


 下载:
下载:
-
网络欺凌语言是指在社交平台上发表的针对个人或群体的攻击性言论,其攻击性多表现为谩骂、诋毁和嘲笑等[1-6]. 这类语言的提取、甄别工作一般归自然语言处理领域,而自然语言表述的灵活性、无规律性,使得网络欺凌语言常常难以被发现,从而难以被及时处理. 在网络信息量呈爆炸式增长的现在,由平台管理员人工审核用户语言的方式已完全无法胜任网络欺凌语言的检测、分析工作,人工智能和机器学习的引入成为解决这一难题的可行且必要的新型途径.
关于网络欺凌语言,国内外的学者们已开展了大量研究. 石国亮等[1]对网络欺凌语言的概念、特点进行了总结论述; 在对网络欺凌语言的分析方面,刘文宇等[2]侧重从语言学角度对欺凌语言进行分析,朱嘉珺[3]提出了大数据技术对网络侵害防治的探索; 在对网络语言的检测方面,强澜[4]从新浪微博搜集了部分数据,并进行了多次迭代的数据处理,然后建立分类模型以达到检测攻击性语言的目的. 鲁倪佳[5]构建了一个网络欺凌公开数据集,并引入了卷积神经网络进行分类,同时研究了数据集平衡问题的解决办法. 文献[7-9]借助半人工的方式从twitter等社交平台上爬取数据并建立数据集,然后对数据集进行分析,最后通过机器学习或深度学习的方法建立分类模型,再用分类模型检测评价数据集,达到检测出网络欺凌语言的目的.
目前学界研究网络欺凌语言时使用的数据集大多来源于英文数据,少量来自其他语种,如Van Hee C等[10]研究了荷兰语的网络欺凌语言检测方法. 中文研究相对较少,因为中文处理过程中存在一词多义、词向量预训练等问题[11]. 为了解决这些问题,赵雅欣等[12]使用哈工大的分词与停用词表,在数据预处理阶段解决了分词问题; 龚静等[13]则是研究多语言统一训练分类模型. 由于我国网民数量庞大,社交平台的网络发言具备了大数据特征,欺凌语言也具备了大数据特征. 在这种背景下,要想和谐网络社区氛围、净化评论语言环境,就必须对社交平台上的网络欺凌语言进行有效的检测与分析.
本文首先构建一个经过人工标注了的中文网络欺凌语言数据集,然后使用基于机器学习与深度学习的方法训练分类模型,并对分类结果进行深入分析. 实验表明,基于深度学习的分类模型效果最佳,结果分析能够挖掘出用户在评论字数、用户等级、发言楼层、评论时间等方面的数据特征.
全文HTML
-
根据艾瑞数据的社交平台使用人数排行报告[14],本文选取了排名靠前的百度贴吧、知乎、豆瓣、新浪微博等十几个常见的社交平台,采用后羿采集器爬取到185.87万条用户评论,构建了初始数据集. 因爬虫软件获取的数据有许多冗余错乱信息,故本文采用python编写的程序进行数据清洗. 首先,删除大量异常值如空值、属性缺失数据、重复爬取数据等,得到115.51万条评论,作为网络欺凌语言的分析样本集. 随后为了进一步筛选优质数据以便挑选人工标注样本,本文对评论内容进行去重,以及删除过长与过短的评论. 其中,将过长或过短评论定义为:将所有评论按其长度进行排序后,首尾两端共占20%的评论. 最后得到86.24万条评论,可从中抽取样本组成网络欺凌语言的分类训练样本集.
-
对网络欺凌语言的检测是一种经典的文本分类问题. 在文本分类问题中,正向样本的数量过少时,分类模型的效果将不明显[15],为了对比含有网络欺凌语言的攻击性评论和不包含网络欺凌语言的正常评论,本文从样本集中随机选取了正向样本和负向样本各3000条左右,通过人工标注的方法,建立了网络欺凌语言分类样本集. 部分经过清洗标注后的样本数据集如表 1所示.
表中“是否攻击性评论”为人工进行的标注. 通过输入大量经过标注的训练样本进行训练,分类模型能够根据学习到的知识来自动化处理无标注的样本.
