


 下载:
下载:

-
分布式拒绝服务(Distributed Denial of Service,DDoS)攻击由于攻击签名不断变化而很难防御,对各种业务和企业构成了严重威胁[1-2].快速有效的网络流量识别和分类可以显著提高网络安全,由于传输数据的大小不断增加以及可用的应用程序的多样性,必须通过流量分析进行流量优先级排序和诊断监控[3-5].信息多样性或传播对网络流量分类来说是一个很大的挑战,信息传播意味着每种类型的流量都可以具有独特的特征或统计属性.集体分类指使用所有可能的信息对一组相互关联的对象进行分类,为了执行集体分类任务,需要为流量实例的初始群体检索类别标签,并在下一轮分类中使用这类标签.因此,在对整个业务进行分类之前需要用所需的信息来标记部分被选择的实例,并且确定它们对于不同类别的归属.基于初始信息可以成批对网络流量的所有其他剩余实例进行分类[6].
主动学习是半监督机器学习的一种特例[7-8],其中学习算法能够交互式地查询用户(或某些其他信息源)以获得新数据点上的期望输出,被称为最佳实验设计[9].虽然存在未标记数据丰富的情况,但是手动标记这些数据成本非常昂贵,而学习算法可以主动地向用户、教师或专家查询标签,这种类型的迭代监督学习称为主动学习.由于学习者选择示例,因此用于学习概念的示例数量通常会远远低于正常监督学习所需的数量.本文使用具有较少训练实例的主动学习法来处理大量的网络流量.
能够正确和快速地检测DDoS攻击是网络安全需要解决的关键技术.近年来,有关DDoS攻击检测系统的研究已取得若干成果.文献[10]提出了一种基于多级自动编码器特征学习的高效DDoS攻击检测技术,该技术以无监督方式学习多层次的浅层和深层自动编码器来对训练和测试数据进行编码,以用于特征再生,通过使用有效的多核学习算法组合多级特征来学习最终的统一检测模型.文献[11]比较了集中式和分布式特征选择方法,该方法垂直或水平地划分数据集,可以在显著减少运行时间的情况下获得更高的分类性能.文献[12]提出了一个快速最小冗余最大相关性算法,并在几个不同的平台上得到了实现,即用于顺序执行的中央处理器(CPU)、用于并行计算的图形处理器以及用于使用大数据技术进行分布式计算的Apache Spark.
结合文献[11]划分数据集的方法和文献[12]快速最小冗余最大相关性算法的优点,本文提出一种基于并行积累排序算法和主动学习的DDoS攻击检测技术.该技术在GPU的核心之间分配海量网络流量数据集的计算负载,并将特征选择方法局部应用于每个核心,可以处理大型数据集,并在不影响质量的情况下近乎实时地对其进行处理.本文首先在并行计算环境中以积累排序方式来对网络流量进行排序,以此选择最佳特征子集.为了大量处理网络流量,通过专家模块以无监督的方式选择适当的实例来训练SVM二值分类器,从而实现从大容量网络流量选择小批量训练样本产生高精度网络流量的分类目的.实验结果显示,本文算法在执行时间和分类准确度性能方面优于其他方法.
全文HTML
-
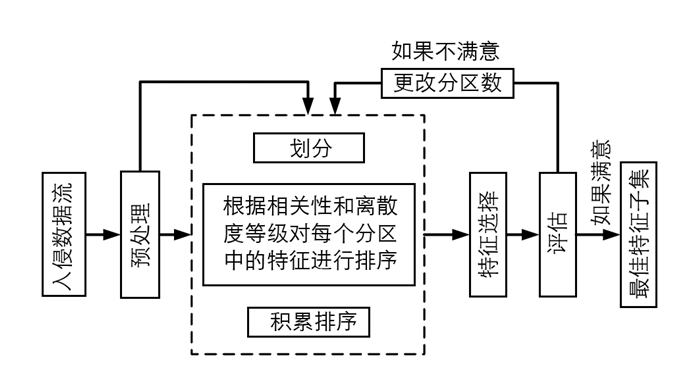
并行积累排序(Parallel Cumulative Rank,PCR)算法在GPU核心之间分配海量网络流量数据集的计算负载,并将特征选择方法局部应用于每个核心,将所选择的特征放在一起并在累积的基础上进行排序,以此实现在不影响质量的情况下近乎实时地处理大型数据集.本文PCR框架如图 1所示,PCR算法有3个主要任务:特征排序、特征选择和数据分类.
-
特征排序首先对数据集每个分区的特征进行排序,特征的等级定义了特征的相关性和非冗余性,通过组合每个部分的单个排序来计算全局或累积排序,等级越高被包括在用于分类的特征子集中的可能性越高.特征排序有3个并行执行的子任务:预处理、数据分区和平行排序.
(1) 预处理
选择网络流量的5个属性来构建原型,即每个流量样本的源IP地址(F1)、目的IP地址(F2)、源端口号(F3)、目的端口号(F4)和帧长度(F5).从包含大约100万个数据包的流量数据中获得这些属性的值.
(2) 数据集分区
为了进行分布式并行计算,本文对网络流量数据进行垂直划分.本文改变分区的数量,计算每个分区中每个特征的排序,并跟踪顺序环境和并行环境中的执行时间.
(3) 平行排序
每个分区都在具有GPU的机器上处理,没有任何重叠.对每个分区单独执行秩计算,同时考虑相关性和冗余性来计算属性的等级,使用相关性排序和离散度等级两种方法来推导每个特征的等级,根据样本集合中属性的唯一性找到特征的等级.相关性排序提供属性之间的水平唯一性,离散排序提供属性之间的垂直唯一性.
定义1:相关等级Ri被定义为特征fi的等级,由相关系数Cori相对于给定类别s′的特征子集Ci的所有其他特征给出.该系数给出了特征fi与来自相同子集的所有其他特征的相关性的度量.
定义2:散度等级Di被定义为特征fi的等级,由散度系数或散度指数Dispi相对于给定类别s′的特征子集Ci的所有其他特征给出.此系数提供了特征fi的实例如何聚集(同构)或分散的度量.
定义3:累积等级Cumi被定义为特征fi相对于给定类别s′的特征子集Ci的所有其他特征的全局等级.该等级通过考虑特征子集中fi的特征s′的相关等级和散度等级两者的累积等级来给定类别Ci.
相关性排序:本文使用相关性度量来计算一个属性与所有其他属性上的相关性,属性的等级可以基于给定类别的相关系数来计算,皮尔逊相关系数p是两个变量x和y之间线性相关的度量,p从-1~+1取值,当p值为+1时表示两个变量线性相关,当p值为-1时表示两个变量负相关,当p值为0时表示两个变量彼此不相关.对于m个特征的集合,通过计算每个特征的m-1个p值来找到该类的相关性.一个特征的平均p值给出了该特征相对于所有其他特征的相关性,因此可以建立所有特征之间的等级.
离散度等级:离散度等级用于量化属性的一组观察实例相对于给定类别的离散程度,可以提供数据集中属性的值相对于该属性平均值的离散系数,即它是一种用于评估一组观察到的事件是紧密聚集还是分散聚集的度量.较高的分散值意味着较大的分散.本文通过将离散度等级应用于对一个属性的排序来获得更多的相关性和非冗余特征.特征的离散系数q由式(2)给出.
其中,σ2为方差,μ为均值.
累积排序:累积排序被定义为在考虑所有分区的情况下将相关性和离散度等级组合,以便更好地计算给定类属性的相关性后得到的等级.相关等级为我们提供了水平相关性,而离散等级为该类提供了属性的垂直相关性.单个属性两个等级的平均值为数据集单个分区的所有属性提供一个等级,因此累积所有分区的等级以产生全局等级.随着垂直分区数量的变化,相关等级和离散等级均会变化,累积等级也会改变.值得注意的是,如果改变分区的数量,固定数据集的一组要素的等级不会保持不变,此时分类准确性也会变化.对于固定数据集,通过调整垂直分区数量以获得更好的分类准确度,而并行计算有助于轻松地进行这种调整.
-
特征选择通过从数据集中去除无关和冗余特征来选择相关特征子集以建立学习模型,包括从所有可能的子集中寻找最佳特征子集的搜索过程.应用评估度量来估计和评估给定类别的每个特征子集的相关性,可以通过包装器、过滤器和嵌入方法3种方式选择或排序.
特征排序过程为本文提供每个特征的等级,本文使用排序中的分界点来选择最佳特征的子集,该分界点可以通过经验结果以启发方式选择,本文根据截止阈值选择3个最佳属性进行分类.
-
为了评估本文方法的性能,本文选择了5种著名的分类算法来检查特征排序过程的准确性:精细k最近邻(KNN)、线性判别、Logistic回归、Boosting和复杂决策树.从每个数据集中取一个包含约10万个数据包的分区,应用特征排序过程来获得前3个特征,并使用这些特征进行分类.
以下命题对于平行累积排序(PCR)正确.
命题1:具有给定类别Ci的高相关等级特征s′的子集与该类相关,即s′⊙Ci,其中⊙表示由于高相关性引起的相关性关系.
说明:相关秩用于评估两个或多个变量之间关系的重要性.假设f1,f2,…,fn是给定类Ci的特征s′的子集中的特征或属性.如果对于给定类Ci的f1的皮尔逊相关系数接近+1或-1,那么f1与同一类特征子集的所有其他特征相关,具有秩越高的特征相关性越高.
命题2:具有给定类Ci的低离散度等级的特征s′子集与该类相关,即s′⊙Ci,其中⊙表示低离散度的相关性关系.
说明:离散系数是一种度量,用于评估给定类的属性值或实例是如何聚类或分散的.假设f1是给定类Ci的特征s′子集中的特征或属性,离散指数用于测试属性观测值的均一性,当色散系数较低时,类别Ci的特征f1的实例称为“色散不足(更均匀)”,否则为“色散过度(不均匀)”.系数值越低,给定类别Ci的色散秩越高,相同类的同构属性更具有相关性.
命题3:对于给定的类Ci具有高累积秩的特征s′子集是相关的.
说明:假设f1是给定类Ci的特征s′子集中的特征或属性,如果它具有更高的相关等级和更高的离散度秩,则类Ci的累积秩或相关性比来自相同特征子集的所有其他属性更高.
1.1. 特征排序
1.2. 特征选择
1.3. 数据分类
-
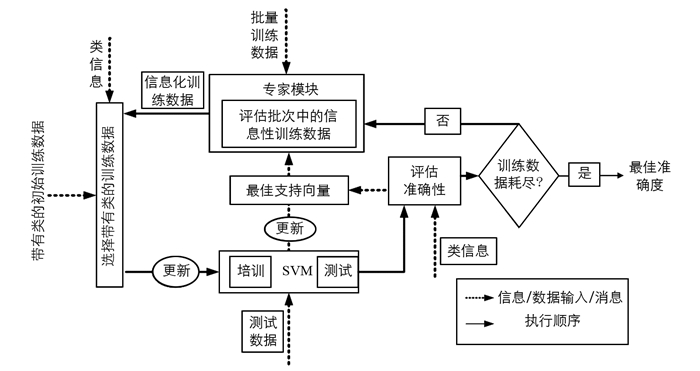
本文设计了一种主动学习方法来对网络流量进行分类以检测DDoS攻击,使用适当的训练样本,由专家模块在批处理模式下从未标记的数据池中进行识别. 图 2给出了本文设计的主动学习框架,整个过程可以根据不同的组件进行可视化.
设A是所考虑的全部数据集,DDoS攻击时DDoS流量嵌入到整个流量中. A将包括已知具有特定恶意活动的所有网络流量实例,以及可能想要测试该活动的所有其他实例.在每次迭代i期间,A被分成3个子集:标签已知的数据点Ak,i、标签未知的数据点Au,i和需要从训练数据中学习来标记的Au,i的A子集.
-
本文使用4个数据集:MIT-DARPA、CAIDA-2007、ISCX和TUDDoS,使用Editcap和Tshark对每个数据集包含大约100万个数据包进行预处理以获得这些属性的值.选择网络流量的5个属性:源IP地址、目的IP地址、源端口号、目的端口号和每个流量样本的帧长度,源IP地址和目的IP地址已转换为十进制值.
训练数据:训练数据由正常流量实例和DDoS流量实例组成,使用5个属性进行描述,每个实例的标签来自标签池.这些数据用于训练SVM二值分类器.
测试数据:测试数据也包括正常流量实例和DDoS流量实例,每个实例的标签都在标签池中.训练好的SVM分类器对测试数据进行分类.
标签池:本文将培训和测试数据的所有标签保存在单独的池中,并且对每个培训和测试数据的实例都有一个准确的标签映射,没有任何错误.当需要提供适当的实例以更新SVM分类器的训练数据时,将用于训练数据的标签提供给专家模块.
最佳可能支持向量:该数据组件是一组支持向量,它们被迭代更新.在训练数据完全耗尽之后,该组件具有用于对测试数据进行分类的最佳支持向量集.
-
对于主动学习,本文根据框架开发了5个核心处理组件:训练数据选择、专家模块、专家模块策略、SVM分类器和评估准确性.首先随机选择几个训练样本,并用训练样本训练SVM,在测试数据上测试SVM,使用公式(3)来查找分类精度需要测试数据上的标签,如果准确性大于最佳准确性,则更新最佳准确度,并使用支持向量集更新最佳支持向量集.如果训练数据已用尽则停止寻找准确度,否则将最佳向量集输入专家模块,调用专家模块获取下一批信息丰富的训练样本.
训练数据的选择:为了启动主动学习过程,本文随机从训练数据中选择一些流量实例进行学习,采用SVM来计算n支持向量.专家模块根据来自该组件的请求,使用这些向量从标签池中提供具有类别标签的适当训练样本,在每次迭代中专家系统评估来自训练数据的3×n实例.在SVM训练阶段,训练数据选择组件更新适当的实例.
专家模块:一批训练数据中的样本数量是分类器前一轮SVM训练产生的支持向量总数的3倍,专家模块根据专家模式策略处理该批训练数据以找到所需的样本.选择的数据样本和类与前一组训练数据合并以便在下一轮进行进一步训练,从而得到更好的边界线和更新的支持向量集.
专家模块策略:设n是在SVM分类器第(i-1)次训练迭代中生成的支持向量数量,从主训练数据集中汇集一批大小为3×n的实例,以便在专家模块中进一步评估以找到适当的实例,从SVM分类器提供的每个支持向量中计算批次中每个样本的欧几里德距离.选择距每个支持向量最短和最长距离的样本与支持向量机分类器的训练数据合并,以创建第i次迭代的训练数据.因此,策略性选择的样本数量小于或等于2×n.对于这些选定的样本,本文使用存储在标签池中的原始类/标签.欧几里德距离可以用其他距离度量代替.
SVM分类器:SVM分类器由培训和测试两个阶段组成.选择或更新的训练数据用于学习,并且在该训练阶段用于分类的超平面构造.将生成的支持向量提供给专家模块以便适当选择下一次迭代学习所需的实例. SVM分类器使用学习阶段生成的超平面对测试数据进行分类.
评估准确性:使用分类标签与实际类标签之间的差异来计算所设计模型的准确性.当SVM分类器将测试数据分类为两个单独的类时,使用公式(3)来查找分类精度需要测试数据上的标签.
其中,El为错误标签,Tl为总的测试标签.
2.1. 数据组件
2.2. 流程组件
-
为了对实验进行评估,本文在配置为Intel(R)Core(TM)i5-3320CPU@2.30 GHz处理器、64 GB RAM的64位Windows 10操作系统上,使用MATLAB R2016a的并行计算工具箱,选择分布式模型单个机器中存在的工作人员来进行实验,假设从CPU向GPU单个工作节点发送业务数据所需的通信时间是恒定的.使用4个数据集MIT-DARPA、CAIDA-2007、ISCX和TU-DDoS中的数据包对3组数据包进行预处理,在每组数据包中,本文合并60%的正常流量和40%的DDoS攻击流量.通过逐一改变初始训练数据、分批训练数据、训练数据总量和测试数据总量4列的条件来找出对分类精度的影响.
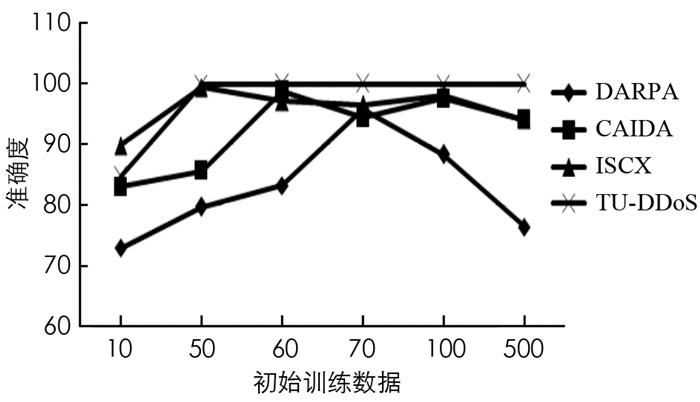
图 3给出了所有数据集下改变初始训练数据实例数量时本文算法的准确度,从而找到初始实例量以获得高精度.提供高精度的少量初始实例使主动学习过程更有效率.从图 3可以看出4个数据集MIT-DARPA,CAIDA-2007,ISCX和TU-DDoS的初始实例分别为70,60,50和50.
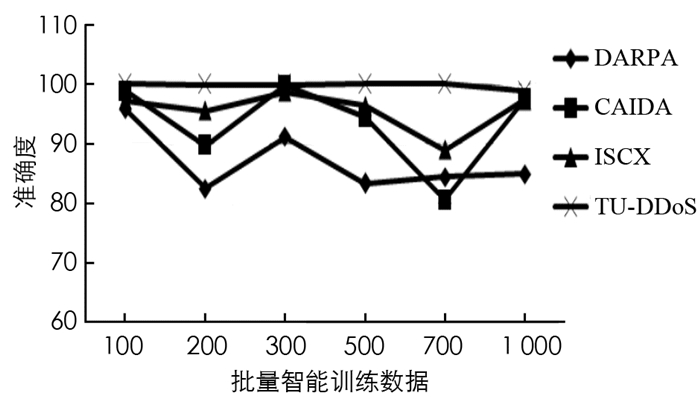
图 4在保持各数据集初始实例数量不变的情况下,改变下一次迭代的批量处理实例数,从而找出合适的批量处理实例数量.如果批次中较低数量的实例可以提供比批次中较高数量的实例更高的准确性,则专家模块使用支持向量查找适当的实例进行进一步分类的工作量会降到最低.从图 4可以看出4个数据集MIT-DARPA,CAIDA-2007,ISCX和TU-DDoS的批量处理实例数分别为100,300,300和700.
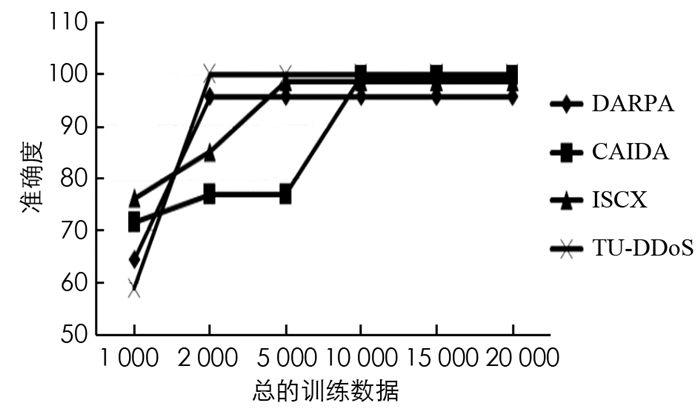
然而,批处理中实例数量较多时通过整个训练数据集运行的迭代较少.因此,本文在图 5中改变了训练实例的总数,在批次中的实例数与训练数据集中的实例总数之间进行完美的调整,可以减少遍历整个训练数据的迭代次数.从图 5可以看出在固定前两列不变的情况下,4个数据集MIT-DARPA,CAIDA-2007,ISCX和TU-DDoS数据实例总数分别为2000,10000,5000和2000.
图 6在将前3列固定以获得更高精确度特定设置的情况下更改了测试数据中的实例数,以此来研究测试数据中较高数量的实例的准确性如何变化.从图 6可以看出对前3列进行固定后,精确度不会随着测试数据中实例数的增加而有太大变化,这从主动学习的角度来看是需要的.
表 1给出了本文算法同基于模糊性的半监督学习方法和使用支持向量机(SVM)训练模型的性能比较.从表 1可以看出本文算法有比较高的准确度和较快的执行速度,这是因为本文使用并行积累排序算法来对数据集属性进行排序以找到最优特征子集,使用并行计算和具有较少训练样本的主动学习方法来处理大量的网络流量.
-
为了对大量的网络流量进行正确和快速地分类以检测DDoS攻击,本文采用基于并行积累排序算法和主动学习的DDoS攻击检测方法.该方法通过并行积累排序算法对数据集的属性进行排序来寻找最佳可能的特征,使用并行计算方法来处理大量的网络流量,并讨论了主动学习的重要性,通过专家模块以无监督的方式选择适当的实例来训练用于检测DDoS攻击流量的SVM二值分类器,以此实现从数据集中选择小批量训练样本来产生高精度的网络流量分类.实验结果表明,本文算法在处理大流量数据分类时,在训练样本较少的情况下提供了更好的分类准确率和更快的速度.未来的工作是通过结合软计算和其他技术开发一种由主动学习支持的模糊推理来扩展PCR,以便能够对大量数据空间的特征进行排序以建立其通用性.