



 下载:
下载:


-
开放科学(资源服务)标识码(OSID):

-
分心驾驶行为是指驾驶员将驾驶资源从对安全驾驶至关重要的任务转移到与之竞争的次任务上[1],这种资源分配失衡会影响驾驶绩效[2],最终威胁到行车安全。驾驶绩效的核心资源依赖视觉注意力与中枢神经处理的协同机制。当驾驶员进行驾驶次任务(如操作手机)时,会触发双重干扰效应:视觉干扰通过转移视线焦点造成目视监测中断;认知干扰通过占用大脑核心运算资源削弱驾驶决策能力[3],从而提高遇到风险场景时决策反应时间,增加事故发生概率[4]。根据美国国家公路交通管理局2023年公布的最新数据显示,2021年涉及分心驾驶的交通事故共造成3 522人死亡,较2020年增加了12.1%[5]。因此实时监测驾驶员驾驶状态,并对检测到的分心驾驶行为给予必要的预警,对保障行车安全具有重要意义。
为降低因驾驶员因素而导致的事故发生率,相关领域的研究学者们对驾驶员监管系统(Driver Monitor System,DMS)展开了深入研究。DMS系统主要功能是检测驾驶员在执行驾驶任务时是否呈现异常状态,并在检测到分心状态时及时发出警告予以纠正[6]。而在分心检测任务中,常用的检测算法有YOLO系列算法、ResNet与AlexNet等改进型卷积神经网络等[7]。根据获取信息特征可分为两类:驾驶人生理信号和驾驶风格特征。其中,关于驾驶风格研究,主要通过分析外部传感器采集到的平均车速、横向加速度标准差、方向盘转速等信息进行驾驶员状态分析[8],该方法虽能够识别驾驶员状态,但识别效果容易受天气、道路状况等客观因素影响[9];关于驾驶员生理信号研究,根据生理信号获取方式可分为侵入式和非侵入式两类[7]。侵入式是指通过智能手环、脑电帽等传感器进行持续、稳定的人机接触方式,获取生理信号[10]。此种方法虽然识别准确率高,但在一定程度上影响驾驶员安全驾驶能力,因此更适合于实验研究和数据采集场合。非侵入式借助计算机视觉技术与深度学习实现,通过车载摄像头实时收集驾驶员面部特征、头部姿态特征、动作行为特征等个体信息与标定物品(手机、水瓶等影响安全驾驶物品),并通过深度学习技术识别驾驶员动作和行为。此种方法成本低、准确率较高,不影响驾驶员安全驾驶,更适用于监控驾驶员[11-12]。
随着深度学习目标检测算法的多次迭代更新,以YOLO(You Only Look Once)[13]系列为代表的实时目标检测算法,广泛应用于目标识别领域中。目前Ultralytics公司推出的YOLOv11是YOLO系列目标检测算法的最新成果,在目标检测领域展现更加强大的性能[14]。而除了目标检测外,YOLO系列算法在姿态估计领域也发挥着举足轻重的作用[15]。因此越来越多的驾驶员状态检测方法选择了YOLO系列算法:为解决环境因素(光照、遮挡)导致的驾驶员检测精度低、误检等问题,文献[16]将Swin Transformer编码器、RepGFPN聚合网络等融合进YOLO-Pose,经实验测试,在复杂场景下仍能保持较高精度和鲁棒性;为提高模型在复杂场景下的识别准确性,文献[17]对YOLOv8颈部网络和SPPF模块进行改进,并集成全局注意力机制,增强YOLO算法在多尺度特征提取能力;文献[18]提出了一种多模态特征融合方法结合粒子群算法获取特征权重,通过捕捉时间依赖性,增强模型获取特征能力。
目前,深度学习在驾驶员分心行为检测方面取得重大进展,然而将现有的大部分研究成果应用在职业驾驶员群体上,会表现出明显的性能下降。这是因为大部分研究成果是基于普通驾驶员数据集训练得出,而职业驾驶员和普通驾驶员之间驾驶行为具有显著差异,进而产生跨领域适应问题[19],这会影响它们在职业驾驶员群体的应用。为了解决这些问题,本研究重新构建面向职业驾驶员群体的分心驾驶行为数据集。在YOLO模型选择上,为满足研究场景速度快、检测精度高的特点,选择参数量最小、检测速度最快的YOLOv8n作为本研究的基础模型。综上,本研究主要贡献包括:
1) 构建了一个专门面向职业驾驶员群体的分心驾驶行为数据集。该数据集从99名职业驾驶员日常驾驶过程中采集视频片段7 886条,累计时长约44 h,包含喝水、摄食、吸烟和使用手机4类典型分心行为,为后续分心驾驶行为识别研究提供了丰富、真实的数据基础。
2) 提出了一种基于YOLOv8的非接触式驾驶员分心驾驶行为检测方法。针对YOLOv8在多尺度特征提取能力不足以及检测速度较慢的问题,引入了卷积注意力模块(Convolutional Block Attention Module,CBAM)[20]与快速块模块(FasterBlock)[21],对网络结构进行优化改进。实验结果表明,该方法有效提升了模型在职业驾驶员分心行为识别任务中的检测精度与实时性,同时具备无侵入、易部署等优势,更符合实际驾驶环境下的应用需求。
全文HTML
-
现有的分心驾驶行为数据集(如100-Driver数据集[22]、SFDDD数据集[23]、QIN数据集[17]等)实验参与者群体未集中于职业驾驶员群体。研究表明非职业驾驶员驾驶习惯、驾驶风格等都与职业驾驶员有着显著差异,可能会导致模型在职业驾驶场景下的泛化性能下降[19]。为填补这一不足,我们重新构建一个面向职业驾驶员的分心驾驶行为数据集,在实验开始前,已从被试者获得关于本研究数据使用的知情同意。
1) 数据采集。使用两个海康威视摄像头收集分心驾驶行为数据。为确保采集数据角度的多样性,选择了两个角度,分别是左前方、右上方,多角度视图能够提供驾驶员出现分心行为时的全面视图,并且可用于后续评估模型对不同未知摄像头的泛化能力。用于收集分心驾驶行为的摄像头数量及具体安装位置如图 1所示。
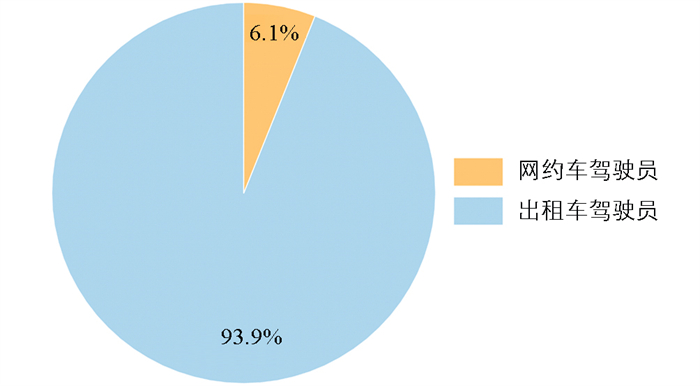
2) 参与实验群体特征。共招募99名持有C1驾驶证人员参与驾驶行为数据采集实验。样本群体按职业性质可分为出租车驾驶员、网约车驾驶员。其中出租车驾驶员93名,网约车驾驶员6名,如图 2所示。
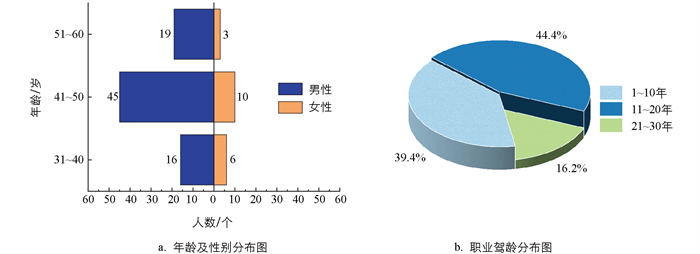
3) 职业驾驶员行为风格多样化。前面提到与非职业驾驶员相比,职业驾驶员驾驶风格、驾驶行为等都有着显著差异,为丰富数据集的驾驶行为,受邀参加实验的99名实验人员有着不同的年龄及职业驾龄,具体分布情况如图 3所示。
4) 环境因素。为了采集到的数据尽可能涵盖不同的驾驶环境,我们将被试者分成昼间组和夜间组,其中:昼间组共50名受试者,在9:00-15:00时段连续采集12 d数据;夜间组共49名被试者,在18:00-3:00时段连续采集8 d数据,涵盖了黄昏、夜间等不同光照条件。同时,涵盖了穿越隧道、早晚高峰期等不同驾驶环境,以此保证数据的全面性。
-
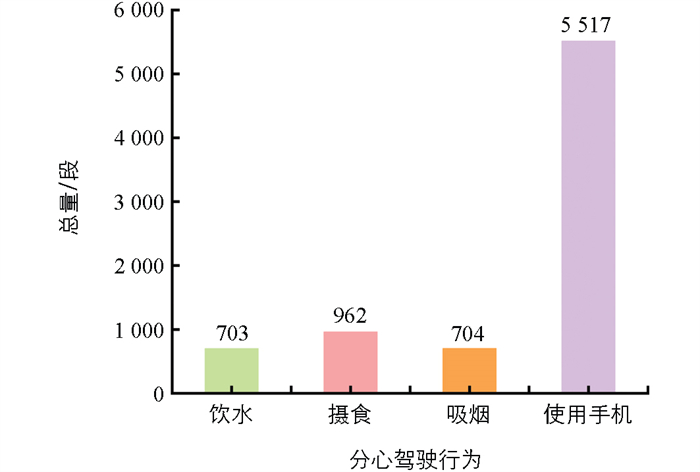
本研究计划构造的分心驾驶行为数据集划分为4个主要类别:摄食、吸烟、使用手机及饮水。基于此,本次实验共收集视频片段共7 886段。其中摄食962段、吸烟704段、使用手机5 517段、饮水703段,如图 4所示。
由于实验采集到的是视频数据,为满足模型训练需要,需要从视频进行抽帧完成原始数据集制作。考虑到在连续动作过程中相邻帧之间相似度较高,若不从数据集里将相似帧筛选出,则会降低数据集样本的多样性,进而影响模型的泛化能力。为尽可能保证数据之间存在较大差异,采取每2 s从视频片段抽取一帧的采集策略,获取了46 110张图片,并从中手动筛选出11 515张,完成数据集构建(示例图片见图 5)。完成数据的筛选后的数据集规模如表 1所示。
从表 1不难发现,使用手机规模占比最大,占比约为70.34%,主要原因在于智能手机会使人上瘾,促使用户产生与智能手机保持连接状态的情感需求[24],进而将大量时间消耗在智能手机上。然而使用手机数据占比过大容易导致训练模型过度关注此类分心行为,进而导致其他类别检测性能下降。因此为保证训练模型性能,需要平衡驾驶分心行为规模,通过随机抽选方式,抽取使用手机数据规模约1/5构建数据集、从100-Driver[22]随机抽取吸烟和饮水的分心行为数据进行补充。表 2展示本实验构建的分心驾驶行为数据集训练集、验证集和测试集的组成情况。
-
由于分心驾驶行为会受到个人驾驶习惯的影响而表现出显著差异,检测驾驶员分心驾驶行为仍是个艰巨挑战,而现有的分心驾驶行为数据集多聚焦于普通驾驶员人群,尚缺乏专门面向职业驾驶员群体的高质量数据集。据我们所知,目前没有专门的数据集聚焦于职业驾驶员人群。因此我们的数据集具有以下显著优势:首先,所有数据均来源于职业驾驶员群体,更贴近真实运营场景。其次,参与实验的职业驾驶员人数远超大部分数据集,在人数规模上仅次于目前最大的100-Driver数据集[22]。表 3对本数据集与现有节选数据集进行了详细比对。
1.1. 数据集描述
1.2. 数据处理
1.3. 数据集对比
-
为适应驾驶员分心驾驶行为快速识别需求,要求模型速度推理速度快速,因此选择YOLOv8系列中参数量最少且检测速度最快的YOLOv8n作为本研究基础模型。YOLOv8系列模型在COCO数据集展现了优越的性能,但是它在具有“快速、复杂、多变”的分心驾驶行为检测任务中仍存在以下问题[17]:
1) YOLOv8主干网络缺乏有效的全局信息集成模块。虽然作者通过跨阶段局部网络(Cross Stage Partial Network,CSP)架构和两层卷积跨阶段部分连接模块(CSP Bottleneck with 2 Convolutions,C2f)增强局部特征提取能力,但是全局信息能力的缺失,可能会降低模型有效捕捉多尺度分心驾驶行为的能力。
2) YOLOv8颈部网络在进行空间通道特征融合时,引入过多冗余信息,进而影响模型检测速度。
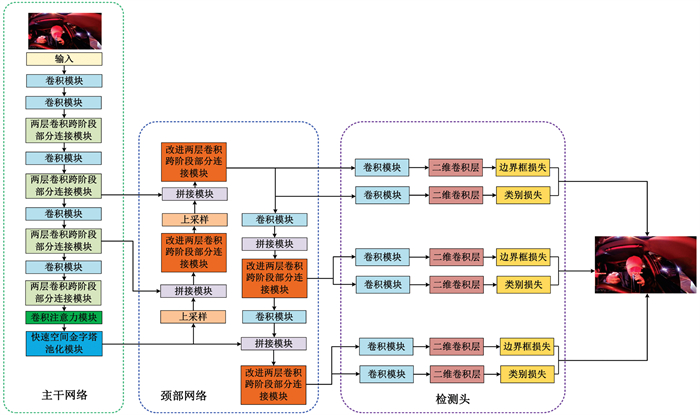
针对以上问题,对主干网络和颈部网络进行改进,改进后结构如图 6所示。
-
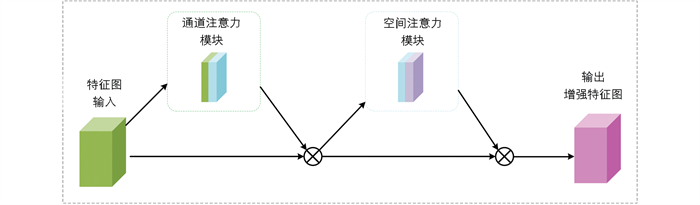
为增强YOLOv8对提取全局特征的总和能力,我们在空间金字塔池化(Spatial Pyramid Pooling Fast,SPPF)模块之前引入CBAM。CBAM[20]由通道注意力模块和空间注意力模块两个子模块构成。两个子模块通常串联使用:通道注意力模块对每个通道输入的特征进行加权处理,突出关键特征;之后空间注意力模块丰富其空间位置的关键信息。此过程同时考虑通道和空间信息,有助于网络更有针对性地关注重要特征。CBAM结构如图 7所示。
-
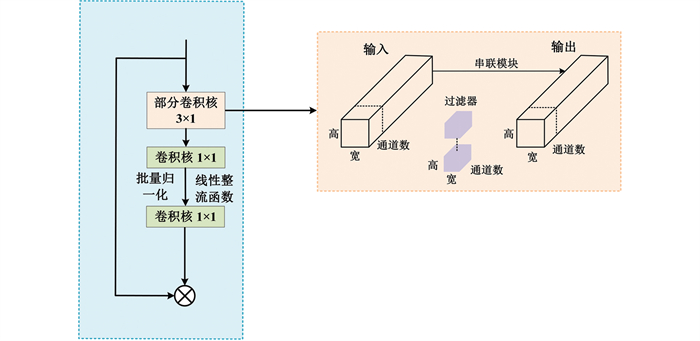
为克服颈部网络检测速度慢的问题,引入FasterBlock,该模块能够以较低的浮点运算量实现较高的模型性能,体现出良好的轻量化效果[21],具体结构如图 8所示。作者在该模块中提出一种部分卷积的新运算符(Partial Convolution,PConv),该卷积核能够使所在的FasterBlock具备速度快且参数少的优点。同时,内置的批量归一化模块(Batch Normalization,BN)能够允许FasterBlock与相邻的卷积核模块结合,进而加快推理速度。具体工作原理如下:FasterBlock在保持通道数不变的情况下,仅对输入特征中的一部分通道执行k×k常规卷积操作,余下通道则直接在1×1卷积中与卷积结果融合。PConv的每秒完成浮点运算次数(Floating Point Operations per Second,FLOPs)值为:
式中:fFast表示FasterBlock模块的总浮点运算次数;h、w分别为输入通道空间尺寸高、宽;k为滤波器卷积核尺寸(此处高、宽相等,因此统一变量为k);Cp为参与卷积操作的通道数。
公式(1)适用于仅对Cp通道执行卷积,且输出通道数也为Cp的场景。若卷积层完整输出C个通道,其中仅有Cp个通道参与卷积运算,则Cp和C共同构成的分离比定义为:
式中:r值代表被过滤器卷积的通道占比。
当
$\begin{equation} r=\frac{1}{4} \end{equation}$ 时,PConv的FLOPs值只有普通卷积的$ \frac{1}{16}$ ,并且PConv内存访问量达到最小值,其近似表达式为:因此,本文使用FasterBlock替换YOLOv8颈部网络的C2f模块中的瓶颈模块(Bottleneck),得到C2f-FasterBlock。
2.1. 基于改进YOLOv8n的分心驾驶行为检测模型
2.2. 融合CBAM的主干网络
2.3. C2f-FasterBlock模块
-
本研究定义的分心驾驶行为检测任务包括对象检测和分类两方面,同时将关注重点放在评估模型在测试集上的准确性。基于此,采用5个指标:准确率(Precision,P)、平均精度(mean Average Precision,mAP)、预测边界框与真实边界框交并比达到0.5时的总类平均值(mean Average Precisiona0.5%,mAP@0.5%)、召回率(Recall,R)和F1值(F1 Score,F1)。
各指标的定义如下所示,其中n为本文定义的驾驶分心行为的类别数量:
式中:TP表示实际为正样本,且被模型正确预测为正样本的数量;FP表示实际为负样本,但被模型错误预测为正样本的数量;FN表示实际为正样本,但被模型错误预测为负样本的数量;n是分心类别的总数;AP表示单个分心类型的检测精度
-
本研究以YOLOv8n为基准模型,分别使用YOLOv8n模型和本研究改进的模型,在本研究新构建的分心驾驶行为数据集中进行实验,本研究模型与YOLOv8n相比,在定义的4种分心驾驶行为类别上,在所有类别上的检测精度都有所提升。具体来说,“摄食”行为检测精度提升了3.53%、“吸烟”行为检测精度提升了5.96%、“使用手机”行为检测精度提升了4.92%、“饮水”行为检测精度提升了5.1%,效果如表 4所示。
改进模型召回率和F1值都有所提升,表明模型在对定义的分心驾驶行为保持较高检测精度的同时,减少了漏检情况的发生,对分心驾驶行为的整体识别能力有所增强。
值得注意的是,在定义的4种分心驾驶行为中,“摄食” “吸烟” “饮水”具有相似的检测精度且都低于“使用手机”检测精度。可能原因在于驾驶员在使用手机时,通常涉及明显的手部动作,如持握、滑动等操作,且手机在被使用时,常位于驾驶员正前方,靠近摄像头,具备清晰的外观特征和有利的拍摄角度,有助于模型识别。而另外3类分心驾驶行为,都具有相似的手部动作:即将物体送入口中,动作模式上高度相似,且相关物体常因距离较远,模型难以准确捕捉特征,进而导致识别难度较高,检测精度相对较低且差异不大,行为动作如图 9所示。
综上所述,根据表 4实验结果,所提出的改进模型在职业驾驶员分心驾驶行为识别任务中展现出较好的性能表现,具有一定的实用参考价值。
为评估各改进模块的贡献,在保持运行环境一致的前提下进行消融实验。如表 5所示,√表示使用相应的改进模块;g表示模型对单张图像推理所需的浮点运算总量,以十亿次为单位(Giga FLOPs,GFLOPs);p表示模型总参数量,以百万字节(Million Bytes,MB)为单位,反映模型的复杂度。
以YOLOv8n为基准模型,得到原始mAP@0.5为85.38%,参数量p为3、推理计算量g为8.2。在此基准上,单独引入CBAM,mAP@0.5提升至87.13%,计算量基本不变;引入C2f-FasterBlock,mAP@0.5提高到88.71%,同时将g和p分别降至7.1和2.5,体现出明显的轻量化优势。最后将两模块集成进行实验,mAP@0.5进一步提升至90.16%,尽管g和p小幅回升,但整体检测精度优于基准值,验证了本文改进策略的有效性。
3.1. 试验模型评价指标
3.2. 模型性能分析
-
本研究针对现有分心驾驶行为数据集数据未涵盖职业驾驶员群体特点,构建以职业驾驶员群体为主的分心驾驶行为数据集。同时针对YOLOv8局限性,进行针对性的改进,提高了算法对驾驶员分心驾驶行为的识别精度与检测速度。具体改进包括将CBAM融合进主干网络以及用FasterBlock替换颈部网络C2f模块中的残差块。实验结果表明,改进后的模型检测性能得到有效提升。
但值得注意的是,与文献[17, 22-23]相比,改进后检测准确率仍有较大提升空间,主要原因在于本研究所构建的数据集规模较小:约为SFDDD数据集[23]的
$\frac{1}{5}$ ;约为QIN数据集[17]的$\frac{1}{9}$ ;约为100-Driver数据集[22]的$\frac{1}{83}$ 。因此,为进一步提高模型的准确性和泛化能力,未来的研究将重点扩大数据集规模,特别是针对职业驾驶员的分心驾驶行为进行大规模数据采集,这一举措有助于丰富分心驾驶行为数据集的多样性,提升模型对真实场景的适应性,为交通安全领域提供更为可靠的技术支持。