



 下载:
下载:

-
随着计算机图形学等技术的发展,计算机生成图像(Computer Generated images,CG)的逼真程度已经能让肉眼无法区分[1-2].这对那些致力于虚拟生成真实图片的行业很有利,如游戏、影视行业,但同时也会带来危害.例如,一个影视人能够修改一幅图像欺骗众人,这使得它变成了一个具有欺骗性的武器.因此,辨别一幅逼真的生成图像和一幅真实照片(Photograpgh,PG)具有重要的意义.图 1显示了真实(PG)人脸图像和生成(CG)人脸图像是很难辨别的.
近期的一些研究[3-6]已经涵盖了CG图像和视频检测.数字取证方法已经被提出.尽管如此,识别CG图像的技术能力仍然有很大的提升空间.文献[1]提出一种基于局部二进制计数模式的CG图像盲鉴别算法,通过颜色空间的转换、归一化直方图和支持向量分类,实现CG图像识别.文献[7]提出一种新的用于区分视频中计算机生成的人脸和人脸的取证技术.这种技术可以识别血流变化引起面部外观的微小波动,由于这些变化是由人体脉搏引起的,因此它们不太可能在计算机生成的图像中找到.该算法使用这种生理信号的缺席或存在来区分真实人脸图像和计算机产生的人脸图像.
文献[8]中提出通过局部二进制计数模式实现对计算机生成图像的识别,该算法对原始图像的颜色空间提取局部二进制计数模式矩阵,求取矩阵归一化直方图,最后采用支持向量机(SVM)进行分类.该方法能有效识别自然图像和计算机生成图像,但缺点是提取的特征维度过高.文献[9]提出一种基于局部三值计数的新颖算法来分类照片级逼真的计算机图形和照片图像.实验结果表明,该算法有效地降低了分类特征的维数,保持了良好的分类性能,缺点是当图像数据集过大时,用于训练的时间过长.
针对上述图像识别方法的问题,本文提出了一种改进的卷积神经网络方法实现计算机生成图像的识别,并在数据训练时引入迁移学习策略,能够降低特征维度和提高识别精度.本文将这个区分CG和PG图像问题建模为一个分类问题,对于给定的一幅图像,只需对这幅图像预测出一个对应的“CG”或者“PG”的标签.
全文HTML
-
本文使用Caffe深度学习框架来实现提出的方法,同时还在训练过程中进行数据增广以提高模型的泛化能力.数据增广包括2个主要的操作:输入图像水平翻转和随机平移.随机平移包括水平和竖直2个维度.
-
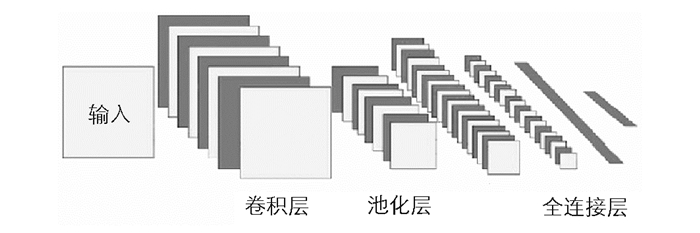
受猫视觉皮层电生理研究启发,有研究者提出卷积神经网络(convolutional neural networks,CNN)与普通神经网络的区别在于,卷积神经网络包含了1个由卷积层和子采样层构成的特征抽取器.卷积神经网络由3个部分构成:①输入层,②由n个卷积层和池化层组合组成,③由一个全连结的多层感知机分类器构成.
CNN由输入层、卷积层、激活函数、池化层、全连接层组成,主要通过卷积层和池化层对输入图像进行处理,其结构见图 2.
卷积层用来提取图像特征,在这一层,卷积神经网络通过2个特有方式降低参数数目:①局部感受野,②权值共享.卷积层越多,特征的表达能力越强,第l层卷积层的表达式为
其中xjl(j=1,2,…Nl)表示该层的特征图,Mj为输入层感受野,kijl为卷积核,bjl为偏置,f(·)表示激活函数,一般激活函数有sigmoid函数、tanh函数和RELU函数,本文使用RELU函数作为激活函数,表达式为
其中i表示隐藏单元个数,w(i)表示权值.
池化层连接在卷积层后面,池化层的对象是特征图的局部区域,这样做能够使特征具有一定的空间不变性.具体过程为:对于卷积层得到的输入图像的邻域特征图(feature map,FM),使用池化技术,对FM降采样得到新的特征,这一步减少参数,降低特征维度,并且保证了特征具有空间不变性的能力.池化操作中最常使用的方法有随机池化(stochastic-pooling)、最大池化(max-pooling)和均匀池化(mean-pooling).
mean-pooling,即对邻域内特征点只求平均;max-pooling,即对邻域内特征点取最大;stochastic-pooling则介于两者之间,通过对像素点按照数值大小赋予概率,再按照概率进行降采样.
本文采用最大池化操作,表示形式为
其中,f(·)表示激活函数,μjl表示权重系数,p(·)表示池化操作,bjl表示偏置.最终将输出特征作为输出层Softmax回归的输入,通过损失函数实现对CGs和PGs的识别.
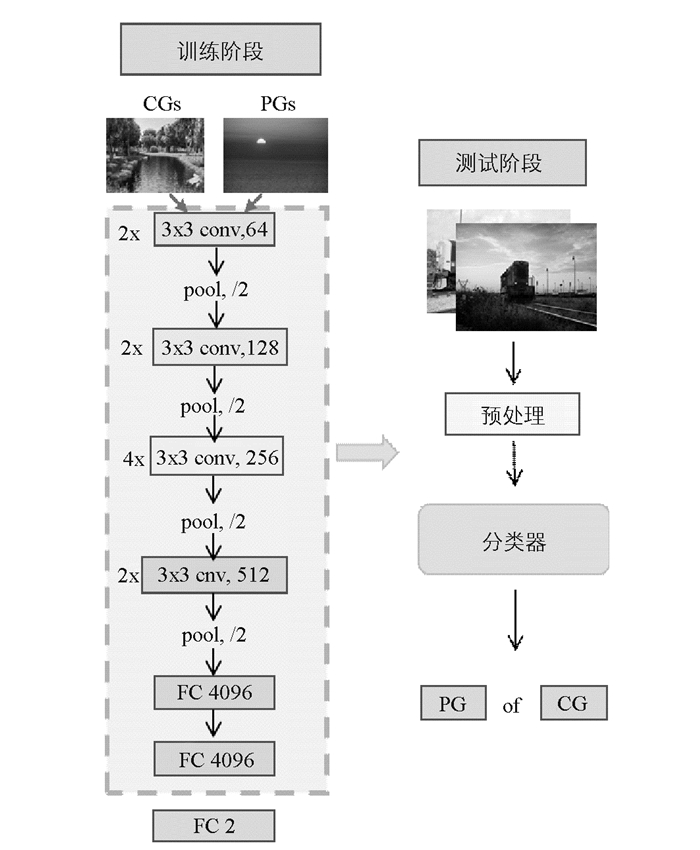
对于卷积神经网络架构,本文选用在ImageNet中取得成功的VGG19网络结构为基础网络,整体的模型框架如图 3所示. VGG19网络结构主要的贡献是采用了一个非常小的3x3的卷积核,通过将深度CNN网络增大到16~19层,大大提高了现存的性能.
-
基于卷积神经网络方法需要大量的训练数据,这导致训练需要很长的时间,因此迁移学习[10-11]得到了关注.这项工作说明:任何训练在自然图像上的深度神经网络都表现出一种奇怪的现象:从第一层学习到的特征与Gabor滤波器相似.在许多类型的数据集和任务中都是通用的.如果最后一层由特定的数据集训练,这些特征可以从一般转换到特定情况.
迁移学习就是利用之前学到的知识来帮助完成新环境下的学习任务,之所以在卷积神经网络中引入迁移学习是基于以下原因:目前大多数成功的模型都是依赖于大量的有标签数据,而很多学习任务很难获得大量的有标签数据,对于每一个任务都从头开始训练,成本非常高.迁移学习定义:给定源域(source domain)D_s和对应的任务T_s,给定目标域(target domain)D_t和对应任务T_t.迁移学习即是在D_s≠D_t或T_s≠T_t时,利用D_s和T_s中的知识来帮助学习D_t上的预测函数f_t(·).
