





-
开放科学(资源服务)标志码(OSID):

-
枇杷(Eriobotrya japonica Lindl.)属于蔷薇科(Rosaceae)枇杷属常绿多年生植物,原产于中国南方及与云南省交界的老挝、越南等东南亚国家[1]. 枇杷果实含有丰富的矿物质、糖类和有机酸等营养成分,根据果肉颜色可分为红肉枇杷和白肉枇杷两种类型[2]. 枇杷属于呼吸非跃变型果实,成熟度低的枇杷糖分低、含酸量高,鲜食口感偏差; 八成熟以上果实含糖量持续增加,酸度降低[3-4]. 当前,枇杷采收后的品质分级主要通过肉眼可观测和可触摸的外观指标(颜色、大小、硬度、质量等)来进行[5],但人的主观判断容易受很多因素的影响,效率和准确性都较差. 采用理化实验的方法可以对枇杷果实的糖度、酸度、硬度等进行较高精度的检测,但这些检测方法均为破坏性实验,需要耗费大量的化学试剂且费时费力. 而采用光学无损检测,建立数学模型后,仅通过机器扫描就能定量分析果实中的营养指标含量,这为我国未来水果成熟度的准确预测以及果品质量分级制度的建立带来了可能性.
高光谱成像技术(hyperspectral imaging,HSI)利用很多窄的电磁波波段的电磁光谱以成像的形式获取物体特性的有关数据,把传统的二维成像技术和光谱技术有机地结合在一起,能同时分析样品的光谱信息和相应的空间信息[6-7],具有“图谱合一”的特点[8]. 高光谱成像获取的原始图像是三维的,是一系列光波波长处的光学图像,图像像素的横坐标轴和纵坐标轴分别用x和y表示,光谱的波长信息以λ(z轴)表示[9]. 当前,一些学者研究了高光谱技术对香蕉[10-11]、苹果[12]、桃子[13]等水果品质及成熟度的无损检测,取得了较好的效果,但关于枇杷果实品质与成熟度的高光谱成像检测研究鲜有报道.
本文以枇杷为研究对象,在可见-近红外(363~1 026 nm)波长区域内获得高光谱信息,建立果实光谱信息与可溶性固形物(soluble solid content,SSC)、硬度、成熟度回归模型,旨在对HSI用于枇杷果实品质无损检测和成熟度的预测潜力进行评估.
HTML
-
以西南大学果树学重点实验室枇杷种质资源圃的红肉枇杷“金华1号”品种为实验材料,采摘大小均匀、无疤痕、无病虫害、成熟度七成(经验判断)以上的果实,采后2 h内运至实验室,放置于7℃的冷藏柜中保存,于3 d内完成高光谱图像获取和理化实验分析,试验样本总计115个.
-
CT-3型质构仪,美国Brookfield公司. PAL-1型数字折射仪,日本ATAGO CO.,LTD.. 可见/近红外高光谱成像系统(363~1 026 nm): 包括1个线性扫描成像仪(Imspector V10E,Spectral Imaging Ltd.),1个高性能的EMCCD相机(Raptor EM285CL),1个由步进电机驱动的移动平台(Isuzu Optics Corp.),2个光纤卤素灯(IT 3900,150W),1台处理数据的计算机和配套图像获取软件(Isuzu Optics Corp.). 系统放置在封闭的箱体内,如图 1.
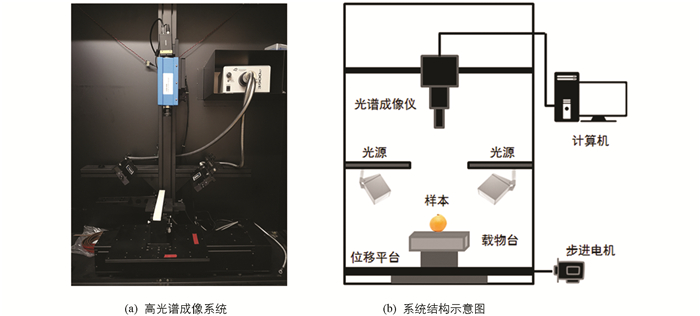
-
将待测的枇杷样本从冷藏柜中取出,放置于20℃室温环境下1 h后进行高光谱图像采集. 参数设置: 光谱分辨率为0.5 nm,样本与镜头之间距离为20 cm,曝光时间为500 ms,载物台移动速度为0.65 mm/s,图像的分辨率为1 632×1 232像素.
为消除光照对图像的影响,使用配套图像处理软件对采集的图像进行黑白校正,校正图像(R)的计算公式:
式中,R0为原始图像,W为白标定图像,B为黑标定图像.
黑白校正后的枇杷高光谱图像需要去除背景仅保留样本区域,或选取图像中的感兴趣区域(ROI),因此,在ENVI 5.1软件中进行ROI提取,并将ROI内所有光谱信息的平均值作为对应反射光谱值,计算公式:
式中,I为ROI区域的平均光谱,m为ROI区域中像素点的个数,Ii为第i个像素的光谱,共1 232个光谱点的光谱数据.
-
去掉样品的果皮,将果肉挤压出汁液于PAL-1型数字折射仪上读数,重复取3次枇杷果肉的汁液,3次读数的平均值作为该样品的SSC值.
-
将果实赤道面果皮小心剥除后,放置于质构仪的测试平板上,探头直径5 mm,测试速度1.0 mm/s,两次压缩停顿时间为5 s,深度5.0 mm,触发点负载0.2 N,重复3次,由质地特征曲线得到果肉硬度.
-
光谱数据处理使用Matlab 2018a软件.
-
由于环境、仪器、人为操作等因素造成的实验误差,应对光谱异常和成分含量值异常的样本进行剔除. 蒙特卡洛方法(Monte Carlo,MC)具有同时检测光谱异常值和理化性质异常值的优点,将所有样本作为建模集建立模型,根据交叉验证均方根误差(RMSECV)最小原则确定最佳主成分数,通过计算各样本预测误差均值和标准差,结合3σ判据方法,判定具有较高预测误差均值和标准差的样本为异常样本[14].
-
联合X-Y距离(samples set partitioning based on joint X-Y distances,SPXY)样本划分方法能够在对样本间距离计算的同时考虑光谱向量和浓度向量[15],因此本文采用SPXY对枇杷样本的SSC,硬度,成熟度按3∶1进行建模集和预测集划分,选择样本时计算其样本间距离dxy(i,j):
式中,dx (i,j)和dy(i,j)分别为仅以光谱和仅以浓度为特征参数统计的各样本间距离,并通过除以各自最大值,从而使两个特征参量在样本选择时权重相同.
-
获得的高光谱图像中共有1 232个波长变量,冗余较多,可从所有波段中选择可分性好的波段子集,降低数据维度. 因此,对样本进行偏最小二乘回归分析,利用竞争性自适应权重采样算法(competitive adaptive reweighted sampling,CARS)、连续投影算法(successive projections algorithm,SPA)进行特征波长的选取.
CARS算法是一种结合蒙特卡洛采样与偏最小二乘(Partial least squares regression,PLSR)模型回归系数的特征变量选择方法,模仿达尔文理论中的“适者生存”的原则. CARS算法中,每次通过自适应加权采样保留PLSR模型中回归系数绝对值大的波长点,去掉权值较小的波长点,再利用交叉验证优选出RMSECV最小的波长子集[13]. SPA算法是前向特征变量选择方法,利用向量的投影分析,通过将波长投影到其他波长上,比较投影向量大小,以投影向量最大的波长为待选波长,然后基于矫正模型选择最终的特征波长,SPA选择的是含有最少冗余信息及最小共线性的变量组合[16].
-
在光谱的定量分析模型中,PLSR是一种处理两数据块之间关系的数学方法和常用的化学计量学算法,能够同时做到回归建模和数据降维,并结合了典型相关分析和多元线性回归分析、主成分分析[17]. PLSR将n个样品m个组分的浓度矩阵Y=(yi,j)n×m和仪器测定的n个样品p个波长点处吸光度矩阵X=(xi,j) n×p分解为特征向量形式Y = UQ + F和X = TP + E,其中U,T分别为浓度特征因子矩阵和吸光度特征因子矩阵,Q,P分别为浓度载荷阵和吸光度载荷阵,F,E分别为浓度残差阵和吸光度残差阵. 而后建立PLS回归模型:
式中,Ed为随机误差矩阵,B为d维对角回归系数矩阵. 对未知待测样品,如果吸光度为x,则其浓度(y)可以求解为:
判别偏最小二乘法(Discriminant partial least squares,DPLS)是基于判别分析基础上的偏最小二乘法,它用类别信息矩阵代替了偏最小二乘法回归模型中的浓度矩阵[18]. 本实验采用PLSR和DPLS进行建模.
SSC和硬度回归模型建立后,将建模集留一法交叉验证相关系数Rc和均方根误差RMSEC作为回归模型性能的主要评价指标,以独立预测集相关系数Rp,预测集均方根误差(RMSEP)作为模型预测性能主要评价指标[19]. 成熟度分类模型以预测集的判别准确率作为评价指标. 建模集的内部留一法交叉验证,使用式(6)和式(7)计算相关系数和均方根误差,
$\hat{y}_{c_i} $ 为用标准方法测定的结果,yci为通过光谱数据测量及数学模型交互验证预测的结果,nc为建模集样品数量; 外部预测集验证使用式(8)和式(9)计算相关系数和均方根误差,$\hat{y}_{p_i} $ 为用标准方法测定的结果,ypi为通过光谱数据测量及数学模型预测的结果,np为预测集样品数量.
1.1. 样品的制备
1.2. 仪器
1.3. 图像采集及校正
1.4. 理化检测
1.4.1. SSC
1.4.2. 硬度
1.5. 数据处理
1.5.1. 异常值剔除
1.5.2. 样本集划分
1.5.3. 特征波长选取
1.5.4. 模型的建立与评价
-
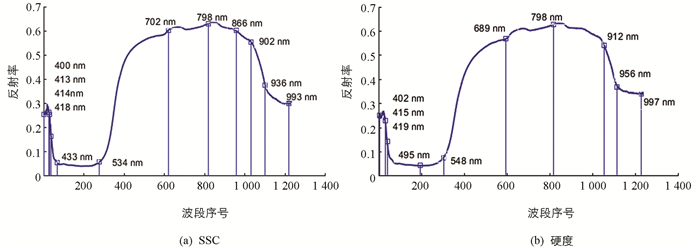
采用ENVI 5.1软件对进行黑白校正后的枇杷高光谱图像进行ROI提取及光谱范围选择. 在枇杷高光谱图像中心部位提取像素400×400的正方形区域为光谱感兴趣区域,每个样本的光谱值以ROI中光谱响应平均值来估算. 分析光谱曲线可知,所有枇杷样本的光谱反射率趋势基本保持一致,在420 nm和680 nm附近有较强光谱吸收特征,这主要是由枇杷中类胡萝卜素和叶绿素吸收光谱所致,980 nm附近的吸收与水分有关(图 2).
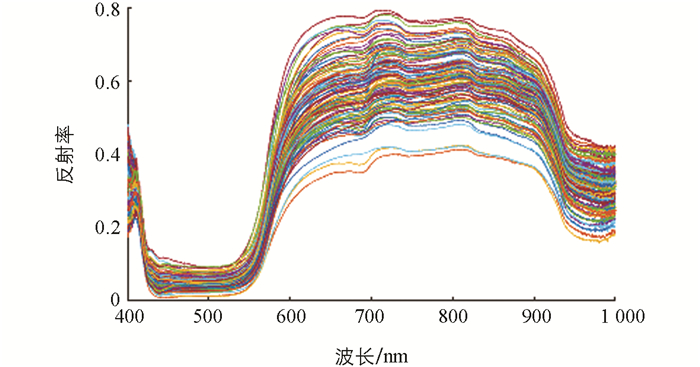
-
采用蒙特卡洛交叉验证法剔除异常值,以全部样本分别建立SSC和硬度的交叉验证模型,计算样本预测误差均值和标准差,散点图见图 3. 结合3σ判据方法对样本中的异常样本进行识别,采用蒙特卡洛交叉验证法建立SSC模型,异常样本有69号,70号,76号,88号,92号,96号; 采用蒙特卡洛交叉验证法建立硬度模型,异常样本有4号,21号,28号,58号,88号,92号. 为尽可能保证样本的多样性,因此仅剔除共有的88号和92号异常样本. 剩余样本进行交叉验证,SSC和硬度交叉检验模型的相关系数Rcv分别从0.892 3,0.851 3提高到0.955 2,0.859 5. 后续用于建模的总样本数为113个.
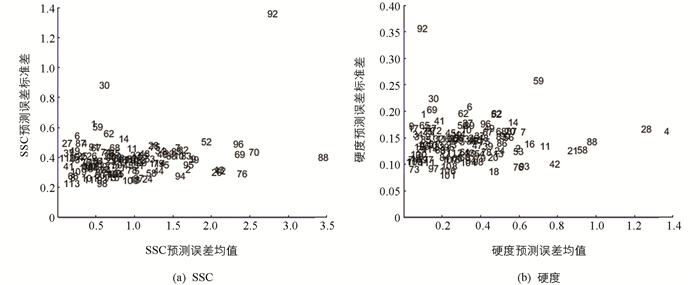
-
经测定,113个“金华1号”枇杷样本的SSC值范围在5.90~13.57 °Brix之间,硬度范围在4.07~7.17 kg/cm2之间,直方图见图 4. SSC值和硬度值分布呈近似正态分布,说明用于实验的样本选择是合适的. 采用SPXY方法将所有样本进行样本集划分,结果见表 1. 可以看出,用于回归模型建立的建模集包含了两个品种枇杷SSC和硬度的最大值与最小值,分布范围较广,样本集划分合理.
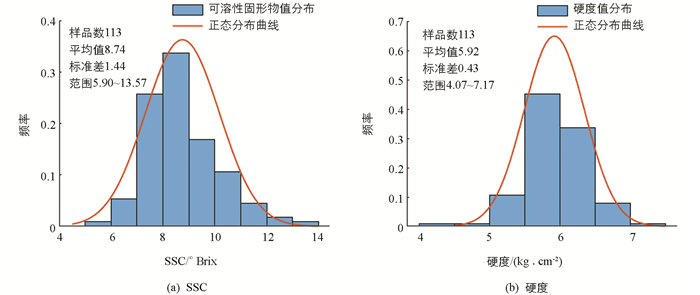
-
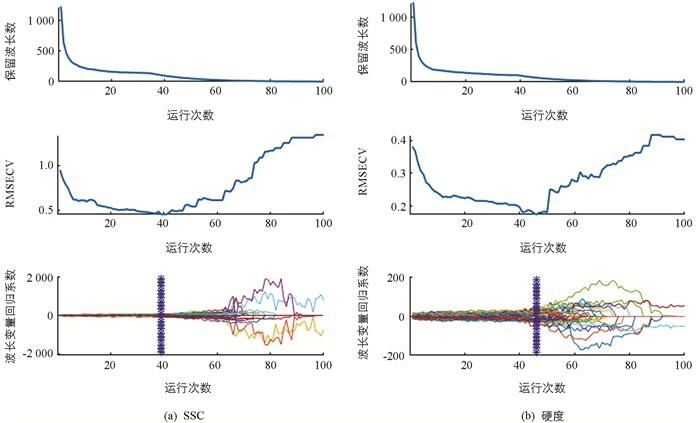
将光谱数据进行预处理后,采用CARS算法提取特征波长建立回归模型. 图 5a为CARS算法选择SSC特征波长的过程,运行次数为39时,选取的波长数为105个,占波长总量的8.52%. 同样方法进行硬度特征波长的选择(图 5b),当运行次数为46时,硬度值选取的波长数为66个,占波长总量的5.36%. 图 6a为SPA算法优选的SSC特征波长分布,选择的波长数范围N=10~84,共选出12个光谱波长,占波长总量的0.97%; 图 6b为SPA算法优选的硬度值特征波长分布,选择的波长数范围N=10~84,共选出10个光谱波长,占波长总量的0.81%.
-
建立全光谱(FS)和CARS,SPA算法优选特征波长的PLSR模型,对其建模效果进行比较分析,结果见表 2和表 3.
由表 2可知,SSC的CARS-PLSR模型与FS-PLSR模型和SPA-PLSR模型相比,Rc值和Rp值均为最大,分别为0.981 7和0.918 5; RMSEC,RMSEP均为最小,分别为0.294 2和0.373 8,具有较好的校正性能和预测性能. 由表 3可知,硬度值的CARS-PLSR模型预测效果也是3个模型中最好的,Rc值和Rp值分别为0.970 7和0.742 3; RMSEC和RMSEP分别为0.113 5和0.165 2. SPA-PLSR模型的预测性能最差,这可能是由于全波长有1 232个光谱点,SPA算法以投影向量最大的波长为待选波长,选出的通常为最小共线性的变量组合,选出的特征波长数较少,而枇杷果实的化学成分较为复杂,导致丢失了一些重要的光谱信息.
-
果实SSC和可溶性糖值变化较大的时间段是在七成熟与八成熟之间. 邓朝军等[3]、许奇志等[4]研究了不同成熟度枇杷的品质特性,发现七成熟至八成熟可溶性糖值迅速上升. 七成熟的枇杷质地较硬,着色淡黄色,SSC和可溶性糖值较低; 八成熟及以上的枇杷则质地较软,着色深黄,香味浓郁,SSC和可溶性糖值显著升高. 采摘时根据样本的外观,对所有样本的成熟度进行标记,并在测定SSC后进行成熟度标记的复核,其中八成熟及以上的枇杷样本有39个,七成熟的枇杷样本有74个. 采用SPXY法按表 4中的数量进行校正集和预测集样本划分; 光谱采用CARS法进行特征波长选择; 类别信息矩阵中,将八成熟及以上的枇杷成熟度属性赋值为1,七成熟的枇杷成熟度属性赋值为2[18].
以建模集85个样本建立DPLS定性判别模型,独立预测集28个样本进行模型的验证,预测集样本中有6个八成熟及以上的样本,有两个样本的类别预测值为2,即有两个样本被错判为七成熟; 预测集样本中有22个七成熟的样本,有1个样本的类别预测值为1,即有1个七成熟的样本被错判为八成熟及以上. 采用DPLS算法对枇杷果实成熟度进行预测,预测集28个样本中八成熟及以上的枇杷预测准确率为66.67%,七成熟的枇杷预测准确率为95.45%. 所有样本判错数为3,总的预测准确率为89.29%(表 4).
2.1. 高光谱图像预处理
2.2. 异常样本剔除
2.3. 枇杷品质指标理化测定结果及样本划分
2.4. 特征波段选取
2.5. PLSR模型的建立
2.6. 成熟度预测
-
采用高光谱成像技术,开展了枇杷品质检测方法的研究,通过光谱与图像信息相结合的方法实现了枇杷果实SSC和硬度的预测以及成熟度判别,主要结论如下:
① 将枇杷果实的光谱信息和理化值经过蒙特卡洛交叉验证法剔除了2个异常值后,所有样本的SSC和硬度交叉检验模型的相关系数Rcv分别从0.892 3,0.851 3提高到0.955 2,0.859 5.
② CARS算法进行波段选取可以有效去除全光谱波段中的无关信息和冗余信息,降低模型的复杂度,提高模型的预测能力. 采用SPXY-CARS-PLSR建立回归模型并进行外部预测集数据验证,SSC的建模集相关系数Rc值和预测集相关系数Rp值分别为0.981 7和0.918 5; RMSEC,RMSEP分别为0.294 2和0.373 8; 硬度的建模集相关系数Rc值和预测集相关系数Rp值分别为0.970 7和0.742 3; RMSEC,RMSEP分别为0.113 5和0.165 2,与FS-PLSR模型和SPA-PLSR模型相比,CARS-PLSR模型具有较好的校正性能和预测性能.
③ 采用DPLS建立枇杷果实成熟度判别模型并进行外部预测集数据验证,28个预测集样本共有3个判错,总的判别正确率为89.29%. 八成熟及以上的样本数量较少,还需在后续的研究中增加样本.
 DownLoad:
DownLoad: