


 下载:
下载:







-
开放科学(资源服务)标识码(OSID):

-
近年来,随着机器学习理论的发展,大量人工智能(artificial intelligence,AI)项目应运而生,促使交通环境感知系统朝着多传感器融合的智能化方向发展[1-4]. 目前,交通环境信息的感知主要依靠激光雷达、毫米波雷达和视觉传感器等机器视觉技术,几乎没有听觉技术的应用. 然而,听觉能力对城市智慧交通系统十分关键,交通环境中的声音事件(如喇叭声、警笛声、车辆碰撞声、轮胎制动声等)携带着大量声音信息. 研究交通声音事件分类方法,对于完善道路安全和不同背景下的声音检测方法有重要的实际意义[5]和应用价值.
交通环境中的声音事件(sound event)是指一段独立完整且能引起人们感知注意的短时连续声音信号[6-7]. 声音事件检测(sound event detection,SED) 是交通环境感知的核心技术之一,主要包括声音事件分类(sound event classification,SEC)和声音事件定位(sound event location,SEL). 传统的声音事件分类主要借鉴语音识别和模式匹配,将语音识别技术迁移应用到声音事件分类领域. 例如使用基于矢量量化的识别技术、动态时间规整(dynamic time warping,DTW)技术、隐马尔可夫模型(hidden Markov models,HMM)、高斯混合模型(gaussian mixture model,GMM)、支持向量机(support vector machine,SVM)等技术.
目前,交通声音事件分类相关研究以模式识别理论方法为主,即特征提取,模式匹配. Karpis[8]研究了基于声学信号检测特种车辆(例如警车消防车)的方法,实现了警车、消防车的初步检测. Choi等[9]针对音频监控问题,采用GMM分类器在不同背景噪声环境下对9种异常声音(尖叫声、汽笛声、撞击声等)进行识别,并自动更新模型参数达到对环境的自适应,识别效率有所提高. Li等[10]以HMM识别模型为基础,采用环境中的大量声学事件训练HMM模型,并通过将未知声学事件的MFCC特征与背景池对比,提取目标声学事件的声音,该算法在不牺牲识别性能的情况下简化了模型的复杂度. Lefebvre等[11]在2017年使用声学信号并采用支持向量回归方法实现了交通流量测量. 朱强华等[12]以MFCC特征和SVM作为声音特征和分类器对交通声音分类(警车、消防车、救护车、汽笛声等)进行了研究,通过优化MFCC和SVM算法,完成无人车交通声音分类任务,但其所建模型在信噪比减小的情况下,分类准确率大大降低. 2020年,Zhang等[13]提出了一种基于稀疏自动编码器的车辆声音事件分类方法分析交通状况,其检测准确率达到94.9%.
上述研究主要采用梅尔频率倒谱系数(mel-frequency cepstrum coefficient,MFCC)等声学特征和传统机器学习方法(machine learning,ML)作为声音事件的模型分类器. 然而传统机器学习仅适用于小样本,在处理大样本、高维度的数据时准确率会大幅降低[14]. 此外,实际交通环境噪音较大,MFCC声音特征提取对噪声十分敏感,较大程度上影响了机器学习的性能[15]. 而近几年由于人工智能快速发展,基于深度学习的算法在声音识别方面表现出巨大优势,具有学习能力强、覆盖范围广等优点,通过神经网络对声音事件进行特征提取和学习,可以获得更好的分类效果[16].
鉴于此,本文以SIF特征提取法作为交通声音的声学特征,将卷积神经网络引入交通声音事件分类研究,在VGG卷积神经网络中搭建了双卷积层融合算法以及块间直连通道,提出一种基于改进VGG-16卷积神经网络的交通声音事件分类算法. 该算法对麦克风系统采集到的交通声音进行预处理,将快速傅里叶变换得到的时频域谱图作为声音的特征,神经网络则负责交通声音的深层特征进行学习,完成交通环境的声音事件分类任务. 实验结果表明,本文提出的VGG-TSEC块间直连算法在交通声音测试集上的准确率为97.18%,分类性能优于随机森林、K邻近(KNN)和支持向量机(SVM)等传统机器学习算法.
全文HTML
-
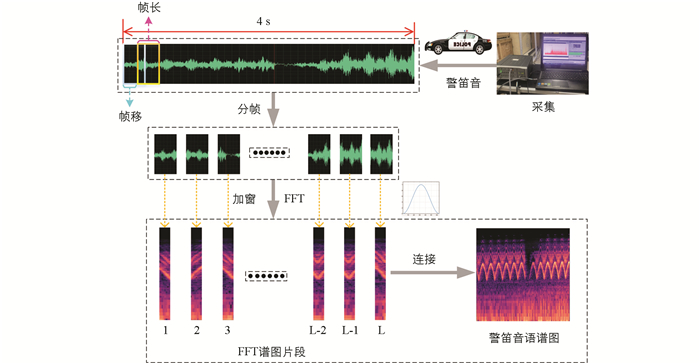
交通声音是一维时域信号,直接输入神经网络会导致信号帧的丢失,进而影响模型精度. 研究表明,语谱图在声音特征标记领域具有较高的噪声鲁棒性优势,然而语谱图特征在兼顾时域和频域信息的同时,容易造成特征泄漏. 因此本文充分考虑语谱图的优势,使用二维语谱图提取交通声音声学特征,增强了特征的噪声鲁棒性. 语谱图特征提取示意图见图 1,该特征是交通声音信号的时频域谱图. 声学特征的提取步骤包括预加重、分帧、加窗、短时傅里叶变换等[17]. 首先使用预加重减小信号在传递过程中高频部分的损失. 对预加重后的目标声音进行分帧,分帧后的片段表现出短时连续性. 汉宁窗是一种窗函数,其定义见式(1),该窗函数用于分帧后的信号处理,可消除各帧两端信号的不连续性,其中M-1是窗函数的周期. 对加窗后的信号进行快速傅里叶变换(fast fourier transform,FFT),计算方法见式(2),将傅里叶变换后得到的时频域谱图碎片按像素帧顺序排列,短时碎片连接即可得到长时稳定的二维特征谱图[18],部分交通声音事件的时域信号和时频谱的特征见图 2.
式中,
$X_{\hat{n}}\left(e^{j \widehat{w}}\right)$ 表示时间n和频率w的二维函数;x[m]为输入的交通声音信号;$w[\hat{n}-m]$ 表示真实的序列信息.
-
语谱图特征提取是将交通声音时域信号从一维映射到二维的图像分类问题. 相比于传统的图像分类方法,深度学习方法可以通过自主学习来提取深层语义特征,加强特征与分类器之间的联系. 目前应用比较成功的卷积神经网络有AlexNet,GoogleNet,VGG,Inception和ResNet系列,此外还包括其他新兴的轻量级网络,如胶囊网络和MobileNet等. 研究表明,CNN结构太深易引起模型过拟合,发生训练退化;结构太浅则容易导致特征提取不充分,无法表达图像的深层次信息. 试验对比以上经典结构模型,选择具有16个权重层的VGG-16网络作为本研究的基线结构,VGG-16网络结构见图 3,包括13个卷积层、3个全连接层、5个最大池化层,以及Softmax输出层.
VGG网络最主要的特点是卷积层采用多个3×3卷积核堆叠构成,池化层则采用2×2的小卷积核. 在感受野相同的情况下,通过较小参数代价的小卷积核能获得更优的非线性结果. 全连接层主要负责卷积特征的融合,起到分类器的作用. 随着网络层数的加深,需要求解的参数数目也随之增加,其中大部分参数来自全连接层. 全连接层的C×1维向量输入Softmax层,该层输出的数值表示该样本所属类别的概率,数值越大,则可信度越高. Softmax函数见式(3).
式中,Zi为第i个节点的输出值;C为分类数目;f(Zi)为分类类别为i的概率;在模型测试中,Softmax层会选择f(Z1),f(Z2),f(Z3),…,f(Zc)中概率最大的类别作为样本的预测标签.
-
传统的VGG-16网络中Softmax层分类的数目达到1 000个,3层全连接层结构为(4 096,4 096,1 000). 第一层全连接层输入参数来自池化层,共25 088个神经元,所需参数为102 764 544个. VGG中3层全连接神经网络共计1.236亿个参数,占总参数量的89.33%. 由此可知,全连接层冗余的参数浪费了系统资源,且容易发生过拟合现象. 本文采用两层卷积核为1×1的卷积层与全局平均池化层融合代替全连接层,降低网络模型权重参数的同时使模型趋于轻量化. 改进后的VGG-TSEC参数数目为0.377亿个,降低72.76%. 全连接层改进前后结构对比见表 1.
卷积层是模型中最为核心的一层,由若干个神经元组成. 假设卷积层第l层直接相连的输入张量为xl∈Rn×p×q,其中p,q分别为矩阵高度和宽度. 第l层激活函数输出al的计算见式(4).
式中,f为激活函数;Wl∈Rm×h×h为卷积核的滤波器,m为滤波器的个数,h为滤波器的尺寸;bl为卷积层的偏置. 常见的激活函数有Tanh,ReLU,Leaky ReLU,Sigmod等. 其中ReLU激活函数收敛较快,然而ReLU存在神经元“死亡”问题,权重迭代见式(5),在使用较大学习率时,wij会取到负值,使激活函数输出为0,因此梯度下降对这些神经元无效. 与之相反,Leaky ReLU在x≤ 0时斜率不为0. 经实验测试Leaky ReLU的交通声音分类性能优于ReLU[19],因此本研究选取Leaky ReLU作为卷积层激活函数.
式中,wij为浅层第i个神经元与深层第j个神经元之间的连接权重;E为网络激活函数.
此外,神经网络在训练过程中极易出现“训练集优,测试集差”的过拟合情况,致使模型的泛化能力差. 因此引入批量归一化层(batch normalization,BN),加快模型训练的收敛速度,增强模型泛化能力.
首先在训练阶段,BN层可以对输入网络的时频谱进行预处理,批处理(mini-batch)输入x:B={x1,x2,…,xm},计算批处理均值μB,见式(6).
批处理数据方差σB2:
规范化处理:
式中,ε是一个很小的数,防止分母为零.
尺度变换和偏移:
式中,γ为尺度因子,β为平移因子.
测试阶段,BN层计算输出
$\hat{x}_{ {test }}$ ,见式(10).式中,μr,σr2,γ,β均来自训练阶段统计或优化的结果,测试阶段直接使用,不会进行更新.
-
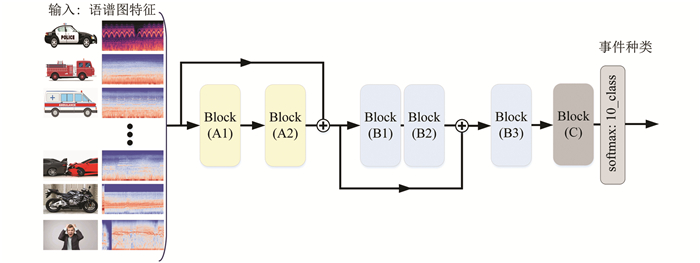
特征信息在网络层传输过程中,各网络块内信息经多层卷积神经网络的特征提取,易产生特征堆叠,从而使特征模糊化,因此本文分别在BlockA1与BlockA2,BlockB1与BlockB2块间引入2个直连通道,A1处部分原始输入的信息传入B1处,B1处的卷积特征传输至B3处,使网络中的SIF特征提取层次不同,这样可以在抑制梯度消失的同时加快网络收敛速度. 改进后的网络结构见图 4,其中2个直连通道分别跨连接核心卷积块. 模型左侧为声音特征输入端,右侧则为Softmax分类的概率. 网络中A1,B1,C 3个核心卷积块的结构和参数见图 5. A1,A2结构类似,包含2个卷积层,1个批量归一化层和1个最大池化层;B1,B2,B3包含3个卷积层,1个最大池化层;C由2个单核卷积层融合全局平均池化层构成.
2.1. VGG网络结构
2.2. VGG卷积神经网络参数优化
2.3. 块间直连通道
-
交通环境中的声音事件类别复杂,如警笛声、汽车喇叭声、车辆刹车制动声、发动机加速声、事故碰撞声、行人尖叫声等. 鉴于典型声音事件对交通系统影响最大,因此研究选择警车、消防车、救护车警笛声、车辆事故碰撞声、公共汽车、城市警报声、摩托车、倒车提示音、行人尖叫声、卡车共10种交通声音作为主要研究对象,场景为交通声学场景. 根据《车用电子警报器》(GB 8108-1999),设置车用电子警报器的音响频率和重复变调周期,见表 2.
交通声音采集过程存在不安全、困难度高等问题,因此在保证实验室声音采集有效的情况下,叠加实际路口交通环境背景音,以模拟真实路况下的交通声音. 本文声音事件的采集工作分2个阶段进行:第一阶段在实验室内采集交通声音;第二阶段采集交通背景噪音. 首先在实验室使用采集设备采集声音. 交通声音采集示意图见图 6,采集设备为LMS Test.Lab,Grass专业级声学麦克风和笔记本电脑等. 实验室采集获得交通声音约10 h. 第二步采集交通背景噪音,采集地点为重庆市北碚区云华路与双元大道某岔路口(路口常见卡车、轿车、摩托车、行人等). 采集现场见图 6,获得交通背景噪音约10 h.
-
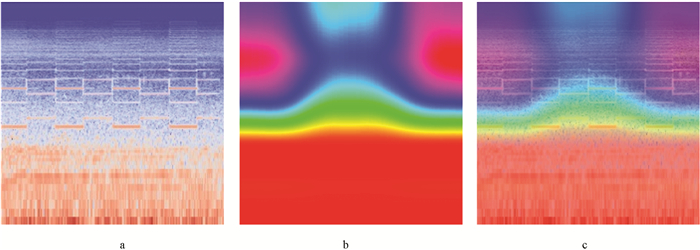
训练深度学习模型需要大量样本,低样本复杂度极易导致模型过拟合. 选择多普勒频移、声音扭曲、卷积混响、相位改变、延迟等扩增方式,对采集到的交通声音进行数据集扩增. 两通道的声音增益和衰减设置见表 3,警笛音原始声音频谱图见图 7(a),卷积混响扩增后的频谱图见图 7(b)和图 7(c). 扩增后得到交通声音数据约45 h. 参考警笛音的周期性,对扩增后的音频声音信号进行切片处理,得到训练集32 740个,验证集和测试集4 092个,各类交通声音的具体编号、数量等信息见表 4和图 8.
-
实验训练与测试计算机的物理环境配置:CPU为Intel(R) Xeon(R) Platinum 8259L,GPU为NVIDIA Quadro GP100,显存16GB,主存192GB;软件环境:Ubuntu操作系统,Tensorflow-gpu 2.5.0深度学习框架,CUDAtoolkit 11.2.0,CUDNN 8.1.0.77,keras 2.5.0,基于python 3.8.12的Pycharm开发环境. 学习率为0.001,最大迭代次数300,选用交叉熵损失函数和Adam模型优化器.
此外,引入准确率(A)、精确率(P)、召回率(R)、F1分数等指标对试验结果进行评价,具体计算方法见式(11)-(14):
式中,TP为真阳性;FP为假阳性;TN为真阴性;FN为假阴性.
-
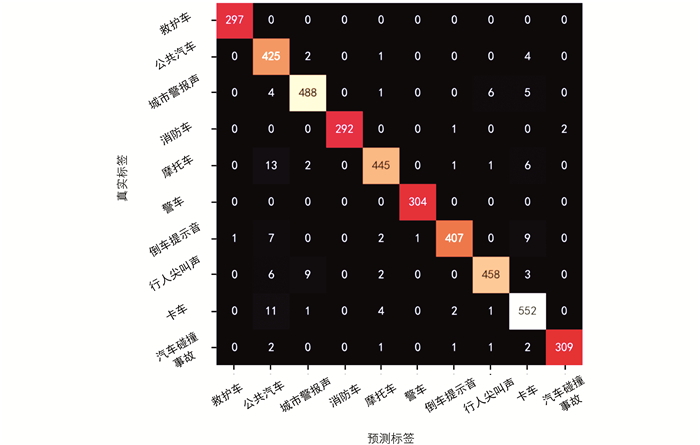
使用交通数据集验证改进后的模型. 通过CAM方法获取声音SIF热力图,见图 9,从热力图高亮部分可以看出该区域包含模型的重要特征. VGG-TSEC模型训练的准确率和损失值曲线见图 10,在迭代了80次后,模型趋于收敛、重合,此时训练集、验证集的准确率和损失值基本保持不变. VGG-TESC混淆矩阵见图 11,混淆矩阵高亮对角线代表模型预测正确数,通过该图可以直观地分析模型分类能力,如公共汽车和卡车的分类性能较差,警笛音的分类结果较好. 交通声音验证集结果见表 5,VGG-TSEC在测试集上的准确率为97.18%,声音事件分类精确率、召回率、F1分数均处于较高水平.
-
将LeNet-5,AlexNet,VGG等卷积神经网络用于验证交通声音数据集,结果见表 6. 本文提出的VGG-TSEC模型的精确率、召回率和F1分数相比其他网络有了显著提高. 实验表明,本文提出的VGG-TSEC比原VGG网络分类准确率高4.68%. 各机器学习方法的交通事件分类性能见表 7,对比VGG-TESC模型与其他研究结果,传统机器学习方法在交通声音事件分类领域的识别准确率较低,而本文所优化的VGG-TSEC分类准确率比随机森林、K邻近(KNN)和支持向量机(SVM)分别提高了17.05%,22.25%,11.59%.
3.1. 建立实验数据集
3.1.1. 采集交通声音
3.1.2. 数据集扩增
3.2. 实验环境配置和模型评估指标
3.3. 分类结果及分析
3.4. 与其他模型性能的对比
-
交通声音事件分类旨在识别环境中的声音事件类别,为交通系统提供更多的声音信息. 结论如下:本文针对现有交通系统环境声音感知能力不足、效率低、鲁棒性低、可分类数量少等问题,基于VGG-16改进并提出了VGG-TSEC交通声音事件分类方法,提高了复杂交通环境下的声音事件分类的准确率,丰富了不同环境背景下的声音事件分类方法.
1) 本文所提出VGG-TSEC交通声音事件分类方法的平均准确率达到97.18%,与AlexNet,VGG-16,ResNet34等网络相比,模型性能显著提高.
2) 实验表明,双卷积层融合算法优化后的模型参数量降低了72.75%,使得网络时空效率均得到了明显提升,为后续移动端的部署奠定基础.
3) 创新性地引入块间直连通道算法,避免深层网络中图形特征堆叠,抑制梯度消失,加快网络收敛速度.