





-
随着医学领域信息资源的日渐丰富,消费者需要专门解决方案来适应健康相关信息的异质性和特点[1].在线医疗保健社区可以为用户提供远程医疗支持,既给用户带来了便利,又有助于积累大量的数据.同时,与数据量的爆炸性增长相比,医生的数量相当有限[2].医疗问答可将患者提出的问题进行整合、分析,利用机器学习算法训练智能问答模型,再利用其自动解答患者的疑问,从而减少医生的工作量.
本文采用知识问答模型构建医疗问答系统解决上述问题,知识问答模型不同于传统的基于文档的问答模型. DBQA(Document-based question answering,文档问答系统)采用自然语言表达方式进行提问,返回包含着答案的文档,用户需要阅读已存在的文档发现相关答案.而KBQA(Knowledge Base Question Answering,知识问答系统)通过理解问句的意图,利用人工定制的句法解析树,将自然语言处理为Select语句,查询数据库可直接返回答案.所以,医学知识问答模型需要人工对句法解析树不断添加新词汇和映射机制,成本过大.近些年基于短文本匹配的知识问答模型逐渐发展起来,但我国的医疗知识问答模型仍存在着一些挑战和限制.首先,我国还没有现有的中文医疗知识问答库.其次,针对中文领域的医学词库的构建尚不成熟,没有较好的中文分词工具处理专业领域文本.由于医学文本的分词效果不佳,导致现有研究诸如疾病预测或医疗问答问题中利用深度学习模型很难提取到医学文本的特征.
针对以上问题,本文通过各大医疗网站爬取大量医疗问题与疾病常识,将疾病常识存储为“实体—关系—实体”形式的医疗知识图谱[3].根据医疗问题和其对应的医疗关系,构建“问题—关系”一对一的医疗知识问答库.本文还利用LCN模型提取问题特征,LCN中的格子可以提取问句中的所有分词情况并把它们转为特征向量,充分概括问句的特征信息,解决因为分词工具不成熟所导致的特征提取模糊.基于LCN的问答模型将医疗问答转换为一个选择最佳关系的文本匹配问题,并根据匹配提高问题与标签答案的相似度从而构建问答模型.当新问题输入时,根据新问题的特征,选取相似度最高的对应答案.无需人工定制句法分析树,节省人工成本.最终通过实验,LCN模型准确率可达89.0%,比同类知识问答模型准确率高出2%.
医疗知识问答模型需要先构建医疗知识图谱,近年来多位学者利用不同的方法构建了医疗知识图谱,并结合知识图谱解决医疗问题. Li X等利用膝骨关节炎患者的电子病历文本构建医学知识图谱[4],以支持诸如知识检索和决策之类的智能医学应用,并促进医学资源的共享. Chai X Q提取生物医学实体之间的关系以构建生物医学知识图谱[5],并利用知识图谱嵌入方法将知识图谱中的实体和关系转换为低维连续向量.最后,将已知的病理疾病关系数据用于训练双向长短期记忆网络(Bi-STLM)的疾病诊断模型. Yuan J B等利用弱监督的方法提取医疗文本中的实体与关系词构建医疗知识图谱[6].现有研究主要利用自然语言处理的方法抽取电子病历信息构建知识图谱,抽取到的实体或关系存在部分错误.本文利用爬虫方法对于医疗网站中的实体和关系进行抽取,并存储于Neo4j数据库中,有着较高的准确性.
构建知识图谱成功后,需要将医疗问题和其对应的知识进行匹配,并计算两者的相似度构建医疗知识问答模型.现有的医学问答系统主要分为文本问答系统和知识问答系统.近些年,文本问答系统已有多位学者进行了研究,Liu H I等[7]提出了一种基于CNN的自我注意嵌入式模型的中医问答系统,利用LSTM分析问题特征,并通过CNN的卷积核获取特征图,最终通过CNN的池化层提高模型的准确性. Nguyen V等[8]利用文本推断的方法识别具有相似语义的问题,改进了自然语言推理和问题蕴含的方法,进一步完善了医学问答,提出了结合开放领域和生物医学领域以改善语义理解和语义消歧的问答系统MEDIQA. Zhang S等[9]利用答案匹配的方法,提出了一种端到端的字符级多尺度卷积神经框架cMedQA,使用CNN从不同比例的问题或者答案中提取上下文信息,进而通过相似度的计算完成医疗问题与答案的匹配.
文本问答系统返回非结构化文本答案,是概念性片面化的文本,更适用于回答“为什么会患病”之类的问题,需要人们从散乱的答案之中进一步分析获取自己想要知道的信息,不能直接满足人们的需求.然而现有医疗问答系统则会直接通过分析医疗问题,从知识库中获取和问题相关的实体词,并通过自然语言处理方法构成包含答案的简短语句,人们可从系统返回的答案中直接获得所需信息,更适用于“所患什么疾病” “吃什么药”等问题的答案,显然知识问答系统更适用于医疗领域.
现有的医疗知识问答系统对医疗知识普及以及医生的临床用药决策有着重要的意义和参考价值,近年来人们提出了利用神经网络方法计算问题与答案的相似度. Zou Y等[10]以中医药领域为基础,以中医药网站《本草纲目》的开源数据为数据源,建立了中药知识图谱,根据知识图谱实现自动答疑和辅助处方的功能. Zhu W等[11]提出问答系统Dr-KGQA,利用bilstm-crf提取医学文本中的实体和关系,构建医疗知识图谱,并使用text-CNN将医疗问题和图谱中的关系词进行匹配,构建问答模型. Sadid A H等[12]基于T-Know中医药知识图谱服务系统,抽取电子病历中的三元组,并在知识图谱的基础上,开发了用于单个问题理解和多轮对话的深度学习算法. Zhang Y Y等[13]构建了一种多模态知识感知层次注意网络MKHAN,通过利用多模态知识图谱解决医学问题,通过组合实体结构、语言学和视觉信息来生成路径,并通过利用MKG路径中的顺序依存关系来推断问答互动的基本原理.
基于相似度方法采用了相对统一的RDF表示知识图谱,并且把语义理解的结果映射到知识图谱的本体后生成SPARQL查询解答问题系统,通过本体可将用户问题映射到基于概念拓扑图标识的查询表达式中,相当于知识图谱中的子图,基于相似度算法不断完善对用户问题特征的提取,以便于找出问题到知识图谱子图的最合理映射.上述方法虽然很全面地抓取了问题中的信息,但并未解决针对专业领域的分词困难问题,Lai Y X等[14]提出了LCN模型,通过单词格抓取语言问题中的多粒度信息提高匹配的准确性,本文利用LCN的多粒度抓取特征方法解决医疗专业分词困难的问题,进而训练医疗知识问答模型.
HTML
-
构建医疗知识问答模型共分为4步:第一步,利用某三甲医院提供的15 000份电子住院记录,基于Glove算法训练医学词向量.第二步,通过医疗网站获取大量医学关系三元组,构建医学知识图谱,并提取知识图谱中的关系名词,结合医学词向量构建关系向量.第三步,利用医疗网站获取大量医学问题,构建“问题—关系”数据库,基于此数据库,利用本文提出的LCN模型训练医疗知识问答模型.第四步,根据已构建的问答模型,向问答模型输入新的医学问题,返回模型中与新问题特征相似度最高的答案,完成医疗问答.整体流程如图 1.

-
我们采用某三甲医院提供的15 000份电子住院记录作为词向量训练的数据,本文所用的电子病历由多个科室的病患住院记录组成,病例的科室分布如图 2.
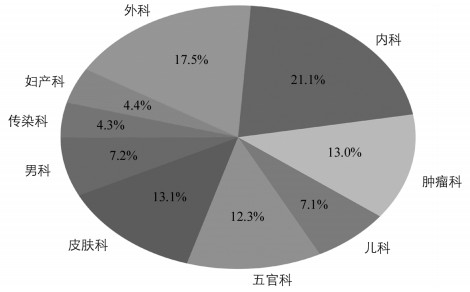
图 2显示,外科和内科病人所占比重较大,因为现多数常见疾病如“感冒” “咳嗽”被划分到内科之中,“颈椎病”等被划分到外科之中,所以医学词向量词库中多数为外科和内科疾病的有关词语.肿瘤科、五官科、皮肤科数量仅次于内、外科,妇产科、传染科和儿科中的疾病种类比较少,所占病例比重也较少.本文选取了外科中的骨伤科作为样式,如图 3.

电子住院记录涵盖了病人的性别、年龄、所在地等特征信息,病人主诉是病人自述自身的症状或者体征.现病史为病患发病的最初症状,即从病患发病至本次就诊之间的身体情况,图 3中患者的现病史表明近期在家中摔倒,并感觉到下肢疼痛、麻木,并伴随着胸背疼痛.既往史为患者过去曾经所患的疾病以及身体状况.个人史和婚育史为患者的个人家庭以及生活习惯.病人主诉以及病史对医生初步诊断有着辅助作用.病历中主诉、现病史包含了大量该领域的专属医学名词,本文通过利用jieba分词工具对病历文本进行分词,并进一步使用Glove预训练模型训练词向量.
采用Glove[15]模型训练医学词向量,定义X为共现词频矩阵,其中元素Xi,j为词j出现在词i环境的次数,“环境”为词i周围不超过10个词的范围.
我们定义$X_{i}=\sum\limits_{j} X_{i, j}$,Xi为所有词出现在词i环境的次数,求得词k出现在词i环境的条件概率Pi,k,
给定矢量wi,wj,wk可计算损失函数J,
由于复杂度过高,利用wki,wkj和wkk的矢量特性进行相减和内积,得到
并进行指数运算
将公式1带入
将Xi拆分为两个标量bi,bj
得到最终损失函数J
将调试所得的词向量wi集合构建医学词向量库T,且wi∈T.
-
本文利用爬虫手段,对医学网站中的疾病实体和实体间关系进行抽取.设知识图谱表示为G,图中节点与关系定义为
M表示节点集合,B表示边的集合.每2个节点和1个关系组成1个三元组z,定义为
定义lh为头实体,lt为尾实体,lr为实体关系,从语法角度解释为
以(病毒性感冒,并发疾病,鼻炎)为例,设“病毒性感冒”为头实体lh,“鼻炎”为尾实体lt,“并发疾病”为实体间关系lr,知识图谱样式如图 4.

图 4的左半部分,病毒性感冒的用药为川贝枇杷糖浆和小柴胡颗粒,该病的检查方法是血常规,传染方式为呼吸道传染,症状为鼻塞和流鼻涕.还可看出,病毒性感冒和鼻炎为并发疾病,图的右半部分显示了鼻炎的用药、传染方式等属性.通过遍历词向量库T,获取图谱中的关系词向量fan,
-
针对CNN无法提取不同分词下的语义特征问题,本文采用LCN模型,LCN模型引入了词格,词格包含了一个单词针对于不同分词的所有可能的上下文,如图 5.

LCN有效地避免了专业领域分词不准确带来的弊端.由于每个词格包含了一个词的不同上下文,所以会产生多个特征向量,采用合并法处理多个特征向量,如图 6.

针对于任意一个晶格B=〈V,E〉,V是问题中所有可能出现的字词的集合,E是相邻两个字词组成的边的集合,设问题中字w处的晶格核尺寸为n,通过卷积的操作,该晶格输出的特征向量可以表示为
其中softmax是激活函数,vwi是与该层中单词wi相对应的输入向量,同时vwi∈T,(vw1:…:vwn)表示合并不同词向量,Wc为卷积核参数矩阵,bc为偏置向量.对于多个特征向量,通过池化求得表示向量
其中,ti为固定参数,βi为池化操作的门控权重,n为词格所承载上下文范围,通过调节βi和n可控制表示向量,fqu为所求得的问题表示特征向量.将fqu带入到残差链接神经网络计算评分s,
其中yi为第i个词所对应的标签,L为交叉熵损失.
综上所述,本文提出了基于LCN的问答模型,如图 7.

1.1. Glove词向量训练
1.2. 医疗知识图谱构建
1.3. 构建LCN问答模型
-
本文利用爬虫手段,抽取寻医问药网、39健康网等中国医疗网站中的结构化数据与医学问题,网站如图 8.

图 8上半部分中,“鼻旁窦支气管综合征”为疾病主体,“并发疾病——支气管扩张” “传染方式——无传染性”是每个疾病都拥有的相关属性和其对应的属性值,利用数据爬虫的方法,抽取网站中的疾病主体及其相关属性和属性值.利用1.2节中的知识图谱构建方法,构建“(主语,谓语,宾语)”样式的知识图谱,例如“(鼻旁窦支气管综合征,并发疾病,支气管扩张)”.
图 8下半部分中,通过爬虫法爬取医疗问题,例如“鼻旁窦支气管综合征有哪些并发症”,由人工制定规则的方法,将问题与正确关系的三元组一一对应,并组合成我们的数据集,如表 1.
我们利用机器学习中较为传统的二八定律法则[16]划分数据集,将训练集和测试集按照4:1的比率划分,如表 2,第2列和第3列为不同数据部分所对应的问题和关系的数量.
训练集中有24 000个问题和132 000个三元组,测试集有6 000个问题和36 000个三元组,每个问题仅包含1个正确三元组,若干个候选三元组,其中候选三元组包括1个正确答案,其余为错误答案,用于负采样.本文共爬取有3 000种疾病,5 000种症状,每个疾病或症状占有大约10~15个三元组.
-
对于KGQA,每个问题仅1个正确关系三元组,因此仅使用准确率(ACC)和MRR计算,
TP,TN,FP,FN分别表示正类预测为正类数、负类预测为负类数、负类预测为正类数、正类预测为负类数.
MRR是国际通用的搜索算法的评价机制,
其中|Q|为搜索总个数,ranki是第i个搜索结果,即把标准答案在被评价系统给出结果中的排序取倒数作为它的准确度,再对所有的问题取平均.
-
本文使用Glove算法对医学词向量进行训练,设定Glove模型的中心词环境大小为10,词向量长度为50,训练过程经过100词的调整和微调,最终获得训练后的医学词向量.本文所构建的词向量库,包括15 000个词向量,5 000个字向量.
-
LCN模型中,定义训练集批处理量train_batch_size为64,测试集批处理量test_batch_size为32,全连接层采用dropout为0.3,激活函数选用Relu,learning_rate为0.8,衰减因子为0.9,优化器选用Adam.
-
LCN模型主要解决了因分词导致的模型提取特征模糊问题,所以为了验证模型的有效性,首先与不同分词工具做对比实验.本文分别使用CNN结合HanLP,jieba,FudanNlp和CTB(斯坦福)分词器与LCN做对比实验,如表 3.
利用CNN结合不同分类器可知,更适用于中文的jieba分词器明显好于其他分词器,但是,由于医学分词的专业性,限制了传统中文分词器的优势,所以字符级别的CNN+char的效果好于jieba分词器.尽管CNN+char整体性能很好,但是由于医学专业领域的分词限制,无法提取到医疗文本的主要特征. LCN的多粒度抓取可以使医学文本中的字信息和词汇信息互补,使得在分词极不准确的情况下仍然保持优势.
-
LCN以CNN为基础,以字和词混合多粒度医疗文本为输入,提取文本特征.所以本文选择了LSTM[17],Bi-GRU[18],AMPCNN[19] 3种深度学习模型进行比较,分别计算模型的准确率(Accuracy)和MRR,如表 4.
AMPCNN包含了由字符级别和单词级别的CNN构成,字符级别用来抓取字符串特征并计算字符串的相似性,单词级别利用最大缓冲带(AMP)检测语句中的谓词含义.但是AMPCNN并不能细节地抓取上下文信息,而本文使用的LCN可以抓取谓词上下文的所有可能性,包括每个词的字符与单词状态,所以准确率较高. LSTM提取医疗问句中的语序信息,通过分析问句时间序列特征计算与答案之间的相似度,但是模型中的错误信息导致结果准确率较低. Bi-GRU性能高于传统的LSTM,因为Bi-GRU中的门控单元不但可传递节点之间的隐藏状态,而且可重置节点中的错误信息,可有效解决训练中反向传播的梯度消失问题,但上面两种模型无法解决关系序列在不同分词情况下的特征提取,本文所采用的LCN不但将关系名称分解为单词,关系上下文内容也被分解为字与词的混合模式,同时利用关系级别和单词级别的序列分别提取本地信息和全局信息,对于问题的特征抽取更加全面,使得特征图内容更加丰富,准确率更高.
-
在基于LCN的条件下,为了验证Glove的有效性,分别利用Cbow[20],Skip-gram[21],Bert[22]和Glove编译的医学词向量,比较预测的准确性.通过利用不同的词向量所得结果如图 9.

图 9中Skip-gram和Cbow属于早期提出的词向量模型,Skip-gram要预测每个词作为中心词时周围词的情况,模型更加精细,所以准确率高于Cbow.然而前两者只考虑词的局部信息,忽略了中心词与预测范围外的其他词,Bert利用Transformer进行编码,充分考虑了上下文特征情况下预测其他词,表现更佳.本文采用的Glove词向量统计了词的共现率,获得的医疗词特征信息更加充分,效果优于其它算法.
从图 9中还可看出,本文的Glove+LCN模型在模型迭代次数为15时准确率逐渐趋于饱和,后维持在89%左右.
-
利用本文的医疗知识问答模型,关于医疗问答的简单应用如表 5.
2.1. 知识问答数据集构建
2.2. 评价指标
2.3. 词向量构建
2.4. 模型比对
2.4.1. 分词工具实验对比
2.4.2. 深度学习模型对比
2.5. 词向量对比
2.6. 问答模型应用
-
本文通过爬取医疗网站信息构建医学知识图谱,并进一步构建了医学知识问答库,利用Glove模型将电子病历训练为医学词向量,将医学词向量作为输入端,利用LCN模型提取问题的特征,并且计算问题特征和答案之间的相似度,进而训练模型完成医疗问答,不仅省去了传统问答模型人工定义规则这一过程,而且在实验中通过与其它问答模型对比,效果优于其它深度学习模型.但是LCN还存在以下不足:
1) LCN的核心是利用CNN中的卷积核提取问题特征,但是忽略了问题的时序特征.
2) 模型对于“问题—关系”的1对1模式准确率较高,但是对于一个问题多个答案的1对n模式,其问答表现不佳.
后续将RNN入到模型中,提升对问题时序性特征的关注,并且针对1对n的问答情况更新模型.
 DownLoad:
DownLoad: