



 下载:
下载:



-
开放科学(资源服务)标识码(OSID):

-
柑橘是世界上最受欢迎的水果之一,具有极高的经济价值。中国是世界上最大的柑橘生产国,主要种植区域在长江以南。受气候变化的影响,我国柑橘种植区域逐渐由长江中下游地区向西南地区转移,呈现出“西移内扩”的种植格局[1-4]。四川省是我国西南地区柑橘的重要产区,气候类型为亚热带季风气候,地形以丘陵为主,形成了独特的小气候条件,使得冬季阴湿寒冷。为避免损伤柑橘果实,降低生产成本,在冬季果实成熟前会使用白色单层纸袋对其进行套袋处理[5]。此外,为防止柑橘果实被鸟类啄食而感染虫害进而影响到柑橘产量,也需在果实成熟前进行套袋处理[6]。
传统的柑橘产量估测主要采用人工计数的方法,此方法费时费力,存在漏数或重复计数的情况,误差较为严重。近些年,机器视觉技术在农业生产领域得到广泛应用,从田间管理到采收销售等环节都进行了全面研究,极大促进了我国农业的发展[7-8]。机器视觉具有精度高、处理速度快等优势,因此利用机器视觉准确识别到套袋柑橘目标成为实现柑橘产量准确估测的关键[9-10]。虽然在绿色背景下,白色的套袋柑橘目标比未成熟的绿色柑橘果实更易识别,但受西南地区小气候影响,阴天较多,柑橘园内采光较差,果实重叠和枝叶遮挡的复杂环境仍然是影响套袋柑橘目标识别的主要问题。
基于机器视觉的图像处理技术和目标检测技术是目前在自然环境下进行目标识别研究的主流方法,目标的颜色和形状是成功检测的重要识别特征。利用图像分割方法可以有效地将目标与图片背景进行分离,达到识别目标的效果。程洪等[11]提出了一种基于图像处理和支持向量机的方法,并将此方法应用到青苹果产量估计的模型中;熊俊涛等[12]使用K-means聚类分割和优化的Hough变换圆拟合算法从背景中有效提取柑橘果实目标并应用到柑橘采摘领域中;庄家俊等[13]提出了一种改进的GB色差图方法并结合支持向量机算法来解决在果实粘连或重叠情况下识别柑橘果实的问题,为未成熟柑橘果实产量的估算提供了依据;白雪冰等[14]改进了用于柑橘缺陷样本图像分割的传统GAC模型算法,可有效识别柑橘的表面缺陷;邹小林[15]使用基于局部邻域二阶差分法的过渡阈值图像分割算法可以更快更好地提取皇帝柑的图像目标;Gong等[16]开发了一种使用图像分割技术在自然环境中识别黄色柑橘的软件系统,该系统可用于柑橘果实产量的估算;Dorj等[17]设计了一种利用图像处理技术识别成熟柑橘的计算机视觉算法,可应用到柑橘产量估算研究中。
传统的图像分割算法存在算法复杂、效率低等问题。近年来,深度学习算法发展迅速,在农业生产领域研究中也逐渐得到应用。现有的深度学习目标检测算法主要分为2种类型,分别是双通道检测和单通道检测。双通道检测应用最广泛的算法为R-CNN系列算法,如Huang等[18]利用改进的R-CNN算法提高了分割葡萄簇的能力,有利于果园管理者对葡萄生产进行管理。单通道检测主要有YOLO系列算法和SSD算法[19],YOLO系列算法相较于SSD算法具有更快的检测速度和更高的识别精度,被诸多学者应用到农业生产中。杨军奇等[20]基于YOLOv4目标检测算法提出了改进的目标检测模型,提高了在田间检测葡萄叶片目标的平均精度;涂智荣等[21]提出了一种基于YOLOv7-Tiny模型改进的目标检测模型,该模型更加轻便,提高了识别果园中百香果目标的能力;杨健等[22]修改了YOLOv5算法的骨干模型结构和损失函数,有效地提高了目标检测模型在温室环境中识别番茄的准确率;黄小玉[23]采用YOLOv3算法对绿色柑橘进行了识别研究,有助于构建早期柑橘估产模型;伍锡如等[24]采用深度学习算法为水果采摘机器人设计了一个视觉识别系统,其识别准确率超过97%;Wang等[25]提出了YOLO-CIT模型,用于识别柑橘果实成熟度;Lin等[26]以Next-ViT为基础结构,通过添加注意力创建了AG-YOLO网络模型,有效解决了识别成熟黄色柑橘目标时漏检和多检的问题;Gu等[27]提出了一种基于YOLOv7-Tiny的改进算法模型,提高了在复杂环境下识别柑橘果实目标的能力。
柑橘生长会经历萌芽、开花、结果和成熟4个阶段。在开花和结果阶段以及果实成熟前的时间段内,会对柑橘植株进行疏花疏果工作,防止因过多的果实消耗植株内养分造成植株过劳乃至死亡。柑橘成熟期主要集中在12月至次年3月,并以春节为界分为早熟柑橘品种和晚熟柑橘品种。绿色柑橘果实不易在绿色背景下识别并且无法判断是否对柑橘植株进行过疏果工作。而在套袋期间,大部分柑橘植株已经完成疏果工作,更有利于开展柑橘产量估测。因此,构建柑橘估产模型的关键是如何提高在自然环境下识别套袋柑橘目标的能力,并为未来轻量化部署创造有利条件。目前有关套袋柑橘目标识别检测的研究较少,吕佳等[28]提出了基于师生模型的SPM-YOLOv5算法用于识别套袋柑橘,其平均精度均值为77.4%,为套袋柑橘识别研究提供了参考依据;Sapkota等[29]将YOLOv8系列算法与CNN算法在不同果园条件下对2个不同数据集的实例进行分割比较,结果表明YOLOv8算法具有较高的准确性和效率,更有利于为模型轻量化部署创造条件。
通过上述理论研究和实际情况分析,本研究在YOLOv8n目标检测模型基础上提出DH-YOLO(YOLOv8n-DySample-HWD)套袋柑橘目标检测模型,用于识别自然环境中的套袋柑橘,以期为柑橘产量估测研究提供新的参考依据。
全文HTML
-
本研究的套袋柑橘数据集来源于四川省成都市蒲江县堰儿子村的一处柑橘园,柑橘品种为“春见”。使用智能手机对套袋柑橘进行了不同角度的拍摄,包括目标的正面、侧面、反面等,所采集到的套袋柑橘目标如图 1所示,图片像素为3 000×4 000,总共采集到500张图片。采集时间为2023年11月,天气以多云、阴天为主,为西南地区秋冬季节正常天气条件。
-
使用X-AnyLabeling标注工具对所采集的图片进行手动标注。为提高模型的训练效率,所采用的标注方式为沿套袋柑橘目标轮廓进行标注。为了更加精准地识别单棵果树上的套袋柑橘目标,减少背景中其他果树目标的干扰,主要标注对象以图片中距离摄像头最近的套袋柑橘为主,标注方式如图 2所示。
随后,将标记好的套袋柑橘图像导出为YOLO训练所需的txt文件并进行分类,按4∶1的比例分为训练集(train)和验证集(val)。为了进一步提高模型的识别精度以及验证数据集中图片数量对训练结果的影响,通过提高亮度、加噪声和增加对比度等方式,将训练集扩展到2 000张。原始图像对应的txt文件也进行了修改,以满足实验要求。图像增强效果如图 3所示。
-
本研究基于YOLOv8系列目标检测算法提出了一种专门识别套袋柑橘目标的检测模型。YOLOv8系列算法是一种单通道目标检测算法,具有精度高、检测速度快和可扩展性强等优点,根据模型内存大小划分为5个等级,由小到大依次为n、s、m、l、x[30]。为了使所修改的模型能投入到实际农业生产中,便于轻量化部署,本研究选择以YOLOv8n目标检测模型为基础,进行了相应的改进[31]。
YOLOv8系列算法由主干网络(Backbone)、颈部网络(Neck)和头部网络(Head)3部分组成。与结构相似的YOLOv5目标检测算法相比,YOLOv8算法的结构用C2f模块代替了YOLOv5算法结构中的C3模块,这种改动使模型具有更丰富的梯度流,可以有效调整不同模型中的通道数量,提高了模型的检测速度;在头部网络中,YOLOv8算法使用解耦的头部结构,即无锚算法,将YOLOv5中的Anchor-Based替换为Anchor-Free,可灵活适应不同目标的形状和大小[32]。因此,基于YOLOv8算法处理速度快、准确度高等优点以及该系列算法中YOLOv8n模型的轻量化结构,利于开展套袋柑橘目标识别的研究。
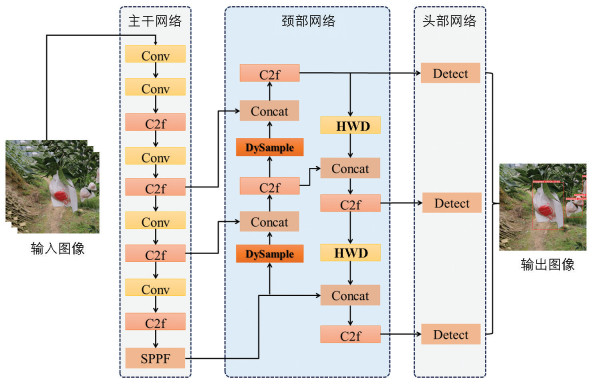
为了提高模型在果实重叠、枝叶覆盖等复杂条件下识别套袋柑橘目标的能力,本研究提出了一种目标定位更准确、识别精度更高的检测模型DH-YOLO,且与原模型相比更有利于轻量化部署。该模型主要对YOLOv8n中的颈部网络结构进行了上下采样模块的替换,所替换的模块在训练过程中可有效学习到复杂背景中的目标,从而增强模型识别套袋柑橘的能力,模型结构如图 4所示。首先,特征图在通过模型的C2f模块和SPPF层后,会经过侧重于点采样的DySample模块,在样本充足的情况下,模型的准确率得到了有效提高;其次,在执行上采样任务时,一些特征图被推进到下采样模块中,将下采样模块替换为HWD模块后,可以更加高效地学习关于特征图的大部分信息,提高了计算效率,并减少了模型内存。2个模块协同工作,在提高复杂背景下套袋柑橘目标识别精度的同时降低了模型内存大小,使改进后的模型比原始模型更有利于投入到实际农业生产中。
-
网络模型在训练时,输入图像通过卷积神经网络后图像变大,从小分辨率变为大分辨率的过程称为上采样。传统的上采样模块是基于核处理,在训练过程中需要消耗大量内存并且增加训练时间。为了提高上采样的工作效率,出现了动态采样模块。本研究使用的DySample模块与其他动态采样模块相比,具有重量较轻、工作效率高、使用范围广等优点[33]。该模块的重点是点采样发生器,此发生器有2种采样点生成方法,分别是静态范围因子(Static Scope Factor)和动态范围因子(Dynamic Scope Factor)。
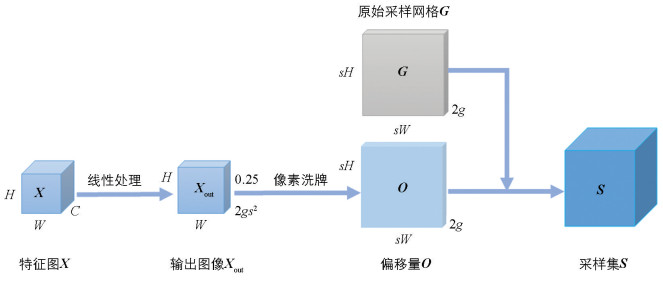
首先,静态范围因子使用线性处理和原始采样网格(Original Sampling Grid)获得偏移量。图 5展示了静态范围因子的结构,式(1)-式(3)展示了当特征图(Feature Map) X通过静态范围后的计算过程。
在式(1)中,当一个尺寸为H×W×C的特征图X输入后,通过线性处理操作得到2s2的偏移,再通过转换特征图的通道数后得到通道数量为2gs2的Xout。
随后,通过像素洗牌(Pixel Shuffle)技术得到尺寸为sH×sW×2g的偏移量O。在原始的上采样模块中会出现采样点重叠的情况,这对预测结果将产生较为负面的影响。为了解决这个问题,该模块将X out乘以0.25,对采样位置做了一定约束,更好地满足重叠和非重叠的理论边界条件,计算过程如式(2)所示:
最后,将偏移量O与尺寸为sH×sW×2g的原始采样网格G相结合,得到采样集S,计算过程如式(3)所示:
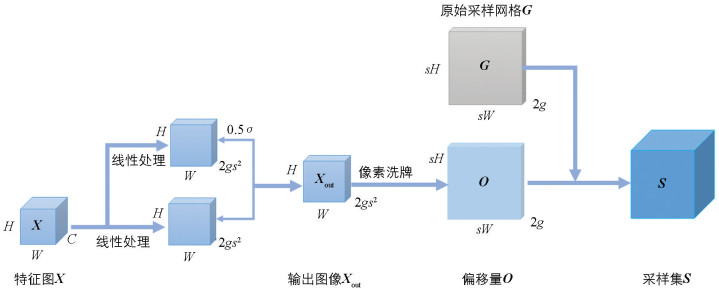
动态范围因子与静态范围因子结构类似,但在特征图处理和计算上有些许不同。图 6展示了动态范围因子的结构,式(4)展示了当特征图X输入后得到偏移量O的计算过程。
当特征图X输入后被分成2部分,将这2部分分别进行线性处理,其中一部分使用sigmoid函数进行线性处理并乘以0.5,而另一部分则与静态范围处理相同。将这2部分处理结合到一起得到偏移量O,最后与原始采样网格相结合获得最终采样集S。
DySample上采样模块增强了点采样的抗干扰能力,与其他动态上采样模块相比,它减少了参数算法,提高了识别套袋柑橘目标的准确性[34]。
-
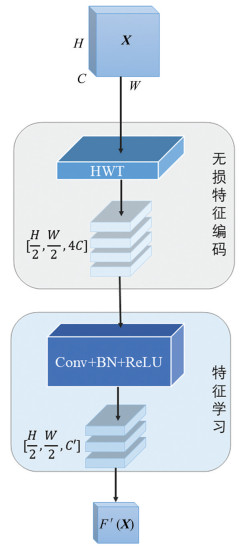
与上采样相反,下采样是在完成上采样任务后降低图像分辨率。在进行下采样任务时,图片像素减小容易丢失重要的信息,为了避免在套袋柑橘识别的训练阶段因像素不一致而导致重要目标丢失的问题,引入了一个基于Haar小波的HWD下采样模块[35],图 7展示了该模块的结构。HWD的核心思想是在转换图像分辨率时使用Haar小波来保留尽可能多的信息,该模块由2个子模块组成:无损特征编码模块(Lossless Feature Encoding)和特征学习模块(Feature Learning)。
在无损特征编码模块中,使用Haar小波变换可以有效降低特征图的分辨率,并保留大量信息。这是因为Haar小波中的滤波器可用于从维度为W×H、通道数为C的图片中提取近似和高频信息。使用Haar小波后,特征图像被处理成4个部分:近似分量以及在水平、垂直和对角3个方向上的细节分量[35]。每个部分的尺寸为
$ \frac{W}{2} \times \frac{H}{2}$ ,通道数将变为原来的4倍。特征学习模块由1个大小为1×1的标准卷积、1个批处理归一化层和1个ReLU激活函数组成。标准卷积层可以调整特征图的通道数量,允许在下采样过程中将处理后的图像与其他通道进行拼接。此功能能够删除冗余信息,从而促进对识别目标的学习。最后采用批处理归一化和ReLU激活层来提取判别特征。
HWD模块由2个不同功能的因子串联而成,特征图在通过该模块时,首先保留所有的图像信息,同时通过无损特征编码模块降低图像分辨率,最后通过特征学习模块去除冗余信息。与原下采样模块相比,降低了目标的漏检率并且减少了一定的计算量,缩减了模型的大小。
1.1. 数据来源
1.2. 构建数据集
1.3. 套袋柑橘目标检测模型
1.3.1. DH-YOLO模型结构
1.3.2. DySample动态采样模块
1.3.3. 基于Haar的HWD模块
-
该实验基于Windows 11系列操作系统,CPU为Gen Intel Core i5-13400F 2.50 GHz,GPU为NVIDIA GeForce RTX 4060 8 GB,Python版本为3.11.7,PyTorch版本为2.2.2,CUDA版本为12.1。所参与实验的训练模型均达到饱和迭代次数。在训练过程中,输入图像都被调整为640×640像素大小。
-
为了验证模型的有效性,需要对模型进行评估。深度学习网络训练时常见的评估指标有准确率(P)、召回率(R)和平均精度(mAP)。mAP分为2种类型,即mAP0.5和mAP0.5∶0.95。mAP0.5表示IoU阈值为0.5时的平均精度,mAP0.5∶0.95表示从0.5到0.95范围内的IoU阈值的平均精度[26]。结合上述4个指标可以较好地评估模型的准确性和鲁棒性,所对应的公式如式(5)-式(8)所示。
其中:TP为正确识别的套袋柑橘目标数量;FP为错误识别的套袋柑橘目标数量;FN为未识别到的套袋柑橘目标数量;n为类别总数。
-
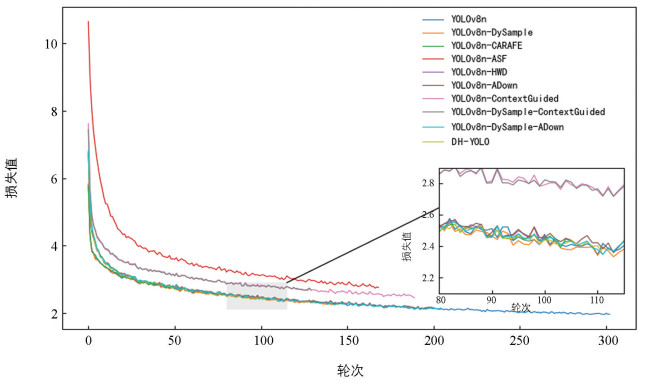
为了验证该模型所使用的上采样模块和下采样模块的优越性,参考相关文献后,选取了一些性能较好的采样模块,如CARAFE[36]、ASF[37]、HWD[35]、ContextGuided[38]、ADown等,并将模块按照类别进行组合。实验结果如表 1所示,训练中损失值与轮次之间的变化曲线如图 8所示。
由表 1可知,有3种不同模块类型的模型:只替换上采样模块、只替换下采样模块和同时替换上、下采样模块。在只替换上采样模块的模型中,尽管YOLOv8n-DySample模型的P低于YOLOv8-CARAFE模型和YOLOv8n模型,但它的R和mAP0.5明显高于这2种模型,表明引入DySample采样器后,降低了目标检测的漏检率,能够更精确地识别到目标。在只替换下采样模块的模型中,YOLOv8n-HWD模型的P高于其他模型,但R相对较低,表明模型识别到的目标有很高的可信度。在同时替换上、下采样模块的模型中,表现最佳的模型是DH-YOLO,尽管模型的P相较于YOLOv8n模型降低了0.6个百分点,mAP0.5∶0.95降低了0.9个百分点,但R提高了1.5个百分点,mAP0.5提高了1.2个百分点。虽然YOLOv8n-DySample-ADown模型的P相较于YOLOv8n模型提高了1.2个百分点,但是R降低了3.4个百分点,mAP0.5∶0.95降低了0.7个百分点,表明模型的P主要依靠降低R来提升,在执行检测任务时会产生大量的漏检目标。
从图 8展示的损失曲线可以看出,由于所有模型训练均达到饱和,所有改进模型的训练轮次要远小于YOLOv8n模型,表明改进模型的学习效率均高于YOLOv8n模型;但YOLOv8n-ASF、YOLOv8n-ContextGuided和YOLOv8n-DySample-ContextGuided 3个模型的损失值下降要远小于其他模型,表明这3个模型虽然学习效率高,但是模型所学习到的信息要少于其他模型;YOLOv8n-HWD、DH-YOLO和YOLOv8n-DySample最先达到饱和状态,饱和轮次分别为101、112和145,并且损失值下降稳定;DH-YOLO模型的损失曲线波动最为平缓,可以表明引入DySample模块和HWD模块后,提升了模型的训练质量。
基于上述分析,为了进一步提高模型识别套袋柑橘目标的能力,将YOLOv8n-DySample、YOLOv8n-ADown、YOLOv8n-HWD、YOLOV8n-DySample-Adown和DH-YOLO 5种模型在扩充数据集上进行增强实验,并通过对比分析验证DySample模块和HWD模块的优越性。
-
深度学习需要大量的图像数据,因此将数据集扩展到2 000张图像,训练集与验证集的比例依旧保持为4∶1,实验结果如表 2所示。
由表 2可知,在数据增强的协助下,所有模型的P、R和mAP都有显著提高。虽然YOLOv8n-DySample模型具有最高的P和mAP,但模型内存没有明显变化;而DH-YOLO模型的P、R、mAP0.5与YOLOv8n-DySample模型相同,仅在mAP0.5∶0.95方面比其少0.4个百分点,但DH-YOLO模型的内存小于YOLOv8n-DySample模型。尽管YOLOv8n-DySample-ADown模型的内存与DH-YOLO模型相同,但它的P不及DH-YOLO模型,即在识别套袋柑橘目标的精度上DH-YOLO模型更具有优势。对评估指标进行综合分析后可知,DH-YOLO模型在提升P、R和mAP0.5∶0.95的同时有效减少了模型内存,拥有最高的P和相对较小的模型容量,与原模型相比具有更强的优势。
-
为了更客观地展示DH-YOLO模型在检测套袋柑橘方面的优势,从识别精度和轻量化部署的综合角度出发,选取了YOLOv3、YOLOv5以及YOLOv6系列算法中最轻量化的模型,这3种模型具有较小的内存和较高的识别能力,并且已被广泛应用于各个领域中。将DH-YOLO模型与未经改进的YOLOv3-Tiny、YOLOv5n、YOLOv6n和YOLOv8n进行了比较,主要目的是验证模型在枝叶遮挡以及果实重叠的情况下辨别套袋柑橘目标的能力。上述模型在验证集上的识别能力对比如表 3所示。
与未经改进的YOLOv3-Tiny、YOLOv5n、YOLOv6n和YOLOv8n模型相比,DH-YOLO模型在整个数据集上识别套袋柑橘目标方面表现出更优越的综合性能,进一步证实了DH-YOLO模型在复杂环境中识别套袋柑橘的可行性。
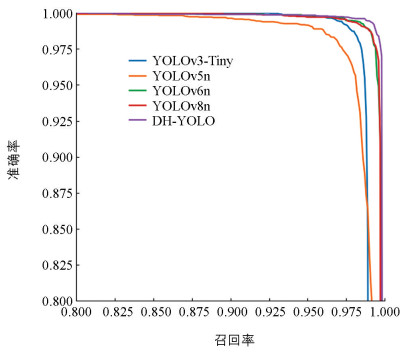
如图 9所示,DH-YOLO模型实际检测效果明显优于其他模型。黄色椭圆形区域表示模型在执行识别套袋柑橘任务时出现了多个目标识别错误,这类情况在YOLOv5n、YOLOv6n和YOLOv8n模型中较为常见;深蓝色矩形区域表示模型在执行检测任务时将背景识别成目标的情况,主要集中在YOLOv3-Tiny、YOLOv5n、YOLOv6n和YOLOv8n模型中;深红色矩形区域表示在复杂背景下检测套袋柑橘目标时模型未识别目标的情况,这类情况易存在于YOLOv6n和YOLOv8n模型中。除DH-YOLO模型外,所有模型都难以在复杂背景下准确识别套袋柑橘。从轻量化部署的角度来看,虽然YOLOv5n模型具有最小的内存,但在识别效果上不如DH-YOLO模型。PR曲线可以更加直观地衡量模型识别目标准确率和召回率之间的关系,在本次实验中,曲线越接近右上角表明模型的性能越高。5种模型在验证集上的PR曲线如图 10所示,从图中也可以看出DH-YOLO模型具有最好的性能。
2.1. 实验环境和参数设置
2.2. 模型评估指标
2.3. 实验结果
2.3.1. 不同采样模块的对比实验
2.3.2. 扩大数据集对检测性能的影响
2.3.3. 不同YOLO模型的对比实验
-
本研究旨在解决果实重叠、枝叶遮挡等复杂自然环境下,提高模型识别套袋柑橘目标的能力,并为轻量化部署创造有利条件。主要开展了以下研究工作:1) 柑橘园中拍摄套袋柑橘影像,使用X-AnyLabeling标注软件构建了套袋柑橘数据集;2) 以YOLOv8n目标检测模型为基础,通过改进YOLOv8n模型结构,提出了一种专门识别套袋柑橘的目标检测模型DH-YOLO,为柑橘采收和产量估算研究提供了有利依据。
YOLOv8系列目标检测算法与YOLO系列的前代算法相比,具有更高的识别精度,但在复杂环境下识别套袋柑橘方面存在较大不足。在本研究中,通过将DySample模块代替原始的上采样模块,提高了在复杂环境中识别套袋柑橘目标的准确率;由于上采样模块计算量较高,模块容量较大,而在执行下采样任务时,选择了基于Haar小波的下采样模块HWD,可以在保证模型准确率的同时学习目标特征,减少了目标的漏检率,同时降低了模型容量,使模型能够更好地应用于实际农业生产。
本研究所提出的DH-YOLO套袋柑橘目标检测模型与YOLOv8n模型相比,虽然整体指标相差不大,但在实际应用过程中,由于背景环境中存在枝叶遮挡的问题造成YOLOv8n模型容易漏检,而DH-YOLO模型能够较好地解决此问题,并且模型内存减少了0.2 MB,表明模型具有更强的部署能力且在实际应用中表现良好,为我国数字农业果实产量估测领域的研究提供了新的参考方案。