对于Domain(域),其定义为
其中χ为特征空间,P(X)为边际概率分布,X=(x1,x2,…xn)∈χ.对于Task(学习任务)定义为
其中y为标签空间,f(·)表示通过训练集{xi,yi}来训练,当用来预测X的标签时,f(·)可以表示为P(y|X).
迁移学习代表了转移从一个问题上学习到的知识到另一个问题的可能性.一般来说,迁移学习过程包括传递(源)神经网络的参数,根据特定数据集上的特定任务,将这个网络预训练为另外一个(目标)网络,这个目标网络有一个不同的数据集来解决另一个不同的问题.迁移学习简单且成本效益很高,一方面迁移学习节省了很多训练时间和大量的计算资源;另一方面如果从零开始训练,就需要大量的训练图像,然而一些特定任务的数据集图像通常不是很大.迁移学习很好地解决了这两个问题.因此,本文通过利用预训练的VGG-19网络进行迁移学习.
迁移学习策略取决于多种因素,但最重要的2个是数据集的大小以及新数据与原数据集的相似度.谨记网络前面几层的CNN特征更加泛型(generic),在后面几层中更加具有数据集特定性(dataset-specific).通过持续的反向传播来微调预训练CNN的权重,达到CNN最佳性能.
-
在本文的工作中,区分CGs和PGs的问题被建模为一个分类问题. Softmax损失函数是在基于卷积神经网络的方法中最常用的损失函数,它是一个二元逻辑回归到多元的推广,Softmax损失函数的形式如公式(6)或公式(7)所示.其中fj表示第j个元素的分数向量,Softmax函数如公式(8).
Softmax损失函数源于交叉熵损失函数,用于评价一个真实类别的分布p和一个估计分布q之间的关系,如公式(9)所示.
1.1. 卷积神经网络框架
1.2. 迁移学习
1.3. 损失函数
-
在2个图像数据库上对本文方法进行实验,数据库1是自行建立的数据库,数据库中2 000张计算机生成图像和2 000张真实图像,这些图像都以JPEG图像格式压缩,大小介于12 kb到1.8 Mb之间,图像库内容分类范围广,包括人物、风景、动物和建筑等. CG图像中的400幅来自Columbia University CG库,1 600幅来自国内外的CG网站;PG图像中的1 600幅来自Columbia University PG图像库,400幅来自其他PG图像库.数据2是DSTok数据集,包括4 850张CG图像和4 850张PG图像,这些图像涵盖了汽车、动物以及户外等多个领域,都以JPEG图像格式压缩,大小介于12 kb到1.8 Mb之间.一些图像如图 4所示,数据集里的图像都被缩放为224×224,第一行为PG图像,第二行是CG图像.
使用五折交叉验证协议,展示本文所有实验的平均精度.本文设置初始学习率为0.001,衰减系数为每迭代2万次下降0.1倍.本文设置训练批次大小为每批次64张图像,并且权重衰减系数设为0.000 5,优化方法为SGD (Stochastic Gradient Descent),动量因子设为0.9.
实验中训练样本和测试样本的比例是4:1.最后一层全连接softmax网络层会影响整个随机初始化网络的训练,为了减少影响,在进行微调整个网络之前,先对最后一层进行了预训练.在DSTok数据集上对本文方法进行实验,实验结果见表 1.
由表 1中数据可知,使用迁移学习和微调来进行训练的模型取得了最佳性能.而迁移学习模型的性能也优于不使用迁移学习训练的模型,由此可以说明迁移学习和微调策略具有有效性和鲁棒性.表 2为本文模型与现有最先进的方法在图像数据库1上的对比结果.
表 2表明本文所建立的模型在最先进的模型中具有竞争力.在自建图像数据集上,本文的平均精度达到了92%,这些结果证明本文的迁移学习技术和微调策略比已有方法性能更好.
-
本文为了解决计算机生成图像与真实照片识别率不高的问题,提出了一种微调迁移学习的卷积神经网络方法来实现计算机生成图像检测,该方法采用了VGG-19网络架构,并在数据训练时引入迁移学习策略,节省很多训练时间和大量计算资源,提高工作效率和识别精度.实验结果表明,在自建图像数据库和DSTok数据集上,相比已有方法,本文提出的模型取得了更好的识别精度,说明本文方法的可行性与有效性.