





-
开放科学(资源服务)标识码(OSID):

-
柑橘是我国种植面积和产量最大的水果作物,对我国南方农村乡村振兴发挥了重要作用[1]。氮是柑橘生长发育的三大必需营养元素之一[2],但过量施氮可能会造成柑橘植株徒长[3]、花芽分化受阻[4]、果实酸度增加[5]、果皮增厚与转色推迟等问题,不仅增加肥料成本,而且还破坏土壤环境。因此,快速监测诊断果园土壤有效氮含量进而科学合理施氮,对柑橘优质丰产栽培具有十分重要的意义。
近年来,高光谱成像技术作为一种快速无损检测植株与土壤中物质含量的技术广受关注,且取得了一定进展。彭杰等[6]利用便携式地物光谱仪建立了4种不同类型土壤全氮含量高光谱反演预测模型;刘霞等[7]利用蝙蝠算法建立了柑橘叶片氮含量PLSR预测模型;赵建贵等[8]建立了番茄叶片光合色素含量高光谱预测模型(CARS-IRIV-PLSR)。基于此,本研究在传统模型的基础上,通过一阶导数、二阶导数、平滑滤波函数、标准正态变量变换和小波变换等5种光谱预处理方法,建立其与土壤有效氮含量之间的相关性,采用支持向量机回归、偏最小二乘回归以及海鸥算法的智能优化偏最小二乘回归来构建不同预测模型,通过比较各模型的预测精度,筛选最适宜的光谱预处理方法、特征波段选择和建模算法,以期为建立一种快速无损果园土壤有效氮含量预测技术提供理论依据与方法。
HTML
-
本试验于2023-2024年度在重庆市北碚区歇马街道西南大学柑桔研究所栽培与智慧化中心试验示范园中进行。果园位于北纬29°45′、东经106°22′,气候为亚热带季风气候,年均日照时长为1 224 h,年均降水量为1 351 mm,年均气温为19 ℃。果园土壤为紫色土,其中土壤有机质含量为30.69 g/kg,pH值为7.46,碱解氮含量为98.38 mg/kg,有效磷含量为110.39 mg/kg,速效钾含量为275.37 mg/kg,有效镁含量为23.75 mg/kg,有效钙含量为783.81 mg/kg。试验材料为果园采集的150个土壤样品。
-
土壤样品于2024年12月随机采自西南大学柑桔研究所栽培与智慧化中心试验示范园,每个土壤样品采集同一株果树四周沿滴水线0~45 cm深处的4个均匀土块,通过四分法进行混合取样,大约1 kg/样。样品带回实验室风干,研磨后用20目筛网全部过筛,150个样品随机分成训练集96个,测试集30个,验证集24个,使用便携式地物光谱仪(ASD)进行图像数据采集,采用碱解氮扩散法[9]测定土壤有效氮含量,结果如表 1示。
-
高光谱数据通过美国ASD公司研制生产的FieldSpec4 Standard-Res便携式地物光谱仪进行采集,所获得的光谱数据使用Python 3.11对其进行各种光谱预处理、提取特征光谱和建立模型。利用R语言进行相关性分析。
1.1. 研究区概况
1.2. 数据测量
1.3. 数据分析
-
采用便携式地物光谱仪采集高光谱数据,该仪器主要用于野外地表反射率、辐射率等光谱数据测量,核心结构分为硬件系统和软件系统两部分[10]。其中,硬件系统包括光学探头、光谱仪主机、控制与储存单元、校准和辅助配件等;软件系统主要为采集软件(ViewSpec Pro)。在地物光谱测量前,需进行黑白校正以消除仪器噪声和环境干扰,校正公式如下:
式中:Vtarget(λ)为目标物的原始光谱信号(未校正的DN值);Vdark(λ)为暗电流信号(盖上镜头盖或使用黑筒测量的背景噪声);Vwhite(λ)为白板参考信号(标准反射板的DN值)。
-
本研究采用竞争自适应重加权采样法(Competitive Adaptive Reweighted Sampling,CARS)进行特征波段的选取。通过模拟“达尔文进化论”的竞争机制[11],自适应地筛选出对建模最重要的变量,从而提高建模的预测精度和可解释性[12-13]。
-
支持向量机回归模型(Support Vector Regression,SVR)[14]利用已经输入的空间和超平面内找到一条拟合函数并构建一条宽度为2 α的间隔带,如图 1所示,SVR并不要求目标穿过所有点,容忍小误差,若训练值位于条带内,则预测正确。图 1中,±α表示支持向量机的随机误差,f(x)=αRx+β表示超平面。本模型采用SVR来预测土壤有效氮含量,以光谱特征为x变量,并将这些特征投射至高维超平面,然后进行泛化拟合[15-17]。
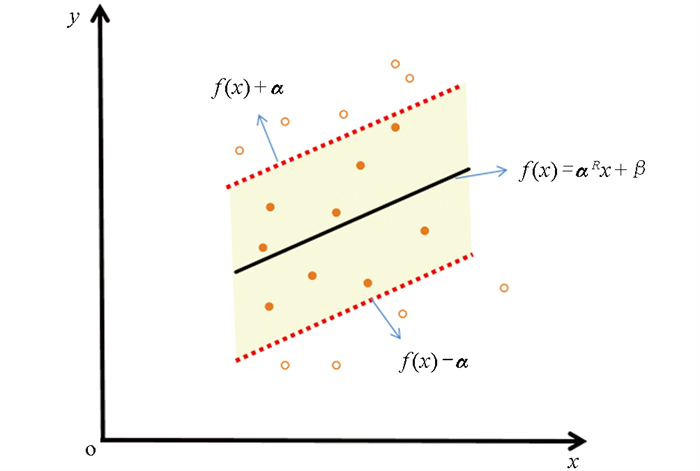
-
偏最小二乘回归(Partial Least Squares Regression,PLSR)[18]是一种多元统计分析方法,主要应用于处理预测变量多重共线问题或预测变量数量多于观测样本数量时进行回归建模。PLSR会将高维的预测变量和响应变量投影到新的低维空间,在这个新的低维空间中建立回归关系,然后再投影回高维原始空间,并建立新的综合变量,新变量可以较好解释自变量与因变量之间的协方差[19-20]。
-
海鸥优化算法(Seagull Optimization Algorithm,SOA)[21]是一种模拟自然界海鸥迁徙和攻击(捕食)行为的群体智能优化算法。它的核心流程包括迁徙(避免碰撞、向最佳邻居方向移动、靠近最佳位置)和攻击猎物。在优化偏最小二乘回归(PLSR)模型时,海鸥算法主要用于确定PLSR模型的最佳成分数量,从而提高模型的预测性能。
1) 初始化海鸥种群。随机生成一组“海鸥”,每只海鸥代表一个可能的PLSR成分数量。成分数量的取值范围通常由用户指定。例如,在代码中,海鸥的初始位置(即成分数量)是通过随机数生成的,范围为n_components_range=[2, 20]。
2) 适应度评估。对每只海鸥的适应度进行评估。适应度函数通常定义为模型的负均方根误差(RMSE)。在PLSR模型中,适应度函数为:
式中:yi为真实值;
$\hat{y}_i$ 为预测值;m为验证集的样本数量。适应度值越小,表示模型性能越好。3) 位置更新。根据适应度值更新每只海鸥的位置(即成分数量)。位置更新规则结合了全局搜索和局部搜索。全局搜索:海鸥会随机调整位置,探索新的成分数量。局部搜索:海鸥会向当前最优解(即适应度最高的海鸥)靠近,进行局部优化。
4) 迭代优化。重复上述适应度评估和位置更新过程,直到达到预设的最大迭代次数。在每次迭代中,算法会记录当前最优的成分数量,并将其作为全局最优解。
5) 输出最优解。最终输出最优的PLSR成分数量,用于训练最终的PLSR模型。
6) PLSR模型训练与评估。使用海鸥算法优化后的成分数量训练PLSR模型,并在训练集、验证集和测试集上评估模型性能。
-
模型评价指标采用预测值和实测值的决定系数(R2)和均方根误差(RMSE)来进行判断,R2越接近1,RMSE越小,则说明模型精准度越高。计算公式如下:
其中:yi表示土壤有效氮含量的实测值;
$\hat{y}_i$ 表示土壤有效氮含量的预测值;yi表示实测值的平均值;m表示预测值的数量。
2.1. 数据采集与校正
2.2. 特征波段筛选
2.3. 模型构建
2.3.1. 支持向量机回归模型
2.3.2. 偏最小二乘回归模型
2.3.3. 结合海鸥算法智能优化
2.4. 模型评价
-
由图 2可知,原始光谱(OS)在全波段的反射率与氮含量之间均表现为极显著的负相关,并在波长为2 269 nm至2 283 nm相关性最高,R2=-0.59;D1处理后,在波长2 201 nm处(R2=0.63)和2 257 nm处(R2=-0.72)与氮含量的相关性达到最高正相关和负相关;经过D2处理后,在波长1 379 nm和波长1 416 nm处与氮含量的相关性最强,R2分别为0.40和-0.57;经过SNV变换后在波长1 432 nm和1 433 nm处正相关性最强,R2=0.77,在波长2 160 nm和2 161 nm处负相关性最强,R2=-0.53;经过SG变换后与OS曲线基本一致,同样在2 269 nm至2 283 nm相关性最高,R2=-0.59;经过WAVE处理后,波长在2 271 nm至2 278 nm处与氮相关性最强,R2=-0.59。综合上述,D1预处理效果相较于其他处理更为理想,相关系数无论是正相关还是负相关均高于其他预处理方式。
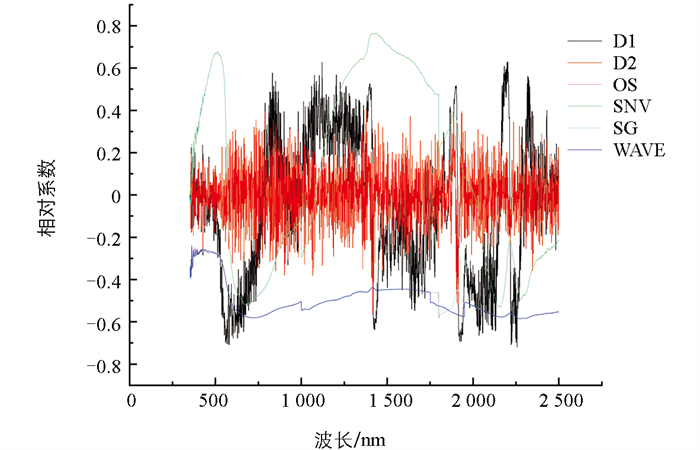
-
图 3为基于竞争自适应重加权采样法(CARS)选取的原始光谱和经过各种预处理后的特征波段,以SG为例,随着蒙特卡洛迭代次数的不断增加,选取的特征波段数量和RMSECV在不断下降,当运行到24次时,RMSECV达到最小,随后逐渐增加。故在24次时确定特征波段,此时选择的特征波段数为81。同理,从D1、D2、SNV、WAVE 4个处理的变换后的光谱中分别选取124、165、94、124次。可见,经过CARS选取的特征波段比较均匀。
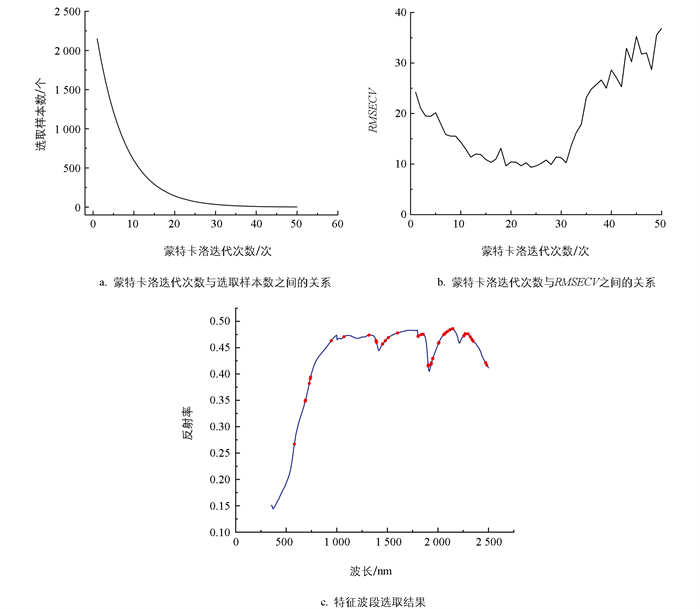
-
使用不同光谱预处理变换、特征波段选取算法预测土壤有效氮含量的精确度尚不清楚,因此,需建立不同的模型预测土壤有效氮含量,结果如图 4所示。对于原始光谱(OS),PLSR的模型精度要高于SVR;经过D1、D2、SG、SNV、WAVE 5种预处理后,PLSR模型预测土壤有效氮含量的精准度均不同程度地优于SVR模型,表现为PLSR模型的R2要高于SVR模型,PLSR的RMSE要低于SVR模型。
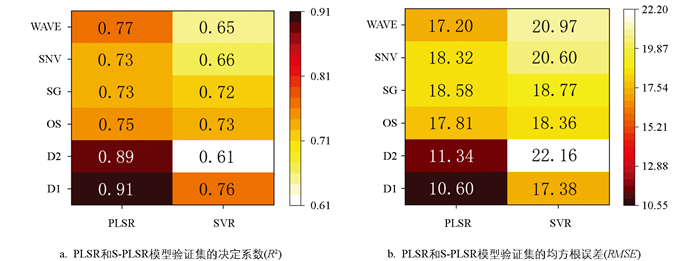
-
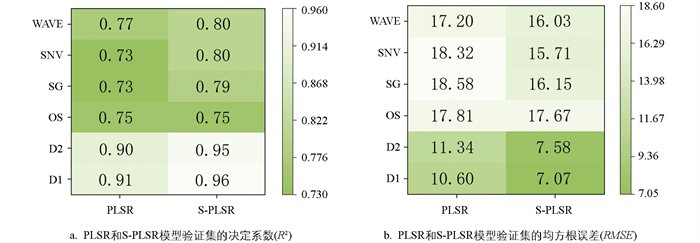
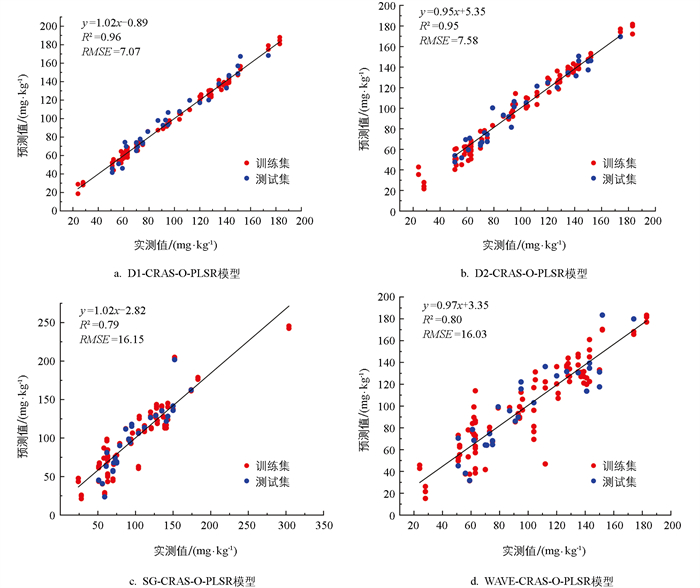
为了建立相对更准确的回归预测模型,本研究在PLSR模型基础上采用海鸥算法(SOA)进行改良优化,以提高模型的预测精度,得到了R2更高和RMSE更低的S-PLSR模型。如图 5所示,相比PLSR模型,S-PLSR模型的R2提高了5.4%,RMSE降低了14.5%,可见,基于SOA优化的PLSR模型可以更加精准的预测土壤有效氮含量。同时,D1预处理的R2达到了0.96,RMSE仅为7.07,为5个光谱预处理中预测精度最高的一种方式(图 6)。
3.1. 光谱变换及相关性分析
3.2. 特征波段筛选
3.3. PLSR和SVR模型估测土壤有效氮含量结果
3.4. 基于混合海鸥智能算法优化PLSR模型预测土壤有效氮含量
-
本研究采用5种光谱预处理方法对原始光谱进行处理,以降低光谱数据噪声,来提高建模预测土壤有效氮含量的精度。使用CARS进行特征波段筛选,再对原始光谱和5种预处理后选取的光谱分别进行建模,得到PLSR模型和SVR模型;使用海鸥算法对PLSR模型进行进一步智能优化得到了最终的S-PLSR模型,其中D1光谱预处理建模的土壤有效氮含量预测精度相对最高。与陈红艳等[22]、徐永明等[23]的研究结果一致,这可能是因为一阶导数精准匹配了光谱噪声消除与有效信息增强的结果,即同时兼顾“降噪效果”和“特征保留”。从特征波段选取角度看,CARS算法在不同预处理光谱中筛选出的特征波段数量存在明显差异,其中D1预处理后筛选了124个特征波段,其波长分布与土壤有效氮含量的敏感光谱区间(2 200~2 300 nm)的N-H键伸缩振动波段重合度最高,从而提高了相应建模预测精度。
本研究采用PLSR、SVR、S-PLSR 3种算法进行建模,结果表明,不同光谱预处理下,PLSR的R2均高于SVR,RMSE均低于SVR,这与裴志福等[24]的研究结果相似,PLSR算法所建立柑橘土壤有效氮含量预测模型比SVR具有相对更高的精度。可能与PLSR是一种融合主成分分析、典型相关分析和多元线性回归优势的多元统计数据分析方法,主要用于解决多因变量对多自变量的回归建模问题,专门针对适应高维复杂信息的数据结构和问题设计的算法[25]。它通过有监督的潜变量提取,高效地解决了维数灾难和多重共线性问题,直接从海量光谱数据中提炼出对预测目标最相关的信息,同时以较低的模型复杂度和易于控制的过拟合风险,在小样本条件下实现了优异的泛化性能[26]。SVR是一种强大且灵活的通用算法,在处理复杂非线性关系或样本量相对充足的非光谱问题上可能表现更好[27]。然而,在光谱分析的特定约束条件下,其灵活性反而可能成为负担(如难以选择最优核和参数、过拟合风险高),导致其在实际应用中平均精度往往低于精心构建的PLSR模型。当然,具体哪个模型更好最终取决于具体的数据集和问题,但PLSR在光谱领域被广泛采用并取得优异成果,正是源于其算法特性与数据特性的高度契合。在经过SOA算法智能优化后,得到了S-PLSR模型,相较于PLSR模型,S-PLSR的R2得到了不同程度的提高,RMSE也显著降低,这说明在PLSR模型的基础上,SOA优化后的S-PLSR模型预测精准度更高。从优化参数的角度来看,这可能是因为海鸥算法突破了传统参数选择方法的局部最优局限,PLSR的预测性能高度依赖潜在变量数(LVs),传统交叉验证或经验法常因搜索范围有限,导致LVs过少或过多。而SOA通过模拟海鸥“迁徙-攻击”的群体智能行为,在预设的LVs范围(2~20个)内实现全局搜索,其以模型测试集RMSE的负值为适应度函数,通过迭代更新筛选出预测误差相对最小的LVs,因此,其优化后的模型精度相对更高。
目前,大量数据模型分析系统被应用于高光谱数据与元素含量预测的关系之中,PLSR作为应用较为广泛的模型之一,其优化途径仍需不断拓展。本研究采用海鸥算法对PLSR模型进行优化建立了D1-CARS-S-PLSR模型,得到了较好的柑橘土壤有效氮含量预测结果,验证集决定系数R2高达0.96,可见,S-PLSR模型可以为柑橘土壤有效氮含量的估测提供一种新的技术路径,研究结果可为柑橘生产精准施氮的土壤有效氮含量快速无损监测提供有效方法。虽然本研究初步建立了基于高光谱技术的柑橘土壤有效氮含量预测技术,但采集的土壤样品仍需进行土壤水分与土壤颗粒大小等的简单前处理才能得到较为理想的光谱信息,今后可通过田间大量实时样本的训练学习与建模优化,有望实现真正意义上的田间在线实时检测。
-
本研究采用D1、D2、SG、SNV、WAVE 5种方式对原始光谱进行预处理,利用CARS进行特征波段的筛选,结合SVR和PLSR算法建模,最后通过SOA对PLSR进行智能优化,初步建立了柑橘土壤有效氮含量预测精度相对较高的S-PLSR模型,其中D1光谱预处理的模型精度相对最高,建立的D1-CARS-S-PLSR模型表现出最佳的预测性能,其R2为0.96,RMSE为7.07。
 DownLoad:
DownLoad: