



 下载:
下载:
-
开放科学(资源服务)标识码(OSID):

-
自动化技术对提高育种效率和粮食产量意义重大。小麦作为全球重要的粮食作物,为人类提供了约20%的蛋白质与碳水化合物[1],且在工业原料、生物燃料以及动物饲料等众多领域有着广泛应用。但小麦产量的增长速度已跟不上不断提升的社会发展需求。有数据表明,小麦需求的年增长率为1.7%,而其遗传增益的年均增长率仅为1%[2]。自动化技术在农业领域得到广泛运用,如利用软硬件协同,加速农作物病害鉴定[3],或通过自动化技术替代人工对作物表型(如株高、颜色、麦穗数量等)进行统计分析[4],减少了人力和时间成本,促进了高效育种的开展。
自动化计数筛选具有优良性状的品种是小麦育种中的核心环节。小麦产量作为关键的育种性状,由单位面积的麦穗数、单穗粒数和千粒质量这3个要素共同决定[5]。传统的育种方式不仅效率低下、耗费大量时间和人力,还容易因为人为操作产生较高误差。所以,实现麦穗的自动化计数对于提高育种效率、节省人力资源十分重要。为了实现这一目标,研究人员早期尝试通过图像处理技术来识别麦穗:文献[6]利用颜色和纹理特征处理技术实现了图像中小麦穗的分割;文献[7]结合Gabor滤波器与K-means聚类算法,完成了麦穗区域的检测与计数。不过,这些传统方法的泛化能力有限,容易受到光照、环境等干扰因素的影响,难以适应复杂场景。
随着深度学习技术的不断突破,以边界框监督和点监督为代表的位置监督方法在麦穗计数领域受到了广泛关注[8-13]。这些方法在一定程度上解决了一部分传统方法泛化能力差、抗噪声能力弱的问题,但都依赖高成本的位置级图像进行训练,并且边界框监督和点监督的麦穗计数模型大多基于局部感知的卷积神经网络[14]。然而麦穗密集且多样的位置信息不仅标注成本高昂,还会引入噪声制约模型性能。
本文借鉴了针对人群的计数监督方法[15-18],构建了一个只需图像级计数标签即可做到高精度的麦穗计数网络模型(A Lightweight Count-Supervised Network via Efficient Multi-Scale Dilated Convolution,L-CSNet),其主要的创新之处在于设计了高效多尺度膨胀卷积模块(Efficient Multi-Scale Dilated Convolution,EMDC),即用并行膨胀卷积[19]替代计算密集型结构,在高效捕获多尺度麦穗特征的同时将模型参数量大大降低,且没有削弱模型的性能。在GWHD_2020[20]和GWHD_2021[21]数据集上的实验结果可以清楚地证明,L-CSNet在平均绝对误差(MAE)和均方根误差(RMSE)等指标上都优于现有方法,因此它也是自动化农业计数任务中更经济实用、更易于推广的理想选择,可以更好地推动深度学习在实际农业场景中的应用落地。通过以上论述,本文的主要研究工作有以下几点:
1) 提出了轻量级计数监督网络L-CSNet:该网络只需对图像级计数标签进行训练,并将模型参数量显著压缩,为模型在边缘设备上的实时部署提供实际支撑。
2) 设计了高效多尺度膨胀卷积(EMDC)模块:该模块通过通道优化、并行多尺度膨胀卷积和轻量级注意力机制,实现了高效且鲁棒的多尺度特征感知。
3) 构建架构与训练协同优化策略:从模型架构和训练策略两方面进行协同设计与优化,确保了训练的稳定性和模型最终性能。
全文HTML
-
小麦作为全球广泛种植的农作物之一,其品种因各种自然条件的区域差异呈现出显著多样性。为验证L-CSNet的有效性和泛化能力,本文选取农业表型领域覆盖范围最广且标注规范的全球小麦检测(GWHD)系列数据集作为实验基准(图 1)。GWHD_2020[20]涵盖世界多个地区的4 700张RGB图像,共标注193 634个小麦穗,采集后经数据协调处理确保了所有样本的可视化一致性。该数据集包含不同生长阶段与基因型的小麦品种,麦穗性状丰富多样,可实际检验模型对不同场景的适配能力。GWHD_2021[21]为GWHD_2020的扩展版本,新增了5个国家的1 722张图像与81 553个标注小麦穗,更适用于高密度、复杂背景下的模型性能测试。
GWHD_2020和GWHD_2021的单张图像平均麦穗数量分别为42.77和42.22,其中:中等密度图像占比约75%,是数据集的核心组成部分,让模型能充分学习田间最常见场景的麦穗特征;低密度与高密度图像占比约25%,为模型提供了极端场景的特征学习样本,保证了模型的泛化能力。本文从GWHD_2020和GWHD_2021中选取部分数据集进行筛选与划分,将每个数据集按8∶1∶1的比例划分为训练集、验证集与测试集(表 1)。
-
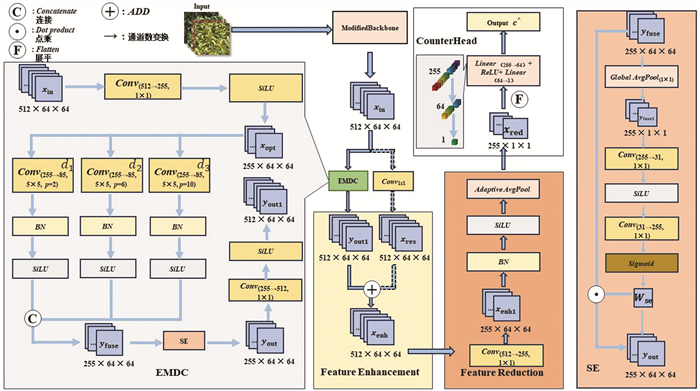
为实现“轻量级、高精度、低成本”的小麦穗计数目标,本文提出的轻量级计数监督网络(L-CSNet)以计数监督为核心设计理念,摆脱了传统位置监督对边界框或密度图的依赖,仅通过图像级计数标签完成训练。L-CSNet整体架构由改进型骨干网络(ModifiedBackbone)、高效多尺度膨胀卷积(EMDC)模块和简化计数头(CounterHead)3部分构成(图 2)。
-
骨干网络是模型进行特征提取的基础,决定了后续模块的表达能力与计算效率。为能在“特征表达能力”与“参数量控制”之间取得平衡,本文基于VGG16[22]网络进行裁剪优化,构建了ModifiedBackbone。该ModifiedBackbone保留了对边缘、纹理等底层视觉特征的提取能力,同时剔除了冗余的全连接层与部分池化层,从而显著降低了计算开销。具体结构包括10个3×3卷积层与3个2×2最大池化层。该骨干网络的参数量仅为7.6×106个,相较完整VGG16降低了约65%,并且依托ImageNet预训练权重进行初始化[23],减少了对大规模训练数据的依赖并加速模型收敛。
-
高效多尺度膨胀卷积模块(EMDC)如图 2所示。模块依次完成通道优化、并行膨胀卷积、通道注意力与通道恢复及残差适配4个步骤。其中,Xbb与Xin均表示ModifiedBackbone输出的特征图,在残差连接部分记为Xbb,在EMDC输入部分记为Xin,以区分其在不同模块中的作用。
为了防止特征图Xin直接进入多分支卷积造成冗余计算,ModifiedBackbone输出的特征图Xin先通过1×1的卷积将通道压缩至255(512→255,其中“→”为通道数变换操作),用SiLU(Sigmoid Linear Unit)激活函数提升非线性表达得到特征图Xopt:
模型将压缩后的特征均匀分配至三路,通过设计的三路并行5×5卷积后得到特征图Yk,膨胀率分别为d1=1、d2=3、d3=5,捕获不同尺度的小麦穗特征,三路通道中的d1用于聚焦细节,d2用于适配中等尺度,d3则用于捕获全局信息。三路的输出最后拼接(Concat)得到融合特征Yfuse:
如图 2所示,在模型中引入改造后的轻量化SE注意力机制[24],目的是突出模型的有效通道,抑制背景噪声的干扰。模块在对Yfuse进行全局平均池化(Global AvgPool,GAP)之后得到了融合特征Yfuse1,再经过两层1×1的卷积与SiLU激活,最后使用Sigmoid归一化得到通道权重向量Wse,Wse与融合特征逐元素相乘并以1×1的卷积与SiLU进行整合得到特征图Yout:
公式(5)中的⊗表示逐元素乘法,经过加权后的特征图为255通道。对特征图使用1×1的卷积将通道恢复至512,和残差分支对齐得到特征图Yout1再与残差映射相加得到增强的特征图Xenh:
这种设计将原始的语义信息与多尺度增强后的特征信息有效融合,保证了梯度的稳定传递,大幅提升了模型在复杂田间背景下的检测鲁棒性。
-
如图 2中Featuer Reduction模块所示,在ModifiedBackbone与EMDC之间引入了残差连接,此设计有效地缓解了深层训练中的梯度消失,确保了特征的稳定分布。模型的ModifiedBackbone输出Xbb后进行1×1的卷积形成了恒等映射Xres,再与EMDC的输出逐元素相加得到Xenh:
模型在最后进行了特征降维操作:在通过1×1的卷积后将通道由512压缩至256,经过BN层与SiLU优化分布后,再通过自适应平均池化操作将空间维度压缩至1×1,得到全局特征向量Xred:
-
如图 2所示,将控制模型输出的计数头(CounterHead)设计为“扁平化—全连接回归”结构,这种设计将全局特征映射为计数结果。先通过扁平化操作将Xred转化为一个256维的特征向量,再经过两层全连接层与ReLU(Rectified Linear Unit)激活函数输出的最终预测计数为$\hat{C}$:
使用了该设计的简化计数头参数量仅约为42 K,只占模型总参数量的极小部分,在最大程度上保证了预测的准确性,而且大幅降低了推理延迟与模型参数量。
-
设计并采用了一种分阶段训练策略的模型训练方式,目的是确保L-CSNet在计数监督场景下的稳定性与精度。在第一阶段的训练中冻结了ModifiedBackbone的浅层参数,仅微调了EMDC模块、特征降维层与计数头,让新设计的模块能够快速学习小麦穗的特征分布。第一阶段的训练轮数为40,学习率设为1×10-5。第二阶段的训练则是解冻所有层进行全局微调,进一步优化了整体网络结构的参数,保证了模型能够在多样化场景下保持稳定表现。设置第二阶段的训练轮数为460,初始学习率为1×10-5,结合MultiStepLR学习率调度策略,控制学习率在训练到第200轮时衰减至1×10-6。
采用Huber损失函数,让模型在面对异常样本时具有更强的鲁棒性。Huber损失函数结合了L1损失(绝对误差)与L2损失(均方误差)的优点,在误差较小时表现为平方损失,在误差较大时转化为线性损失,Huber损失函数的使用避免了L2损失对异常值过度敏感的问题:
其中:$\hat{C}$表示预测计数;C表示真实计数;δ=1为分段阈值。L-CSNet以计数监督为核心设计理念,其核心设计逻辑为麦穗计数结果与麦穗多尺度视觉特征的空间密度存在强线性关联,因此无需位置标注,仅通过预测计数与真实计数的误差损失,即可通过梯度反向传播指导网络自发捕获麦穗特征。该损失并非直接学习“麦穗位置”,而是通过标量误差的空间化梯度分配与多尺度特征的密度感知拟合,让网络聚焦于麦穗的边缘、纹理、麦穗密度等核心视觉特征,同时抑制土壤、杂草等背景干扰;而EMDC模块的多尺度膨胀卷积与轻量化注意力机制,为特征学习过程提供了高效的提取框架,这是实现“无位置标注但有特征精准聚焦”的计数监督学习方法的核心原因。
-
在评估指标的选择上,本文采用平均绝对误差(MAE)衡量模型的计数准确性,采用均方根误差(RMSE)衡量模型的稳定性,采用决定系数(R2)衡量模型的拟合程度:
其中:N表示测试集图像数量;$\hat{C}_i$为第i张图像的预测计数;Ci为真实计数;C为测试集所有图像的平均真实计数。
1.1. 数据集
1.2. 方法与L-CSNet网络架构
1.3. 整体架构设计
1.3.1. 改进型骨干网络
1.3.2. 高效多尺度膨胀卷积模块
1.3.3. 残差连接与特征降维层
1.3.4. 简化计数头
1.4. 模型训练策略与机制讨论
1.5. 评估指标
-
L-CSNet的优化算法采用随机梯度下降算法,并设置动量为0.9,权重衰减系数为5×10-4。分两阶段调整学习率:前40轮冻结ModifiedBackbone浅层参数,设学习率为1×10-5,仅微调EMDC模块与计数头;41-500轮解冻所有层,学习率保持1×10-5,采用MultiStepLR调度器(学习率在第200轮衰减至1×10-6)。
硬件环境为NVIDIA 3070Ti GPU(8GB显存)、AMD Ryzen 55600 CPU,单卡训练总时长约325 h。
-
选取3类主流小麦穗计数方法与L-CSNet进行对比实验,其中:边界框监督方法Faster R-CNN[8]、SSD[25]、DETR[26]、YOLOv11[10]均为不同时期目标检测领域的代表性模型,需人工标注边界框;点监督方法MCNN[27]、CSRNet[28]、WheatNet[12]通过预测密度图实现计数,需人工标注麦穗中心点;计数监督方法TransCrowd[16]、CSNet[18]仅需图像级计数标签,与L-CSNet监督方式一致。
-
通过观察表 2中的数据发现,L-CSNet网络在GWHD_2020数据集上表现优异,MAE和RMSE在所有对比方法中仅次于CSNet。在GWHD_2021更具挑战性的密集场景数据集上,L-CSNet网络的MAE与RMSE表现稳定,模型性能与最佳的CSNet预测结果非常接近。该实验结果证明了EMDC模块通过多尺度膨胀卷积能够有效地捕捉不同密度场景下的麦穗特征,模型具有较强的泛化能力。
L-CSNet网络的模型参数量仅为9.96×106,远低于其他计数监督方法,且优于多数轻量化的点监督模型。同时,L-CSNet网络具备高速的推理能力,其推理速度达到了120 FPS,在表 2的所有对比方法中速度最快。推理速度快与参数量低的特点,有利于L-CSNet在资源受限的设备上实时部署。
通过对比两个数据集的不同结果可得出结论:由于GWHD_2021因包含更多密集和复杂场景的图像,表中所有模型的MAE和RMSE都存在明显上升,但L-CSNet的增幅平稳。这验证了L-CSNet模型的鲁棒性。
-
为了进一步探究L-CSNet模型的拟合程度,采用R2来衡量模型预测值与真实值的线性拟合程度。实验结果如表 3所示。
由表 3可知,L-CSNet在小麦穗计数任务中具有优秀的可靠性与泛化能力,在各类方法中整体拟合度位于前列。
-
为了进一步验证骨干网络对L-CSNet性能的影响,选取了多种经典的网络进行对比,其中包括VGG16[22]、ResNet34[29]、ResNet50[29]、MobileNetV3[30]、EfficientNet-B0[31],以及Swin-Transformer[32]。所有骨干网络均在imageNet上预训练。实验结果如表 4所示。
由表 4可知,采用VGG16时,L-CSNet获得了最优的计数精度。这与任务特性密切相关:小麦穗计数主要依赖边缘与纹理特征,而VGG16的浅层卷积结构更适合这一场景。而ResNet50虽然参数量更大,但表现不佳,说明过深的残差结构可能在简单任务中导致过拟合。
在轻量化骨干方面,MobileNetV3在GWHD_2021上的精度不佳,说明其更适合简单场景需求。EfficientNet-B0表现较为均衡,但精度略低于VGG16。值得注意的是,Swin-Transformer在两个数据集上的表现均不理想,说明该类结构可能更适用于复杂度更高的大规模数据。
实验结果表明骨干网络选择对L-CSNet性能影响显著,合理选择骨干网络是平衡准确性、泛化性与效率的关键。VGG16是当前任务的最优选择。
-
为了验证L-CSNet各核心组件的必要性与有效性,在GWHD_2020数据集上进行了系统性的消融实验。实验以“ModifiedBackbone+CounterHead”为基础方案(Baseline),所有实验均在统一条件下运行,结果如下。
-
如表 5所示,EMDC模块是性能提升的关键,多尺度膨胀卷积能够有效捕捉不同大小的小麦穗特征。而残差连接可以进一步降低误差,说明该措施缓解了梯度消失,使底层边缘与纹理特征能够更好地传递。两阶段训练带来了额外的准确性提升,原因在于冻结浅层保护了预训练特征,避免破坏底层信息,而后期全局微调则优化了整体适配。三者结合使L-CSNet在保持轻量化的同时实现了高精度与高鲁棒性。
-
如表 6所示,三分支设计e=1/3/5(e为膨胀率,1/3/5表示三分支膨胀率分别为1,3,5)能够覆盖麦穗的多样性。四分支并未带来额外收益,原因在于过多分支导致特征冗余,增加了参数量并降低速度。并且SE注意力机制不可或缺,在其关闭后误差显著上升,说明了通道权重调整对抑制背景干扰至关重要。Conv1×1替代FC(全连接层)更高效,可以解释为保持张量结构减少了计算开销。而通道压缩过度显示出性能下降,说明通道过少不足以捕捉复杂纹理。
-
如表 7所示,CounterHead宽度增加(64→128)并未提升性能,结果显示由于任务本身较为简单,宽度过宽反而浪费参数。GeM-pool(Generalized Mean Pooling,广义平均池化)略优于GAP,说明其能更灵活地调整聚合方式,适合密集场景。AvgPool2×2表现较差,原因在于空间压缩过早导致信息丢失。综上,GAP+Lineard的组合是最好的计数头方案,既轻量又准确。
-
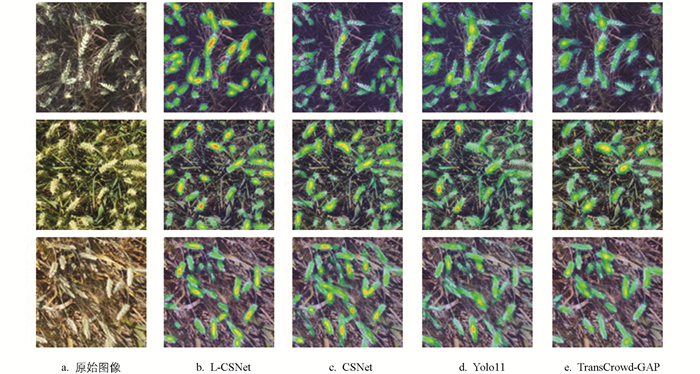
为直观对比L-CSNet与CSNet、YOLOv11以及TransCrowd-GAP在小麦穗区域的关注能力,采用了Grad-CAM技术[33]生成模型最后一层卷积层的注意力热力图(图 3)。
如图 3所示,L-CSNet的热力图红色区域精准覆盖麦穗主体,对杂草、土壤等背景的关注度较低,这表明EMDC模块中的SE通道注意力能够有效强化麦穗相关通道并抑制背景干扰。CSNet的热力图整体表现优于YOLOv11,但在高密度区域仍存在部分背景区域被错误激活的情况,说明其MLP-Mixer结构在复杂场景下存在一定局限性。YOLOv11受限于边界框预测机制,热力图在杂草区域出现较多红色响应,说明检测类方法在复杂背景下容易受到干扰,且对重叠麦穗的注意力分散。TransCrowd-GAP的热力图能够在全局范围内捕捉麦穗分布,但在边界及局部细节上注意力不足,导致部分小麦穗响应偏弱。
综上,L-CSNet在密集场景下的注意力分布最为集中和准确,能够有效区分麦穗与背景,表现优于其他对比模型。
-
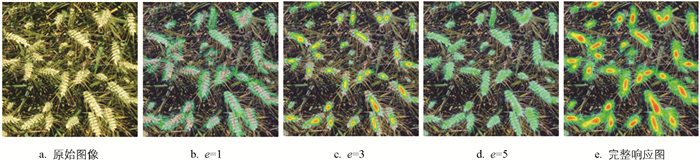
为验证EMDC模块中不同膨胀率的分支在特征提取中的作用,可视化了3个分支的特征响应,结果如图 4所示。
从图 4可知:当e=1时,分支(感受野为5×5)的特征响应集中于麦穗边缘,亮度较高,能够捕捉小尺寸麦穗的纹理细节;e=3时,分支(感受野为13×13)的响应集中于单个麦穗区域,适配中等尺寸麦穗的特征提取;e=5时,分支(感受野为21×21)的响应覆盖密集麦穗全局,能够避免漏检重叠麦穗。三者融合后,EMDC模块实现了细节、局部、全局的多尺度特征互补,这是L-CSNet在密集场景下性能优越的核心原因。
2.1. 实验细节
2.1.1. 训练配置
2.1.2. 对比方法选择
2.2. 性能对比实验
2.2.1. GWHD数据集上的定量对比
2.2.2. 计数拟合程度分析
2.2.3. 不同骨干的影响
2.3. 关键组件消融实验
2.3.1. 核心组件消融
2.3.2. EMDC微结构消融
2.3.3. 计数头与池化策略消融
2.4. 注意力热力图对比
2.5. EMDC模块多尺度特征可视化
-
本文针对农业场景下小麦穗计数任务标注成本高、现有模型计算复杂度高难以实时部署的挑战,提出了一种轻量级计数监督网络L-CSNet。该网络模型摒弃了对边界框或密度图等位置标注的依赖,仅需图像级计数标签即可完成训练,显著降低了数据标注成本。
高效多尺度膨胀卷积(EMDC)模块是本文的核心创新。该模块通过并行膨胀卷积与通道注意力机制,实现了在较低的参数量下对多尺度小麦穗特征的高效捕获。在公开数据集GWHD上的大量实验表明,L-CSNet在计数精度、模型轻量化和推理速度方面取得了平衡,在GWHD数据集上,模型的综合性能均优于现有的位置监督和计数监督方法,模型参数量大幅压缩至9.96×106,在单GPU上实现了120 FPS的实时推理速度。
但本论文工作仍然存在可以改进的地方,未来的工作将集中于以下几个方向:一是探索模型在不同作物(如水稻、高粱)计数任务上的泛化能力;二是研究如何将L-CSNet与无人机等移动平台深度集成,实现真正端到端的实时田间作物表型分析;三是借鉴深度学习与类脑计算[34]的最新进展,提升模型的能效与可扩展性,探究更前沿的农业自动化方法。