





-
开放科学(资源服务)标识码(OSID):

-
近年来,以卷积神经网络为核心的深度学习技术在计算机视觉领域取得了突破性进展,在病害特征提取、分类识别与目标定位任务中具备远超传统人工识别方法的精度与鲁棒性,为作物病害智能检测提供了全新的技术方案[1]。随着智能农业的快速发展,利用深度学习技术对番茄叶片病害进行实时检测可显著提升番茄生产效率。
当前,国内外主流的基于深度学习的目标识别模型有单阶段目标检测算法和双阶段目标检测算法。单阶段目标检测算法包括SSD[2]、YOLO[3]等,其中YOLO模型因检测速度快、准确度高而备受关注[4]。然而,在农田的叶片病害检测场景中,叶片病害目标普遍存在小目标占比较高、背景复杂以及现有识别模型难以兼顾检测精度与模型轻量化的问题。
针对上述问题,本研究围绕番茄叶片病害识别任务设计了Dil-YOLO(YOLOv8n-DilatedConv-Slim-Neck)番茄叶片病害识别模型,从3个方面进行改进:①在YOLOv8主干网络设计了Dil-FasterNet模块,替换原C2f模块,该模块将标准卷积拆分为单通道空间特征提取的深度卷积(Depth Wise Convolution,DWConv)与跨通道特征融合的逐点卷积(Point Wise Convolution,PWConv),在不破坏特征传递逻辑的前提下大幅降低单卷积层的参数量与浮点运算量;②引入高效特征颈部网络Slim-Neck模块[5],该模块通过分组卷积(Grouped Convolution,GConv)与通道混洗操作的协同作用,在降低卷积运算参数量与计算复杂度的同时,保留了通道间的特征交互能力;③设计了FocalWise-IoU损失函数,结合Wise-IoU函数的动态聚焦机制[6]和Focal-EIoU v1函数的动态权重分配机制[7],加强对低质量锚框的识别能力。通过上述改进整体提升番茄叶片病害识别的准确性与鲁棒性。
HTML
-
本研究使用的复杂环境下番茄叶片数据集采集于陕西临潼番茄产业园,该产业园具有独特的地理位置和多样的气候条件,为获取丰富多样的番茄叶片病害数据集提供了理想环境[8]。在不同生长时期(发芽期、幼苗期、开花期和结果期)及不同场景(图 1)下对番茄叶片图像进行了采集。图像采集相关信息如表 1所示。

由于番茄发芽期相对较短,而幼苗期和开花期持续时间长,感染病害概率大,且需在结果期前进行病害检测,故本数据集主要选取幼苗期和开花期的图像进行实验。该数据集包括3 451张番茄叶片病害图片,并且使用LabelImg工具标记3 723个手工数据框,由研究团队采用“初标-校验-复验”三级质控模式,对数据集进行标注后划分为训练集(2 039张)、验证集(572张)、测试集(840张),从而保证训练和测试数据的一致性和准确性。数据集划分情况如表 2所示。
-
本研究将YOLOv8系列模型参数进行了对比(表 3),其中FLOPs(Floating-point Operations)为模型浮点运算量,Params为模型参数量。
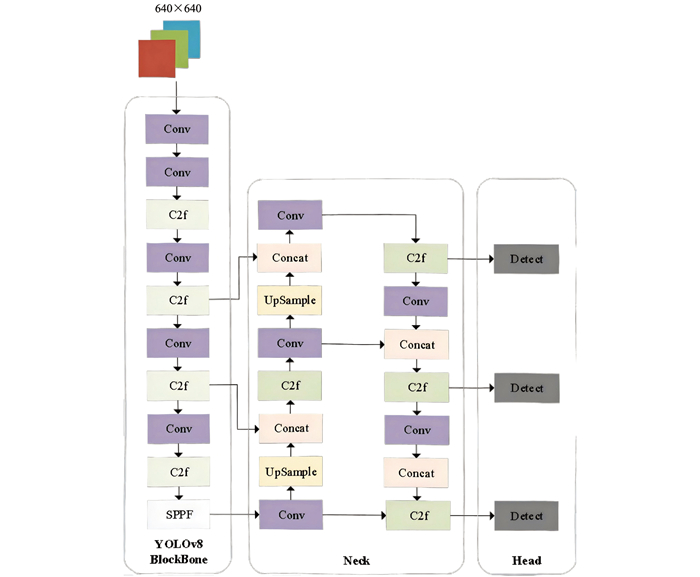
如图 2所示,YOLOv8结构分为3部分:骨干网络、颈部网络和探测头。其中骨干网络为基于C2f模块构建的轻量化卷积网络,常见的包括残差网络系列(Residual Network,ResNet)[9]和更高效的EfficientNet[10]等。颈部网络的一个显著特点是增强了多尺度特征融合的能力。通过引入路径聚合网络(Path Aggregation Network,PANet)[11]等先进的特征融合技术,YOLOv8能够更好地将低层和高层特征信息结合起来,提升小物体和远距离物体的检测精度。本研究内容为小目标检测,以尽可能轻量化为目的,故采用YOLOv8n作为原始模型结构进行优化[12]。
-
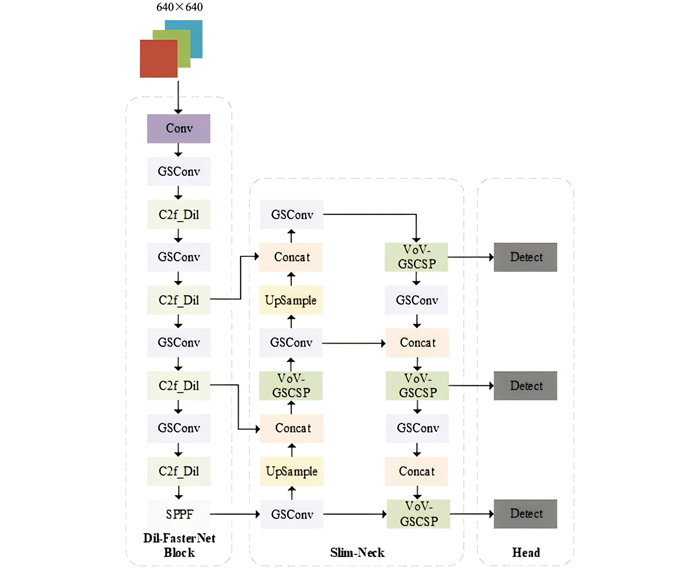
为了进一步提高模型的识别性能,本研究基于YOLOv8n框架设计了Dil-YOLO模型(图 3)。在原模型的特征提取网络设计了新的轻量级骨干网络Dil-FasterNet。该网络通过优化FasterNet模块[13]显著降低了模型参数量,适用于轻量化部署环境下的识别任务。此外,本研究在颈部网络部分引入了Slim-Neck空间深度卷积结构,提高了模型的响应速度和运行能力。最后,设计了FocalWise-IoU损失函数,通过结合Wise-IoU的非单调动态聚焦机制和Focal-EIoU v1的动态权重分配机制,减小低质量产生的异常梯度,按梯度进行增益分配。这些设计不仅提高了模型的运行速度,还降低了模型的存储开销,为番茄叶片病害识别模型的轻量化提供了有效的技术支持。
-
为了使农田环境下部署的检测模型在保持检测精度的情况下尽可能轻量化,本研究设计了Dil-FasterNet模块。
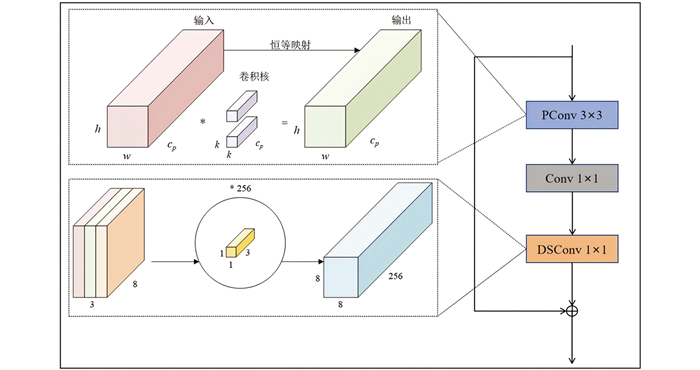
目前优化后的网络模块,例如空间和通道重构卷积(Spatial and Channel Reconstruction Convolution,SCConv)[14]虽然提升了检测性能,但由于其通道重构单元(Channel Reconstruction Unit,CRU)和空间重构单元(Spatial Reconstruction Unit,SRU)模块需要额外的全连接层或卷积层来生成权重,增加了模型参数量,导致训练时显存占用量显著增加,需要引入新的网络部件进行补偿。在保持高速有效检测的情况下,Ren S等设计出快速网络架构FasterNet[13],引入部分卷积(Partial Convolution,PConv)来代替基础卷积。PConv通过在部分输入通道中使用常规的Conv进行空间特征提取来减少冗余。PConv的FLOPs计算公式如下:
式中:h为输入图片高度;w为输入图片宽度;k为卷积核边长;cp为输入输出通道。FasterNet在提高浮点运算速度的同时有效降低了FLOPs,从而显著提升了目标检测的速度。
在此基础上,为进一步提高模型特征提取能力,在原FasterNet模型的特征转换器MLP中设计了Dil-FasterNet模块。该模块利用深度可分离卷积(Depth-Separable Convolution,DSConv)将标准卷积分解为DWConv和PWConv进行维度转换,同时利用空洞卷积(Dilated Conv,DConv)[15]增强特征提取能力。
Dil-FasterNet在自然农田番茄叶片病害识别环境中具备两大优势。一是其使用的DWConv对每个输入通道单独滤波,PWConv仅用1×1卷积融合通道,参数量远少于标准卷积。虽然计算量减少,但通过分离空间滤波和通道融合,仍然能有效地提取特征。二是由于扩张卷积直接在高分辨率特征图上进行操作,模型网络可在保持空间细节的同时捕捉更大范围的上下文信息,从而减少有效信息的丢失。本研究Dil-FasterNet模块如图 4所示。
-
为了加强物体边缘的信息捕捉能力,本研究引入了Slim-Neck模块。该模块通过优化特征图的空间表示和通道间的交互,提升了对图像边界框特征的捕捉能力,同时通过交互学习增强了对不同物体类别的区分。该模块基本原理如下:
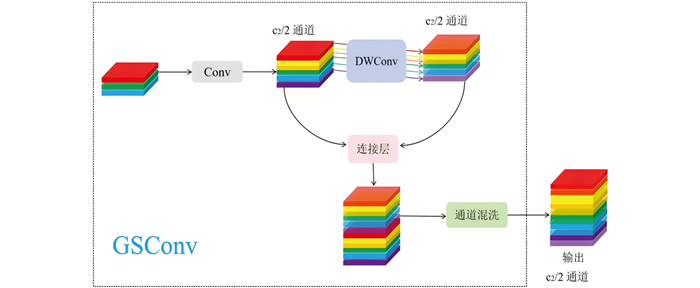
分组混洗卷积(Group-Shuffle Convolution,GSConv)提高了模型图像预测能力。常规的卷积神经网络将空间信息转化为通道信息的过程中易发生语义内容丢失的情况。GSConv能保持通道之间的隐藏连接,且不会增加模型的时间复杂度[15],其计算原理如下:
GSConv全局跨通道信息融合的时间复杂度为:
GSConv在稀疏部分通过稀疏化来降低计算量:
GSConv的总时间复杂度为:
其中:H、W、Cin为输入特征图尺寸;α为稀疏率;Cout为输出通道;K×K为卷积核大小。当稀疏策略仅保留局部关键点时,α会显著降低。GSConv模块结构如图 5所示。
在GSConv之后,继续引入由GS瓶颈和跨阶段部分网络(Cross Stage Partial Network,CSPNet)组成的多视角-分组混洗跨阶段部分模块(Variety of Views-Group Shuffle Cross Stage Partial,VOV-GSCSP)。GS瓶颈通过稀疏注意力机制和动态稀疏化机制,仅对重要区域和通道进行密集计算,在不显著增加计算量的前提下扩展有效识别视野、减少模型冗余计算。
Slim-Neck模块在农田环境中有如下优势:不同尺度的特征图(P3、P4、P5)先通过GSConv模块处理,然后通过上采样VpSample和拼接(Concat)操作与其他尺度的特征图结合,并再次通过GSConv模块,最后使用VOV-GSCSP模块进一步提取和融合特征,最后检测头对接收到的特征图(P3、P4、P5)进行检测。通过以上模块化和分层的方法,Slim-Neck架构能在保持高准确度的同时减少计算量和推理时间。
-
目标的检测与识别是深度学习的重点问题之一,其效果与损失函数性能密切相关。目前大多数的边界框回归函数(如IoU、SIoU[16]、原模型GIoU[17]和DIoU[18])会忽略训练集中存在的低质量示例,从而导致低质量示例产生的异常梯度影响算法模型的识别能力。Focal-EIoU v1被用于解决此问题,但由于聚焦机制不是动态的,现有研究对于非单调聚焦机制的内在机理和潜在效能未进行充分挖掘。本研究结合非单调的动态聚焦机制Wise-IoU和动态权重分配机制Focal-EIoU v1构建了FocalWise-IoU损失函数。FocalWise-IoU损失函数的主要优势在于:
非单调动态聚焦机制使用“离群度”[19]替代IoU对锚框进行质量评估,并设计了更加可靠的按梯度进行增益的分配机制。该函数降低了一部分高质量锚框的竞争力,并减小了低质量示例产生的异常梯度,其定义如图 6所示。
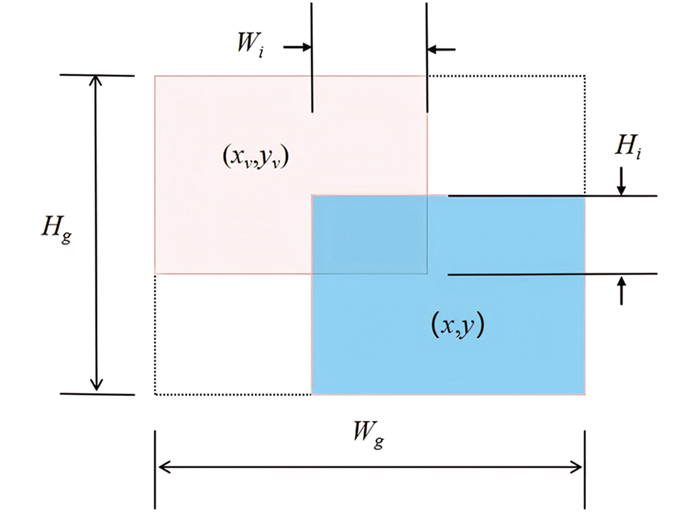
训练数据中的低质量样本常受几何因素例如距离和长宽比的影响,这可能会影响模型的泛化能力。一般理想的损失函数应在锚框与目标框高度重合时减少几何因素对检测的干扰,同时减少训练干预,从而增强模型的泛化能力。基于此构建距离注意力,并结合动态聚焦机制获得具有两层注意力机制的损失函数LWIoU-v1:
式中:RWIoU是距离注意力权重;LIoU是标准损失函数,为基础IoU损失。RWIoU计算公式如下:
式中:Wg、Hg分别表示最小封闭框的宽、高;*表示Wg,Hg仅用于归一化的数值运算,不再对模型参数产生梯度,从而没有引入新的度量。RWIoU∈[1,e),可显著放大普通质量锚框的LIoU。LIoU∈[0,1)可显著降低高质量锚框的RWIoU,并且当锚框与目标框重合良好时,它更注重中心点之间的距离。LWIoU-v1∈[0,1)可明显地降低高质量锚框的RWIoU,并且当锚框与目标框较吻合时,它将更加集中于中心点之间的距离。
锚框的离群度定义如式(7)所示:
式中:$\overline{L_{\mathrm{IoU}}}$表示IoU损失的指数移动平均值。
之后使用离群度构造非单调聚焦系数并将其应用到LWIoU-v1,得到了LWIoU-v3[6],其计算公式为:
式中:r为非单调梯度增益;α、δ为超参数,用来控制损失函数的梯度增益。
利用Focal动态加权机制[7]解决目标检测分类中正负样本、难易样本不均衡的问题。Focal动态加权机制计算公式如式(9)所示:
式中:pt∈[0,1)表示模型对真实类别的预测概率,越接近1表示预测越准确;γ∈[0,5]表示聚焦参数,用于控制对简单样本的权重衰减速率,γ=0时退化为标准交叉熵损失;(1-pt)γ为动态调制因子,用于自动降低高置信度简单样本(pt→1)的损失权重,使模型聚焦于难分类的样本(pt→0)的优化。
本研究基于LWIoU-v3以及Focal动态加权机制公式得出FocalWise-IoU函数,核心逻辑是先通过Focal调制因子聚焦低IoU样本,并通过几何注意力来强化锚框的几何位置约束,最后通过r优化低质量锚框的权重分配。FocalWise-IoU函数的推导公式为:
-
为了汇总分析各优化部分对模型的影响,采用5种模型实验指标进行评判:精确率(Precision)、浮点运算量(FLOPs)、召回率(R)、模型参数量(Params)、检测精度均值(mAP)作为评价指标[20]。计算公式如下:
式中:TP为预测正确的样本数;FP为被错误预测为正例的负例样本数;FN为被错误预测为负例的正例样本数;C为任务中的类别总数;APc为第c个类别的检测精度。
-
实验的硬件环境为12th Gen Intel(R)Core(TM)i3-12100F 3.30 GHz处理器,显卡为NVIDIA GeForce RTX 4060 ti,显存为16 GB;操作系统为Windows10;机器学习软件平台为PyTorch 2.3.1和CUDA 12.4。为了保证结果的有效性和真实性,所有实验均在PyTorch框架下进行端到端训练。本实验参数如表 4所示,各个模型训练过程均未使用任何预训练权值。
1.1. 数据集材料
1.2. YOLOv8网络结构
1.3. 改进的YOLOv8n网络
1.3.1. Dil-FasterNet模块
1.3.2. 特征融合模块
1.3.3. 损失函数的改进
1.4. 评价指标
1.5. 实验环境及参数设置
-
为了验证优化后模型的优势,将其与目前阶段常用的6种目标检测模型(SSD、Faster R-CNN、YOLOv7-tiny、YOLOv5s、YOLOv10-N、YOLOv8n)进行对比实验。对比结果见表 5。
与SSD、Faster R-CNN、YOLOv5s、YOLOv7-tiny、YOLOv10-N等主流检测模型相比,本研究提出的模型Dil-YOLO在mAP50、mAP50∶95、R、Precision上分别达到80.3%、63.9%、75.0%、79.8%,综合精度表现优异。相比基线模型YOLOv8n,Dil-YOLO模型的mAP50提升0.5个百分点,FLOPs减少2.1 G、参数量减少1.1 M,以更低开销取得更好检测效果,兼顾了检测精度与模型轻量化。
-
为了系统分析每一个改进点对模型的影响情况,以YOLOv8n模型作为初始模型,将FasterNet模块替换为Dil-FasterNet模块、特征融合模块替换为Slim-Neck模块、损失函数替换为FocalWise-IoU,改进模型的8次实验结果见表 6。
由表 6可知Dil-FasterNet的引入使模型的Params和FLOPs分别降低了0.6 M、1 G,有效减少了骨干网络的参数大小和浮点运算量。Slim-Neck特征融合结构的引入让模型的mAP50增加了0.3%,Params和FLOPs分别降低了0.4 M、0.8 G,在增强小目标检测精度的同时减小了模型规模。消融实验证明了YOLOv8n改进的有效性,在Params和FLOPs上分别下降了1.1 M和2.1 G,同时提升了模型的精度。
-
为了验证改进后的模型在不同场景下的表现,本研究选取国际农业植物病害应用最广泛的公开基准数据集PlantVillage[21]作为跨域测试数据源,从中筛选出与训练数据集完全独立、作物品类与病害特征存在显著的域偏移的棉花叶片病害数据集(PlantVillage Cotton Leaf Disease Dataset)与水稻叶片病害数据集(PlantVillage Rice Leaf Disease Dataset)两个标准子集作为跨域测试集。对比实验结果见表 7。
从表 7格数据可知,相比于原模型,改进后的检测模型在棉花病害数据集和水稻病害数据集保持了最佳的计算效率,验证了改进后模型在自然农田环境检测任务中具有良好的泛化性。
-
为了直观呈现改进后模型在农田环境中的病害检测性能,本研究采用了Grad-CAM[22]可视化技术,旨在展示深度神经网络检测结果的特征映射。改进模型能够检测到在原始模型中被忽略的微小目标,说明模型性能得到提升。实验热力图见图 7。
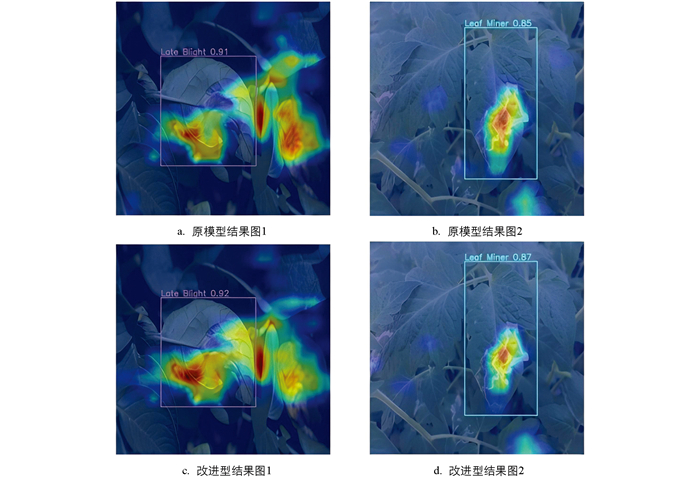
-
为了进一步通过可视化热力图展示改进效果,对2.3节泛化实验中所使用的两个泛化数据集采用Grad-CAM可视化技术,从而更加直观地展示改进后模型的检测效果。水稻病害、棉花病害数据集结果热力图分别见图 8、图 9。
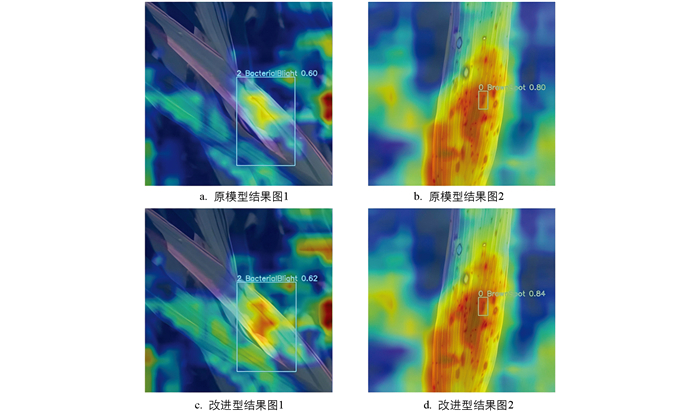
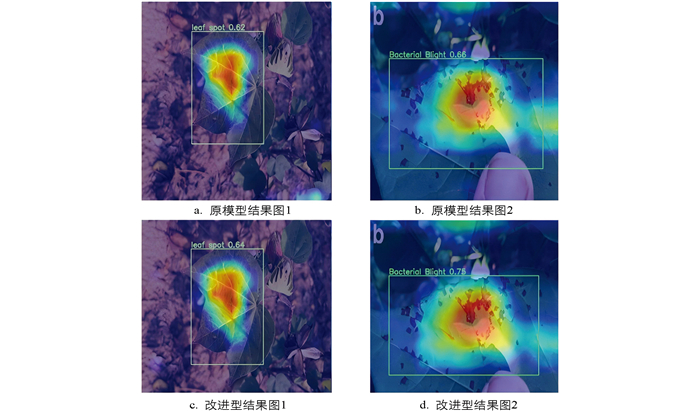
2.1. 对比实验
2.2. 消融实验
2.3. 泛化实验
2.4. 可视化
2.4.1. 可视化热力图
2.4.2. 热力图泛化结果
-
随着智慧农业的高速发展,农田环境下对于高精度、低延时、低算力的目标识别模型提出了更高的需求。当前主流识别模型在目标密集、尺度差异大的农田环境中常出现识别偏差,难以兼顾模型大小等问题。基于此,本研究提出了一种基于YOLOv8的番茄叶片病害识别模型。在YOLOv8的骨干网络中设计了Dil-FasterNet模块,通过空洞卷积可在不增加参数量的同时捕捉多尺度特征,通过深度可分离卷积能将标准卷积拆解为深度卷积与逐点卷积以大幅削减参数量和计算量。之后在颈部网络引入Slim-Neck模块,通过GSConv来替代标准卷积,搭配VoV-GSCSP瓶颈结构优化特征融合,在大幅降低参数量与计算开销的同时,强化多尺度特征的高效交互与表达。最后设计了FocalWise-IoU损失函数,使模型聚焦低IoU样本,解决锚框质量导致的梯度不平衡的问题,通过对特征维度的精细化约束,提升模型对复杂目标的判别能力。与基线模型相比,Dil-YOLO模型大幅减少了模型的计算量和参数量,Params降低了1.1 M,浮点运算量降低了2.1 G,且模型mAP相比于基线模型提高了0.5个百分点。
在后续研究中,将进一步增加数据集中病害种类和图像数量,强化数据的多样性,并与更多先进模型进行对比分析。同时补充不同地域、不同种植模式(设施大棚、露天种植)、不同作物生育期、极端光照/阴雨/叶片严重遮挡等田间复杂环境下的病害样本,构建更完备的番茄病害专用数据集。
 DownLoad:
DownLoad: