


 下载:
下载:

-
开放科学(资源服务)标识码(OSID):

-
碳纤维增强复合材料(Carbon Fiber Reinforced Polymer,CFRP)是一种高比强度、高比刚度的轻质材料,目前被广泛应用于航空航天、汽车制造和轨道交通等众多领域。由CFRP蒙皮和蜂窝铝夹心组成的三明治结构在使用过程中常会受到外界物体的冲击作用,产生不同程度、多种类型的损伤。这些损伤往往出现在CFRP内部,可能会导致CFRP力学性能大幅下降。对于CFRP三明治结构受到低速冲击后所产生的损伤,研究人员往往通过构建物理模型进行研究[1-4],然而CFRP三明治结构在冲击载荷作用下,仿真计算效率较低,因此基于数据挖掘和深度学习等人工智能技术为CFRP三明治结构受到低速冲击后的损伤预测提供了一种新的思路[5]。
近年来,国内外学者将深度学习技术广泛应用于复合材料研究领域,并取得显著进展。Karsandik等[6]总结了影响复合材料夹层结构冲击力学行为的主要参数;Li等[7]提出将弹性体引入CFRP铺层形成新型三明治结构,研究表明其在低速冲击下具有优异性能;Liao等[8]开发出一种结合主成分分析与卷积神经网络(Convolutional Neural Networks,CNN)的特征提取方法,在ResNet50架构下显著提升了模型效能;Chen等[9]通过改进RegNet模型中的激活函数,使分类准确率达到99.5%;Sumit等[10]提出轻量级CNN模型,将知识蒸馏与超参数优化相结合,实现模型尺寸显著缩减的同时保持预测性能。在图像处理领域,Oliveira等[11]采用U型网络对CFRP低速冲击损伤进行分割,在4种传统方法中表现最优;Liu等[12]提出基于深度学习的缺陷剖面重建方法,在细节表征上超过传统热成像后处理;Wei等[13]将人工智能和红外热成像相结合,以检测和分割弯曲层压板的冲击损伤;Oliver等[14]开发出一种模态数据驱动的人工神经网络复合材料损伤检测系统,准确率达95%;Deng等[15]基于深度学习方法提出了一个新的框架,以研究CFRP中出现的几乎不可见的冲击损伤(Barely Visible Impact Damage,BVID)特征与测试冲击能量之间的关系;Cao等[16]设计双流CNN用于一维热信号分类,实现缺陷区域精确识别。在深度学习模型优化方面,Saeed等[17]结合CNN和DFF-NN算法开发智能后处理器,对缺陷进行检测与深度估计;Dong等[18]提出三维CNN模型,在单个缺陷检测任务中超越传统方法;Hu等[19]创新性地融合时空特征,提出了基于注意力模块的新型热成像缺陷检测模型,显著提升了结果的精度和鲁棒性;Deng等[20]构建结合注意力机制的时空深度学习框架,成功建立了BVID与能级影响的关系模型;徐杰[21]提出了一种基于深度学习和损伤图像来预测车用CFRP冲击能量的方法;Hasebe等[22]结合特征工程,使用机器学习模型确认了从CFRP表面损伤剖面推断低速冲击信息的可能性;端木正等[23]使用改进后的深度学习模型进行材料设计;杜禹樵等[24]基于人工神经网络深度学习算法,设计了一套CFRP损伤监测系统;Wang等[25]通过深度学习方法对复合材料的宏观等效特性进行预测,预测结果与有限元仿真误差不超过0.5%;王敏等[26]对碳纳米管/碳纤维增强型复合材料(Carbon Nanotube/Carbon Fibre Reinforced Polymer,CNT/CFRP)在低速冲击下的响应和破坏进行了数值模拟研究,结果表明在相同的冲击能量下,更大的冲击速度会造成更多的拉伸破坏;Huang等[27]使用机器学习高效准确地预测了CNT增强水泥复合材料的力学性能;Yang等[28]提出了一种基于迁移学习的逆方法,通过吸能结构的变形图片提取复合材料的结构参数和耐撞特性;Loutas等[29]提出了一种将数值模拟和主动学习相结合的方法,能够快速有效地搜索仿生多级不连续纤维复合材料几何参数的设计空间;钱奇伟等[30]采用深度学习算法,对大量三维编织碳/碳(Carbon Fiber Reinforced Carbon,C/C)复合材料的微观X射线计算机断层扫描(Micro X-ray Computed Tomography,XCT)图像进行训练,结果表明深度学习算法能够有效过滤噪声与伪影并自动精准分割各组分和缺陷;Fonseca等[31]结合有限元、人工智能和进化搜索方法,实现了混合动力汽车结构及其塑料注塑成型工艺的增强。
综上所述,目前深度学习在复合材料冲击损伤检测领域中的应用,其数据集大多来源于红外热成像等试验技术,然而相关技术需要大量的试验和制备成本,并且可获得的数据集样本有限。因此,本研究使用有限元仿真得到的CFRP蜂窝铝三明治结构低速冲击损伤图像作为数据来源,提出一种融合多头注意力机制的深度学习方法,对三明治结构冲击能量进行预测,采用ResNet50和RegNet 2种神经网络对数据集进行训练,并分别在ResNet50网络的全局平均池化层(Global Average Pooling,GAP)之前和RegNet网络的初始卷积层之后添加注意力模块,使2种网络的准确率得到提升,为CFRP蜂窝铝三明治结构冲击能量预测研究提供一种新的参考,同时也为车辆碰撞性能的研究开拓一种新的思路。
全文HTML
-
本研究基于深度学习模型对CFRP蜂窝铝三明治结构的冲击能量进行预测。深度学习模型构建与训练过程中需要大量的三明治结构冲击行为和损伤信息数据集,仅依靠冲击试验获得的数据集面临着试验成本高、周期长以及信息表征局限等问题,因此本研究采用有限元仿真模型对CFRP蜂窝铝三明治结构进行低速冲击模拟,可以快速、大量获取深度学习模型所需数据集。
-
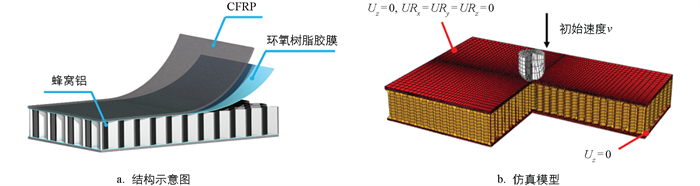
采用Abaqus/Explicit进行低速冲击模拟,该模型由具有初速度的刚性冲击器以及CFRP蜂窝铝三明治结构模型组成,如图 1所示。按照实际低速冲击试验夹具约束方式对三明治结构夹持区域所有自由度进行约束,图 1b中Uz表示z方向平移自由度,URx、URy、URz分别表示绕x、y、z轴的旋转自由度。
采用孤立网格偏置方法对CFRP蜂窝铝三明治结构进行建模[7],为确保模型精度,提高计算效率,将上、下蒙皮的网格划分为渐进式网格,使得靠近冲击中心的网格更密。按照实际结构进行偏置得到上、下蒙皮模型,其中CFRP层内采用SC8R单元、层间采用COH3D8单元进行建模。蜂窝铝模型采用S4R单元进行建模,网格尺寸为1 mm。蜂窝和上、下蒙皮之间使用Tie连接进行绑定,同时,由于蜂窝和蒙皮之间的连接是较为脆弱的线连接,在蒙皮和蜂窝之间设置层间单元以模拟蒙皮和蜂窝的脱黏行为。采用surface to surface接触算法定义刚性冲击器和三明治结构中心区域的接触以及蜂窝面板和蜂窝之间的自接触行为,摩擦因数μ=0.3。蜂窝结构的材料选用5052系铝合金,并采用Johnson-Cook(J-C)模型对蜂窝铝的塑性变形和失效进行模拟。
-
为验证所建仿真模型的准确性,开展9 J和14 J能量下的CFRP蜂窝铝三明治结构低速冲击试验,并将试验数据与仿真模型进行对比,本研究以冲击后CFRP蜂窝铝冲击侧的形变程度作为对标指标。图 2分别展示了9 J和14 J冲击后试验损伤形貌和仿真模型形变云图的对比,可以发现仿真模型形变云图与对应低速冲击试验中CFRP蜂窝铝三明治结构的损伤形貌展现出较高的一致性。
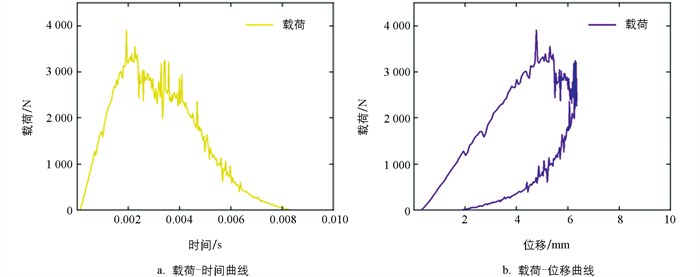
如图 2a所示,在9 J冲击下,上蒙皮冲击侧出现了较明显的凹陷,主要损伤形式为基体开裂,冲击凹坑与上蒙皮平面连接较为平滑,这一点在对应的9 J冲击仿真模型形变云图中的表现相同。如图 2b所示,在14 J冲击下,试验样件出现了剧烈的纤维断裂损伤,冲击中心形变出现大幅增加,冲击坑与面板之间的界限明显;在14 J冲击仿真模型形变云图中,冲击中心出现了由纤维断裂造成的较大变形,并且冲击中心与蒙皮平面存在明显界限。因此,仿真模型能够较好地模拟CFRP蜂窝铝三明治结构在2种冲击能量下的冲击行为和损伤形式,具有较高的准确性和可信度。此外,CFRP蜂窝铝三明治结构受落锤冲击后的载荷-时间曲线和载荷-位移曲线如图 3所示,说明该仿真模型在三明治结构的冲击行为和损伤模拟方面满足研究要求。
1.1. 有限元模型
1.2. 仿真验证
-
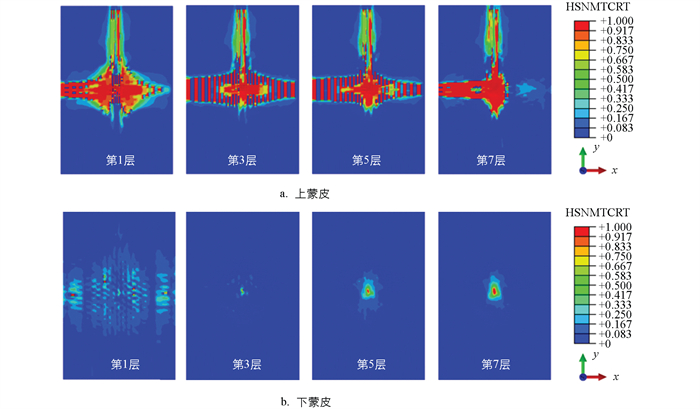
本研究建立了5组低速冲击仿真模型,冲击能量分别为4 J、7 J、9 J、12 J和14 J。在每组冲击能量下,通过修改冲击锤头质量与速度,进行多个不同组合的仿真,以提高可获得数据的体量。由仿真结果可知,蜂窝铝产生的塑性变形在冲击过程中起到了一定的缓冲作用。CFRP蜂窝铝夹心层合板的下蒙皮只受到了很小的损伤,损伤程度并不明显。图 4分别展示了上、下蒙皮的基体拉伸损伤情况。在创建数据集时,仅获取上蒙皮各层的基体拉伸损伤图像,然后通过Abaqus运行Python脚本快速得到仿真结果中的原始损伤图像。
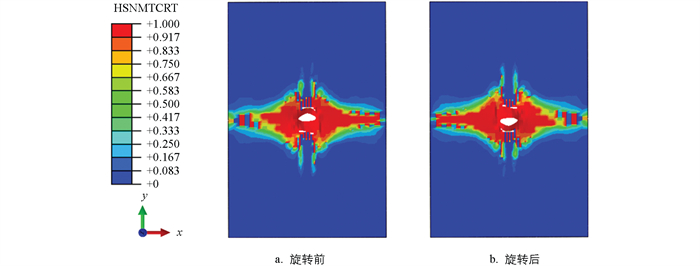
在构建数据集时,本研究采用了一种数据扩充的方法,即在1个仿真模型的第300帧到500帧中每20帧取1组损伤图像构建数据集,这样可以有效减少时间成本,所得到的图像数据集满足深度学习模型训练的要求。此外,通过仿真结果得到的原始数据集不能直接用来训练模型,还需要对图像进行预处理来防止模型的过拟合。在原始图像中,有部分是图例信息,可视为损伤图像的噪声,为了简化网络计算以及去除背景和其他噪点的干扰,将原始损伤图像像素裁剪为310×412。此外,为了增强神经网络的鲁棒性,对数据进行扩充及转换。对于同一张图片,结果应具有旋转不变性,因此对图像进行随机旋转。图 5展示了旋转180°前后的损伤图像,最终得到处理好的损伤图像数据集。
-
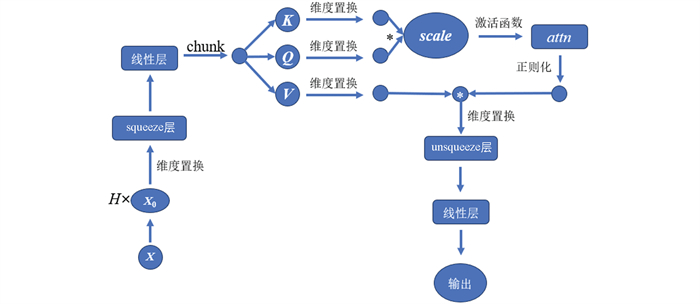
注意力机制模块在深度学习神经网络中的作用类似于人类视觉注意力的机制,它允许模型在处理数据信息时能够聚焦于当前任务的重要部分,从而提高模型的性能和效率。本研究采用的注意力机制是一种多头注意力机制(Multi-Head Attention),其主要思想是分别聚焦数据集中的多个方面,多个“头”采取并行的方式,对数据集中不同的特点进行注意力分数的计算,最终将所有“头”的注意力分数拼接起来,通过1个线性变换得到多头注意力机制的最终输出。多头注意力模块的算法流程如图 6所示,其中头数H为16。当模型的输入是一批图像时,输入矩阵为(batch_size,channel,height,width),通过模型将矩阵展平为(batch_size,sequence_length,inner_dim*3)作为输入X进行计算。
首先将输入矩阵X映射到多个“头”中,得到多个子矩阵X0,再将输入的子矩阵进行维度置换并经过1个squeeze层,随后再经过1个线性层进行线性变换,通过chunk函数输出3个矩阵,分别为键矩阵K、查询矩阵Q、值矩阵V,公式为:
式中:W为线性层的权重矩阵。
将K、Q、V矩阵维度置换之后对K和Q做点积运算求得注意力分数,公式为
式中:dotsij为注意力分数,衡量了第i个查询和第j个键的相关性;Qi为查询矩阵的第i行;Kj为键矩阵的第j列;dk为键矩阵的维度,这里等于dim_head;
$\begin{equation} \frac{1}{\sqrt{d_k}} \end{equation}$ 为缩放点积注意力中的缩放因子。将运算结果通过Softmax归一化为概率分布得到注意力权重Aij,公式为:
随后,通过Dropout操作,对Aij进行随机失活,防止过拟合,将Aij与V进行加权求和,得到每个“头”的输出,公式为:
式中:Ohi为第h个“头”的第i个输出;Vj为值矩阵的第j行。
对得到的结果矩阵通过unsqueeze层进行增维重排,并将所有“头”的输出通过线性层nn.Linear拼接之后得到最终的注意力输出。
由上述注意力模块的计算过程可知,注意力机制的输入数据与其输出加权和向量的大小是一致的,即注意力机制并不会改变输入矩阵的形状。因此,通过torch生成1个形状与输入数据相同的随机矩阵,将函数输入该随机矩阵,观察函数输出矩阵的形状。若输出矩阵的形状与输入随机矩阵的形状一致,则该注意力机制便可以使用。由于本研究使用的图像数据是每次输入大小为(64,3,224,224)的矩阵,数组中的4个参数代表(batch_size,channel,height,width),而该注意力模块需要的输入为三维矩阵,因此将矩阵中的height和width相乘,并做换序处理,作为模块的输入。随后生成1个大小为(64,224×224,3)的随机矩阵作为试验,输出的矩阵形状与输入的随机矩阵形状一致,注意力模块即可以使用。
注意力机制的本质是神经网络中前向传播中的加权环节,因此在向模型中添加注意力机制时,核心目标是通过动态计算权重来突出输入数据中与当前任务更相关或重要的部分,从而使模型能够更有效地聚焦于关键信息,提升性能和效果。将注意力机制函数添加到模型当中,在模型前向传播forward函数中调用注意力机制函数,对输入数据进行注意力加权,输出后继续进行前向传播的剩余计算。不同的模型结构不同,对应的前向传播步骤也不同,因此对于不同的模型,注意力机制函数添加在forward函数中的具体位置也不同,必要时需要将卷积、循环等操作进行添加。从模型优化的角度来看,注意力模块的添加位置存在多种选择策略,包括层级间嵌入和残差连接嵌入。
-
本研究的神经网络模型是基于PyTorch 2.1.2版本实现的。为了训练模型,采用分类交叉熵损失函数,初始的训练学习率为0.001,模型迭代步数为100。交叉熵损失函数是一种常用于分类任务的损失函数,它通过衡量模型预测的概率分布与真实分布之间的差异来优化模型参数,其核心思想是让模型预测的正确类别概率尽可能接近1,从而指导模型的训练方向。交叉熵损失函数的优点在于能够明确地反映预测与真实标签之间的差异,并且在与Softmax函数结合后具有良好的数值稳定性。然而,其对预测错误的惩罚较大,容易受到异常值的影响,并且需要模型输出概率分布。
深度学习中神经网络是一个大规模的、非线性的、自适应的动态系统,由许多相互连接的单元组成。神经网络结构中的基本单元是人工神经单元或神经元,它通过激活函数将上一层的线性加权和转换为非线性激活值传递到下一层。激活函数有多种类型,最常用的有Sigmod、tanh、整流线性单元(ReLU)、Softmax。表 1展示了几种深度学习中常用的激活函数表达式和取值范围。与非线性激活函数(Sigmod和tanh)相比,ReLU不存在梯度消失问题,其非负区间的梯度是恒定的,因此该模型的收敛率保持在稳定状态;Softmax函数一般只用于网络的最后一层进行分类和归一化。
随机梯度下降(Stochastic Gradient Descent,SGD)是一种常用的深度学习优化方法,在处理大型数据集时具有优势,其主要思想是每次迭代过程中随机选择1个样本或小批量样本,然后再计算这个样本或小批量样本的梯度,并用其更新模型的参数达到训练模型的目的。它的优点是计算非常简单,每次计算只需要1个样本或小批量的梯度即可完成,收敛速度较快,调整学习率也可以使其更加优秀地适应不同的图像特征。
ResNet50是一种经典的深度卷积神经网络,由多个层构成,包括卷积、批量归一化、激活函数、池化和全连接等,其核心在于通过残差块解决梯度爆炸问题,使网络训练更深层,从而提取更复杂的特征。本研究将注意力机制添加到ResNet50网络的全局平均池化层之前,即在模型将特征图转化为特征向量之前添加注意力。在网络接近输出的位置添加注意力机制,能够对前面所有阶段提取的特征进行最后的整合和筛选,聚焦于最具判别性的特征,使得最终输入到全连接层的特征向量更具有代表性,从而提高模型的准确率。通过关注主要特征,减少无关信息的干扰,有助于模型更好地泛化到不同的数据集合任务中。
RegNet是一种基于神经架构搜索(Neural Architecture Search,NAS)技术的卷积神经网络,以系统方式探索高效网络结构,在有限计算资源下实现优异的表现。RegNet采用层次化设计,分为多个阶段,每个阶段由相同模块组成,结构规则化,便于训练和部署。每个模块使用瓶颈结构,包括降维、特征提取和升维3个步骤,与ResNet50类似,但更注重宽度、深度的平衡,通过优化参数将特征表达能力最大化。本研究将注意力机制添加到RegNet网络的初始卷积层之后,初始卷积层负责提取图像的底层特征,如边缘和纹理信息。在此处添加多头注意力机制,模型可以在早期就聚焦于图像中的关键区域和特征,增强底层特征的表达。同时通过引入全局信息,让模型初始便对图像整体布局有所了解,有助于后续网络模块更好地理解图像,提升后续深层特征提取的有效性。
本研究将准备好的数据集按照70%训练集、15%验证集和15%测试集的比例将图像数据进行划分,其中测试集的数据由未包含在训练过程中的损伤图像组成,确保了对模型泛化到未见损伤图像样本能力的严格评估。训练模型时,以CFRP蜂窝铝夹心层合板基体拉伸损伤图像为输入,层合板受到的冲击能量为输出进行训练,实现图像识别的分类功能。训练过程中采用小批量学习方法,当损失值减小到一定值、准确率趋于稳定不再上升或者模型无法收敛时结束模型的训练,超参数的值取训练迭代过程中准确率最高的训练参数数据。训练和测试过程在每个模型上重复3次,每次重复会再次重新随机分配训练集、验证集和测试集,取训练结果最优的模型。
2.1. 数据集构建
2.2. 注意力机制算法
2.3. 深度学习模型配置与训练
-
本研究采用准确率A(Accuracy)对模型进行评估,计算公式如下:
式中:TP(True Positive)为做出Positive的判定,且判定是正确的次数;FP(False Positive)为做出Positive的判定,但判定是错误的次数;TN(True Negative)为做出Negative的判定,但判定是正确的次数;FN(False Negative)为做出Negative的判定,但判定是错误的次数。
表现优异的模型,其准确率在90%以上,并且不会出现梯度爆炸以及梯度消失的情况。损失值的大小随着迭代过程而不断降低,当接近于0时,模型中的超参数几乎不再更替变化,模型趋于稳定,准确率也不再有明显的变化,此时不需要对模型进行再训练。因此,在训练的时候若出现迭代次数未达到训练步数的设定值就停止的情况,这并不会影响试验数据和结果,反而提高了训练效率,节省了时间成本。
-
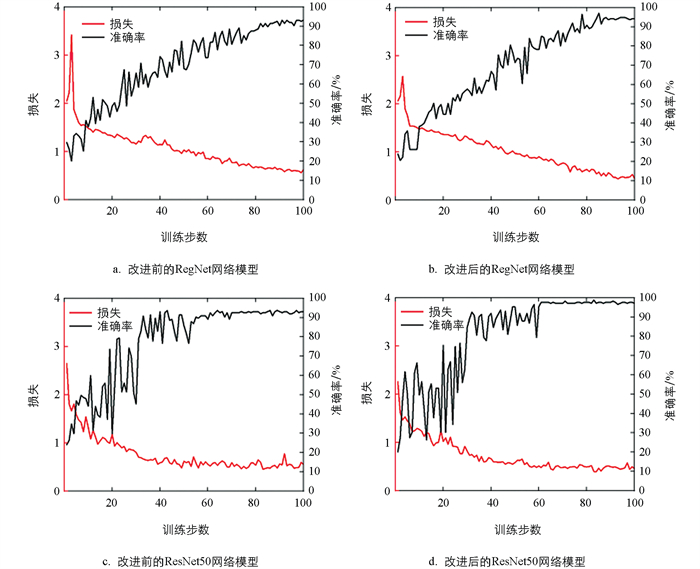
将改进前后的ResNet50和RegNet网络模型训练得到的准确率与损失曲线进行对比,如图 7所示。由图 7a、7c可以看出,改进前2种模型的训练曲线在训练动态与性能表现上具有显著差异。ResNet50的损失曲线在训练初期快速下降,体现出模型对数据特征的初期学习效率,可迅速缩小预测值与真实值之间的差距;进入训练中期后损失曲线下降平滑,反映出训练稳定,网络稳步收敛,其准确率曲线平均值也趋于稳定,但中期准确率不断震荡,说明模型对数据特征提取模式未稳固;训练后期,ResNet50的损失曲线基本收敛于一个较小的值,准确率增长趋缓,稳定在93.7%左右。而RegNet的损失曲线在训练初期虽有大幅下降,但相较ResNet50更保守,无剧烈震荡;训练中期损失曲线持续稳步降低,波动幅度小,这得益于其网络结构对梯度传播的优化,参数更新更加有效,而准确率曲线虽呈持续上升趋势,但模型整体收敛缓慢,最终可能并未完全收敛;最后RegNet的准确率达到93.1%左右,损失曲线收敛水平比ResNet50低,说明RegNet收敛缓慢,对信息的提取能力也不如ResNet50。
综合对比,ResNet50能够更加高效地提取图像信息,而RegNet收敛缓慢,并且准确率相较于ResNet50更低,对信息的特征提取能力不如ResNet50。这一差异凸显了不同网络结构处理训练动态能力的差异,即RegNet的设计性能更加保守,而ResNet50的学习能力更强。
-
ResNet50网络模型在添加多头注意力机制之后,训练得到的准确率与损失曲线如图 7d所示。对比图 7c、7d可知,ResNet50在添加多头注意力机制前后的训练曲线出现明显的变化。在未添加多头注意力机制时,模型的训练过程表现出较大的不稳定性,主要表现为损失曲线波动剧烈,尤其是训练步数在20~40阶段,准确率曲线也相应出现高频震荡。这表明模型对数据噪声和复杂样本较为敏感,特征提取模式不够稳定。在引入多头注意力机制后,训练的稳定性得到了显著提升,主要表现为损失曲线的波动幅度大幅减小,下降趋势更加平滑,准确率曲线的震荡频率和幅度也明显降低。这种改进源于多头注意力机制的作用,它使模型能够更好地关注关键特征,同时抑制无关信息,从而帮助模型更稳定地捕捉数据的内在模式并逐步固化特征提取方式。
模型训练效果如表 2所示,从收敛效果来看,在未添加多头注意力机制时,ResNet50网络模型的损失曲线虽然在后期持续下降,但最终仍停留在相对较高的水平,而准确率增长也在后期趋于平缓,这表明模型存在一定的拟合瓶颈,难以深入挖掘数据中的深层特征。相比之下,添加多头注意力机制后,损失曲线收敛到更低的值,说明模型对任务的拟合能力得到了显著提升,同时准确率也达到了更高水平,稳定在98.9%左右,这表明多头注意力机制有效增强了模型的特征表征能力,其核心作用在于通过并行计算多个子空间的注意力分布,使模型能够从多个角度捕捉数据特征之间的关联关系,尤其是在处理图像中的长距离依赖和关键信息区域时表现出明显优势。这种机制弥补了原始ResNet50在特征筛选和权重分配上的局限,使模型能够更高效地利用数据信息。不仅如此,它同时还优化了训练的稳定性、收敛性能以及特征学习能力,实现了模型综合表现的全面提升。
RegNet网络模型在添加多头注意力机制之后,训练得到的准确率与损失曲线如图 7b所示。对比图 7a、7b可知,RegNet在添加多头注意力机制前后的训练曲线出现明显的变化。在未添加多头注意力机制时,模型在训练初期表现出快速下降的损失曲线,随后在训练中期出现了较大的波动,这表明模型在训练过程中的稳定性不足,容易受到数据特征的干扰影响。同时,准确率曲线虽然总体呈上升趋势,但伴随着频繁的振荡,反映出模型在特征提取过程中缺乏稳定性,导致对样本的判别能力无法持续提升。在引入多头注意力机制后,模型的训练稳定性得到了显著改善,损失曲线的波动幅度明显减小,下降趋势更加平缓,这说明模型在优化过程中能够更稳定地逼近最优解。而准确率曲线也表现出更低的振荡频率和幅度,上升趋势更加平稳,表明模型能够持续且稳定地学习数据特征,从而减少了因特征学习不充分导致的预测波动。从收敛效果来看,在未添加注意力机制的情况下,损失曲线在后期虽然继续下降,但仍然存在一定的优化空间,准确率曲线的增长也显得乏力。而通过引入多头注意力机制后,损失曲线进一步收敛到更低的水平,表明模型对任务的拟合更加充分,同时准确率达到更高的水平,并稳定在97.1%,这充分体现了多头注意力机制对模型特征表征能力的显著提升。
多头注意力机制通过专注于关键区域和重要特征,抑制无关干扰信息,从而提高了特征提取的质量。同时,其多子空间并行计算的特性能够捕捉不同维度的特征关联,这弥补了原始RegNet在特征权重分配上的不足,使得模型能够更高效地利用数据中的关键信息,不仅优化了训练过程,还显著提升了最终的分类性能。通过这种双重提升,RegNet在处理复杂特征时展现出更强的优势,并能更充分地挖掘数据的潜在价值,表明引入多头注意力机制是RegNet网络模型优化和性能提升的一种有效方法。
综上所述,通过多头注意力机制的添加,大幅提升了ResNet50网络模型的训练稳定性和特征学习能力,而RegNet网络模型在特征学习能力方面也得到提升,但模型收敛仍然较为缓慢。
3.1. 不同深度学习模型效果对比
3.2. 改进后的深度学习模型效果对比
-
本研究针对CFRP蜂窝铝三明治结构,利用深度学习方法构建了材料内部损伤和所受冲击能量之间的关系,借助有限元仿真,避免了获取数据集时浪费过多的试验和制备成本。分别在深度学习模型ResNet50和RegNet中引入一种多头注意力机制模块进行改进,改进后的2种网络模型相较于原模型,其准确率和效率都有不同程度的提升。最终,改进后ResNet50和RegNet的准确率分别达到了98.9%和97.1%,在通过损伤图像预测冲击能量的任务中达到了理想的效果。同时,本研究还引入了一种在有限数据体量情况下高效扩充数据集的方法,提高了数据准备的效率。本研究在冲击能量预测的方法上具有普适性,可应用到其他复合材料损伤图像和损伤指标预测中,为复合材料冲击力学性能研究提供了一种新的思路和参考。