



 下载:
下载:

-
开放科学(资源服务)标识码(OSID):

-
中国总面积的70%左右为丘陵山地,大约56%的人口居住在这些区域[1]. 随着城镇化进程的加速,农村劳动力向城市的持续转移导致部分耕地荒废,这一趋势可能危及国家粮食安全. 因此,提高丘陵地区的农业智能化水平对于保障农业正常生产和推进农业现代化具有至关重要的意义. 精准识别道路行驶区域是智能农机装备搭载视觉系统的主要目的,由于丘陵田间道路具有狭窄蜿蜒、起伏大、路况复杂等特点,所提取行驶区域的道路信息难以保证智能农机装备的自主导航. 因此,精确、实时的丘陵田间道路信息提取就变得尤为重要.
在道路信息提取研究中,传统的方法包括边缘检测和阈值分割等[2-4],但这些方法在处理复杂道路环境时准确率不高. 近年来,随着神经网络技术的发展,语义分割逐渐成为了道路信息提取的主流方法. 孟庆宽等[5]提出一种基于通道注意力结合多尺度融合的轻量级语义分割模型,实现对非结构化田间道路场景的识别. 但MobileNetV2作为主干网络采用深度可分离卷积,易出现信息丢失和梯度消失等问题从而导致分割精度下降. 杜小强等[6]提出一种优化Mask R-CNN模型的非结构化农田障碍物实例分割方法,引入可变形卷积增大感受野并提高模型的鲁棒性. 但可变形卷积的输出结果与初始位置有关,可能导致可变形卷积输出结果偏差较大从而影响模型的分割性能. Xu等[7]提出一种将Transformer与卷积神经网络(CNN)结合的MCTNet网络结构,模型基于Encoder-Decoder在CNN和Transformer独自运行后再融合输出特征,缺点是融合模块难以平衡各种特征的权重,可能出现信息冲突及分割目标错误的情况. Zhang等[8]在FCN基础上提出了一种多特征全卷积网络,通过RGB图像与DEM图像结合以提取山地道路区域. 不足之处是仅使用一次上采样将特征图恢复到原图尺寸大小,可能影响细节和边缘信息的精确表达. Wang等[9]提出一种针对夜间道路场景的语义分割模型SFNet-N,虽然模型提高了增强后图像的真实性,但试验结果表明其准确率和实时性还存在不足. Firkat等[10]提出一种用于农林业环境非结构化道路检测方法ARDformer,虽然试验结果表明其性能大大优于SOTA道路检测方法,但计算成本过大且推理速度较慢. Liu等[11]基于图像级联网络(ICNet)架构提出一种轻量级实时语义分割网络,通过提取不同层次特征避免了概率图模型引起的大量计算和内存消耗的问题,但该网络易产生分割边缘模糊和不准确的问题. Tian等[12]提出一种多任务学习GCS-MUL算法,将卷积块注意力模块(CBAM)作为整个模型的骨干,设计的轻量级目标特征提取网络Ghost CBAM(GCNet)提高了模型分割精度并减小了模型参数量,但多任务学习的相互作用会出现检测目标的漏检. 对于田间果园非结构化路面,大多使用基于Encoder-Decoder结构的Unet模型提取果园道路信息[13-14],但由于数据集的不充分及编码器卷积层的堆叠,影响提取上下文信息导致部分目标的分割精度较低. Lin等[15]提出一种非结构化场景的实时语义分割模型,通过融合领域泛化和注意力机制增强其在复杂无组织环境的能力,但使用轻量化的主干网络对稀有类别的感知有限可能导致分割边界模糊. Baheti等[16]基于非结构化道路对DeepLabV3+语义分割网络进行改进,加入膨胀卷积的Xceptions作为主干网络,试验结果表明在流量较大的复杂环境中会出现部分重叠目标分割错误的情况. 总之,上述研究基于深度神经网络对道路图像进行语义分割,相比于传统方法其性能有了较大提升,但也存在分割精度与模型参数量平衡的问题.
本文以丘陵田间道路作为研究对象,采集田间道路图像构造数据集,基于DeepLabV3+网络将轻量化的G_Ghost_RegNetX_4.0GF作为主干网络搭建语义分割模型,引入轻量级空洞空间金字塔池化模块(Lite-RASPP)将多尺度特征融合. 通过对复杂的丘陵田间道路图像进行语义分割,实时精确地提取可行驶区域和动态目标等有效信息,为智能农机装备的自主导航研究奠定基础.
全文HTML
-
丘陵田间道路狭窄、坡度起伏大、路面坑洼不平,传统轮式转运平台性能难以满足丘陵田间复杂的道路环境. 鉴于履带式转运平台有较好的稳定性和路面适应能力,在丘陵田间有卓越的性能表现,故本文以履带式转运平台为试验平台. 转运平台的整体布局如图 1所示,感知硬件为无畸变工业相机,相机的像素、帧率分别为5×106和30 f/s.
-
该试验在重庆市北碚区果树重点实验室研发基地进行. 研发基地中包含田地、果园、村庄等区域,基地道路类型丰富且随丘陵起伏延伸,可作为丘陵田间道路的图像采集场所. 图像采集过程中手动遥控转运平台行驶路线和速度,行驶路线覆盖整个试验基地,包含了石子路、水泥路、沥青路和混合路面等多种道路类型,控制转运平台以4 km/h匀速行驶模拟其正常运行状态. 工业相机固定于转运车正面中轴线上,数据通过USB端口传输并储存在手提电脑中,相机采集的图像分辨率为640×480像素,图像采集的帧率为30 f/s.
-
从试验基地采集到的原始数据集有可能受到路面颠簸、光照及阴影等因素的影响,不能直接用于深度学习训练,需要对图片进行筛选. 从原始数据集中选出1 000张较为清晰的图片,通过开源标注软件EISeg处理图像集生成标签图像,再通过人工对标注边缘进行调整. 按照8∶1∶1的比例划分训练集、验证集和测试集,数据集的储存格式为PASCAL VOC数据集格式.
本文根据丘陵田间道路环境中对象的特征属性将环境对象类别划分为10种,包括道路、动态目标、障碍物、水塘、天空、标志牌、建筑、挡墙、护栏和背景,其定义见表 1,标注示例如图 2所示. 通过数据集的增强和均值化方法提高数据集的丰富程度,进而提高神经网络模型的泛化能力和鲁棒性. 数据增强是指通过对原有训练数据进行一系列变换和扩充生成更多的图像数据,同时将采集到的图片格式大小转化为520×520像素;训练神经网络时通过程序随机翻转、裁剪及旋转图片扩充数据集并保持随机性,降低神经网络过拟合风险,使模型有更好的适应性和鲁棒性.
1.1. 试验平台和设备
1.2. 田间道路数据集制作
1.2.1. 图像采集
1.2.2. 数据集制作
-
DeepLabV3+模型是基于卷积神经网络的语义分割网络[17],使用了Encoder-Decoder的模型架构,将空洞空间金字塔模块(ASPP)与Decoder模块结合提高网络的边界分割效果. 该模型选用Xception作为模型的主干网络并对其改进,选用深度可分离卷积替代其最大池化层,从而改善了主干网络的特征提取能力和网络分割精度,不足之处是明显增加了网络的计算量并降低了推理速度.
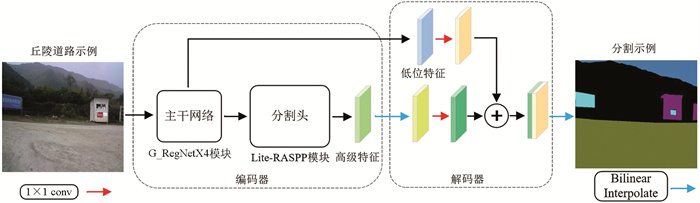
为实现智能农机的自主导航,语义分割模型不仅要高效准确地对丘陵田间道路信息识别分割,还需要在较小计算量下完成田间道路图像分割以减小对计算资源的占用. 基于此,通过对DeepLabV3+进行改进,搭建的语义分割模型如图 3所示.
