


 下载:
下载:
-
开放科学(资源服务)标识码(OSID):

-
增程式汽车较好解决了续驶里程和污染物排放问题,是实现“碳达峰、碳中和”的重要抓手. 增程式汽车的结构相对复杂且具有多个工作模式,对动力系统进行精确控制以便提升车辆的节油率是当前的研究热点[1].
目前,增程式电动汽车的能量管理策略(Energy Management Strategy,EMS)主要分为基于规则的EMS和基于优化的EMS[2-4]. 常见的基于规则的EMS有恒温器控制、发动机多工作点控制、功率跟随控制. 如Banvait等人提出在车辆启动时电池给发动机提供助力使其工作点落在高效区,以改善车辆燃油经济性[5]. 不足之处是该方法仅适用于特定的工况下,局限性较强. 基于优化的EMS主要有动态规划[6-7]、庞特里亚金最小值原理[8]、模型预测控制[9-10]、等效能耗最小[11]、人工智能技术等[12-15]. 如Lin等人利用动态规划设计了最优EMS策略,并在NEDC工况下验证了该方法的有效性[16]. 但该方法往往需要事先获得行驶工况信息,一般不能实现即时控制.
鉴于基于规则的EMS和基于优化的EMS都存在不足[17-18],因此有必要探索新的方法. 人工智能是模拟、延伸和扩展人的智能的一门技术科学,它擅长于解决决策、控制、优化系统中的复杂问题. 本研究将其中的强化学习方法应用于增程式汽车能量管理问题形成基于强化学习的EMS,并与基于规则的EMS在相同条件下进行对比仿真,以期研究该方法的节油效果.
全文HTML
-
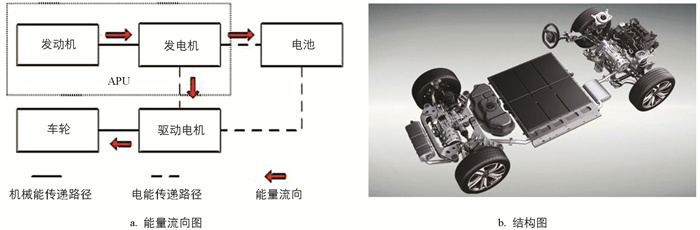
增程式电动汽车按照其增程器和动力电池组的工作状态可将该车的工作模式划分为:完全纯电(驱动电机能量供给仅由电池)、发电补电(电池提供能量给驱动电机)、充电驱动(增程器提供能量给驱动电机,且为电池充电)、发电驱动(增程器只给驱动电机提供能量)、再生制动等主要混动工作模式. 其能量流向图与结构图如图 1a、b所示.
汽车运动模型:汽车行驶时,设汽车驱动力为F,则汽车动力学方程可表示为:
式中:ρ0是空气密度,CD表示空气阻力系数,A是汽车迎风面积,V表示车速,m是汽车整备质量,g表示重力加速度,k是汽车滑动阻力系数,a为汽车的加速度,θ为坡道坡度. 而汽车驱动力F又可表示为
式中:Tw为增程系统输出的轮边扭矩,r车轮半径.
发动机模型:采用准静态模型,定义发动机的瞬时燃油消耗C0,一段时间T内的燃油消耗定义为
动力电池组模型:采用内阻模型,电池组放电功率Pa与电池荷电状态值SOC微分形式可表示如下
式中:V0是电池组开路电压,r表示电池组内阻,Q是电池组容量,I是电池组放电电流.
-
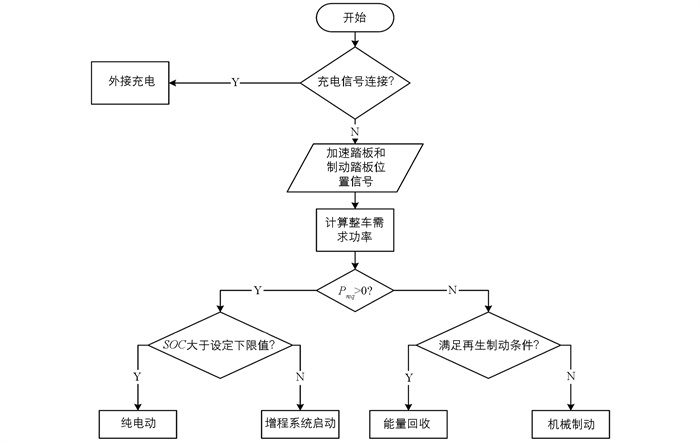
基于规则的EMS整体流程主要包括以下几个阶段:①判断是否有外接充电信号连接;②根据加速和制动踏板信号计算整车需求功率;③若需求功率Preq大于零,根据动力电池SOC值的大小,判断整车是进入纯电动模式还是增程模式,且增程器输出功率由当前车速与整车控制器VCU计算的请求功率查表;④若需求功率Preq小于零,判断是否满足再生制动条件,从而选择再生制动或者机械制动,具体如图 2所示.
增程器若启动,VCU根据当前车辆加速度需求、附件消耗功率、电池组当前允许充电功率等计算请求当前整车需求功率,再结合当前车速,查询表 1得到请求增程系统输出功率.
尽管该EMS对于特定车型直观且有效,但其输出的增程系统功率需根据工程经验进行标定,且不同车型需要重新设定,会耗费许多的人力资源与时间成本. 此外,标定的结果也存在主观性较强、精确性较差现象. 由于存在上述问题,这里有必要尝试研究基于强化学习的能量管理策略解决这些问题.
1.1. 增程汽车模型
1.2. 基于规则的能量管理策略
-
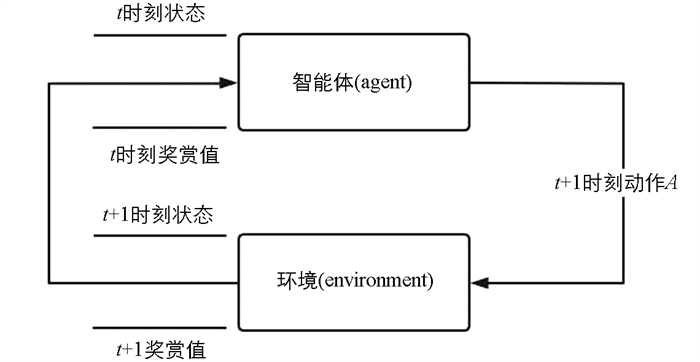
强化学习就是程序或智能体(agent)通过与环境不断地进行交互,学习一个从环境到动作的映射,学习的目标就是使累计回报最大化[19-21],结构如图 3所示.
式中系统t时刻的状态St,at是智能体t时刻的动作,rt是智能体t时刻的奖赏值,St+1是系统t+1时刻的状态,rt+1是t+1时刻的奖赏值. 强化学习方法应用场景中,对象一般具有序惯性,通过分析发现强化学习方法适用于增程汽车能量管理问题.
-
为将强化学习方法应用于研究对象,先简化REEV能量管理系统为一个非线性离散系统,可表示为
式中S(t+1)是t+1时刻的状态值,t表示采样时刻,N是采样终止时刻,S(t)是t时刻的状态值,u(t)是t时刻的控制量. 状态变量S(t)从属有限的状态空间,控制变量u(t)从属有限的控制空间.
-
将扭矩需求T、当前车速V、动力电池荷电状态SOC、及行驶里程d选定为状态变量S并对所选状态值按采样时间离散,设定扭矩需求和车速上下边界为0到520 N·m、0至132 km/h,行驶里程设定为行驶累计里程与总里程的比值,其范围为[0, 1],状态变量S为
-
通过上面的分析,选择增程器的输出功率Pr作为动作空间A的控制变量,其范围为0到80 kW,动作个数按采样时间数离散.
-
设定即时奖赏值r(s,a)为所选时间步长内燃油消耗与电量消耗的总花费如下
式中C0是前面定义的瞬时燃油消耗率,t是采样时刻,Δsoc是该步长内的电池组SOC变化量,f(Δsoc)为电量和油耗的换算关系函数.
-
本研究采用贪心策略来来制定选择动作的规则,动作更新公式如下
式中ε为探索率,本文设置的探索率会根据训练次数进行变化,A为动作空间.
-
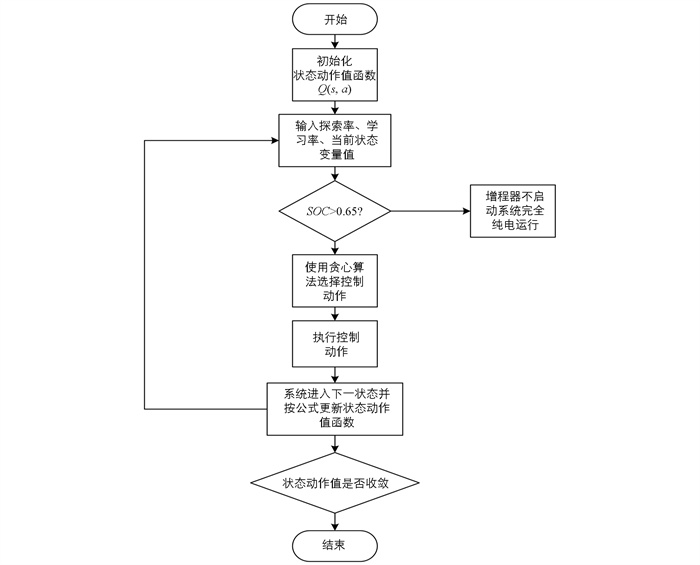
该部分状态动作值更新方式采用Q学习算法,该算法的状态动作值函数Q(s,a)直接逼近最优状态动作值函数. 状态动作值函数Q(s,a)更新公式如下
式中rt为在t时刻的状态选择该动作的奖赏值,Q(st,at)为在t时刻的状态动作值,Q(st+1,at+1)为在t+1时刻的状态动作值,γ为学习率. 状态动作值函数的具体更新流程如图 4所示.
基于强化学习的EMS中,选取车速、扭矩等参数作为状态变量,在每一个时间节点t,车辆产生一组控制动作at并观察即时的奖赏值rt,并将一串控制动作映射到状态的函数. 考虑环境的随机输入,如驾驶员的需求转矩及需求车速,即时花费和下一状态都难以预测,所以采用免模型的Q学习来实现能量管理控制. 对比前种方法可知于强化学习方法的EMS易于在仿真环境中得到控制策略,面对不同车型的不同模型参数时也具有可扩展性.
2.1. 强化学习
2.2. 强化学习的模型对象及能量管理策略
2.2.1. 状态
2.2.2. 动作
2.2.3. 奖赏值
2.2.4. 动作更新选择
2.2.5. 状态动作值更新选择
-
为验证上述两种控制策略燃油节省的效果,在MATLAB/Simulink与AVL/Cruise进行仿真,选取某款增程式插混汽车为研究对象,其部分参数如表 2所示.
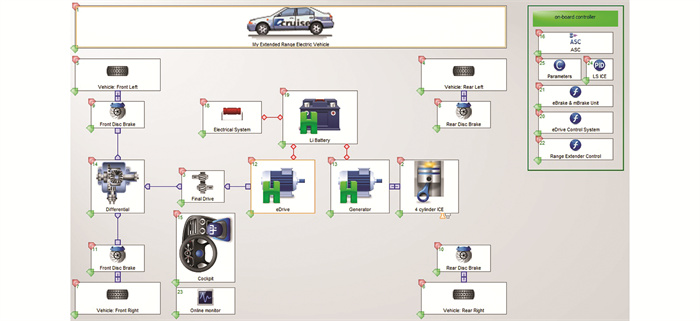
在AVL/Cruise主界面搭建整车物理模型,包括发动机、发电机、动力电池组、主减速器、车轮等组件,并对组件按表 2进行参数设置,如图 5所示.
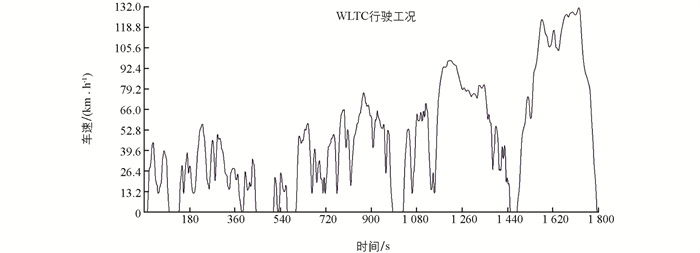
仿真选择在WLTC(World Light Vehicle Test Cycle)工况下进行,WLTC测试循环总共持续1 800 s,累计行驶里程23.3 km,测试当中车辆的最高时速提升至131 km/h,平均速度约为47 km/h,整个过程如图 6所示.
-
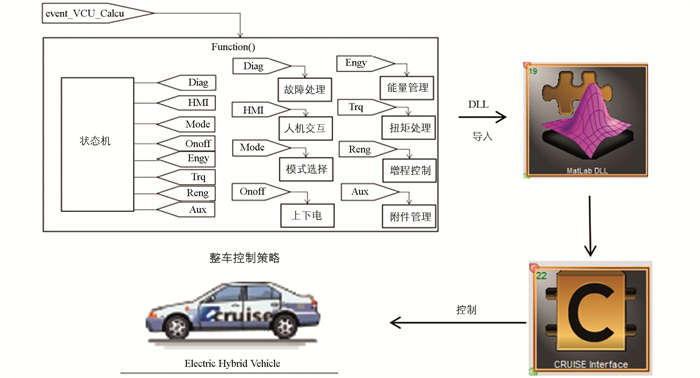
在MATLAB/Simulink中建立基于规则的整车的控制策略模型后,将该模型嵌入到AVL/Cruise的整车模型中,进行AVL/Cruise和MATLAB/Simulink的联合仿真(图 7). 即利用Simulink中的Real Time Workshop工具,将Simulink模型转化成DLL文件,在AVL/Cruise中选择MATLAB DLL接口模块并将生成的DLL文件导入. 此外,需要在CYCLE RUN任务中选择WLTC工况作为测试工况.
