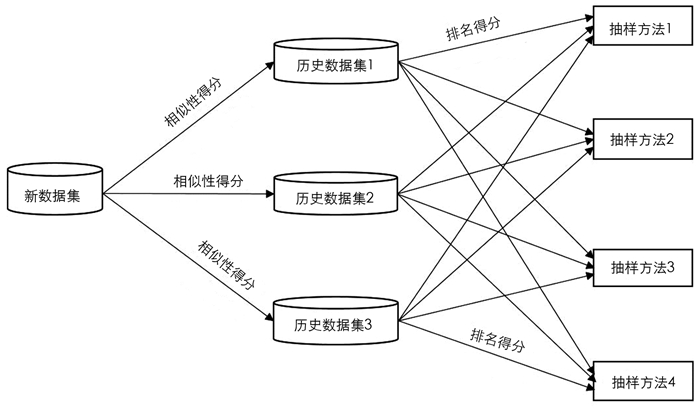
图 2给出了由3个历史数据集和4种抽样方法组成的推荐网络结构. 在图 2中,第一层是新数据集,第二层的节点表示历史数据集. 第一层和第二层的连接权重是两个数据集之间的相似性得分. 此外,抽样方法都在第三层,排名得分作为第二层和第三层的连接权重. 在构建推荐网络后,根据所获得的推荐分数对所有抽样方法进行排序,并选择Top-N排序方法向新数据集推荐抽样方法.
-
由于不同的抽样方法在处理给定的不平衡缺陷数据时可能表现出不同的性能,因此抽样方法排序的目的是根据这些不同抽样方法对指定数据的适用性提供详细的等级,这可以通过一些常见的分类评价指标来衡量,如准确率. 此外,抽样方法的性能可能随着各种分类算法的不同而变化. 算法1提供了获得抽样方法适用性的详细过程,在特定分类算法下采用10折交叉验证对软件缺陷数据进行训练,利用预测准确率作为对主流抽样方法排序的度量指标.
挖掘数据集之间的相似性是推荐算法的重要组成部分,本文采用Jaccard系数来衡量两个数据集之间的相似性. Jaccard系数的值越大,说明之间的相似性越高,其定义如下:
具体获取数据集之间相似性得分的过程见算法2.
通过前面的算法1和算法2可以得到抽样方法排名存储库和相似性存储库,利用这些信息就可以为用户的新数据集推荐适用的抽样方法,具体的过程见算法3.
2.1. 抽样推荐算法的框架
2.2. 抽样推荐算法流程
-
本文采用NASA提供的MDP软件缺陷数据集,对抽样推荐算法进行验证分析和推荐性能评价. 具体使用MDP数据集中的10个数据集文件构建了训练集,并选取了PC3,JM1和PC5这3个数据集进行验证,因为PC3,JM1和PC5的总模块数分别为1 099,9 591和16 962,其数据集规模不断扩大,由此可以验证抽样推荐算法的可扩展性. 其相关信息如表 1所示. 实验环境:Windows 10操作系统,8GB内存,使用python进行具体编程实现.
-
为了证明本文方法的有效性,通过准确率、平均准确率及命中率这些推荐算法的通用指标[16]进行评价. 在对抽样推荐算法进行评价时,需要兼顾考虑上述的评价指标.
假设R(u)是为新数据集在特定分类算法下推荐的抽样方法列表,T(u)是新数据集在特定分类算法下实际的抽样方法列表. 准确率表示预测正确的样本数占总样本数的比例,准确率Precision记为P1,其定义如下:
对于用户u,Ωu表示推荐的抽样方法在实际的抽样方法列表中,pui表示抽样方法i在推荐列表中的位置,pui>puj表示抽样方法j在推荐列表中排在抽样方法i之前. 平均准确率AP记为P2,那么u的平均准确率为
在Top-N推荐中,HR是一种常用的衡量召回率的指标,分母是所有推荐的抽样方法的个数总和,分子表示推荐的抽样方法出现在实际Top-N列表中的个数总和.
-
本文选取CM1,KC1,KC3,KC4,MC1,MC2,MW1,PC1,PC2和PC4这10个数据集作为历史数据集进行训练,并在ADASYN,Borderline SMOTE,Cluster Centroids,ENN,Near Miss,Random Over Sampler,Random Under Sampler,smote,SMOTEENN,SMOTETomek和TomekLinks这11种主流的抽样方法上进行实验. 最邻近分类算法(KNN)、支持向量机(SVM)和决策树(DTC)是机器学习中的3种经典分类算法,被广泛应用于软件缺陷预测领域,故本文选取KNN,SVM和DTC作为特定的分类算法. 按照算法1的过程,得到训练集在KNN,SVM,DTC分类算法下的预测准确率,并作为抽样方法的排名指标,具体见表 2-4. 由于ADASYN抽样方法在KC4上并不适用,故在表中的值为0.
本文选取PC3,JM1和PC53个数据集进行验证,按照算法2的流程,得到PC3,JM1和PC5与另外10个训练集之间的相似度,并作为其相似性得分,具体见表 5.
本文选取TOP-5进行推荐性能评价,按照算法3的流程,得到了PC3,JM1和PC5的排名前五的推荐抽样方法,具体见表 6.
表 6中不仅有Top-5的推荐抽样方法,还给出了测试集在特定分类器下实际表现前5的抽样方法. 本文选取Top-5推荐列表中的第一个抽样方法作为实际推荐给用户的抽样方法,因为在9次推荐中就有5次推荐分数最高的第一个抽样方法与实际表现最好的抽样方法相同,而在剩下的4次推荐中,推荐的第一个抽样方法也位于实际表现的第二位.
从表 6中可以看出,在SVM作为分类器的前提下,JM1和PC3的预测前5的抽样方法都出现在实际表现前5的抽样方法列表中,特别是在JM1的预测中,除了第一和第二的抽样方法顺序不一样外,其余都完全一样. 不论是在小规模数据集PC3上,还是在中等规模数据集JM1以及大规模数据集PC5上,最差的预测也有3个抽样方法预测正确,而且在实际中表现良好的抽样方法也位于推荐列表的前面,说明本文的推荐算法性能良好,并且可扩展性好.
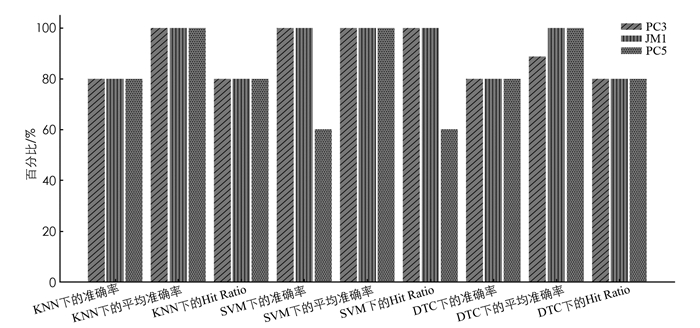
图 3给出了PC3,JM1和PC5在特定分类器下的准确率、平均准确率和Hit Ratio,由图 3可知,本文提出的抽样推荐算法在测试集上总的准确率达到了0.82,其准确率是非常高的,平均推荐的5种抽样方法中就有4种抽样方法在实际中表现良好. 平均准确率也是一个重要的推荐指标,在9次测试中,本文提出的算法就有8次的平均准确率为1,最差的也能达到0.8875,说明实际表现良好的抽样方法基本上都在推荐列表的前面. Hit Ratio的均值达到了0.823,根据这些评价指标综合考虑,可以看出本文提出的抽样推荐算法的推荐性能良好且可扩展性好,可以为用户推荐出适用的抽样方法.
3.1. 实验数据
3.2. 评价指标
3.3. 实验结果分析
-
本文提出了面向软件缺陷数据的协同过滤抽样推荐算法. 该算法首先在特定的分类器下计算训练集在11种主流的抽样方法处理后的预测准确率,并以此为衡量标准对抽样方法进行排序,然后使用杰卡德相似系数计算测试集与训练集之间的相似度,最后通过前面的排名分数和相似度值就能得到推荐分数,根据推荐分数为用户推荐适用的抽样方法. 在NASA的数据集上开展的验证实验证明所提算法能为新数据集推荐出适用的抽样方法,为后面的软件缺陷预测奠定了良好的基础.
为了证明抽样推荐算法的可行性和有效性,本文的训练集和测试集都是在NASA缺陷数据集中选取的,是因为这样能更容易地找到与测试集相似度高的训练集,不需要大量的缺陷数据集进行训练. 如果训练集从其他的缺陷数据集中选取,或者只选取与测试集相似度低的数据集进行训练,其推荐性能会下降,推荐效率会降低,但只要训练集达到一定的规模,同样可以为新的缺陷数据集推荐出性能良好的抽样方法,因此本文中抽样方法的排名结果不具有局限性. 软件缺陷数据集的数量是比较多的,比如常用的有NASA MDP,PROMISE和Eclipse等数据集,所以能找到足够数量的缺陷数据集进行训练,这样就能在很大程度上解决上述问题. 本文在算法1中使用预测准确率作为抽样方法排名的指标,还有一些其它的度量指标,比如AUC和F-Measure,使用其它的度量指标进行抽样方法排序是进一步的研究方向.
 DownLoad:
DownLoad: