


 下载:
下载:
-
计算机科学的不断发展和成熟对人机界面的智能化提出了新的要求[1-2].机器的智能化导致对语言文字的处理深度和广度越来越高,在界面层,识别、理解和翻译自然语言是最重要的要求之一[3-4].自然语言理解(Natural Language Understanding,NLU)是实现聊天机器人、移动秘书和智能扬声器等自然用户界面的核心技术,自然语言理解的目标是从自然语言中提取意义并推断用户意图. NLU嵌入模型有助于分析理解非结构化文本和与其对应的结构化语义知识之间的关系,对NLU的研究者和实践者都是必不可少的[5-6].
从人工智能的角度看,NLU的任务是建立一种能够给出像人那样理解、分析并回答自然语言结果的计算机模型[7-8]. NLU通常涉及2个任务:识别用户意图和提取特定领域的实体,其中,识别用户意图一般表述为句子分类,需对每个句子完成单个或多个意图标签的预测[9-10].提取特定领域实体通常被称为时隙填充,其中仅有部分句子被提取并用领域实体进行标记[11],NLU使用统计建模来完成意图识别和时隙填充任务.
为了使NLU技术在实践和科学研究中发挥最大的作用,文献[12]提出了一种用于自然语言理解的多任务基深层神经网络,该方法将多任务学习与预训练语言模型相结合进行语言表示学习,利用大量的跨任务数据和正则化效应来适应新的任务和领域,在领域适应实验中具有优异的泛化能力.文献[13]采用Transformers的双向编码器表示(Bidirectional Encoder Representations from Transformers,BERT)顺序推荐模型,用深层次的双向自编码建模用户行为序列.文献[14]提出了一种基于序列到序列模型和指针网络的生成性时隙填充神经网络模型,用来预测只有句子级语义标注时对话数据的时隙值.该模型通过在复制和生成未登录词(out-of-vocabulary,OOV)之间切换,可以绕过单词级标注的需要,并克服在实际自然语言处理中常见的OOV问题.
上述NLU文献使用统计建模来完成意图识别和时隙填充任务以及输入表示,但均未同时将文本和语义框架表示为矢量形式,因此,本文提出了一种同时学习文本和语义框架的分布式语义向量学习框架,在单个框架中同时执行原始文本到向量和结构化文本到向量的方法,以便更直接地学习语义表示.在该框架中,通过最小化文本输出的语义向量与语义框架阅读器之间的距离,将文本和语义框架分别投影到向量空间.语义框架重构技术用于在嵌入向量与其对应的语义框架之间导出一对一的映射.为了学习语义框架表示的鲁棒向量形式,采用文本投影向量与语义框架间的对应关系作为目标得分,并采用重构意图和标签生成损失作为目标得分.实验结果表明,本文所提出的语义框架实现了自然语言库的可视化,可以对多个系统的自然语言库结果进行重新排序.
全文HTML
-
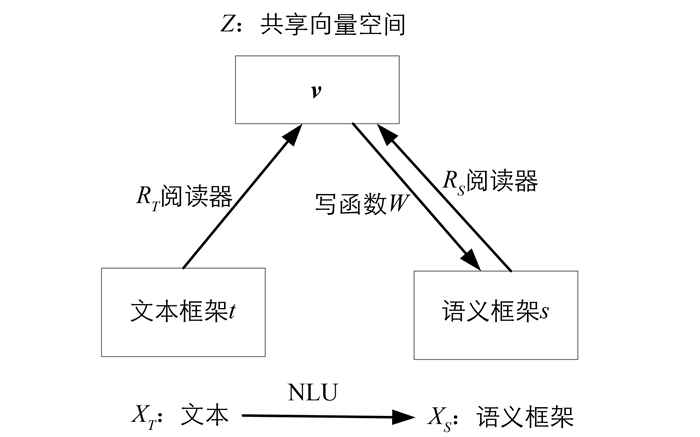
本文分布式语义向量学习框架由文本阅读器、语义框架阅读器和语义框架编写器组成.文本阅读器将标记序列嵌入到分布式向量表示中,语义框架阅读器读取结构化文本并将每个文本编码为一个向量,语义框架编写器根据向量表示生成一个符号语义框架. vt表示从文本阅读器派生的向量语义框架,vs表示从语义框架阅读器派生的向量语义框架.
设一对对应的文本和语义框架(t,s)在原始文本表示形式(xT)中具有相同的语义,并且语义框架表示形式(xS)可以编码为共享嵌入向量空间Z中的向量v.文本阅读器函数RT读取原始文本并将每个原始文本编码为向量,语义阅读器函数RS将结构化文本编码为语义向量,W是将语义向量解码为符号语义框架的写函数.语义框架和语义框架的向量形式之间的关系如图 1所示.
-
文本阅读器RT读取一系列输入标记并将每个标签编码为一个向量vt,实现了神经语句编码器.本文使用长短期记忆(Long Short-Term Memory,LSTM)对输入序列进行编码.编码过程可以定义为
其中,s={1,2,…,S},
${\overrightarrow h _s} $ 为时间s上输入序列上的前向隐藏状态,Rtext是循环神经网络(Recurrent Neural Network,RNN)单元,EX是输入文本标记x的嵌入函数,EX(xS)是标记嵌入函数,它表示时间s返回标签x的分布式矢量,σ(z)是sigmoid函数.最后RNN的输出${\overrightarrow h _s} $ 表示为vt,它是从文本中派生出来的语义向量. -
本文使用语义框架阅读器来构建分布式语义框架,它由意图标签、时隙标记和时隙值等结构化标签组成.本文将意图标签作为一个符号来处理,时隙标记和时隙值被当作一系列符号来处理.例如,“请列出星期一从北京到上海的所有航班”这句话的处理方式如下:
意图标签:航班
时隙标记序列:[出发城市,终点城市,出发日期]
时隙值序列:[北京,上海,星期一]
意图阅读器是一个简单的嵌入函数vintent=EI(i),其中EI为意图标签的嵌入函数,它返回一个句子的意图标签i的分布式矢量表示.
堆栈LSTM层用于读取时隙标记和时隙值的序列.设ES(o)是一个以o为标志的时隙标签的嵌入函数,EV(a)是一个以a为标志的时隙值的嵌入函数.嵌入结果ES(om)和EV(am)在时间步m处串联,合并后的向量分别在每个时间步长处都反馈到叠加层.时隙标记和时隙值序列的读取结果从M的循环神经网络单元RNN的最终输出结果中提取,其中,M为句子中的时隙数.最后,构造出如下的分布式语义框架:
其中[;]表示向量连接运算符,vintent表示意图识别输出,vtag,value表示时隙标签和时隙值的阅读器输出,vs的维度和vt相同.所有的嵌入权重均随机初始化并通过训练过程学习.
-
本文语义框架编写器从语义上学习文本的合理矢量表示形式和相关的语义框架.首先通过最小化文本输出的语义向量vs和语义框架阅读器vt之间的距离,将语义等价向量放置在向量空间中.然后根据期望语义向量的属性计算相应的损失函数.
本文期望语义向量的2个属性:嵌入对应和语义框架重构.
嵌入对应的损失:嵌入语义上有意义的量,并在向量空间中计算它们的距离,距离损失度量了向量空间中来自文本阅读器与来自语义框架阅读器的语义向量之间的相似性.损失函数定义为:
其中,Ddist函数可以是任何矢量距离度量,本文采用欧几里得距离和余弦距离.
语义框架重构的损失:语义框架重构用于得出嵌入向量及其对应的语义框架之间的一对一映射.内容损失提供了一种语义框架向量包含多少语义信息的方法.在没有内容损失的情况下,vt和vs趋向于迅速收敛到零向量,这意味着无法学习语义表示.为了度量内容的保持性,从语义向量中生成符号语义框架,并计算原始语义框架与生成语义框架之间的差异.
由于语义框架的时隙值需要较大的词汇量来生成时隙值,因此设计了一个简化的语义框架来解决时隙值的生成问题.本文通过简单地从相应的语义框架中删除时隙值,创建一个简化的语义框架,在这个简化的语义框架上执行内容丢失计算.使用简化语义框架的另一个优点是,所学习的分布式语义向量对词汇的敏感度较低,因此具有更高的抽象能力.
对于内容丢失,将测量意图标签和时隙标签的生成质量.意图生成网络可以简单地用线性投影定义为如下所示:
其中,v是语义向量,WI为意图写入函数,yintent是输出向量,b1为偏置量.
时隙标记生成网络定义为
其中,RG是RNN单元,bS为偏置量.语义向量v被复制并重复地输入到每个RNN输入中. RNN的输出用于W′S投影到时隙标签空间.
生成的标签向量和参考标签向量之间的交叉熵可以定义为
其中,M为句子中的时隙数(包括时隙结束序列符号),H(p,q)为CrossEntropy交叉熵函数.
结合意图和时隙损失,从语义向量v重构语义框架的内容损失(Lcontent),可以定义为
在上述描述中,可以通过进一步的处理从vt和vs中选择分布式语义向量v,则
最后,用于学习语义框架表示的总损失值(L)定义为
-
使用所学的文本和语义框架阅读器,不仅可以测量来自同一表示(文本或语义框架)的实例,还可以测量来自不同表示的实例.将文本表示为t和语义框架表示为s,将文本和语义框架阅读器表示为RT和RS.它们之间的距离测量可按如下方式进行:
在所提出的语义框架中,具有不同形式(文本或语义框架)的实例可以直接在语义向量空间上进行比较.
1.1. 输入序列编码
1.2. 构建分布式语义框架
1.3. 语义框架编写器和损失函数
1.4. 多种形式的距离测量
-
为了对所提出的语义框架进行性能评估,本文使用ATIS2数据集进行训练和测试(见表 1). ATIS2数据集由一个带注释的意图和空乘信息搜索任务的时隙语料库组成,ATIS2数据集带有一个常用的训练和测试拆分.在本次实验分析中,进一步将训练集进行划分,实验使用的训练集占原训练样本的90%,开发集占10%.
基于相似度的分类器通过测试样本和标记训练样本之间的相似度,以及训练样本之间的成对相似度,从而得到测试样本的类别标签.计算每个训练句子的文本语义向量,并用相应的意图标记索引.当句子被赋予NLU系统时,文本阅读器读取句子并生成vt.然后,意图标记随距离分数进行升序排列.
表 2给出了基于相似度的意图分类结果,K在1~40之间变化.从意图标志的顶部K列表中,选择出现最频繁的意图标记作为给定句子的意图标记.可以看出,所提语义框架具有较好的分类性能,在K=1时意图分类性能最优.
对多个NLU模块输出结果重新排列是困难的,但这种排列对于构建健壮的NLU系统来说是非常重要的.典型的选择是将结果与每个系统产生的分数进行比较,但是这技术并不总是可行的,语义框架的向量形式为重排序问题提供了一种非常清晰、自然的解决方法.本文根据对应的vs到vt的距离,重新排序来自多个NLU系统的NLU结果(语义框架).
表 3给出了文本合成法重新排序算法的性能结果,其中Acc表示准确度,Pre表示精确度,Rec表示召回率,F-m表示F测量. NLU结果重新排序的典型选择是多数投票和基于NLU分数的排序,多数投票法选择NLU系统预测最多的语义框架.可以看出所提出的基于距离的语义向量重排序方法在意图和时隙嵌入方面都表现出了优越的选择性能,这是因为本文使用学习的语义向量,通过比较文本和语义框架的语义向量值来实现对多个NLU系统的重新排序.
所提出的重排序算法基于以下假设:NLU系统的质量与vt到vs距离之间存在很强的相关性. 表 4给出了NLU系统的所有测试语句(11*882=9 702语句)的相关性分析结果.所有的性能指标(特别是联合指标)均显示p值接近零的强相关性(负相关性),它表明vt到vs的距离越小,NLU性能越好.
-
为了得到有效和有意义的分布式语义表示模式,本文提出了一种用于自然语言理解的分布式语义向量学习框架.该框架使用深度LSTM对输入序列进行编码,之后通过多维度标签组构建分布式语义框架,然后设计语义框架编写器和损失函数以学习鲁棒的语义向量,最后通过多形式距离测量,使具有不同形式(文本或语义框架)的实例可以直接在语义向量空间上进行比较.实验结果表明,本文提出的分布式语义向量学习框架能够学习文本与提取的语义知识之间的嵌入语义对应关系,同时,该框架在NLU输出结果重新排列方面,性能优于测试的NLU系统.