-
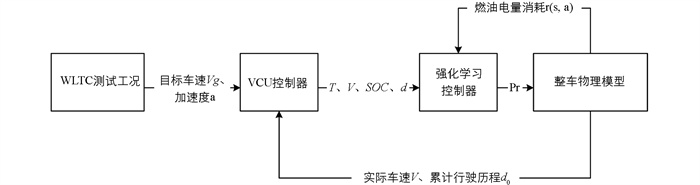
如图 8整个仿真的过程是首先将WLTC测试工况输入的目标车速和加速度信息传给VCU控制器,VCU控制器一方面接收输入的信息和整车模型反馈的实际车速、累计里程,另一方面将计算后得到的需求扭矩T、电池SOC、车速V、剩余里程d作为状态变量输入给强化学习控制器,强化学习控制器负责迭代训练并产生控制动作,且会根据燃油电量消耗更新输出的控制动作,训练完成后选择最优结果得到强化学习控制策略.
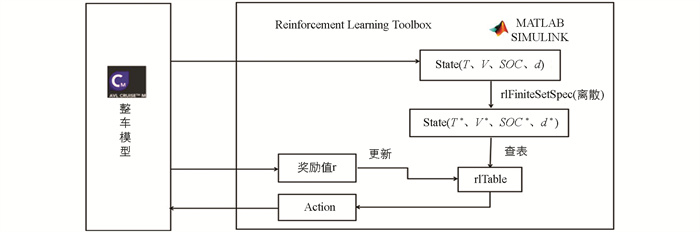
建立强化学习控制策略时,选择Matlab中强化学习工具箱(Reinforcement Learning Toolbox)来完成,如图 9所示. 首先初始化Q值,再通过rlNumericSpec函数对状态进行离散,并将状态(State)、动作(Action)和Q值存储在三维数据表格rlTable中,并根据表格选取最优动作,与整车Cruise模型交互,并基于即时奖励函数r,按式(10)更新Q值. 重复上述步骤完成Q学习过程.
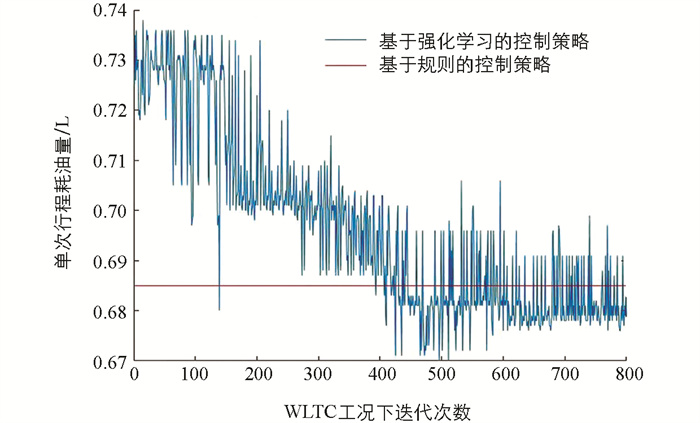
基于强化学习的控制策略需要经过一定次数的训练才能获得稳定收敛状态动作值,在WLTC工况下每一次行程便是一次完整的训练. 为了加快收敛的速度,在训练过程中并未采用固定的探索率εi和学习率γ,而是在训练的前期选择较大的探索率和学习率,随着训练次数的增加再逐步减小,最终获得良好的收敛. 探索率及学习率的设定为
由图 10可以看出,随着训练次数的增加,每次行程的花费值渐渐趋于收敛,并在第513次训练时有最小耗油量0.675 L.
