


 下载:
下载:
-
在禽蛋经营中,破损禽蛋分拣是一个非常重要的环节. 为解决传统人工分拣准确度低、漏检率高、速度慢的问题,提高自动分拣的水平,研究人员一直在研究采用先进技术来实现禽蛋破损自动检测. 在过去的20年里,有不少专家学者将传统的机器视觉[1-2]和音频分析[3-4]等各种技术手段应用在禽蛋破损检测上. 贺静等[5]提出的基于DSP实时图像采集处理的鸡蛋破损检测方法,将DSP实时采集的鸡蛋图片灰度化处理后,应用外接矩形法描绘鸡蛋近似椭圆投影的外切矩形,利用改进型标记法判断鸡蛋是否破损. 但该方法有一定的局限性,检测时会受到蛋壳斑点的影响,当斑点面积大于15.04 mm2时,就会错检. 王树才等[6]根据声波在不同介质中的不同特性,利用敲击声音信号进行研究,发现正常蛋、破损蛋、钢壳蛋和尖嘴蛋在衰减时间、共振峰频率、最大频差3项指标上存在显著差异,据此实现蛋的破损检测. 但该方法受到噪声和敲击点的位置影响较大,对检测精度有一定的影响.
从相关研究文献[1-6]可以看出,传统机器学习算法应用在禽蛋破损检测时,鲁棒性比较差,容易受到多因素的干扰,漏检和错检问题比较突出,很难满足大规模分拣的需要. 近年来,计算机视觉技术迅猛发展,目标检测算法不断改进和创新,被广泛运用在各个领域中[7-8]. 在蛋破损检测领域,研究人员也不断尝试将各种目标检测算法应用在研究中,极大地提高了蛋壳破损检测的精度和速度. 如涂伟沪等[9]利用蝗虫算法(grasshopper optimization algorithm,GOA)改进canny算子,提高了鸡蛋线型、网状裂纹的检测精度,对鸡蛋的线型和网状裂纹的漏检率分别降低了20%以上和60%以上;赵祚喜等[10]用YOLOv4进行了鸡蛋破损的在线检测研究,破损蛋的识别率达85%左右.
相比于鸡、鸭、鹅等禽蛋,鸽子蛋具有体积更小、蛋壳更易碎的特点. 据汤青萍等[11]人研究,鸽子蛋壳平均厚度为0.23 mm,蛋壳强度1.19 kg/cm,乳突层稀疏、形状不规则且直径较大,栅栏层断面凹凸不平,晶体层晶体排列松散、晶格棱角模糊. 基于此,本文实验采用目前综合性能最优的目标检测算法YOLOv5来研究鸽子蛋壳破损检测. 以自行设计的设备分别对裂纹鸽蛋和完好鸽蛋的图像进行采集,对数据通过Mosaic数据增强[12]、自适应锚框计算、自适应图片缩放等进行预处理. 在实验过程中,出现了模型对部分裂纹鸽蛋识别准确率不高的问题,原因在于细微裂纹在深层网络中出现特征丢失、气室特征权重过高的问题,干扰了裂纹特征的提取. 为此,本研究对YOLOv5模型进行了相应的改进,增加一个检测层以提高对细微裂纹特征的提取能力,融合改进的SE注意力机制(squeeze-and-excite)[13]以提高裂纹特征的权重. 本文采用YOLOv5[14],Faster RCNN[15],YOLOv3-SPP[16]进行对比,结果显示,本文改进的YOLOv5模型在鸽蛋破损检测中综合优势明显,为鸽蛋的破损检测提供了新的解决方案.
全文HTML
-
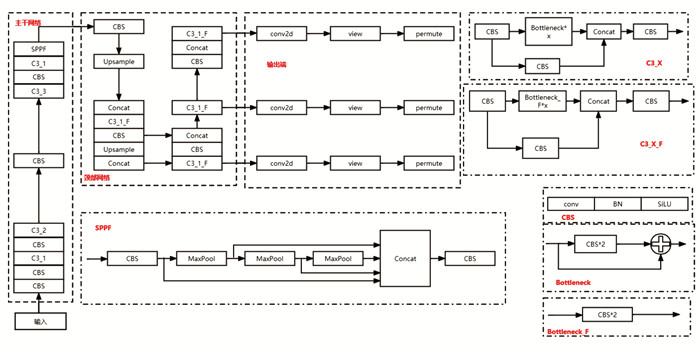
YOLOv5由4个模块组成:输入端(Input)、主干网络(Backbone)、颈部网络(Neck)和输出端(Head),其网络结构见图 1.
-
主要功能是数据输入与数据增强,包括Mosaic数据增强、自适应锚框计算、自适应图片缩放等. 其中,Mosaic数据增强通过对输入图像进行随机缩放、裁剪、拼接、排布等方式增加小目标的样本数量,从而提高模型的检测精度.
-
主要包括CBS、带shortcut的C3和SPPF 3种模块(图 1). CBS的结构为Conv+BN+SiLU,主要用于卷积操作;C3为CSP架构[17],包含了3个标准卷积层和多个bottleneck模块,这个部分的C3模块包含的位置信息、细节信息较多,但语义信息较少,主要用于特征提取;SPPF模块采用了多个小尺寸池化核来代替单个的大尺寸池化核,在保留了单个大尺寸池化核的多感受野特征融合功能的情况下,进一步提高了运行速率.
-
位于主干网络和输出端之间,主要由CBS,Upsample,Concat和不带shortcut的C3组成. 颈部网络采用FPN+PAN的结构,FPN结构[18]能使所有尺度下的特征都有丰富的语义信息;PAN结构[19]则主要用于加强定位信息. Neck的CBS主要作用是通过下采样来抽取高层次语义信息. C3则主要用于纹理特征的提取,包含的位置信息、细节信息较少,语义信息较多,将提取出的特征进行混合组合后,传递到预测层,增强网络特征融合的能力.
-
Head模块利用之前获取的特征作出预测,采用GIoU_Loss作为损失函数,同时通过非极大值抑制NMS来筛选目标框[20].
因网络深度和维度不同,YOLOv5模型主要有YOLOv5n,YOLOv5s,YOLOv5m,YOLOv5l,YOLOv5x等版本. 其中,YOLOv5n是支持移动端的最小化模型,训练出来的最终模型的大小是YOLOv5s的1/4左右,只有3.4 MB,具有轻量化、精度高、速度快的特点. 为满足轻量化要求,本研究实验选择了适合搭载在移动设备上、更轻量的YOLOv5n模型.
-
针对鸽蛋破损检测过程中,裂纹目标细微、裂纹特征模糊、裂纹特征提取能力差等特点,本研究提出了两点改进. 一是为提高细微裂纹检测精度,采用Kmeans聚类算法计算细微裂纹锚框适应度,并在head模块增加检测层,从而检测到更小的裂纹;二是为提高对鸽蛋纹理特征的提取和融合能力,用融合了改进SE注意力机制的C3模块代替原有的C3模块,提高裂纹特征的权重,增强对鸽蛋纹理特征的提取和融合能力.
-
YOLOv5的3个检测层对应3组初始化Anchor值[10, 13, 16, 30, 33, 23]、[30, 61, 62, 45, 59, 119]、[116,90,156,198,373,326],最大能检测32×32的目标,最小能检测8×8的目标. 由于大部分鸽蛋的裂纹比较细微,图像分辨率低、特征表达能力弱,能提取的特征比较少,更容易出现错检问题.
为此,本研究采用Kmeans聚类算法计算细微裂纹锚框适应度,迭代次数为1 000,获得自适应锚框[7, 9, 13, 8, 9, 12]. 即为了检测和提取到更细微的裂纹特征,在head模块中增加Anchor值为[7, 9, 13, 8, 9, 12]的检测层. 计算过程为:
依此改进后,主干网络的第2层就会开始增强特征,并在17层后继续对特征图进行上采样等处理,扩大特征图. 在第20层将获取到的大小为160×160的特征图与主干网络中第2层特征图进行concat融合,以此获取更大的特征图,从而能够提取到4×4大小的特征,实现对比较细微的裂纹的特征提取.
-
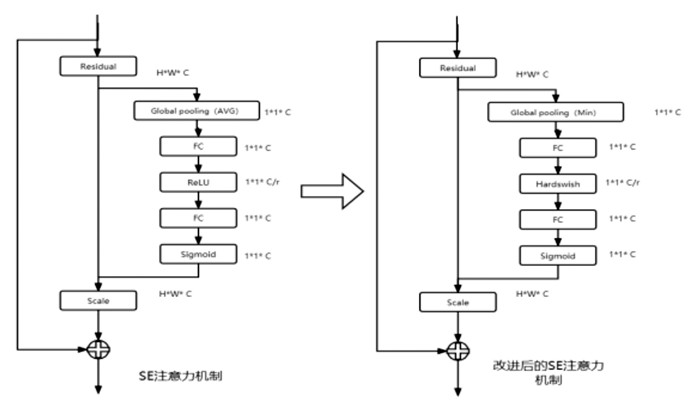
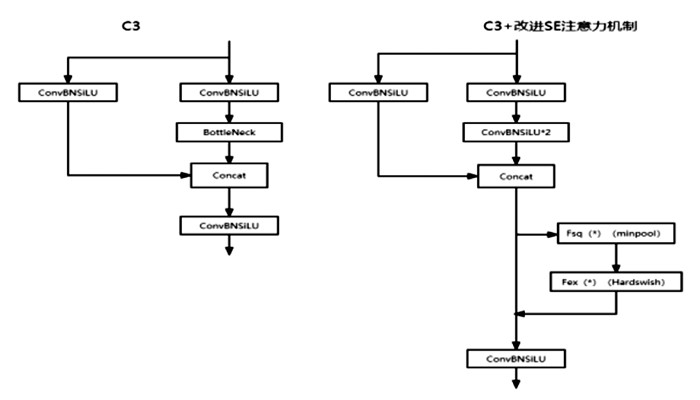
在本鸽子蛋破损检测任务中,细微裂纹的特征信息容易在深层网络中丢失. 同时,在暗室照蛋的条件下,气室部位会形成光晕,给裂纹特征信息带来极大的干扰,需要更加注重纹理特征的提取. SE注意力机制[13]能通过建模来确定各个特征通道的重要程度,然后针对不同的任务增强或者抑制不同的通道,增强对裂纹特征信息的学习,增加裂纹特征的权重,可以让网络更加关注待检测目标,减少细微裂纹特征信息在深层网络中丢失的现象,从而提高检测效果. 为此,本实验将SE注意力机制融合到C3模块中,以增强裂纹特征信息的提取.
SE注意力机制结构主要包含Squeeze和Excitation两部分.
Squeeze通过全局平均池化层(global pooling)将全局空间信息压缩到信道描述符中,将H×W个像素压缩成一组1×1×3的实数,计算公式为:
然后通过Excitation的激励操作,将1×1×3的实数降维为1×1×(3/r),然后再升维到1×1×3,最后经过sigmoid激活函数的全连接层的归一化操作,变成一组0-1的实数,计算公式为:
其中δ为ReLU激活函数.
这组0-1的实数对应了每个通道的重要性,0为最不重要,1为最重要. 最后再对应到特征图的每一个像素值,得到的最终输出为:
考虑到大部分的裂纹在照蛋环境下呈现黑色纹路,在Excitation的激励操作的降维中会出现得到的实数基本相同,而裂纹部分的RGB图色值大多数接近{0,0,0},使得这部分的特征在归一化之后获得的权重很低,出现这部分特征在深层网络中丢失的现象. 为此,本实验对SE注意力机制的全局平均池化层进行修改,以反向最大池化层的方式增强裂纹特征的权重. 改进后的Squeeze操作为:
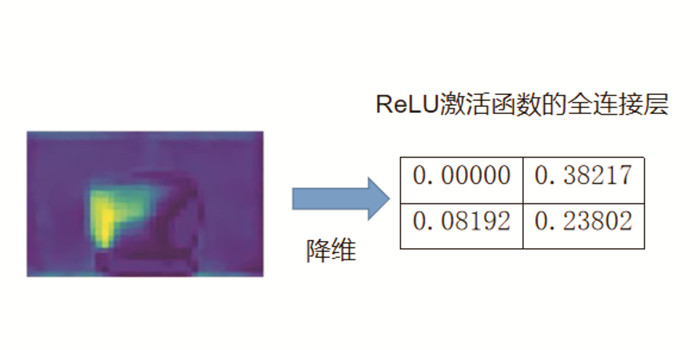
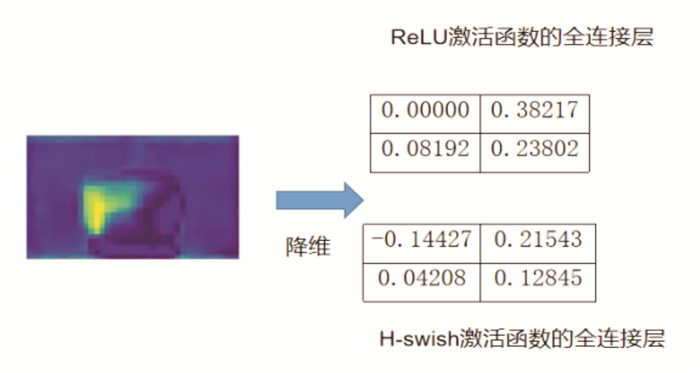
然而,这一改动会在降维操作中出现输入为负的现象. 如果继续使用ReLU激活函数的全连接层,会出现小于零的输入存在时导致的神经元坏死问题(图 2).
于是,本研究采用swish激活函数的全连接层,这样即便在降维操作中输入为负也不会出现输出为0的现象,可以较好地解决融合了反向的最大池化层后出现的负向梯度消失问题,避免部分神经元坏死,确保神经网络误差正常反馈(图 3).
与ReLU激活函数相比,swish激活函数[21-22]是一个平滑的、非单调的函数,它和它的导数定义为:
其中:σ(x)=sigmoid(x).
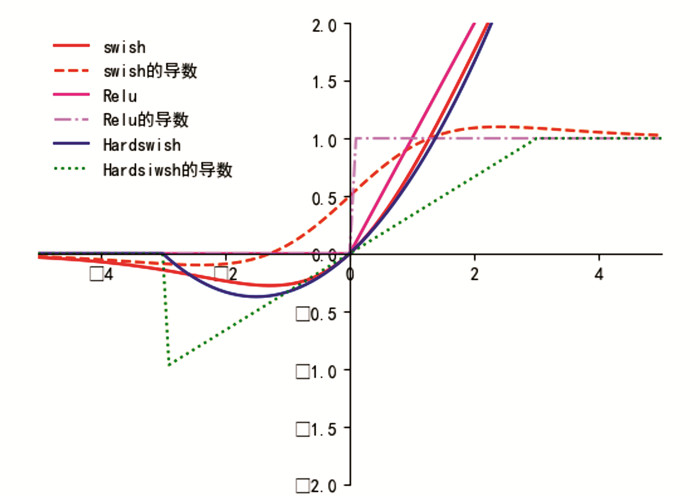
从中可知,在x>0时,swish激活函数不会出现梯度消失的问题;当x<0时,也不会出现ReLU激活函数导致的神经元坏死的问题. 在SE注意力机制的全连接层中,采用swish激活函数的全连接层便不会出现得到的实数中出现0的现象,由此可避免这部分特征在深层网络中丢失. 同时,swish激活函数的导数也不像ReLU激活函数的导数那样一成不变,而是处处可导、连续光滑,能显著提高神经网络的准确性[23],让模型获得更高的精度.
虽然swish激活函数能提高精度,但在移动设备和嵌入式设备上它所需的计算成本要比ReLU高得多. 在相同数据集下,对分别使用ReLU、swish和Hardswish激活函数时模型的推理速度进行对比时发现,使用ReLU激活函数时的单帧推理时间为10.3ms,使用swish激活函数时的单帧推理时间为10.9 ms,使用Hardswish激活函数时的单帧推理时间为10.5ms. 使用ReLU激活函数和Hardswish激活函数时,模型的推理速度差别不大,降低了不到2%;而使用swish激活函数时,模型的推理速度却降低了约6%. 因此,本文采用Hardswish激活函数代替ReLU激活函数[24],其定义为:
ReLU6(x)几乎可以在所有的软件和硬件框架上使用[24],在量化过程中消除了近似Sigmoid函数的不同实现而导致的潜在数值精度损失. 此外,Hardswish激活函数可以实现分段功能,以减少内存访问次数,能使网络的推理速度加快,对量化过程更加友好[25-26].
ReLU,swish,Hardswish 3种激活函数及其导数见图 4.
改进后的Excitation的激励操作为:
其中η为Hardswish激活函数.
改进后的SE注意力机制的结构见图 5.
改进后C3结构见图 6.
1.1. YOLOv5算法描述
1.1.1. 输入端
1.1.2. 主干网络
1.1.3. 颈部网络
1.1.4. 输出端
1.2. 算法优化
1.2.1. 增加检测层
1.2.2. 添加注意力机制SE模块
-
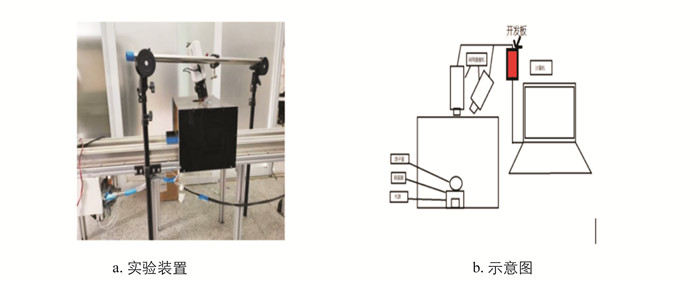
本研究实验采用自主设计的数据采集设备,旨在创造一个尽可能去除外部干扰的检测环境,用来采集鸽蛋图像和实现对鸽蛋的快速检测. 装置的主体部分由可控制传送带、暗室、摄像机、开发板组成. 传送带采用步进电机驱动,使用STM32F030R8芯片控制传送带的转动速度和识别单个鸽蛋的时间;开发板使用的操作系统为Ubuntu 18.04,检测GPU为GTX760,显存容量2048M,测试环境为Python3.8,测试框架为Pytorch1.9.0,使用CUDA版本10.2.89作为框架计算.
鸽子蛋通过传送带被连续不断送入暗室,每个鸽蛋在固定时间内绕轴心旋转360°,利用摄像头通过照蛋法采集到每个鸽子蛋的图像,每个鸽蛋获得蛋身不同侧面的图片若干张,利用这些图片建立数据集并训练模型,最后由开发板搭载训练好的模型对鸽子蛋进行实时检测. 实验装置及示意图见图 7.
-
本研究的实验材料为300枚完好无损鸽子蛋,从鸽子养殖场和菜市场采购获得. 先将300枚鸽蛋通过图 7实验装置拍摄获得图像,并将这些图像编组为“good”. 然后用不同工具、不同力度在300枚鸽子蛋的不同部位敲出裂缝,尽量使裂缝的大小、形状、位置不一,并通过图 7实验装置拍摄获得图像,编组为“crack”.
将“good”组和“crack”组图片建立数据集,并对“crack”组图像的裂纹通过图像翻转、旋转及对裂纹复制、粘贴等方式进行数据增强,对数据集进行扩容,得到2179张图片组成的数据集,其中将1 620张作为训练集,559张作为测试集.
-
在网络模型训练阶段,本实验使用的操作系统为Ubuntu 18.04,训练GPU为2060ti,显存容量6144M,测试环境为Python3.8,测试框架为Pytorch1.9.0,使用CUDA版本10.2.89作为框架计算和cuDNN8.2.1的深度神经网络加速库. 迭代批量大小为16,总迭代次数设置为200次,初始学习率设置为0.001.
2.1. 实验设备
2.2. 数据采集和数据集建立
2.3. 训练环境以及模型训练
-
本文的所有结果利用单张图片的检测时间和视频检测的帧数作为模型推理速度的评价指标. 采用准确率(precision)、召回率(recall)、平均精度(average precision,AP)和权重大小等指标衡量检测效果. 准确率越高,分拣正确的鸽蛋就越多;召回率越高,漏检的鸽蛋就越少. 相关指标计算公式如下:
其中,TP为真实的正样本数量,FP为虚假的正样本数量,FN为虚假的负样本数量.
-
本实验分别用未添加SE模块、添加默认SE模块、改进SE模块3个模型进行对比实验,将这3种模型分别命名为YOLOV5,YOLOV5-SE和YOLOv5-改进SE. 检测试验结果见表 1.
从表 1可见,融合了SE注意力的YOLOv5检测的准确率、召回率得到显著提升,整体检测准确率(Precision)达到91.7%,提高了8.5%;召回率(Recall)达到了92.9%,提高了1.8%;在融合改进SE注意力机制后,准确率和召回率的指标进一步提升,分别达到了92.2%和93.8%,对于漏检问题有了较好的改善.
-
为验证本实验对YOLOv5改进后的检测效果,在原数据集上展开消融实验,以判断每个改进点的有效性,依次在原有模型上添加检测层和改进SE注意力机制,进行逐项改进. 结果如表 2所示(使用该项改进用“√”表示,未使用该项改进用“-”表示).
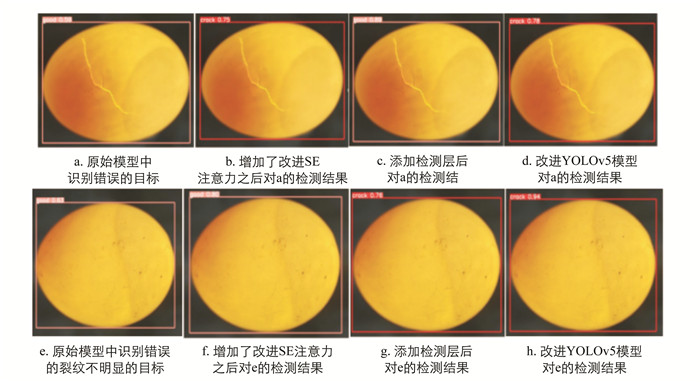
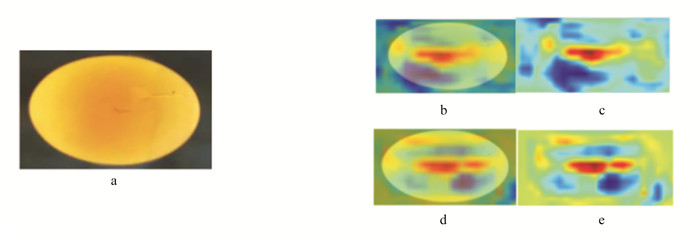
可以看出,引入了改进SE注意力机制后,准确率提高了9%,召回率提升了2.7%;而增加了更小检测层之后,准确率的提升虽然不如融合了改进SE注意力后那么惊艳,但召回率却有了明显的提升,高达3.1%. 综合两种改进之后的新模型在准确率、召回率上都有了明显的提升,其中准确率达到了98%,提高了14.8%;召回率达到了97.3%,提高了6.2%. 实验结果表明,对YOLOv5的每一项改进都取得了一定的效果,综合改进网络结构和预测端的最终模型效果最佳. 部分检测效果见图 8.
-
为了验证本研究实验所用算法的有效性和鲁棒性,本文实验在相同的配置环境下,用Faster RCNN,YOLOv3-SPP,YOLOv5,改进YOLOv5进行了基于同一数据集的对比实验,结果见表 3.
结果显示,Faster-RCNN,YOLOv3-SPP,YOLOv5,改进YOLOv5的准确率分别为49.2%,81.3%,83.2%,97.4%,召回率分别为92.6%,86.9%,91.1%,97.1%,本实验的改进YOLOv5在准确率和召回率方面均为最高水平. 虽然在模型的优化过程中,增加了一定的计算量,导致检测速度略有下降,但差别不大,且在30帧/s的视频流下可以流畅运行并准确识别. 因此,改进YOLOv5模型具有最优检测效果.
3.1. 融合SE注意力机制前后对比
3.2. 消融实验
3.3. 不同模型检测效果比较
-
由表 1可知,融合了SE注意力机制的YOLOv5模型在各项指标上都明显优于原始的YOLOv5模型,表明在neck的C3模块后面融合的SE注意力机制的确提高了对鸽蛋纹理特征的提取能力,从而能够更好地保留裂纹特征,提高了检测的准确率和召回率. 但平均池化层依旧会忽略掉一部分裂纹特征,导致仍有相当一部分裂纹鸽蛋被错检和漏检. 而将SE注意力机制优化后,通过反向的最大池化层提升了裂纹特征的权重;同时,Hardswish激活函数的全连接层替换ReLU激活函数的全连接层后,在基本保证了原有推理速度的前提下,避免了ReLU激活函数在输入为负时存在的神经元坏死问题,确保神经网络误差正常反馈(图 9),检测效果有了进一步提升.
由表 2可知,单项的改进虽然在整体上有所提升,但却有着各自的缺陷:增加了检测层的改进模型虽然提升了对细微裂纹的鸽蛋的检测效果,但对于在YOLOv5模型下裂纹明显的错检鸽蛋的检测结果基本没有得到纠正;而只融合了SE注意力机制的改进模型,虽然在裂纹明显的鸽蛋的错检方面有了较为明显的改善,但对YOLOv5模型下比较细微裂纹的错检或漏检并没有得到很好的纠正. 在融合两种改进之后,模型在减少错检和漏检方面都表现出较好的效果. 增加检测层和融合注意力机制的代价是计算量增加,导致检测速度降低了大约11%,但相对于细微裂纹检测精度接近20%和召回率接近12%的提升,速度上的小幅降低是可以接受的. 因此,这两种改进是比较有效的.
Faster RCNN作为深度学习两阶段的目标检测算法,算法原理是通过RPN(Region Proposal Network)网络先提取出物体的候选位置(Region Proposal),然后对候选位置进行物体分类、边界框回归和置信度计算,因此,Faster RCNN的召回率会高于YOLO系列算法. 从表 3的实验结果中可以看出,Faster RCNN的准确率是四种模型中最低的,表明其较难准确分类出完好鸽蛋和裂纹鸽蛋. 同时,两阶段算法的特性决定了Faster RCNN的运行速度要低于YOLO系列算法. YOLOv3-SPP和YOLOv5的差别不大,但YOLOv5在neck部分引入CSP结构,加强了网络特征的融合能力,从而提高了模型的效果. 此外,YOLOv5模型在检测速度和模型大小上优于YOLOv3-SPP模型,模型性能在整体上也略优于YOLOv3-SPP模型. 而改进的YOLOv5模型不仅性能上优于YOLOv5,而且继承了其占用内存资源较少、适合部署于可移动嵌入式设备平台的优点,相比其他3种模型都有较为明显的优势. 因此,在鸽子蛋的品质分拣中选择YOLOv5算法,并且在两方面进行改进优化,目的是提高模型检测精度和模型特征提取能力:
1) 针对部分破损鸽蛋裂纹比较细微的特点,本研究采用增加检测层的方式增强对细微裂纹特征的提取,以尽可能减少错检和漏检.
2) 针对破损鸽蛋的裂纹特征提取难度比较大的特点,在neck的特征提取模块后加入改进的SE注意力机制,以增强裂纹特征的权重和模型的特征提取能力,进一步提高模型检测精度.
本研究自主设计的检测设备(图 7)对鸽子蛋进行分拣,对于裂纹位于蛋身上的鸽蛋有了较好的检出效果,但对鸽蛋锐端和钝端的细微裂纹,因为角度的原因,无法完全采集并识别到,因此,我们假设鸽蛋锐端和钝端处没有裂纹.
-
本研究实验针对鸽蛋破损的检测任务,提出了一种基于改进YOLOv5的裂纹检测方法,通过数据增强扩大数据集、增加检测层、在主干网络中添加注意力机制并对注意力机制的全局平均池化层和全连接层进行改进,有效提高了裂纹鸽蛋的检测准确率.
实验结果表明,本次实验构建的基于改进YOLOv5的裂纹鸽蛋的分拣识别模型整体性能优于Faster RCNN、YOLOv3-SPP,对于裂纹鸽蛋的识别准确率高、速度快. 在检测设备上进行检测时,模型对鸽子蛋壳裂纹的检测精度达到了98%,召回率达到了97.3%,对单张图片的检测速度在0.09 s以内,开发板环境下可在帧数约30 FPs的实时检测中流畅地运行. 该实验模型已经可以满足企业在鸽子蛋品质分拣上的应用. 并且模型大小仅为4.6 Mb,可搭载在开发板、移动设备等轻量级的设备上,是一个能够大规模部署的轻量级模型,可以为搭建鸽子蛋品质检测流水线提供良好的技术支撑.