



 下载:
下载:




-
开放科学(资源服务)标志码(OSID):

-
家蚕品种资源保存和杂交育种是蚕业科研中的核心内容,在进行资源保存和育种试验前,需同步饲养多个品种. 确保品种纯净度是杂交试验和资源保存准确进行的前提[1-2]. 由于家蚕自身的活动、蚕具交叉使用以及管理疏漏等因素,容易造成不同品种家蚕的混杂,对杂交和资源保存造成不利影响[3-5];同时家蚕品种多,不同品种之间的差异较小,传统人工识别容易产生混淆. 前期有研究表明使用深度学习识别家蚕品种具有较强的可行性[6]. 深度学习需要大量的图像进行模型训练后才能形成识别能力,但构建大型的家蚕品种数据集却面临耗时长、成本高、采集条件受限等难题,因此有必要探明数据集对家蚕品种识别的影响.
近年来,深度学习在农业视觉领域广泛应用,成为当前的研究热点和主流趋势[7-9]. 在家蚕识别领域,课题组前期使用MobileNet对10个家蚕品种在4龄第3 d和5龄第3 d的生长图像进行了识别研究,研究结果表明,深度学习可高效准确识别家蚕品种,且在4龄数据集上的识别准确率最高. 王超[10]使用SE-GoogLeNet模型开展了蚕茧品质分选研究,对3类蚕茧的识别取得了较佳效果. 于业达等[11]、陶丹等[12-13]使用经典卷积神经网络开展了蚕蛹雌雄鉴别研究,也获得了较高的识别准确率. 石洪康等[14-15]使用ResNet-50开展家蚕病害分类识别研究,实现了壮蚕期5种常见病害的准确识别;使用YOLO v3开展家蚕脓病的检测研究,实现了健康蚕与病蚕混杂的条件下对家蚕脓病的准确检测,为病害精准防治提供了依据.
现有研究表明,深度学习在家蚕识别领域具有广阔的应用前景,但大多基于固定的数据集,而当数据集中的图像数量、品种数量和数据增强方法发生变化时均可能会得到不同的识别结果[16-17]. 为探明数据集对家蚕品种识别的影响,本文采集20个家蚕品种4龄第3 d真实生产环境的生长图像构建数据集,利用轻量级卷积神经网络GhostNet在不同的训练集上开展模型训练,探讨图像数量、品种数量和数据增强方法对识别率的影响.
全文HTML
-
在实际生产环境下采集20个家蚕品种在4龄第3 d的生长图像,每个品种的原始图像数量为1 100张. 图像采集时间:2021年9月10日,地点:四川省农业科学院蚕业研究所家蚕养殖基地(四川省南充市顺庆区). 图像采集设备用苹果iPhone 6s智能手机,环境为室内正常光照. 采集时将设备水平放置俯拍,屏幕长宽比设定为1∶1,采集的每张图像中仅包含1只蚕,并随机使用桑叶为图像背景,结果如图 1.
完成图像采集后,无需对图像进行任何预处理,仅使用双线性插值法将图像尺寸统一缩放为224×224像素. 鉴于本文着重关注数据集对家蚕品种识别的影响,因此在不同的试验下,使用的材料仅在图像数量、品种数量以及数据增强方式上有所不同,结果见表 1. 从每个品种的图像中随机挑选100张构建验证集,另挑选200张构建测试集.
在数据增强对识别的影响中,使用数据增强方法生成新图像,主要包括对原始图像进行随机旋转、平移和局部缩放等. 进行数据增强时的每个品种的原始图像数量为100张,依次生成100~700张图像,数据增强生成新图像如图 2.
-
本文选用GhostNet模型开展家蚕品种识别研究,该模型是Han等[18]在2020年发布的一款轻量级卷积神经网络模型. GhostNet使用一系列的线性变换生成重影特征,在最大程度上避免了特征冗余,能同时兼顾识别效率与准确性,在ImageNet数据集上的识别效果超过了MobileNetv3[19],因此使用GhostNet模型可以确保较高的识别准确率和识别效率.
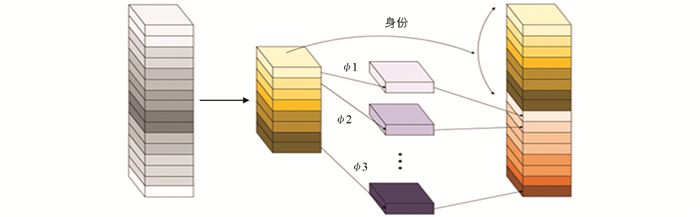
GhostNet中的Ghost模块如图 3,对于给定的特征图,先使用1×1卷积进行特征通道压缩成原来的一半,然后使用可分离卷积进行特征点(ϕ)的分离提取,并将通道压缩后的特征图与可分离卷积运算的输出特征映射堆叠后输出.
两个Ghost块可组成1个Ghost bottleneck块,结构如图 4,其中,“DW Conv Stride=2”表示卷积步长为2的可分离卷积运算,用于压缩特征图维度,“BN”为Batch Norm运算,“ReLU”为激活函数,“Add”代表特征图像相加.
GhostNet的网络结构如表 2,其中,“SE”代表通道注意力模型SENet[20],“Conv2d 3×3”代表卷积核尺寸为3×3的2维卷积,“G-bneck”代表Ghost bottleneck结构,“AvgPool 7×7”代表尺寸为7×7的全局平均池化,“FC”代表全连接. 使用GhostNet进行家蚕品种识别时,输入图像尺寸为224×224像素,先使用16个尺寸为3×3的卷积核按步长为2进行卷积运算,提取图像特征,再使用一系列堆叠的Ghost bottleneck结构,每个Ghost bottleneck中会进行维度膨胀,部分结构中还使用了SE注意力模型,最后使用1×1的卷积运算进行特征通道调整,全局平均池化和全连接运算后输出网络预测结果.
-
试验用硬件设备为DELL Precision 5820图像工作站,处理器:Core i7-9800X,显卡:RTX 2080Ti,显存:11G,内存:32G,运算平台:CUDA-10.0,操作系统:Windows 10专业版64位,编程语言:Python 3.7,开发环境:Jupyter notebook,深度学习框架:TensorFlow-gpu 1.14和Keras 2.0.
模型训练的超参数:mini batch_size为16,迭代次数为300次,损失函数为交叉熵,优化器为Adam,初始学习率为0.001,当损失值连续5次迭代未明显下降时,就将学习率乘以0.8. 模型训练完成后使用测试集进行测试,以模型在测试集上的平均识别准确率为评价指标,计算公式为
式中,η为平均识别准确率,Ncorrect为正确识别数量,Ntotal为测试集图像总数量.
1.1. 家蚕品种图像数据集
1.2. GhostNet模型
1.3. 试验环境与评价指标
-
试验时,每个品种用于模型训练初始图像数量为200张,并逐次增加100张至800张. 训练过程中,以模型在训练集上的准确率和损失值作为参照,用于查看模型的收敛效果如图 5.
从图 5中的准确率和损失值曲线可知,在固定品种数量条件下,当训练集中图像数量发生变化时,模型的收敛速度存在一些差异,且整体呈现出图像数量越多,模型的收敛速度越快,收敛效果也越佳;在进行130次训练迭代时,不同图像数量模型均趋于或达到稳定状态,据此确定本文后续测试使用300次迭代能确保模型完全收敛.
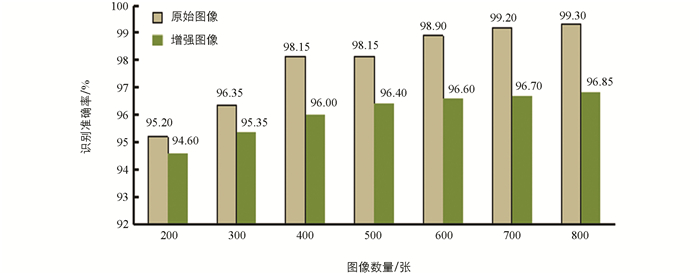
模型训练完毕后,使用测试集对其进行测试,由图 6可知:随着用于模型训练的图像数量增加,识别准确率也相应增加. 当用于模型训练的图片数量少于300张(含300张)时,其识别准确率最高为96.35%,低于行业标准(≥97%)要求,只有图片数量大于400张时的识别准确率超过98%,高于行业标准规定. 用于模型训练的图片数量由500张增加至600张时,其识别准确率提高了0.75%;图片数量由600张增加至700张时,其识别准确率只提高了0.30%;图片数量由700张增加至800张时,其识别准确率仅提高了0.10%. 由此可见,用于模型训练的图片数量不能低于300张,多于700张意义也不大. 因此,鉴于成本、识别速度及符合行业标准条件下,建议数据集图像数量在400张即可,若考虑高识别率时,数据集图像数量在700张为好.
-
在数据集图像数量较少时,使用数据增强生成新图像是一种常用的方法,为验证图像数据增强方法对识别准确率的影响,使用10个家蚕品种,每个品种原始图像数量为100张,并通过数据增强依次生成200~800张图像,再利用生成的新图像和原图像构建训练集用于模型训练与测试(与2.1相同),测试结果如图 6.
图 6表明,当使用数据增强方法生成更多图像用于模型训练时,随着图像数量的增加,模型在测试集上的识别准确率由200张原图的94.60%提高到800张增强图的96.85%,图像数量增加了600张,但识别准确率仅仅提高了2.25%,还是没能达到行业标准(≥97%).
从图 6中还可以看出,采用图像数据增强方法增加图像数量,其整体识别准确率及增加幅度均相对较低,表明使用数据增强方式生成新图像对于识别准确率的提升作用有限,且不能达到实际应用的要求.
在原始图像数量不够的条件下,纵然通过图像数据增强的方式增多图像数量,其识别率的提高也是相当有限的,因此,应尽可能增加原始图像数量以获得最佳的识别效果.
-
根据2.1的试验结果,固定单个品种训练图像数量为400张,测试的初始品种数量为4个,并逐次增加2个直至20个,训练过程中记录模型在训练集上的准确率和损失值(图 7). 从图 7可以看出,当单个品种图像数量固定、品种数量不同时,模型的收敛效果存在一定差异,收敛效果最佳的是使用4个品种的训练模型,最差的是20个品种的训练模型. 所有品种尽管有一定差异,但大致经过150次迭代后,不同品种数量的模型均能达到稳定状态.
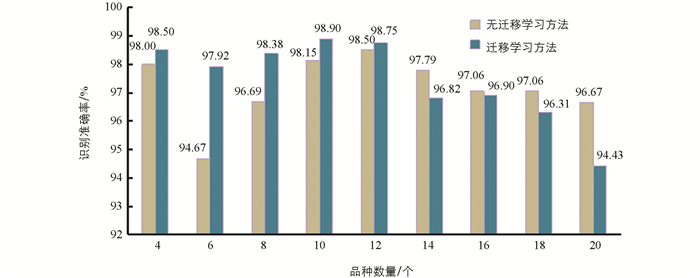
图 8是不同品种数量模型在测试集上的识别准确率,从图 8中可以看出,采用无迁移学习方法,其识别准确率最高的是12个品种,为98.50%;其次是4个品种,识别准确率为98.00%;最低的是6个品种,识别准确率仅为94.67%. 当品种数量从12个逐步增加至20个时,识别准确率由98.50%逐步下降至96.67%,由此,建议在品种识别数据集中品种数量选择12个为最佳.
-
在数据及图像数量较少时,迁移学习也是一种常用的方法. 为验证迁移学习对家蚕品种识别的影响,使用GhostNet在ImageNet数据集上预训练的权重进行迁移学习,取每个品种的原始图像400张,初始品种数量为4个,每次增加2个直至20个品种,即只增加品种数量,而每个品种的图片数量保持不变,训练完成后在测试集上进行测试,结果如图 8.
由图 8可以看出,使用迁移学习方法,品种数量的不同对识别准确率也有明显影响,即在品种数量由6个增至10个时,识别准确率为97.92%~98.90%,基本能达到实际生产的要求;当品种数量由10个增至20个时,随品种数量的增多,识别准确率由98.90%逐步下降至94.43%,且下降速度较快. 结果表明,在品种数量为10个时,识别准确率最高,为98.90%;其次是12个,为98.75%.
从图 8还可以看出,采用迁移学习方法后,在品种数量为4个,10个和12个时,其识别准确率提升小于1%;在品种数量为6个至8个时,识别准确率提升较大,并均能使识别准确率达到97%以上;当品种数量大于12个后,识别准确率不升反降,随数量增多,下降更快.
由此可见,当品种数量低于12个时,采用迁移学习方法可有效提升识别准确率,并取得较好的效果;在品种数量大于12个时,迁移学习方法对识别准确率的提升无效.
2.1. 图像数量对识别的影响
2.2. 图像数据增强对识别准确率的影响
2.3. 品种数量对识别的影响
2.4. 迁移学习对识别的影响
-
针对当前我国家蚕品种数量多,开展基于深度学习的家蚕品种识别研究时,数据采集及数据集构建面临耗时长、成本高、采集条件受限等诸多问题,本文开展了数据集对家蚕品种识别的影响. 在实际生产环境条件下,采集了20个家蚕品种在4龄第3 d的真实生长图像,构建出家蚕品种图像数据集,采用GhostNet的家蚕品种识别模型,分别开展了图像数量、品种数量、图像数据增强和迁移学习方法对品种识别准确率的影响研究,结果表明:
1) 增加构成数据集的图像数量有助于提升识别准确率. 当单个品种训练集图像数量为400张时,识别准确率可达98.15%,达到行业标准要求;当图像数量在800张时,识别准确率高达99.30%. 图像数量增加纵然会提高识别准确率,但也会大大增加成本、降低运行效率、提升硬件要求等. 综合各项因素,在构成数据集时,单个品种的图像数量选取400张即可.
2) 品种数量会对识别准确率造成一定的影响. 品种数量过多或过少,都会使识别准确率降低,不能满足行业标准要求,只有当品种数量在10~12个时,识别准确率超过98%,能够满足行业标准要求,因此,建议在构成数据集中的品种数量选择在10~12个.
3) 构成数据集的原始图像数量低于100张,采用图像数据增强的方法对识别准确率的提升作用非常有限且无实际意义,因此,建议在构建数据集时尽可能增加原始图像数量.
4) 当品种数量低于12个时,采用迁移学习方法,可有效提升识别准确率,并取得较好的效果,品种数量越少,表现越好. 当品种数量大于14个时,迁移学习方法反而会使识别准确率下降,品种数量越多,下降的速度越快.