


 下载:
下载:
-
随着大数据时代的到来[1-2],收集和存储在数据库中的数据量也以惊人的速度快速增长,随之增长的是入侵活动和安全攻击[3-5].标准数据库安全机制以及基于网络和基于主机的入侵检测系统已经无法检测专门针对数据库的恶意攻击.数据库系统中的入侵攻击可分为外部攻击和内部攻击,外部人为获取数据库而进行的恶意交易称为外部攻击,组织内用户发生的攻击意识到安全性设置并具有某些资源的访问权限称为内部攻击[6].
每个用户的数据库使用模式都与他人不同,每个用户行为中存在的唯一性可以通过适当的事务属性来表示,这有助于构建其行为配置文件[7],并识别攻击者执行的任何恶意尝试.通常,当入侵者试图通过提交各种非法事务查询来破坏数据库时,通过日志挖掘和犯罪学程序研究的内部入侵检测与防护系统,用于显示和区分普通行为和入侵者的客户端配置文件,从而达到侵入活动的识别[8].随着数据价值的增加,数据库系统遭受攻击从未停止,因此数据库入侵检测系统(database intrusion detection system,DIDS)方面的研究不断深入[9].
Rao等[10]提出一种基于角色访问控制的数据库恶意行为检测方法,设计了基于加权角色的数据依赖性规则挖掘算法,从数据库日志中挖掘出基于加权角色的数据依赖规则,违反数据依赖规则的事务被检测为恶意事务. Elaziz等[11]提出了增强顺序数据挖掘数据库入侵检测模型,所提出的算法对用户正常历史数据进行挖掘,并对产生的规则进行归并更新,通过训练学习生成异常检测模型,并利用此模型实现基于数据挖掘的异常检测. Wang等[12]提出了一种基于粗糙概念的多层数据库入侵检测模型,提取计算机数据库的入侵特征,建立粒子群鉴别树进行节点分层处理.通过不同层次数据库入侵检测的概率操作,实现了多层次、分布式、大型差异数据库的入侵检测. Yi[13]提出了一种利用数据挖掘技术的数据库入侵检测系统,根据相关系统数据提取特定行为特征和规则,利用误用检测和异常检测方法实现入侵检测.现有数据库入侵检测系统在保证数据库不受入侵的同时,误报率也会上升.
针对这个问题,本文提出了一种新的数据库入侵检测系统,该系统创新性地将密度聚类技术的点排序识别聚类结构(Ordering Points to Identify Clustering Structure,OPTICS)引入到数据库入侵检测系统,在数据训练阶段,使用OPTICS从用户历史数据库中提取用于构建正常用户配置文件的事务特征.然而,数据库用户工作职能的转移可能会导致数据库活动出现偏差,这些数据库活动显示为异常值,但不一定是恶意的.因此,本文系统进一步单独使用多个监督分类器来加强聚类模块的初步结果,学习组件的结合最大限度地减少了数据库所有者因入侵而遭受的损失.在本文工作中,已经应用了5种不同的监督算法,说明本文系统的可用性和普适性.
全文HTML
-
OPTICS是一种基于密度的聚类技术,用于发现不同密集区域的聚类,是具有噪声的基于密度聚类方法(Density-Based Spatial Clustering of Applications with Noise,DBSCAN)的扩展,OPTICS的基本思想是:对于簇Ci中的每个对象k,其ε邻域(Nε(k))中至少存在P个点,其中ε表示半径,P表示创建群集所需的数据点数量.此外,OPTICS计算数据集中每个数据点的核心距离(disc)和可达性距离(disr).
可以将对象k的核心距离disc(k)定义为实例k与其邻域Nε(k)中对象之间的最小距离,表示为
k到另一个核心对象q对应的可达性距离disr(k)被定义为使得k从q直接密度可达的最小距离,如果在Nε(k)中找到至少P个数的实例,则数据点k可以被称为核心点.
从式(2)可以推导出点k的本地可达性距离dislr(k),其可以被描述为与k的P最近邻居的平均可达性距离的倒数.
其中,o是k的邻居,NP(k)表示P邻域,偏离集群的点可以看作是异常值.为了确定对象k是否是离群值,针对每个对象计算局部离群因子(Local Outlier Factor,LOPp(k)),其被定义为P最近邻居和k的dislr的比率平均值.
据观察,位于集群内实例的LOF值接近1. OPTICS算法能够在变化密集的地区识别出有意义的群集,群集方法将类似的数据库访问特征分组到群集中.本文将OPTICS引入到数据库入侵检测系统中,在数据训练阶段使用OPTICS生成用户配置文件,并根据局部离群因子LOF的值对用户行为进行判断.
-
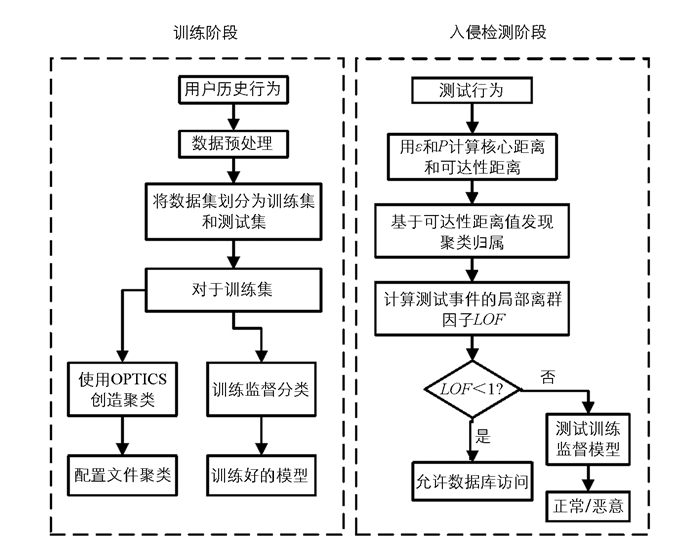
本文提出的基于密度聚类数据库入侵检测系统,最初对用户的原始事务数据执行数据预处理,其中所有属性值都被映射为数字.接下来是应用归一化过程,其中所有属性值都在[0, 1]范围内转换,归一化过程很有必要,因为数值高的数据项可能会影响异常计算的结果.然后,基于密度的聚类技术,即OPTICS被应用于预处理数据集,基于其数据库访问模式中的相似性来构建配置文件簇.位于集群中的一个事务被标记为真的,而不属于任何群集的事务被传递到不同的监督分类器-朴素贝叶斯(Naive Bayes,NB)、决策树(Decision Tree,DT)、规则归纳(Rule Induction,RI)、K-近邻(k-Nearest Neighbor,k-NN)和径向基函数网络(Radial Basis Function Network,RBFN)进行进一步的研究.
这些分类器通过组合当前事物的信息以及数据库用户的过去行为来检测恶意事物.在图 1中,本文提出的入侵检测系统事物流包括2个阶段:训练阶段和入侵检测阶段.
-
训练阶段讨论与数据库用户原始数据预处理有关的程序,以及用户行为概况构建和5种不同监督分类器的训练.
训练事物可以由 < user_id,querytype,tablelist,attlist,timeslot,timegap,loc>这个属性来表示,其中每个属性的解释见表 1.
假设,一个包含两个查询q1和q2的事务已经由具有user_id = 10的用户提交到执行某些任务的数据库中,事务中的查询为q1:从表T1中选择x,y,其中z=1;q2:从表T2中删除,其中w=1.
其中,表T1由属性x,y和z组成,而表T2由w作为其特征,对于q1,其访问的属性列表是〈z,x,y〉,而对于q2,其访问的属性列表是〈w〉.在事务中,querytype为〈SELECT,DELETE〉,tablelist为〈T1,T2〉,attlist为〈z,x,y,w〉.将分类值映射到整数后,假设querytype〈SELECT,DELETE〉=〈1,4〉,attlist〈z,x,y,w〉=〈40,23,12,6〉和表格〈T1,T2〉=〈3,6〉.假设用户在上午6点至下午6点30分(timeslot=37)之间执行了事物(loc=1),并且距离用户最后一次事物的timegap为21 min.因此,用户10的配置文件可以描述为〈10,{1,4},{3,6},{40,23,12,6},37,1,21〉.
为了构建用户配置文件,首先执行事务属性的数据预处理,然后将数据集划分为训练集和测试集.数据预处理结束后,通过在训练集上应用OPTICS算法来构建用户配置文件,其需要两个参数ε和P作为输入.根据OPTICS算法的式(1)和式(2)来计算每个数据点的核心距离(disc)和可达性距离(disr)值,OPTICS算法以升序方式产生数据点的disc和disr值.通过累积具有相邻disr值的数据点来形成聚类.
此外,监督分类器的训练是通过将历史训练事物作为输入来完成的,这些分类器分别从数据集中生成各自的学习模型,然后将这些训练好的模型用于异常事务处理以作最终决策.
-
无论用户何时向数据库提交测试事务,聚类模块使用式(2)计算来自配置文件聚类的disr值,以确定由最低disr值决定的聚类归属.另外,通过使用式(4)计算其局部异常因子(LOF)来确定交易的异常程度.如果LOF < 1,那么事物被标记为真实,并且允许数据库访问.相反,对于LOF≥1的事务被发现偏离其正常状态,因此经过一系列训练有素的监督分类器进一步处理,以确认数据库访问模式中的偏差.这些经过训练的分类器模型用于预测不一致事务的最终结果.
2.1. 训练阶段
2.2. 入侵检测过程
-
本文使用Panigrahi等[14]提出的数据生成程序来生成模拟事物及其标签,以表示真实客户及入侵者的行为.该模拟器通过使用马尔可夫调制泊松过程(Markov Modulated Poisson Process,MMPP)构建. MMPP的状态定义和控制来自真实用户和入侵者事务请求的到达率.此外,3种高斯分布函数已被用于生成不同的事务属性,以模拟不同类别的真实用户和入侵者.事务生成在表属性(attlist,tablelist)及事务属性(querytype,timeslot,timegap,loc)的粒度级别上进行控制.
本文采用准确度(Accuracy,Acc)、真正类率(true positive rate,TPR)和负正类率(false positive rate,FPR)来对系统的性能进行验证. Acc表示正确分类事物的百分比,TPR表示所识别出的正实例占所有正实例的比例,而FPR表示错认为正类的负实例占所有负实例的比例.
训练集和测试集的比例为7:3,本文提出的基于密度聚类数据库入侵检测系统的测试由聚类模块开始,该模块以参数ε和P两个参数作为输入.为了获得最佳的参数值选择,本文进行了大量实验,得到数据性能随着构建集群数据点数量P的增大而变好,而随着ε增加而变差.本文实验中选择了P取值为10,50和100,ε取值为0和0.9,得到不同ε和P组合的分类性能(表 2).
从表 2中可以看出,当P=10时,ε=0条件下比ε=0.9条件下性能更佳,此时Acc和TPR的值都高于ε=0.9产生的性能,而FPR=34.73%,低于ε=0.9产生的FPR.并且随着P值越来越大,Acc,TPR和FPR的值都随着升高.
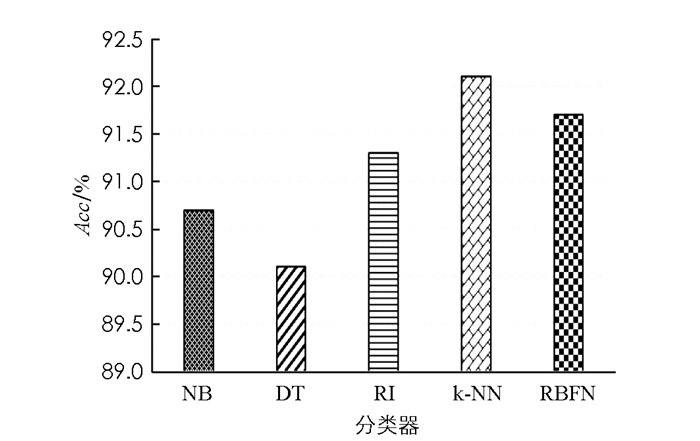
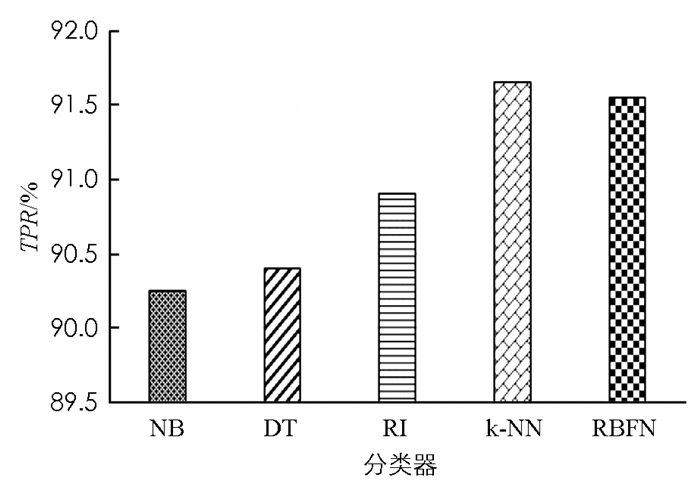
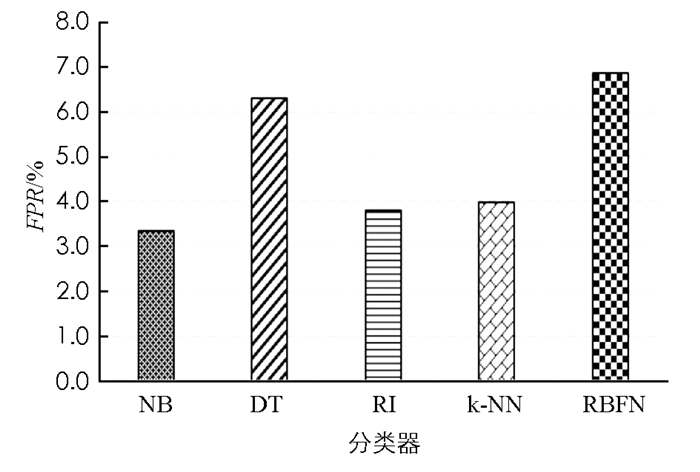
图 2-图 4给出了本文所提系统使用每个单独的监督分类器(NB,DT,RI,k-NN和RBFN)进行入侵检测的性能.
从图 2中可以看出,在Acc性能方面,k-NN分类器表现最好,其次是RBFN分类器、RI分类器和NB分类器,DT分类器性能最差,只有90.1%.
从图 3中可以看出,在TPR性能方面,k-NN分类器表现最好,其次是RBFN分类器、RI分类器和DT分类器,NB分类器性能最差,只有90.25%.
从图 4中可以看出,在FPR性能方面,NB分类器表现最好,其次是RI分类器、k-NN分类器和DT分类器,RBFN分类器性能最差,FPR高达6.87%.
由图 2-图 4所示的结果可以得到,k-NN分类器在Acc=92.05%和TPR=91.65%情况下优于其他分类器,而NB分类器在FPR=3.35%情况下具有最低值.
为了验证本文系统性能的优越性,将本文系统与现有系统进行比较,现有系统为2017年文献[10]中访问控制启用的数据库恶意检测系统和2016年文献[13]中关联规则数据挖掘的数据库入侵检测系统.分别从Acc,TPR和FPR 3个方面进行对比,结果见表 3.通过图 2-图 4中性能比较,本文系统选择kNN作为监督分类器进行入侵检测.
从表 3中数据可以看出,本文数据库入侵检测系统在Acc,TPR和FPR性能方面都优于其他两种现有系统,说明本文方法的有效性.
-
本文提出了一种新的数据库入侵检测系统,该系统引入基于密度的聚类OPTICS算法构建数据库用户配置文件,入侵检测方法包括两个阶段:训练和入侵检测.在训练阶段,对输入数据集的特征进行预处理,并将OPTICS聚类建立行为配置文件特征以及监督分类器的训练.在入侵检测阶段,每个传入事务都由集群模块处理,用于过滤合法模式,并将不一致和错误的事务传递给每个单独受过训练的监督模型以进行最终决策.使用随机模型进行大规模实验来验证本文系统的有效性,使用的分类器有NB,DT,RI,k-NN和RBFN.结果表明,本文系统能够使用不同机器学习技术进行入侵检测.另外,通过与现有数据库入侵检测系统对比,本文系统的性能优于其他系统,说明本文系统的可行性和有效性.