-
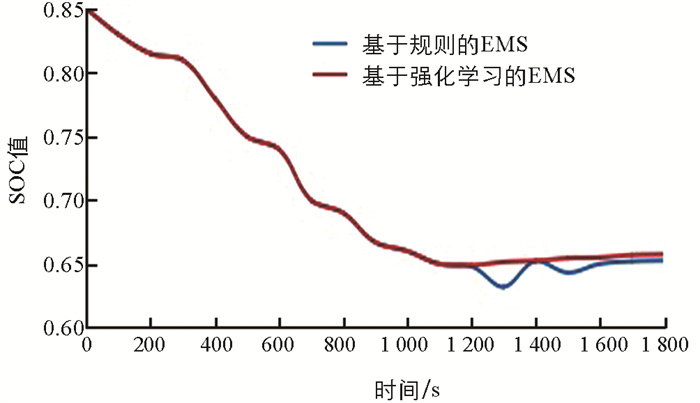
图 11表现了训练完成后,WLTC工况下使用两种能量管理策略仿真后SOC的轨迹. 测试的初始阶段,因为增程器未启动,电池组提供驱动所需功率,而相同测试对功率需求一致,故SOC轨迹在这段时间重合. 当SOC下降到0.65时,增程器启动. 此阶段基于规则的EMS电池SOC轨迹上升的总体来说更快,表明基于强化学习EMS策略在增程器启动后选择输出的功率平均值更小.
为更直观地体现燃油节省率,下面将WLTC循环的电耗统一折算为油耗进行对比,电池SOC值与油耗的换算公式(根据GB/T 37340-2019《电动汽车能耗折算方法》)如下式所示:
式中:Fc表示燃油的消耗量;E为电能消耗;FE是能量折算因子,92号汽油为0.1161.
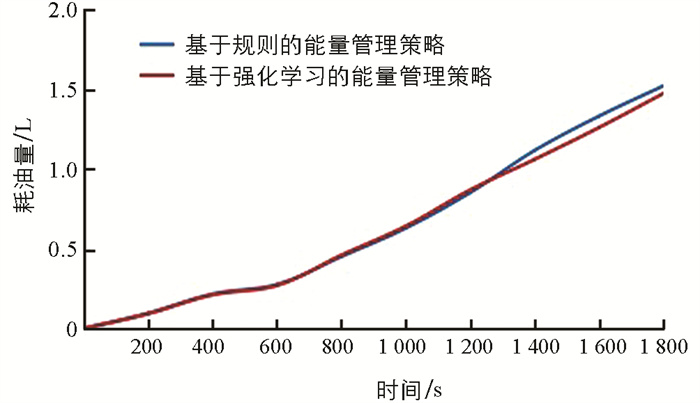
经训练后,基于强化学习的最优能量管理策略与基于设定规则的能量管理策略在WLTC工况的运行燃油消耗(电量消耗折算后)对比如图 12所示.
WLTC工况下基于强化学习的能量管理策略与基于规则的能量管理策略能耗结果对比如表 3所示.
上表中将电池组SOC值变化折算成油耗得到WLTC工况下等效油耗,可以看到:跑完整个WLTC循环,基于规则EMS油耗为0.719 7 L,而基于强化学习EMS油耗为0.696 2 L. 折算后,若设基于规则的能量管理策略能耗节省率0%作为对比基准,基于强化学习的能量管理策略比基于规则的能量管理策略能耗节省率提高了3.2%.
图 11中SOC轨迹的变化表征了电池组充电功率的变化,也间接反映了增程器启动后两种策略下的增程器输出功率变化,计算后可知整个WLTC循环过程中,基于强化学习EMS增程器启动时输出功率平均值小于基于强化学习EMS增程器启动时输出功率的平均值. 因油耗的来源是增程器中发动机的运行,更小的增程器输出功率意味着更低的燃油消耗.
基于规则的增程器功率输出表来源于人工标定,其值设置的偏大,会导致电气传输过程中,线路电流会偏大,内阻一定时能量传递损耗的越多. 而基于强化学习的EMS在离线多次迭代后找到了当前采样时刻下更合适的增程器功率输出值,从而有更少的能量消耗.
3.1. 仿真车型参数与条件
3.2. 能量管理策略仿真
3.2.1. 基于规则的能量管理策略仿真
3.2.2. 基于强化学习的能量管理策略仿真
3.3. 仿真结果分析
-
根据研究对象的结构建立模型并进行仿真,结果表明基于强化学习的能量管理策略比基于规则的能量管理策略能量消耗率减少了3.2%. 因此,在WLTC循环工况下基于强化学习的能量管理策略是一种相对更优的能量管理策略. 考虑到车辆实际运行的工况比模型要复杂,故还需进行实车测试以便检验能量分配策略的可靠性. 但基于强化学习方法训练得出的EMS可为工程上最优增程器输出功率标定提供范围,该范围下将显著减少工程人员标定工作量.