1.1. 初始数据的获得与清洗
1.2. 分类样本集构建
-
网络欺凌语言样本表现为自然语言形式,而分类模型无法直接处理自然语言,因而需要将文字转化为向量形式,即词向量[11]. Word2vec是单词向量化的重要方法之一,可以根据给定的语料库,通过优化后的训练模型快速有效地将词语表示为矩阵形式,训练方法分别为连续词袋模型CBOW(Continuous Bag-of-Words)模式和跳字模型Skip-gram模式[16]. CBOW模式通过原始语句推测目标字词,比较适合小型数据库,而Skip-gram模式从目标字词推测原始语句,在大型语料库中表现得更好. 鉴于本文需要对大量的评论词语进行分类,因此我们采用Skip-gram模式进行训练. 分类问题可以采用的模型很多,其中朴素贝叶斯与支持向量机是机器学习中经典的算法[17],而长短期记忆网络是深度学习中针对股票、文本这样的序列数据提出的模型,很适合用来解决文本分类问题[18].
-
朴素贝叶斯[19]是常见的分类模型之一,适用于文本分类问题. 对于中文自然语言处理领域而言,朴素贝叶斯算法将词向量中每一个元素看作符合独立性假设的一个特征,对训练集所有特征拟合后,即可通过测试文本的特征判断其属性. 例如:对于评论X,有x∈(x1,x2,…,xn),其中xn为词向量的特征,而类别为y∈(0,1),0表示正常评论,1表示分类模型识别出的攻击性评论. 算法的思想为:根据人工标注的语句构建训练集以及学习训练集的特征,再在测试集中,通过其特征计算评论属于分类(0,1)的概率,取其中较大者作为分类结果.
概率计算公式为
其中,yk为输出类别(y0,y1),P(yk|x)为该评论属于yk分类的概率,P(xi|yk)为在yk分类条件下xi的概率.
-
SVM是由模式识别中广义肖像算法发展而来的分类器,基于SVM算法的分类策略可以将数据集分类成明确的多个集合[20-22],SVM通过某种事先选择的非线性映射将输入向量x映射到一个高维特征空间z,在这个空间中构造最优分类超平面,从而使正例和反例样本之间的分离界限达到最大. 构造出的决策函数为
其中,a与b为偏置系数,xi与yi为训练数据,K为自定义的核函数.
SVM模型中有2个重要的参数,C与γ. 其中,C为惩罚系数,即对误差的宽容度,C设置得过高容易出现过拟合现象,C设置得过低会出现欠拟合现象,二者均会导致模型泛化能力变差,效果不够理想; γ为核函数使用高斯函数时其中的重要参数,γ决定了低维样本到高维的映射,γ越大,支持向量越少,γ越小则支持向量越多,因此它影响着模型训练测试的速度. 本文通过网格搜索,在保证C与γ相互独立的前提下,寻找全局最优解,设置C为13,γ为0.8.
-
长短期记忆网络[23]是基于循环神经网络(Recurrent Neural Network,RNN)的一种改进网络,广泛应用于各类问题中[24-25],针对RNN对于长期记忆遗忘的问题,LSTM在细胞中设置了不同的“门”结构,遗忘门结构(公式3)决定在传递到下一个细胞时隐层中的信息是保留还是遗忘,更新门(公式4)对ct进行了更新,c(t-1)中的信息借由ft进行有选择的记忆,输出门(公式5)在ct已被更新后,再用一个激活函数决定输出的内容,然后通过tanh缩放,即完成一个时间序列的输出.
上述公式中,ft,it与ot为各门的神经元,Wif与bif为神经网络的权重,gt为新信息,ct与c(t-1)为当前与前一个的细胞状态,xt为输入,ht与ht-1为当前与前一个的隐层状态和输出.
2.1. 朴素贝叶斯(Naive Bayes,NB)
2.2. 支持向量机(Support Vector Machine,SVM)
2.3. 长短期记忆网络(Long Short-term Memory,LSTM)
-
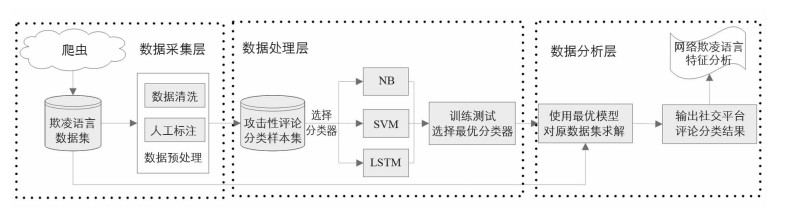
在选定数据源和分类模型之后,数据的采集、处理和分析过程如图 1所示:
1) 收集社交平台用户发表的评论数据,构建一个网络欺凌语言数据集;
2) 取原数据集中一小部分,进行数据清洗和人工标注,选择使用机器学习中的分类模型进行拟合,建立一个攻击性评论分类样本集;
3) 选择3种不同的分类算法,分别用分类样本集进行训练,并对比不同的分类模型在测试集上的分类效果,选择其中结果最优的分类模型;
4) 使用效果最好的模型,对原数据集中的所有样本求解,得到全部数据的分类结果;
5) 基于分类结果对网络欺凌语言的特征进行可视化分析.
表 2展示了检测社交平台中网络欺凌语言的3个算法的伪代码描述,虽然算法的实现有所不同,但基本特点一致:
1) 将收集的数据转换成便于处理的形式,比如词向量;
2) 分析各自的参数形式与所处理数据属性之间的关系;
3) 采用具体算法对数据的各种属性进行处理,形成易于观察的结果;
4) 分析结果,研究相应的属性表现出来的特殊性质,如准确度、F1值等.
-
在构建好样本集的基础之上,采用上面描述的3种方法进行训练,其结果如表 3所示.
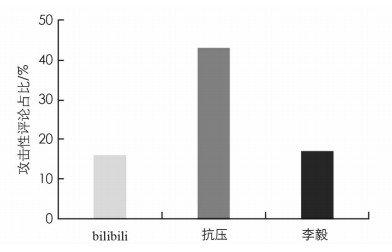
由表 3可知,长短期记忆网络在构建数据集上的综合效果较好,F1值达到88%,同时准确率与精确率达到88%与89%. 为此下面的研究将采用长短期记忆网络分类模型来识别检测攻击性语言. 为了进一步检验模型的有效性,我们先选取了百度贴吧中颇具代表性的bilibili吧、抗压吧、李毅吧进行验证,统计分类模型的测试结果,并与人工观察的现象进行对比. 凭借人工观察可知:bilibili吧在人工监督下网友的交流较为友善; 抗压吧则相对自由,呈现出较强的攻击性; 李毅吧是百度贴吧中用户数量最多的贴吧,其风气呈中性偏多. 而依据构建好的分类模型对这三大贴吧中清洗好的评论进行检测,得到的攻击性语言占比结果如图 2所示:bilibili吧与李毅吧的攻击性语言各占16.02%,17.17%,而抗压吧则达到了42.99%. 这一结果与人工观察得出的结论在趋向性上一致,而在精确度上又高于人工观察的结果,从而在一定程度上印证了分类模型的可信度.
-
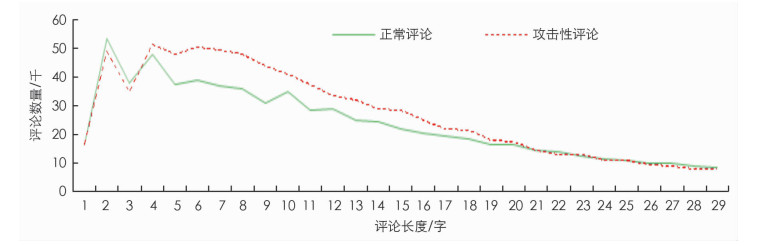
将分类模型分类结果为1的定义为攻击性评论,分类结果为0的定义为正常评论,其评论长度的数量统计如图 3所示. 为了公平对比两数据集,我们对攻击性评论的数量进行了一次加权调整,具体为
其中,len(sentence)new为经过加权的语句长度,len(sentence)old为原语句长度,num(common)为正常评论的总数量,num(aggression)为攻击性评论的总数量.
由图 3可以看出,相对于正常评论,攻击性评论的语句长度在4~20汉字间的数量较多一些. 评论的平均长度与每句评论的不同词性词汇数量统计如表 4,表 5所示.
由表 4,表 5可以看出,攻击性评论平均语句长度只有正常评论的44.88%,同时,每一句话中的名词、动词、形容词数量也要少很多,但副词的使用数量是正常评论的2倍.
-
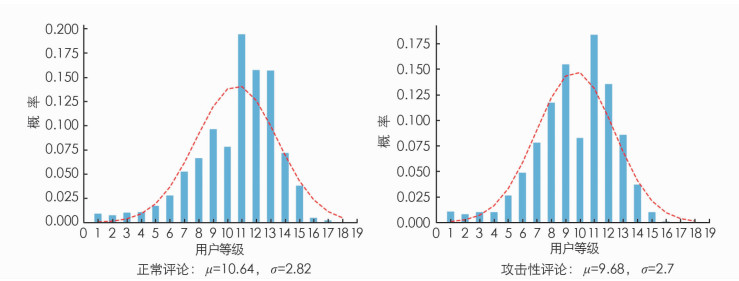
我们设置用户的等级为横轴,设置参与正常评论/攻击性评论的概率为纵轴,绘制出了柱状分布图. 如图 4所示.
根据图 4用户等级分布的数据可知,拟合的函数呈现出正态分布特性. 正态分布拟合公式为
拟合的各个参数结果如表 6所示.
由表 6可以看出,相对于正常评论,攻击性评论的用户等级的分布更为集中(σ较小)且等级集中的位置较低(μ较小),即攻击性评论用户与正常评论用户相比等级集中在较低的位置,同时集中的程度较高.
-
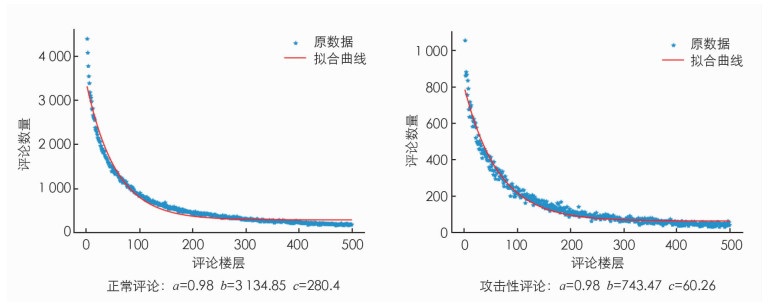
图 5为对每一条评论的所在楼层进行统计的分布图.
从图 5的表现来看,数据呈指数函数曲线形式,其拟合函数为
拟合结果如表 7所示.
由表 7的参数可以看出,攻击性评论相较正常评论而言数量要少一些(c较小),变化的趋势相差不多(a相近),但变化的速度较快(b较小). 随着楼层的增加,攻击性评论出现的概率便越小,发表攻击性评论的用户更倾向于在楼层较低时进行攻击.
-
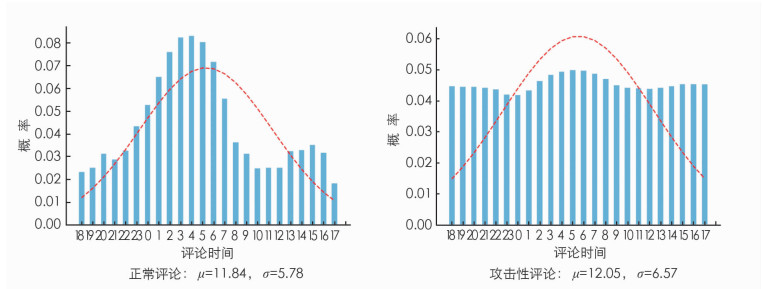
我们对网友参与评论时间和评论概率的关系进行分析,分别绘制出正常评论和攻击性评论的分布图. 如果按0~23时进行观察,很难观察出一定的规律. 因此本文将时间属性做了一定的调整,将18~23时的数据调整到0~17时之前,以便更直观地观察出规律. 结果如图 6所示.
根据图 6,两者的分布图基本呈现正态特性,其正态分布拟合公式为
拟合结果如表 8所示.
由表 8可以看出,相对于正常评论,攻击性评论的时间分布相对离散很多(σ较大),集中的位置较大(μ较大). 可以解释为攻击性评论呈现出相对不太受时间影响,且攻击性用户熬夜更晚的特点.
4.1. 评论长度与词性分析
4.2. 用户等级分析
4.3. 评论楼层分析
4.4. 评论时间点分析
-
本文从常见的社交平台中收集了大量用户评论,清洗后从中选取样本人工标注形成了网络欺凌语言数据集. 根据任务特点,选用朴素贝叶斯、支持向量机与长短期记忆网络作为分类模型进行了实验,其中长短期记忆网络综合效果最好. 随后使用长短期记忆网络处理未标注的内容,并对结果进行了分析:在3个百度贴吧数据集中,模型分类结果与人工观察结论高度相符,一定程度上验证了模型的可靠性; 在全部数据集中,攻击性评论相对于正常评论表现出评论字数较少、用户等级较低、评论时间更离散等分布特征. 但是本文仅考虑了传统二分类问题,未对网络欺凌语言的进一步划分作研究,因此下一步考虑使用细粒度情感分析方法,对网络欺凌现象的成因、发展等因素做深入剖析,从而寻求更有效的检测分析网络欺凌语言的方法.