


 下载:
下载:





-
开放科学(资源服务)标识码(OSID):

全文HTML
-
近年来,我国高速公路里程持续增长. 由于高速公路车速快,车流大,当驾驶员遇到团雾时,能见度突然下降极易引起交通事故,造成重大伤亡. 据统计,团雾引起交通事故的概率是其他灾害天气的2.5倍,因此解决高速公路团雾实时检测问题具有重要意义. 由于高速公路摄像头部署密度较密,因此实现基于在线摄像头的能见度测量,能够在更高分辨率条件下实时检测高速公路的能见度,对于小尺度团雾也具备监测能力. 目前,智能交通系统能见度检测一般分为两大类:仪器检测法和图像视频检测法. 仪器检测法是采用仪器,比如散射能见度仪或激光透射能见度仪来替代人工测量能见度,仪器检测的能见度值具有较高的精度,但仪器检测法对设备安装的空间要求较高,探测范围有限,设备造价高昂,难以大面积部署. 图像视频检测法相对于仪器检测法降低了仪器安装的要求,扩大了监测范围,只需要安装摄像头和对应的参照物,构建能见度估算模型就能检测能见度. 我国高速公路里程长,基于图像视频的能见度测量是最经济和实用的方法,对减少高速公路交通事故具有重大意义.
随着计算机视觉技术和人工智能技术的成熟,基于视频图像和深度学习的能见度测量估算模型得到快速发展[1-5]. 目前,基于视频图像的能见度测量方法主要有两种:一种是通过提取图像与能见度相关的特征,比如提取图像对比度、亮度、边缘等特征,再通过神经网络、支持向量机、随机森林等模型构建提取特征和能见度值的映射关系,最后通过映射计算得到能见度. 王兴隆等[6]提出基于U-ResNet的机场视频图像能见度检测;刘冬鞾等[7]提取图像各分块的梯度、饱和度和亮度信息特征,基于简单卷积神经网络建模得到能见度;卢振礼等[8]根据能见度与发光目标物光亮度参数之间存在的显著相关性,设计了高速公路团雾视频监测预警系统;沈岳峰等[9]结合暗通道先验理论和支持向量机算法提出了基于机器学习的白天能见度检测方法. 这类方法不但需要大量高清晰的图像进行预处理和训练,而且在物理上缺乏可解释性. 另外一种是以大气散射模型为基础,结合线性回归分析或暗通道先验理论,构建能见度估算物理计算模型. 杨天麟等[10]构建测距模型,提出了采用改进暗通道先验算法的高速公路能见度检测算法;宋海声等[11]提出了一种基于车道线和暗通道先验理论的能见度计算模型. 这类方法依赖较精细的透射率图,而且计算能见度时一般需要获得摄像机的高度、方向等参数才能计算场景深度或者简单进行线性拟合. 本文结合两类方法的优点,提出一种基于多任务深度卷积网络[12-14]的能见度测量算法,通过设计多条路径的卷积网络分别计算单幅图像的透射率、大气光和场景深度,最后根据大气散射模型计算图像能见度. 本文算法不仅考虑计算模型的物理解释性,同时不依赖摄像机标定或者参照物自动计算场景深度,提升了能见度测量的准确率和速度,改善了能见度的检测结果和适用范围.
-
能见度是指视力正常的人能将目标物从背景中识别出来的最大距离. 大气中粒子的散射作用是导致能见度降低的主要原因. 依据柯西米德定律(koschmieder's law),具体表达如式(1)所示[15].
式(1)中,d为观测点到观测目标的距离,C为目标物与背景的亮度差,C0为目标物自身固有亮度的对比度,σ为大气透明度的消光系数.
目标物可视亮度和目标自身固有亮度之间的对比,通常称为视觉对比阈值ε.
国际民航组织ICAO(International Civil Aviation Organization)推荐视觉对比阈值为0.05时,人眼最大可视距离为能见度距离. 因此,计算大气能见度时,可以将式(3)代入式(1)得到式(4).
式(4)中,当视觉对比阈值为0.05时,计算得到的距离d值也就是能见度距离V. 从式(4)中可以看出,能见度的计算与大气消光系数成反比. 因此,要计算能见度,首先要计算出大气消光系数.
根据大气衰减模型,光线在大气中传播时满足衰减定律
式(5)中,F为物体接收光的光照强度,F0为发射光的光照强度. 式(6)中,t=F/F0为大气透射率,光线经过目标物体反射后,在传播过程中由于空气中的颗粒物散射,导致能见度降低. 在视频图像中,透射率降低主要表现为色彩减退、对比度降低、边缘模糊等特点. z为场景深度,即观测点到目标物体之间的距离. 因此,只要计算出透射率t和场景深度z,通过式(6)即可得到大气消光系数.
将式(6)代入式(4),即可得到能见度距离V.
-
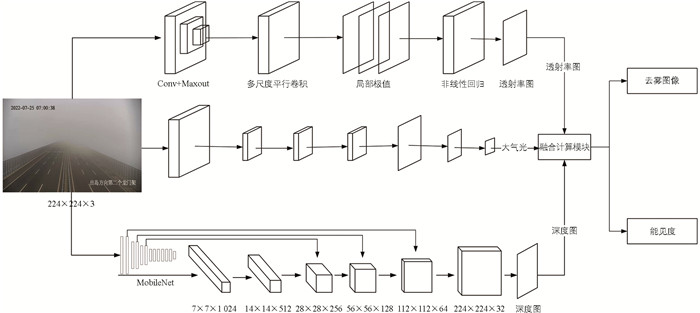
从能见度距离计算公式可知,计算能见度需要得到图像透射率t和场景深度z. 图像透射率计算的准确性又和大气光的估计密切相关. 基于多任务卷积的能见度测量网络如图 1所示,能见度计算网络结构可以分为透射率计算,大气光计算和场景深度计算3个部分.
为了减少模型参数和计算量,参考张东等[16]的方法,采用深度可分离卷积(Depthwise Separable Convolution)替代普通卷积减少网络参数. 深度可分离卷积可以分为深度卷积和逐点卷积. 其中,深度卷积针对每个通道采用不同的卷积核,逐点卷积采用1×1的卷积操作,两者结合效果等同于普通卷积,有效提升了计算效率. 大气光计算部分,单幅图像的大气光值是一个全局变量,因此为了提取全局特征,采用空洞卷积,在控制计算量的同时,增加感受野,通过卷积层提取全局特征,并采用全连接进行降维,得到全局大气光值. 场景深度计算部分,参照Work等[17]的方法,采用Encoder-Decoder架构,Encoder部分采用Mobile Net模型,提取7×7×1 024特征. Decoder部分采用5次上采样,中间3次上采样结果通过跳跃连接方法分别与Encoder部分的特征进行特征融合,为了减小上采样部分的通道特征,还使用了5×5卷积来降维;最后使用1×1卷积得到深度图. 在得到透射率、大气光和场景深度图后,依据大气散射模型可以得到去雾图像,同时根据能见度距离式(7),即可得到像素级的图像能见度. 网络结构不仅能够通过单幅图像计算得出能见度值,而且还适用于非均匀雾的图像场景.
-
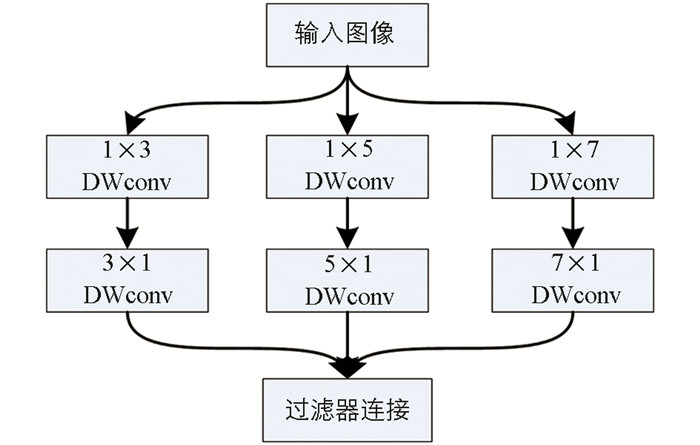
图像透射率计算网络分为特征提取、多尺度平行卷积、局部极值、非线性回归4个部分(图 2).
研究表明,图像雾的浓度主要与4个先验特征相关:即暗通道特征、最大对比度、颜色衰减、色调差异. 为了提取图像雾浓度特征,本文参照图像去雾网络Dehazenet,特征提取采用一个简单的前馈神经网络Maxout,该网络设计了16个卷积滤波器,每4个滤波器等价于一种先验特征提取滤波器. 输入图像为3×16×16,输出图像为16×12×12. 上层输出作为多尺度平行卷积操作的输入. 网络分别使用16个3×3,16个5×5,16个7×7的卷积核,结合深度可分离卷积进行多尺度卷积计算,每一种尺度输出16个特征图,再通过Padding使输出尺寸统一为48×12×12. 然后,局部极值对多尺度的输出采用最大池化操作,考虑到透射率具有局部不变性,因此使用7×7局部最大值替代最大池化,输出图像为48×6×6. 再使用Brelu(双边线性整流损失函数)进行激活,函数有效保存了局部线性和双边约束. 最后通过非线性回归,得到输入块中心点的透射率值,具体参数结构图如图 3所示.
-
大气光值是一个全局变量,与整张图片相关,因此在设计网络的时候应考虑采用相对较大的卷积核,增加感受野. 空洞卷积的好处是在不增加太多计算量的情况下增大感受野,使输出包含较大范围的图片特征信息. 本文首先设计了两层卷积层,分别为7×7和5×5,同时在池化的时候采用最大池化层,这样可以起到有效降维的作用. 然后使用两层全连接层,将维度从256降低到1,输出大气光值.
-
场景深度计算可以分为3个部分:编码部分、解码部分、跳越连接部分,如图 4所示.
编码器网络,通常使用VGG-16或者ResNet-50,本文采用MobileNet进行编码.
解码器网络,由5个级联的上采样层和一个单独的Pointwise层组成,称为NNConv5. 每个上采样层使用5×5卷积,并且输出通道数是输入通道数的一半. 卷积之后使用最近邻插值将特征图的分辨率加倍,并使用Depthwise分解进一步降低所有卷积层的复杂度,得到一个既薄又快的解码器.
为了让高分辨率特征图上所有的细节都能映射到解码器上与解码器内的特征图合并,本文使用了跳跃连接,有助于解码器重建更细节的密集输出,这是在U-Net和DeeperLab中都使用并且被证明有效的技术. 编码器特征图通过加法而不是并列方式合并到解码器特征图上,这样可以避免增加解码层的特征图通道数.
-
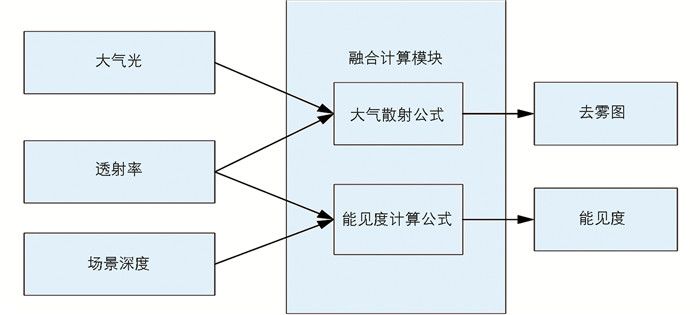
能见度融合计算模块的输入参数是图像的大气光、透射率、场景深度,根据大气散射模型和能见度距离计算公式,得到去雾图和能见度,具体如图 5所示.
通过透射率和场景深度计算模块,分别得到像素级别的透射率和场景深度,通过式(7)可以得到每个像素的能见度计算式(8).
式(8)中,Vpix表示单个像素的能见度,zpix表示某个像素的场景深度,tpix表示某个像素的透射率.
有雾图像包含天空区域,其透射率近似于0,深度近似于无限大. 因此,本文采用设定阈值的方法来排除类似天空区域的异常像素点. 定义3个阈值:像素最小透射率tmin、像素最小能见度Vmin、像素最大能见度Vmax. 当某个像素满足条件透射率大于tmin,并且能见度在Vmax和Vmin之间,则作为有效的像素能见度. 本文采用所有有效能见度的平均值作为整张图像的能见度值. 像素有效能见度用Vest表示,计算式如式(9)所示.
-
多任务卷积融合网络的损失函数由多个部分组成,分别为大气光误差、透射率误差、场景深度误差、去雾误差、能见度误差,如式(10)所示.
式(10)中,LA表示大气光误差,LT表示透射率误差,LD表示场景深度误差,LH表示去雾误差,LV表示能见度误差. λA,λT,λD,λH,λV分别为对应的超参数.
3.1. 网络模型设计
3.2. 透射率计算
3.3. 大气光计算
3.4. 场景深度计算
3.5. 能见度融合计算
3.6. 损失函数设计
-
实验环境显卡为NVIDIA RTX2080Ti,操作系统为Windows 10,内存为32 GB. 使用Microsoft VS Code为开发环境,深度学习框架采用PyTorch 1.11.0进行算法实现和测试. 由于网络训练过程需要有图像对应的场景深度图,因此选择含有深度图的KITTIdepth基准数据集作为训练数据. KITTI的深度数据集是稀疏的雷达图,虽然提供了地面实况数据,但还达不到直接使用深度信息的要求. 因此,构建训练数据标签时使用NYU Depth Toolbox工具进行深度补全,并基于大气散射模型进行人工加雾处理. 通过人工加雾后得到原始图、有雾图、透射率图、深度图作为训练数据集,如图 6所示. 图像数据统一缩放到224×224,得到1 000组样本数据. 在训练阶段采用Adam优化器,初始学习率为0.000 1,批量大小为16,动量参数为0.9.
由于实际高速公路的团雾样本较少,本文通过收集团雾发生时监测摄像头视频图像,自建数据集进行测试,训练后将模型在自建的高速公路图像数据集中进行验证. 自建测试数据集假设能见度仪测量得到的能见度为真实能见度,选择高速公路附近有安装能见度仪的摄像头视频,再通过摄像头视频每分钟截取图片,同时获取能见度仪的能见度测量值,作为图片的能见度标签,通过图片名称命名格式统一命名如下:[时间]_[能见度等级]_[能见度].jpg. 实验数据举例如图 7所示.
-
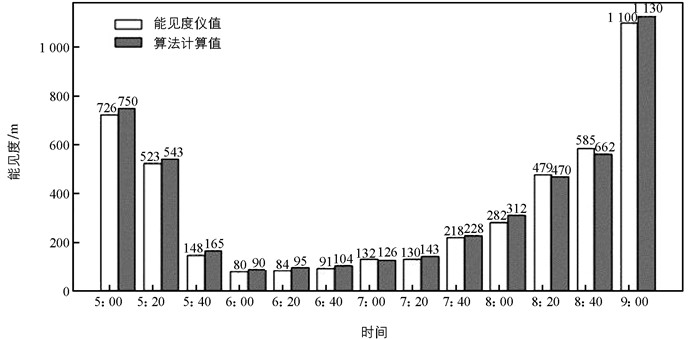
首先对收集到的能见度图片进行筛选,得到2022年7月25日某摄像头5:00到9:00的能见度图片,每20 min获取一张图片,共计13张图像,图像的能见度范围为80~1 100(以能见度仪测试为准). 使用算法对13张图像进行能见度估测,具体算法测试结果和误差如表 1所示.
选取有雾摄像头的视频,选择时间段为5:00到9:00,按每20 min获取一张有雾图片对算法进行测试,并将测试结果与散射式能见度仪进行对比,如图 8所示.
将每张图片估计值与仪器测量值的误差绘制成散点图,并添加拟合趋势线,如图 9所示. 当能见度可视距离小于200 m时,能见度的计算误差较大,大部分超过10%. 随着能见度距离增加,误差逐渐降低并趋于稳定.
-
损失函数的合理设计有助于提高模型的准确率. 融合网络包含上、中、下3条路径,因此损失函数引入了大气光误差λA、透射率误差λT、场景深度误差λD. 除此以外,还额外增加了去雾误差λH和能见度误差λV. 为了方便结果对比分析,本文验证了去雾误差和能见度误差对改进模型的有效性,将能见度值按照国家标准映射为5个能见度等级,并根据模型分类的精确率来评估模型. 对多任务卷积网络模型(Multi-task Deep Convolutional Neural Networks,MDCNN),分别进行3次训练,并对比实验分析结果.
模型1:MDCNN-1损失函数没有增加λH和λV.
模型2:MDCNN-2损失函数只增加λH.
模型3:MDCNN-3损失函数只增加λV.
模型4:MDCNN-4损失函数同时增加λH和λV.
具体测试结果如表 2所示.
从表 2中可以看出,损失函数分别单独引入去雾误差和能见度误差时,对估计效果有一定的提升,但同时引入两种误差时模型估计效果最佳.
-
为了验证算法的准确性和运行速度,本文采用自建数据集,选择优秀图像分类算法进行对比测试,算法选择如下:
算法1:ResNet-50[18]
算法2:VGG-19[19]
算法3:VisNet[20]
算法4:DQVisNet[5]
算法5:MSVP-Net[21]
算法6:MDCNN-4
使用相同的训练数据和测试数据对以上6种算法进行训练和测试,分别计算出图像对应的能见度等级,与散射式能见度仪器进行对比,统计训练准确率和测试准确率,同时计算处理每张图像的平均速度,具体如表 3所示.
从表 3可以看出,在自建数据集上基于多任务卷积融合网络的测量算法相对于其他经典算法,训练准确率和测试准确率均有一定的提升,且计算速度相对较快,适用场景更广,有一定的实际应用价值.
4.1. 实验环境和数据集
4.2. 能见度仪器对比分析
4.3. 消融分析
4.4. 算法对比分析
-
针对高速公路能见度仪器测量部署密度不够,团雾等小尺度天气存在的预报困难问题,本文提供一种基于多任务卷积融合网络的能见度测量方法. 该算法通过设计上、中、下3路网络分别进行有雾图像的透射率、大气光和场景深度估计,同时将多路网络的损失函数进行融合设计,作为能见度测量网络的总损失函数,最终通过大气退化模型公式计算出能见度. 通过实验对比表明,改进后的算法能见度测量准确率更高,不依赖车道线,应用范围更广,能够满足实际交通场景使用要求.