1) 在语义分割任务中,编码器的主干网络能够从输入图像中提取高层次的语义信息,并将其转化为适合分割任务的特征表示. 这些特征使得模型能够准确地识别不同物体并进行像素级的分类和分割,从而实现对图像的精确理解和分析. 所构建的模型选择新型的网络模型G_Ghost_RegNetX_4.0GF(后续简写为G_RegNetX4)作为主干网络,减小模型计算量并确保主干网络能够有效地提取丘陵田间道路目标特征.
2) 选用基于ASPP模块轻量化改进的Lite-RASPP模块作为模型的分割头(Segmentation Head),在不影响模型精度的情况下减少模型的计算量. 对于每个像素,分割头计算其属于每个类别的概率,并根据最大概率值将像素归类到相应的语义类别中. 通过这种方式,网络可以将输入图像的每个像素映射到相应的语义类别,从而实现像素级别的语义分割.
3) 解码器通过跳跃连接的方式结合低位特征和高级特征,融合丰富的上下文信息和空间细节信息提高分割精度,再使用双线性插值将经过编码和特征提取的信息还原至图像大小,并生成每个像素的语义标签. 输出结果可以代表图像中每个像素所属的语义类别,实现了像素级别的语义分割.
模型基于DeepLabV3+的Encoder-Decoder结构做出优化改进,通过采集设备获取丘陵道路图片,处理后传入模型的编码器,经G_RegNetX4主干网络提取低位特征和高级特征. 低位特征经主干网络简单处理后通过跳跃连接传入解码器,再与经主干网络和分割头处理的高级特征结合,最后应用双线性插值将特征图恢复至原始尺寸并输出分割结果.
-
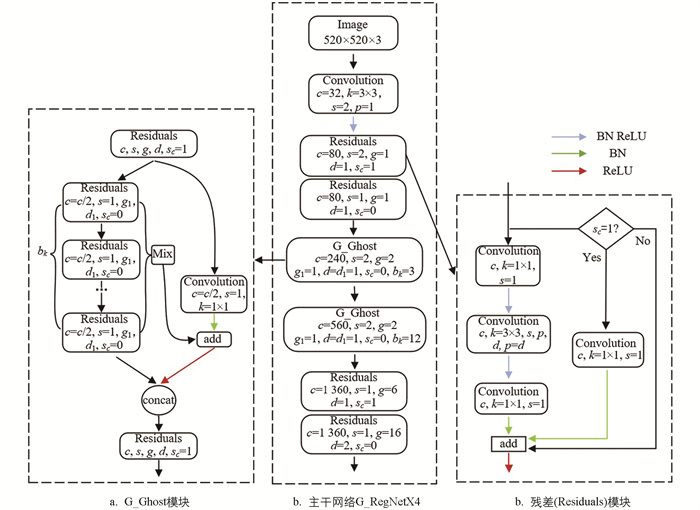
G_RegNetX4是由华为诺亚实验室于2022年提出的分类模型[18],其目的是解决由于移动设备的内存和计算资源有限,卷积神经网络(CNN)在移动设备部署困难的问题,并针对GPU硬件设计G_Ghost优化模块,进一步提高模型计算效率.
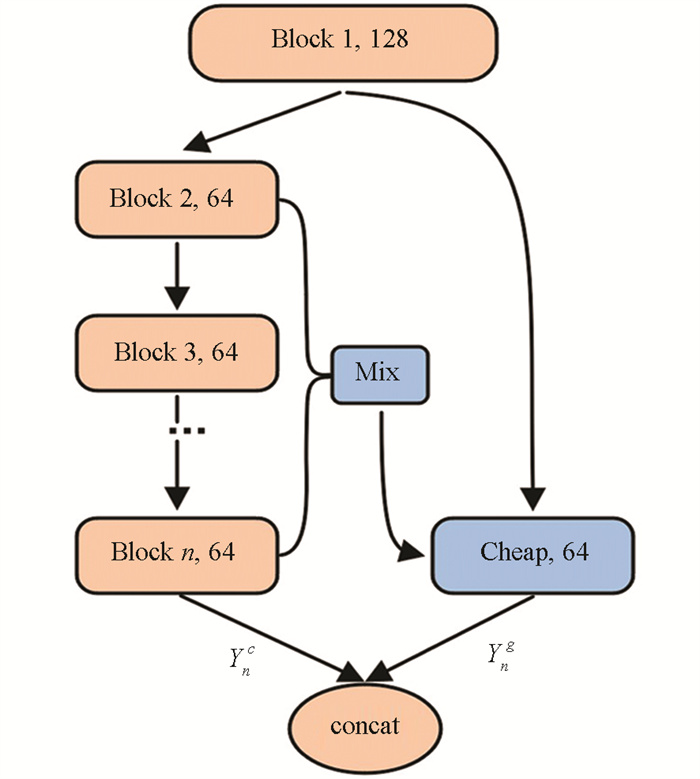
传统的卷积过程输入X,经过连续的卷积层{B1,B2,…,Bn}得到输出特征映射Yn,式(1)与式(2)分别表示第一层和最后一层的输出特征映射. G_Ghost模块考虑到多个卷积层的堆叠会输出冗余特征,不同卷积层生成的特征存在一定的相似性,故可以在GPU上通过廉价变换将部分低级特征映射到高级特征,从而减小模型的计算量,提高模型的推理速度. 整个G_Ghost模块如图 4所示.
G_Ghost模块中将深度特征分为复杂特征Ync∈R(1-λ)c×h×w和Ghost特征Yng∈Rλc×h×w,复杂特征通过一系列卷积具有更丰富的语义信息;Ghost特征直接从第1层卷积层中获取,再通过Cheap模块(简单卷积处理,用C表示)使Ghost特征与复杂特征的通道数相同,用于后续的拼接聚合,如式(3);最后连接聚合Ync和Yng得到G_Ghost模块的最终输出,如式(4).
不同特征的直接聚合会导致Ghost特征与复杂特征的信息域不符,需要补充Mix模块将卷积第2到第n层的中间特征进行拼接,将中间特征设为Z∈Rc×h×w=[Y1c,Y2c,…,Ync],再使用Mix模块(用τ表示)变换到与Ghost特征输出同域,如式(5);最后将聚合中间特征的Ghost特征与复杂特征融合得到输出. 本文所选的G_RegNetX4网络模型如图 5所示.
G_Ghost模块一般用于3个及以上卷积块堆叠的结构,在G_RegNetX4中当Residuals模块的堆积数超过3时,使用G_Ghost模块搭建网络完成对图像复杂特征和Ghost特征的提取融合,减少网络参数量并提高精度. 如图 5(a)所示,将G_Ghost模块中的Block块用Residuals模块替换.
在图 5中,c为卷积输出通道,k为卷积核大小,s为卷积步长,p为特征图四周填充像素的行或列数,g,g1为分组卷积的组数,d,d1为膨胀卷积的膨胀因子,bk为Residuals模块堆叠次数,sc为捷径分支.
-
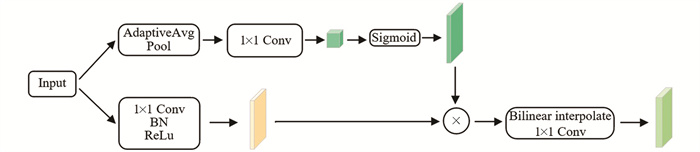
Lite-RASPP在MobileNetV3中被认为是一种轻量级的分割头[19],旨在增强模型对多尺度特征的感知能力,Lite-RASPP结构如图 6所示. 相比ASPP结构,Lite-RASPP模块减少分支数量和膨胀卷积的膨胀率,降低了计算复杂性,使得模型更适合在资源受限的设备上使用. 在不增加参数量的情况下增大有效的感受野,通过压缩激励模块[20]的方式部署了全局平均池化,用于主动选择和强调网络中重要的特征通道. 在主干网络的最后一个Block中应用空洞卷积提取更丰富的特征输入Lite-RASPP模块,输入特征经2个分支通道处理聚合获取具有更多细节信息的特征. 具体步骤为将经简单卷积、ReLU等操作处理过的特征与全局平均池化所得特征聚合,以获取具有丰富细节信息的特征.
2.1. 模型构建思路
2.2. 主干网络
2.3. 轻量级空洞空间金字塔池化模块
-
本文使用的模型训练环境为台式计算机,CPU型号为Intel Core i9 13900KF,储存空间分为32G内存,1T固态硬盘,GPU选用显存为24G的NVIDA GTX 4090显卡;基于64位Windows 11操作系统,采用Python语言在Pytorch深度学习框架下进行语义分割模型搭建,统一计算架构选择CUDA 11.3,深度神经网络加速库版本为CUDNN 8.8.1.
-
通过主干网络验证试验和模型性能试验对所提出模型进行验证,训练网络参数如下:学习率为0.1,权重衰减系数为0.000 01,Batch_size设置为5,动量指数为0.9,训练周期为100.迁移学习可以将一些标准任务上进行预训练深度神经网络模型的特征提取层重新用于其他视觉任务,以提高模型的泛化能力[21]. 在模型性能试验时,对所提出模型及对比模型均载入主干网络的预训练权重,以验证网络模型性能.
-
为了验证搭建的语义分割模型在丘陵田间道路的分割效果,使用了像素准确率PA(Pixel Accuracy)、平均像素准确率MPA(Mean Pixel Accuracy)、平均交并比MIoU(Mean Intersection over Union)、浮点运算量FLOPs(Floating Point Operations)、参数总量Params和推理速度FPS(Frame Per Second) 6个指标对语义分割模型进行性能评价. 其中评价指标PA、MPA、MIoU具体值的计算公式分别见式(6)~式(8),语义分割分类数一般为k+1类(k类目标与1个背景分类).
式中:AP为像素准确率(%);AMP为平均像素准确率(%);MIoU为平均交并比(%);Pii表示属于i类且被预测为i类的像素数(预测正确像素数);Pij表示属于i类却被预测为j类的像素数(预测错误像素数).
-
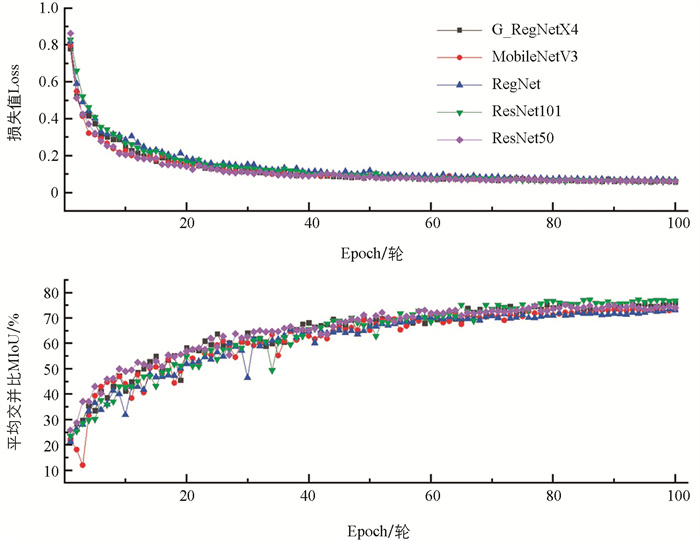
主干网络的特征提取能力及参数量直接影响语义分割模型的分割精度及计算效率,对于语义分割网络而言,合适的主干网络保证分割精度的同时还可以提升网络的计算效率. 本文对比分析了以RegNet[22]、MobileNetV3、ResNet系列[23]、G_RegNetX4作为DeepLabV3+的主干网络时的模型性能,未载入预训练权重的情况下对加载不同主干网络的DeepLabV3+模型进行训练验证.
表 2记录了不同网络的Params和FPS以及网络在测试集中的MPA和MIoU指标. 分析表 2可知,MobileNetV3在FPS和Params上的表现优于其他模型,但是它的MPA和MIoU均小于其他网络,其MPA与MIoU比G_RegNetX4分别低了0.73%和2.5%,MobileNetV3使用轻量级深度可分离卷积搭建卷积模块,该方法能够显著减少计算量和参数量,但该方法也降低了模型的分割精度. ResNet101的MPA和MIoU为对比主干网络中的最优量,分别为84.21%和77.1%,比G_RegNetX4分别提高了1.73%和1.3%,但是其Params为G_RegNetX4的2.30倍,FPS比G_RegNetX4慢了30.15 f/s,ResNet101以残差结构搭建模型,网络层数增加提升分割精度的同时避免了网络的退化,但是网络层数的叠加也会造成网络参数量较多以及推理速度较慢的缺点. 从表 2中可以看出ResNet50和RegNet作为主干网络的DeepLabV3+模型的Params、FPS、MPA和MIoU都不如G_RegNetX4.
由图 7可知,通过观察发现各个网络能够快速稳定地达到收敛,且损失值在40个Epoch后开始趋于稳定,继续训练损失下降幅度微小,此时可以停止训练. 此外,以RegNet、MobileNetV3作为主干网络的MIoU训练曲线波动较大,训练效果不稳定.
综上所述,结合智能农机装备计算资源有限的特点,所建模型需保持一定分割精度及兼顾设备计算资源的限制,而G_RegNetX4主干网络在具有优良的分割效果的同时,还有参数总量少和推理速度快的优点.
-
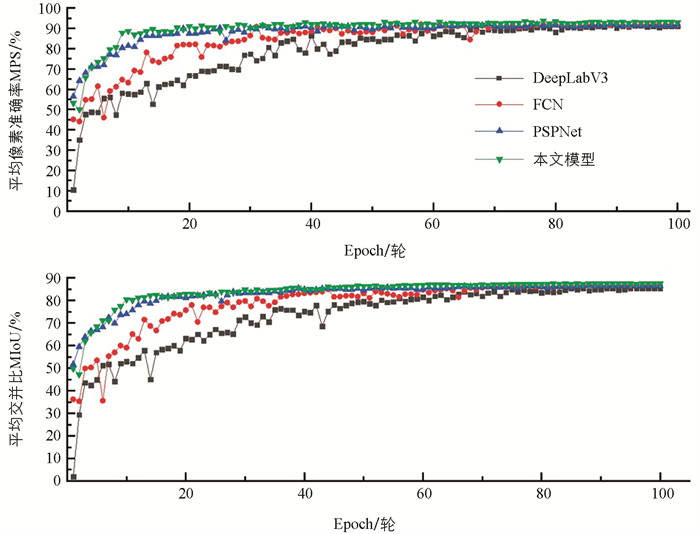
选用DeepLabV3[24]、FCN、PSPNet[25]模型与本文模型进行对比测试,通过PA、MPA、MIoU、Params、FLOPs和FPS等指标验证模型性能. 试验模型均加载主干网络预训练权重,并在丘陵田间道路训练集上训练. 在测试集上进行不同网络模型测试,并计算相关指标. 表 3记录了不同语义分割模型的Params、FPS及FLOPs. 从表 3可以看出本文模型的Params和FLOPs分别为14.71×106和49.34×109,相比于对比模型中较优秀的FCN模型,其Params和FLOPs分别减少了18.24×106和72.74×109,G_RegNetX4作为主干网络,在特征提取过程中注意到相似冗余特征的存在,使用廉价变化将部分低级特征映射到高级特征从而减少模型的计算量. 在推理分割图片时,本文模型的FPS为116.08 f/s,分别为DeepLabV3、FCN、PSPNet模型的1.83,1.33,1.76倍. 本文模型优势突出的原因是分割头为Lite-RASPP,聚合了不同尺度特征获取全局有效信息,同时精简网络结构从而提高网络推理速度.
分析图 8可知本文模型收敛速度快于其他模型,其中FCN和DeepLabV3在训练过程中收敛较慢且波动较大. 在60轮Epoch后各个网络均趋于稳定收敛,但本文模型的MPA与MIoU都高于其他模型.
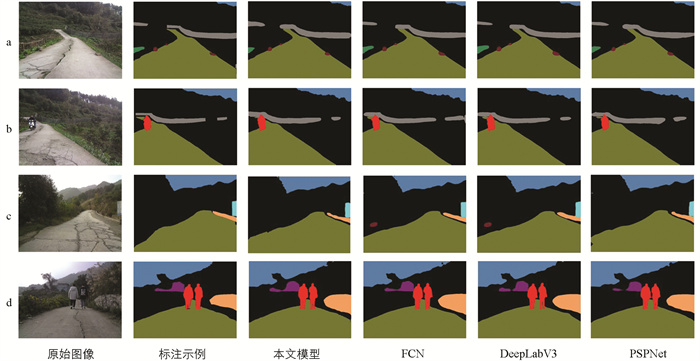
不同网络在测试集上的PA、MPA及MIoU由表 4可以看出,本文提出模型的PA、MPA和MIoU都要优于其他语义分割模型. 本文模型的MPA和MIoU分别为93.24%和87.6%,相比于DeepLabV3分别提高了1.8%和2.2%,比FCN分别提高了1.46%和0.8%,比PSPNet分别提高了1.48%和1%. 本文模型的主干网络采用G_RegNetX4是分割精度提升的主要原因,在G_RegNetX4的网络结构中结合残差模块部署G_Ghost模块,将复杂特征与低级特征融合从而提高分割精度. 图 9为本文模型在测试集上的分割效果对比.
从图 9可以看出,本文模型对丘陵田间道路中的动态目标、道路、障碍物等类别可以进行有效分割. 语义分割模型FCN和DeepLabV3在对障碍物类分割时出现分割错误,对图 9(c)预测分割时将道路两旁的物体预测为道路中的障碍物. PSPNet存在过分割的情况,处理物体边缘和细节复杂区域时易受到背景信息的干扰导致分割错误,如将图 9(d)中动态目标的边界分割错误. 本文模型使用的Lite-RASPP模块减少了模型的参数量,但在推理分割过程中影响了部分类别的边界分割精度导致边界不平滑,如图 9(c)中本文模型对挡墙边界的分割结果是波动的.
综合对比Params、FPS、FLOPs、MIoU、MPA及实际分割效果可知,所提出针对丘陵田间道路的语义分割模型相比于主流的语义分割模型在准确率相关指标的对比中是较优秀的;同时所提模型在Params、FPS及FLOPs的比较中也有大幅度的提升.
3.1. 训练环境
3.2. 模型训练
3.3. 评价指标
3.4. 主干网络验证
3.5. 模型性能试验
-
提出一种基于优化DeepLabV3+的丘陵田间道路图像语义分割模型,编码器环节采用轻量化的主干网络(G_RegNetX4)和轻量级的Lite-RASPP模块,在明显提升分割精度和推理速度的同时降低了参数总量和浮点计算量. 通过采集丘陵田间道路图像建立数据集并将对象属性划分为10个类别,构建测试集以进行模型分割效果测试. 结果表明所提出模型的平均交并比和平均像素准确率分别为87.6%,93.24%,具有准确率高及泛化性能好的优点. 将本文模型与FCN、DeepLabV3和PSPNet进行比较,发现其可以有效对丘陵田间道路进行分割,较好地实现了精度与速度的平衡. 考虑到未对分割后的田间道路场景图像提取视觉导航线,后续将进行相关研究以期更好地实现智能农机装备的自主导航.