





-
慢性肾病具有患病率高、知晓率低、预后差和医疗费用高等特点,是继心脑血管疾病、糖尿病和恶性肿瘤之后,又一严重危害人类健康的疾病.近年来慢性肾病患病率逐年上升,全球一般人群患病率已高达14.3%[1].我国横断面流行病学研究显示[2],18岁以上人群慢性肾病患病率为10.8%,据此估计我国现有成年慢性肾脏病患者1.5亿,但知晓率仅为12.5%,该调查还发现经济快速发展的农村地区居民成为慢性肾脏病的高发人群.随着我国人口老龄化、糖尿病和高血压等疾病的发病率逐年增高,慢性肾病发病率也呈现不断上升之势[3].由此可见对慢性肾病早期筛查的重要性.随着人工智能技术的发展,越来越多的研究者将其应用到医疗卫生领域[4-9].人工神经网络、支持向量机、决策树等机器学习方法可以实现分类功能,并在疾病的风险预测方面得到应用.而使用集成学习方法比单个机器学习方法构建的分类器性能表现更优[10-13].使用集成学习方法已经在各个领域实现图像识别、语义识别、疾病筛查、辐射源信号识别、天气预测等功能[14-17].基于集成学习算法的慢性肾病早期筛查方法在医疗领域具有重要价值.
HTML
-
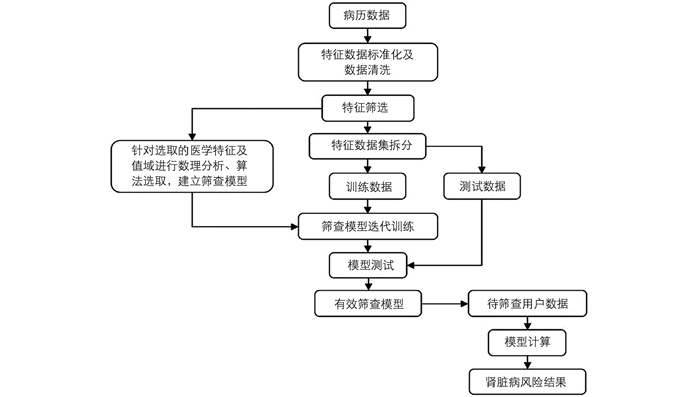
基于集成学习算法的慢性肾病早期筛查方法及其应用过程如图 1所示,包含了医学数据的处理、模型的训练与测试及其应用部分.
-
本研究搜集2016年到2019年江苏省多个市的各个年龄段体检人员的体检资料,其内容包括身高、体质量、血压等基本信息和血常规、血生化、尿常规、肝肾功能、血脂等医学特征数据.去除体检人员的身份证号码、电话号码、住址等敏感信息,排除了数据不完整和诊断不明确的体检资料,最终从中选取了3年内进展为慢性肾病的体检资料3 999例,没有进展为慢性肾病的体检资料4 536例.
数据处理包括标准化、特征筛选. ①标准化:依据建立的医学实体标准库与单位的换算表,并对等级资料数据制定赋值规则. ②特征筛选:将所有特征,按照规则分区间赋值,采用统计学上的卡方检验,根据检验结果删除没有统计学意义的特征.根据肾脏病科医生提出的要求,将3年内进展为慢性肾病的数据标注为1,将3年内没有进展为慢性肾病的标注为0.参与标注的人员共10人,均有医学相关专业背景,将其分为3组,每组标注人员都对全部数据进行标注.最后,三组标注结果进行比对,结果有分歧的都会由肾脏病科医生给出最终的判断.
-
集成学习是一种组合多个基学习器共同完成预测任务的学习算法,与单个分类器相比具有更精确、过拟合风险低的优点,根据其组合思想可分为bagging和boosting两类[18-19],本文分别选取经典模型随机森林和XGBoost进行构建[20-21].随机森林和XGBoost通常都是使用决策树作为基学习器进行集成.决策树是最符合人类思考模式,最容易被理解和解释的模型之一,是一种树形结构,其中每个内部节点表示一个特征条件,每个分支代表对于这个特征条件的不同输出,每个叶节点代表结果相同的一类样本.常见的决策树算法有C4.5,ID3和CART,能够有效地运行在大规模数据集上,处理具有高维特征的输入样本.
-
将数据集按照一定比例分为训练集和测试集,训练集用来训练慢性肾病早期筛查模型,测试集用来测试模型的筛查性能.使用随机森林算法训练过程中,会以有放回采样的方式为每个决策树提供一份不同的样本数据,每个决策树再计算结点上分支效果最佳的医学特征及阈值完成树的分裂构建,最终使得慢性肾病预测结果与相应患者标准诊断结果相符,从而得到慢性肾病早期筛查模型.使用XGBoost算法训练过程中,所有决策树使用同一份数据集,但是要拟合的结果是上一轮模型输出与真实值之间的差距,同样对于每个决策树计算结点上分支效果最佳的医学特征及阈值完成树的分裂构建,最终使得慢性肾病预测结果与相应患者标准诊断结果相符,从而得到慢性肾病早期筛查模型.
-
使用超参数的网格搜索方法与k折交叉检验,进行多次模型训练进而优化模型.网格搜索方法可以穷举参数的取值组合,再利用交叉验证评价优劣,最终获得最佳有效慢性肾病筛查模型.
交叉验证[22]方法可分为2种:留一交叉验证(leave-one-out cross-validation,LOO-CV)和k折交叉验证(k-CV). LOO-CV通常是在数据缺乏的情况下使用,一般情况下都是使用k-CV方法.将原始数据均分成k组,将每个子集数据分别做一次测试集,其余的子集数据作为训练集,这样会得到k个模型,k个模型性能指标的平均值表示此k-CV下模型的性能. k-CV可以有效地避免过拟合与欠拟合的发生,最后得到的结果较有说服性.
-
评估筛查模型使用的度量指标:精确率(Precision,P)、真阳性率(True Positive Rate,TPR)、真阴性率(True Negative Rate,TNR)、F1值(F1-score).精确率是指在慢性肾病筛查模型识别出的慢性肾病患者中被正确识别的占比,P=TP/(TP+FP);真阳性率是指慢性肾病患者被正确识别的占比,TPR=TP/(TP+FN);真阴性率是指非慢性肾病患者被正确识别的占比,TNR=TN/(TN+FP);F1值为P和TPR的调和平均值,F1=2*P*TPR/(P+TPR). F1值能够更好地体现模型的性能.
-
随机森林、XGBoost等分类器能够输出样本的后验概率为P(Y=c|X),其中c代表类别,X代表样本特征.但是模型输出的概率经常与样本属于类c的真实概率有偏差,本产品的应用场景为慢性肾病早期筛查,用户使用该软件能够检测自己患慢性肾病的风险概率,对模型的概率输出有较高要求,为消除偏差,需通过概率校准获取较准确的概率.
-
概率校准即对分类预测的概率重新进行计算,再根据衡量标准评定校准结果的好坏.为避免校准时引入偏差,校准模型需要用一个独立于训练集的测试集.对于分类模型主要有Platt scaling和Isotonic regression 2种校准方式[23].
Platt scaling是用Logistics回归对模型的输出值做拟合,该方法适用于样本量小的情况.将模型输出值作为样本特征,与样本实际标签构成校准模型训练集,训练得到一维LR模型,最终输出的结果就是模型经过Platt scaling后的预测概率.假设样本i的模型输出值为fi,经Platt scaling后预测概率为:
其中,参数A,B可训练得到.
Isotonic回归又称保序回归,是一种非参回归模型,该方法直接对reliability图中的数据进行拟合.假设预测值fi与实际标签yi有:
约束条件:m为单调递增函数.目标函数:
目标函数的一种求解方法是PAV算法(pair-adjacent violators algorithm),主要思想是输入训练集(fi,yi)并使fi从小到大排序,之后不断合并调整违反单调性的局部区间,直到全局满足单调性.
-
由于真实条件概率未知,数据只有类别标签,DeGroot & Fienberg[24]提出了通过reliability图进行可视化模型校准的方式,它可以大致评估出当前模型的输出结果与真实结果有多大偏差.绘制该图有以下几个步骤:
步骤一:将概率空间分为n箱;
步骤二:各样本按模型得到的预测概率值分别落入n箱中;例如将概率空间分为10箱,预测概率为0~0.1的样本落入第一个箱中,预测概率为0.1~0.2的样本落入第二个箱中,以此类推.
步骤三:计算出各箱的预测平均值和各箱样本中的实际正样本比例,作为图中各箱的点的坐标.
步骤四:最后把图中各点连接起来,其斜率越接近1就意味着模型输出结果估计越有效.
另外,模型输出结果的Brier分数也可作为校准的一个衡量标准.在二分类的情况下,计算Brier分数的公式:
其中,ft是预测的事件t的发生概率;ot是事件t的实际标签(发生为1,不发生为0);N是预测事件总数量.因此Brier分数越接近0,代表模型预测结果越接近于真实标签.
1.1. 数据搜集与处理
1.2. 筛查模型构建
1.2.1. 模型训练
1.2.2. 模型测试
1.2.3. 评估方法
1.3. 概率校准
1.3.1. 概率校准方法
1.3.2. 概率校准衡量标准
-
对搜集到的数据进行单位和数值等标准化处理后,对其进行卡方检验或T检验统计学分析. 表 2展示了慢性肾病在各个特征不同取值的是否进展为慢性肾病结局的分布情况,及其统计学检验结果.统计结果显示,进展为慢性肾病人群集中在老年人群,并且进展为慢性肾病的血压、血糖、血肌酐、尿素与尿蛋白水平均高于没有进展为慢性肾病的,而进展为慢性肾病的白蛋白与总蛋白水平明显低于没有进展为慢性肾病的.根据卡方检验结果显示,每个特征针对3年内是否进展为慢性肾病都是具有统计学意义的(p<0.01),表明选取的特征与慢性肾病存在极其显著的相关关系,选取这些特征建立模型是合理的.
-
根据卡方检验分析结果,最终纳入训练模型的特征有性别、年龄、BMI、血压、血白细胞计数、血中性粒细胞计数、血红蛋白、血白蛋白、血总蛋白、血甘油三脂、血总胆固醇、血高密度脂蛋白胆固醇、血低密度脂蛋白胆固醇、血肌酐、血尿酸、血谷草转氨酶、血谷丙转氨酶、血尿素、空腹血糖、尿隐血、尿蛋白.使用超参数网格搜索方法优化筛查模型,其中随机森林涉及到的主要参数有n_estimators,max_depth,min_samples_leaf,min_samples_split,max_features,criterion,XGBoost涉及到的主要参数有learning_rate,n_estimators,min_child_weight,subsample,colsamole_bytree,gamma,reg_alpha,reg_lambda.并使用5折交叉检验方法训练测试筛查模型,取5次的筛查模型测试结果的平均值作为最终测试评估结果.
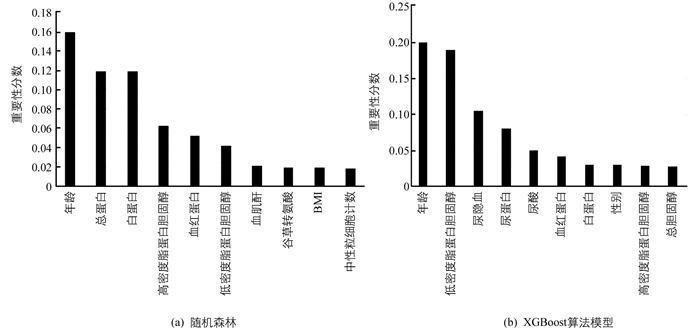
采用随机森林和XGBoost算法模型训练时计算给出的每个特征重要性分数如图 2所示,使用随机森林算法计算得出年龄、总蛋白、白蛋白对慢性肾病早期筛查的作用较大,使用XGBoost算法计算得出年龄、低密度脂蛋白胆固醇、尿隐血对慢性肾病早期筛查的作用较大.
-
表 3展示了5折交叉检验方法得到的基于集成学习算法的慢性肾病早期筛查方法的性能.使用随机森林算法的慢性肾病早期筛查方法的精确率、真阳性率、真阴性率和F1值分别为0.964,0.950,0.969,0.957,使用XGBoost算法的分别为0.950,0.966,0.955,0.958.
-
未校准的随机森林输出预测概率的reliability图和分布直方图,如图 3左图所示.未校准的随机森林Brier分数0.007,模型预测结果集中于0和1这2个值,reliability图呈明显的S型,说明模型分类性能好,但输出的概率的可靠性不佳.选择Platt scaling进行概率校准,如图 3左图所示.校准后Brier分数为0.044,reliability图上的各点连接的曲线明显接近对角线,随机森林输出的概率估计准确性经校准后得到一定提升,这说明Platt scaling可以有效地降低随机森林的偏差.
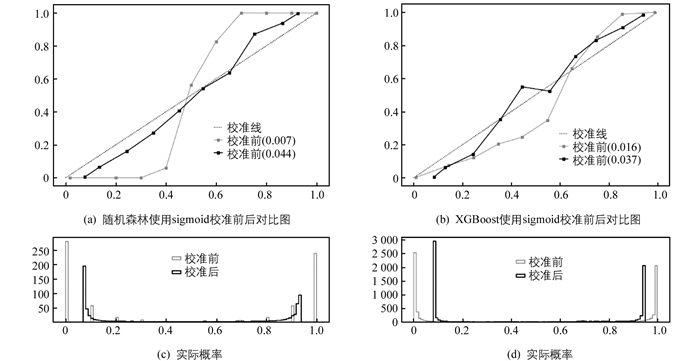
未校准的XGBoost输出预测概率的reliability图和分布直方图如图 3右图所示.未校准的情况下,XGBoost模型的Brier分数为0.016,与随机森林一样,XGBoost预测值也有很多落在0,1这2处,导致Brier分数很小,整个曲线比随机森林更接近对角线,概率可靠性略有提升.同样选择Platt scaling进行概率校准,如图 3右图所示.校准后的Brier分数为0.037,虽然上升了0.021,但是reliability图上的曲线总体上更贴近对角线,概率校准在一定程度上提高了概率估计的有效性,且基本没有影响原模型的分类性能.
随机森林与XGBoost算法模型采用Platt scaling概率校准方法校准前后,对慢性肾病的早期筛查性能的比较见表 4.校准后的模型性能存在一定程度的下降,但是均高于0.94.
2.1. 数据集构造
2.2. 筛查模型训练
2.3. 筛查模型测试
2.4. 筛查模型概率校准结果
-
本研究基于随机森林与XGBoost集成学习算法创建慢性肾病早期筛查方法,使用随机森林算法训练得到的筛查模型精确率、真阳性率、真阴性率和F1值分别为0.964,0.950,0.969,0.957,XGBoost算法的分别为0.950,0.966,0.955,0.958.其中随机森林算法的精确率与真阴性率较高,XGBoost算法的真阳性率与F1值较高.总体来讲,2种集成学习算法筛查模型性能相当,可以根据不同的筛查需求来选择.该慢性肾病早期筛查方法在应用过程中,2个模型共同筛查得到的阳性结果就可以判定为阳性.
慢性肾病筛查最终得出的结果是患者发展为慢性肾病的风险概率值,而分类模型直接输出的分数值并不能直接视为风险预测的概率值,需要评估出当前模型的输出结果与真实结果的偏差是否在允许的范围内,必要的时候需要对其结果进行校准,因此选用概率校准方法解决这个问题.本文使用Platt scaling概率校准方法校准后的模型性能存在一定程度的下降,但是均高于0.94.
由于给出的数据并不知道患者患慢性肾病的真实概率值,无法直接判断原模型的输出是否为有效估计,一种简单而普适的方法即绘制reliability图,图线越接近对角线,说明模型的概率估计越有效,若超出预期范围,可以采用Platt scaling概率校准方法来降低原分类模型的偏差,使最终输出值更接近真实概率,经过概率校准处理后使原模型最终的输出是有效的估计值.
综上,基于随机森林、XGBoost集成学习算法的慢性肾病早期筛查方法的预测效果均表现良好且稳定.采用Platt scaling概率校准方法进行模型概率校准并没有过多的改变分类性能,只是提升了原模型对慢性肾病风险概率估计的可靠性,因此概率校准后输出的概率值更具临床参考价值.基于集成学习算法的慢性肾病早期筛查方法可以应用于医院、体检中心、社区、保险公司及移动平台等辅助体检人员的慢性肾病早期筛查.
 DownLoad:
DownLoad: